1. Введение
В предыдущем посте мы создали базовый пример конвейера агрегации. Возможно, вы захотите взглянуть на агрегирование данных с помощью Spring Data MongoDB и Spring Boot, если вам нужно больше подробностей о том, как создать проект и настроить приложение. В этом посте мы сосредоточимся на изучении варианта использования, в котором имеет смысл сгруппировать часть результата во вложенный объект.
Наши тестовые данные представляют собой набор футболистов с данными о лиге, к которой они принадлежат, и сколько голов они забили. Документ будет выглядеть так:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
|
@Documentpublic class ScorerResults { @Id private final String player; private final String country; private final String league; private final int goals; public ScorerResults(String player, String country, String league, int goals) { this.player = player; this.country = country; this.league = league; this.goals = goals; } //Getters and setters} |
Может быть интересно узнать, сколько голов было забито в каждой лиге. Кроме того, кто был лучшим бомбардиром лиги. В следующем разделе мы собираемся реализовать наш первый простой пример без использования вложенных объектов.
Вы можете найти исходный код всех этих примеров в моем репозитории Github .
2 Базовый пример
Мы можем использовать следующий класс для хранения результатов каждой лиги:
|
1
2
3
4
5
6
7
8
9
|
public class ScorerNotNestedStats { private String league; private int totalGoals; private String topPlayer; private String topCountry; private int topGoals; //Getters and setters} |
Чтобы найти лучших бомбардиров, нам нужно сначала отсортировать документы по забитым голам, а затем сгруппировать их по лиге. В хранилище эти две фазы конвейера реализованы следующими способами:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
private SortOperation buildSortOpertation() { return sort(Sort.Direction.DESC, "goals");}private GroupOperation buildGroupOperation() { return group("league") .first("league").as("league") .sum("goals").as("totalGoals") .first("player").as("topPlayer") .first("goals").as("topGoals") .first("country").as("topCountry");} |
Это должно сделать это. Давайте сгруппируем результаты, используя mongoTemplate Spring:
|
1
2
3
4
5
6
7
8
9
|
public List<ScorerNotNestedStats> aggregateNotNested() { SortOperation sortOperation = buildSortOpertation(); GroupOperation groupOperation = buildGroupOperation(); return mongoTemplate.aggregate(Aggregation.newAggregation( sortOperation, groupOperation ), ScorerResults.class, ScorerNotNestedStats.class).getMappedResults();} |
Если мы получим статистику испанской лиги, мы получим следующий результат:
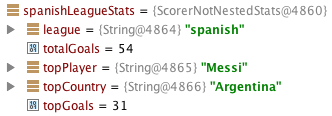
Хотя это достаточно справедливо, я не чувствую себя комфортно со всей информацией лучшего бомбардира, разбросанной по всему классу результатов. Я думаю, что было бы гораздо разумнее, если бы мы могли инкапсулировать все данные оценщика во вложенный объект. К счастью, мы можем сделать это непосредственно во время агрегации.
3 Вложение результата
Вложенный метод Spring Data предназначен для создания вложенных документов на этапе проектирования. Это позволит нам создать верхний класс goalcorer как свойство класса выходного результата:
|
1
2
3
4
5
|
ProjectionOperation projectionOperation = project("totalGoals") .and("league").as("league") .and("topScorer").nested( bind("name", "topPlayer").and("goals", "topGoals").and("country", "topCountry") ); |
В приведенной выше строке вложенный документ с именем topScorer создается вложенным методом, который будет содержать все данные о главном бомбардире текущей лиги. Его свойства отображаются в выходной класс с помощью метода bind (topPlayer, topGoals и topCountry).
Вызов MongoTemplate повторно использует наши предыдущие операции сортировки и группировки, а затем добавляет операцию проекции:
|
1
2
3
4
5
|
return mongoTemplate.aggregate(Aggregation.newAggregation( sortOperation, groupOperation, projectionOperation), ScorerResults.class, ScorerStats.class).getMappedResults(); |
Выполнение этого запроса приведет к гораздо более компактному результату, если все связанные с ним данные лучших целей будут упакованы в его собственный класс:

4. Вывод
Вложенный метод Spring Data MongoDB очень полезен для создания хорошо структурированных выходных результатов из наших запросов агрегации. Выполнение этого шага во время агрегации помогает нам избежать использования Java-кода для последующей обработки результата.
Я публикую свои новые сообщения в Google Plus и Twitter. Следуйте за мной, если вы хотите быть в курсе нового контента.
| Ссылка: | Источник данных Агрегация данных MongoDB: вложенные результаты нашего партнера по JCG Ксавьера Падро в блоге |