Платформа агрегации MongoDB предназначена для группировки документов и их преобразования в агрегированный результат. Запрос агрегации состоит в определении нескольких этапов, которые будут выполняться в конвейере. Если вы заинтересованы в более подробной информации о структуре, то
Документация mongodb — это хорошая отправная точка.
Цель этого поста — написать веб-приложение для запросов к mongodb, чтобы получить агрегированные результаты из базы данных. Мы сделаем это очень просто благодаря Spring Boot и Spring Data. На самом деле это приложение очень быстро внедряется, поскольку Spring Boot позаботится обо всех необходимых настройках, а Spring Data поможет нам настроить репозитории.
Исходный код можно найти в моем репозитории Github .
1 Приложение
Прежде чем перейти к коду, давайте посмотрим, что мы хотим сделать с нашим приложением.
Наш домен представляет собой набор продуктов, которые мы распределили по нескольким складам:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
@Documentpublic class Product { @Id private final String id; private final String warehouse; private final float price; public Product(String id, String warehouse, float price) { this.id = id; this.warehouse = warehouse; this.price = price; } public String getId() { return id; } public String getWarehouse() { return warehouse; } public float getPrice() { return price; }} |
Наша цель — собрать все продукты в ценовом диапазоне, сгруппированные по складу и собрать общий доход и среднюю цену каждой группы.
В этом примере на наших складах хранятся следующие товары:
|
1
2
3
4
5
6
7
8
|
new Product("NW1", "Norwich", 3.0f);new Product("LN1", "London", 25.0f);new Product("LN2", "London", 35.0f);new Product("LV1", "Liverpool", 15.2f);new Product("MN1", "Manchester", 45.5f);new Product("LV2", "Liverpool", 23.9f);new Product("LN3", "London", 55.5f);new Product("LD1", "Leeds", 87.0f); |
Приложение будет запрашивать товары по цене от 5,0 до 70,0. Необходимые шаги конвейера агрегации будут следующими:
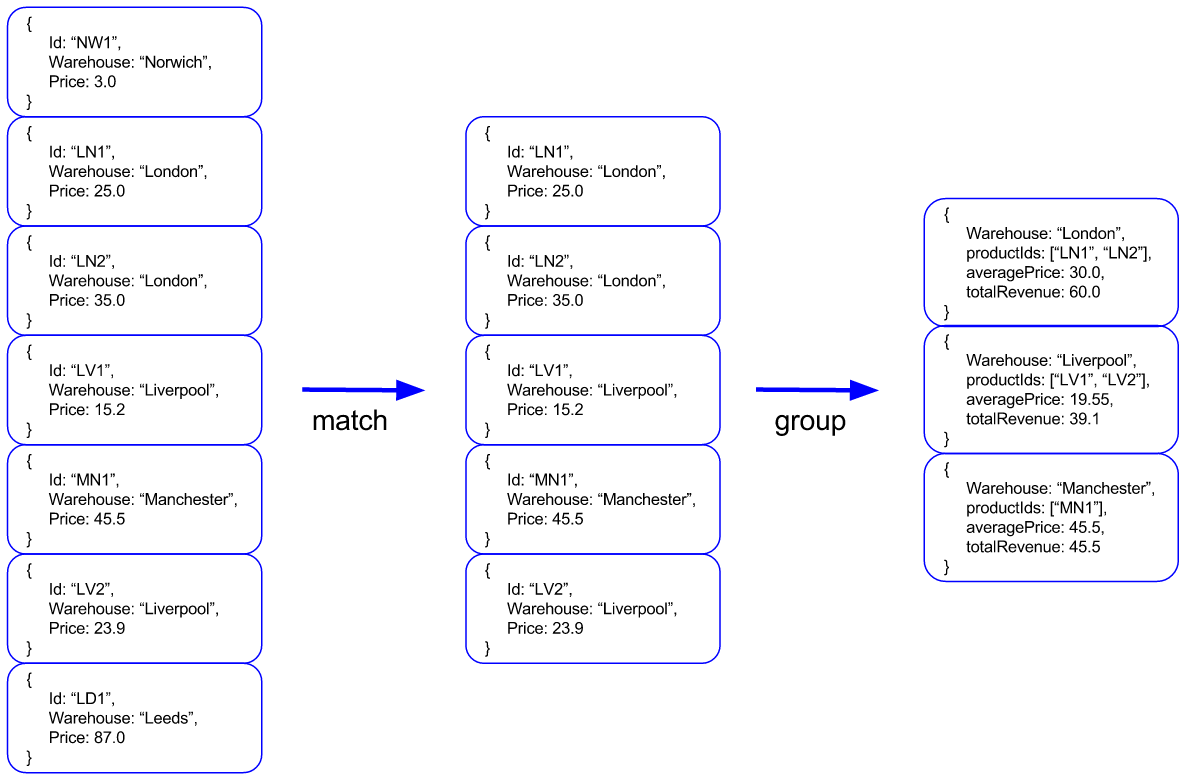
В итоге мы получим агрегированные результаты, сгруппированные по складу. Каждая группа будет содержать список товаров каждого склада, среднюю цену товара и общую выручку, которая фактически является суммой цен.
2 зависимости Maven
Как видите, у нас есть короткий pom.xml с зависимостями Spring Boot:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.3.3.RELEASE</version> <relativePath/></parent><properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <java.version>1.8</java.version></properties><dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency></dependencies><build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins></build> |
Определяя spring-boot-starter-parent в качестве родительского pom, мы устанавливаем настройки Spring Boot по умолчанию. В основном он устанавливает версии набора библиотек, которые он может использовать, например Spring или Apache Commons. Например, Spring Boot 1.3.3, который мы используем, устанавливает 4.2.5.RELEASE в качестве версии среды Spring. Как указано в предыдущих статьях, он не добавляет библиотеки в наше приложение, он только устанавливает версии.
После определения родителя нам нужно добавить только три зависимости:
- spring-boot-starter-web: в основном включает библиотеки Spring MVC и встроенный сервер Tomcat.
- spring-boot-starter-test: включает в себя библиотеки тестирования, такие как JUnit, Mockito, Hamcrest и Spring Test.
- spring-boot-starter-data-mongodb: эта зависимость включает Java-драйвер MongoDB и библиотеки Spring Data Mongo.
3 Настройка приложения
Благодаря Spring Boot, настройка приложения так же проста, как установка зависимостей:
|
1
2
3
4
5
6
7
|
@SpringBootApplicationpublic class AggregationApplication { public static void main(String[] args) { SpringApplication.run(AggregationApplication.class, args); }} |
При запуске основного метода мы запустим наше веб-приложение, прослушивающее порт 8080.
4 хранилище
Теперь, когда у нас правильно настроено приложение, мы реализуем репозиторий. Это не сложно, так как Spring Data позаботится обо всей проводке.
|
1
2
3
4
|
@Repositorypublic interface ProductRepository extends MongoRepository<Product, String> { } |
Следующий тест подтверждает, что наше приложение правильно настроено.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
@RunWith(SpringJUnit4ClassRunner.class)@SpringApplicationConfiguration(classes = AggregationApplication.class)@WebAppConfigurationpublic class AggregationApplicationTests { @Autowired private ProductRepository productRepository; @Before public void setUp() { productRepository.deleteAll(); } @Test public void contextLoads() { } @Test public void findById() { Product product = new Product("LN1", "London", 5.0f); productRepository.save(product); Product foundProduct = productRepository.findOne("LN1"); assertNotNull(foundProduct); }} |
Мы не реализовали методы save и findOne. Они уже определены, поскольку наш репозиторий расширяет MongoRepository.
5 запрос агрегации
Наконец, мы настроили приложение и объяснили все шаги. Теперь мы можем сосредоточиться на запросе агрегации.
Поскольку наш запрос агрегации не является базовым запросом, нам необходимо реализовать собственный репозиторий. Шаги:
Создайте собственный репозиторий с помощью метода, который нам нужен:
|
1
2
3
4
|
public interface ProductRepositoryCustom { List<WarehouseSummary> aggregate(float minPrice, float maxPrice);} |
Измените первый репозиторий, чтобы также расширить наш пользовательский репозиторий:
|
1
2
3
4
|
@Repositorypublic interface ProductRepository extends MongoRepository<Product, String>, ProductRepositoryCustom { } |
Создайте реализацию, чтобы написать запрос агрегации:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
public class ProductRepositoryImpl implements ProductRepositoryCustom { private final MongoTemplate mongoTemplate; @Autowired public ProductRepositoryImpl(MongoTemplate mongoTemplate) { this.mongoTemplate = mongoTemplate; } @Override public List<WarehouseSummary> aggregate(float minPrice, float maxPrice) { ... }} |
Теперь мы собираемся реализовать этапы трубопровода mongodb, как описано в начале поста.
Наша первая операция — операция сопоставления . Мы отфильтруем все товарные документы, которые находятся за пределами нашего ценового диапазона:
|
1
2
3
4
|
private MatchOperation getMatchOperation(float minPrice, float maxPrice) { Criteria priceCriteria = where("price").gt(minPrice).andOperator(where("price").lt(maxPrice)); return match(priceCriteria);} |
Следующим этапом конвейера является групповая операция. Помимо группировки документов по складу, на этом этапе мы также делаем следующие расчеты:
- last: возвращает склад последнего документа в группе.
- addToSet: собирает все уникальные идентификаторы продуктов всех сгруппированных документов, в результате чего получается массив.
- avg: Рассчитывает среднее значение всех цен в группе.
- сумма: Суммирует все цены в группе.
|
1
2
3
4
5
6
7
|
private GroupOperation getGroupOperation() { return group("warehouse") .last("warehouse").as("warehouse") .addToSet("id").as("productIds") .avg("price").as("averagePrice") .sum("price").as("totalRevenue");} |
Последним этапом трубопровода является эксплуатация проекта . Здесь мы указываем результирующие поля агрегации:
|
1
2
3
4
|
private ProjectionOperation getProjectOperation() { return project("productIds", "averagePrice", "totalRevenue") .and("warehouse").previousOperation();} |
Запрос строится следующим образом:
|
01
02
03
04
05
06
07
08
09
10
11
|
public List<WarehouseSummary> aggregate(float minPrice, float maxPrice) { MatchOperation matchOperation = getMatchOperation(minPrice, maxPrice); GroupOperation groupOperation = getGroupOperation(); ProjectionOperation projectionOperation = getProjectOperation(); return mongoTemplate.aggregate(Aggregation.newAggregation( matchOperation, groupOperation, projectionOperation ), Product.class, WarehouseSummary.class).getMappedResults();} |
В агрегатном методе мы указываем входной класс, который является нашим документом Product. Следующий аргумент — это выходной класс, который представляет собой DTO для хранения результирующей агрегации:
|
1
2
3
4
5
|
public class WarehouseSummary { private String warehouse; private List<String> productIds; private float averagePrice; private float totalRevenue; |
Мы должны закончить пост тестом, доказывающим, что результаты — это то, чего мы ожидаем:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
@Testpublic void aggregateProducts() { saveProducts(); List<WarehouseSummary> warehouseSummaries = productRepository.aggregate(5.0f, 70.0f); assertEquals(3, warehouseSummaries.size()); WarehouseSummary liverpoolProducts = getLiverpoolProducts(warehouseSummaries); assertEquals(39.1, liverpoolProducts.getTotalRevenue(), 0.01); assertEquals(19.55, liverpoolProducts.getAveragePrice(), 0.01);}private void saveProducts() { productRepository.save(new Product("NW1", "Norwich", 3.0f)); productRepository.save(new Product("LN1", "London", 25.0f)); productRepository.save(new Product("LN2", "London", 35.0f)); productRepository.save(new Product("LV1", "Liverpool", 15.2f)); productRepository.save(new Product("MN1", "Manchester", 45.5f)); productRepository.save(new Product("LV2", "Liverpool", 23.9f)); productRepository.save(new Product("LN3", "London", 55.5f)); productRepository.save(new Product("LD1", "Leeds", 87.0f));}private WarehouseSummary getLiverpoolProducts(List<WarehouseSummary> warehouseSummaries) { return warehouseSummaries.stream().filter(product -> "Liverpool".equals(product.getWarehouse())).findAny().get();} |
6. Заключение
Spring Data имеет хорошую интеграцию с платформой агрегации MongoDB. Добавление Spring Boot для настройки приложения позволяет нам сосредоточиться на построении запроса. Для процесса построения в классе агрегации есть несколько статических методов, которые помогают нам реализовать различные этапы конвейера.
Я публикую свои новые сообщения в Google Plus и Twitter. Следуйте за мной, если вы хотите быть в курсе нового контента.
| Ссылка: | Агрегирование данных с помощью Spring Data MongoDB и Spring Boot от нашего партнера по |