В этой статье я расскажу о нескольких приемах использования инструментов Hibernate в моделях чтения CQRS для быстрой разработки.
Почему Hibernate?
Hibernate чрезвычайно популярен. Это также обманчиво легко снаружи и довольно сложно внутри. Это позволяет легко начать работу без глубокого понимания, неправильного использования и обнаружения проблем, когда уже слишком поздно. По всем этим причинам в наши дни это довольно печально.
Тем не менее, это все еще кусок надежной и зрелой технологии. Проверенные в бою, надежные, хорошо документированные и имеющие решения для многих распространенных проблем в коробке. Это может сделать вас очень продуктивным. Тем более, если вы включите инструменты и библиотеки вокруг него. Наконец, это безопасно, если вы знаете, что делаете.
Автоматическая генерация схемы
Синхронизация схемы SQL с определениями классов Java — довольно сложная задача. В лучшем случае это очень утомительная и трудоемкая деятельность. Есть множество возможностей для ошибок.
Hibernate поставляется с генератором схемы (hbm2ddl), но в своем «родном» виде он имеет ограниченное применение в производстве. Он может проверять схему, пытаться обновить или экспортировать ее только при создании SessionFactory . К счастью, эта же утилита доступна для пользовательского программного использования.
Мы пошли еще дальше и интегрировали его с прогнозами CQRS. Вот как это работает:
- При запуске потока процесса проецирования проверьте, соответствует ли схема БД определениям классов Java.
- Если это не так, удалите схему и повторно экспортируйте ее (используя hbm2ddl). Перезапустите проекцию, заново обработав хранилище событий с самого начала. Начните проектирование с самого начала.
- Если он совпадает, просто продолжайте обновлять модель из текущего состояния.
Благодаря этому, в большинстве случаев вам не нужно вводить SQL вручную с определениями таблиц. Это делает разработку намного быстрее. Это похоже на работу с hbm2ddl.auto = create-drop . Однако использование этого в модели представления означает, что оно фактически не теряет данные (что безопасно в хранилище событий). Кроме того, он достаточно умен, чтобы воссоздать схему, только если она действительно изменилась — в отличие от стратегии создания-отбрасывания.
Сохранение данных и предотвращение ненужных перезапусков не только улучшают цикл разработки. Это также может сделать его пригодным для использования в производстве. По крайней мере, при определенных условиях, см. Ниже.
Есть одно предупреждение: не все изменения в схеме приводят к сбою проверки Hibernate. Одним из примеров является изменение длины поля — если это varchar или текст, проверка проходит независимо от предела. Другое необнаруженное изменение — обнуляемость.
Эти проблемы можно решить, перезапустив проекцию вручную (см. Ниже). Другой возможностью является наличие фиктивного объекта, который не хранит данные, но модифицируется для запуска автоматического перезапуска. В нем может быть одно поле с именем schemaVersion , причем @Column(name = "v_4") обновляется (разработчиком) при каждом изменении схемы.
Реализация
Вот как это можно реализовать:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
public class HibernateSchemaExporter { private final EntityManager entityManager; public HibernateSchemaExporter(EntityManager entityManager) { this.entityManager = entityManager; } public void validateAndExportIfNeeded(List<Class> entityClasses) { Configuration config = getConfiguration(entityClasses); if (!isSchemaValid(config)) { export(config); } } private Configuration getConfiguration(List<Class> entityClasses) { SessionFactoryImplementor sessionFactory = (SessionFactoryImplementor) getSessionFactory(); Configuration cfg = new Configuration(); cfg.setProperty("hibernate.dialect", sessionFactory.getDialect().toString()); // Do this when using a custom naming strategy, e.g. with Spring Boot: Object namingStrategy = sessionFactory.getProperties().get("hibernate.ejb.naming_strategy"); if (namingStrategy instanceof NamingStrategy) { cfg.setNamingStrategy((NamingStrategy) namingStrategy); } else if (namingStrategy instanceof String) { try { log.debug("Instantiating naming strategy: " + namingStrategy); cfg.setNamingStrategy((NamingStrategy) Class.forName((String) namingStrategy).newInstance()); } catch (ReflectiveOperationException ex) { log.warn("Problem setting naming strategy", ex); } } else { log.warn("Using default naming strategy"); } entityClasses.forEach(cfg::addAnnotatedClass); return cfg; } private boolean isSchemaValid(Configuration cfg) { try { new SchemaValidator(getServiceRegistry(), cfg).validate(); return true; } catch (HibernateException e) { // Yay, exception-driven flow! return false; } } private void export(Configuration cfg) { new SchemaExport(getServiceRegistry(), cfg).create(false, true); clearCaches(cfg); } private ServiceRegistry getServiceRegistry() { return getSessionFactory().getSessionFactoryOptions().getServiceRegistry(); } private void clearCaches(Configuration cfg) { SessionFactory sf = entityManager.unwrap(Session.class).getSessionFactory(); Cache cache = sf.getCache(); stream(cfg.getClassMappings()).forEach(pc -> { if (pc instanceof RootClass) { cache.evictEntityRegion(((RootClass) pc).getCacheRegionName()); } }); stream(cfg.getCollectionMappings()).forEach(coll -> { cache.evictCollectionRegion(((Collection) coll).getCacheRegionName()); }); } private SessionFactory getSessionFactory() { return entityManager.unwrap(Session.class).getSessionFactory(); }} |
API выглядит довольно устаревшим и громоздким. Кажется, нет способа извлечь Configuration из существующего SessionFactory . Это только то, что используется для создания фабрики и выброшено. Мы должны воссоздать его с нуля. Вышесказанное — это все, что нам нужно для правильной работы с Spring Boot и кешем L2.
Перезапуск прогнозов
Мы также реализовали способ выполнения такой повторной инициализации вручную, отображаемый в виде кнопки на консоли администратора. Это удобно, когда что-то в проекции изменяется, но не требует изменения схемы. Например, если значение вычисляется / форматируется по-другому, но все еще является текстовым полем, этот механизм можно использовать для повторной обработки истории вручную. Другой вариант использования — исправление ошибки.
Использование производства?
Мы использовали этот механизм с большим успехом во время разработки. Это позволило нам свободно изменять схему, изменяя только классы Java и не беспокоясь об определениях таблиц. Благодаря комбинации с CQRS мы могли даже поддерживать длительные демонстрационные или пилотные экземпляры клиентов. Данные всегда были в безопасности в хранилище событий. Мы могли бы постепенно разрабатывать схему модели чтения и автоматически вносить изменения в работающий экземпляр без потери данных или написания сценариев миграции SQL вручную.
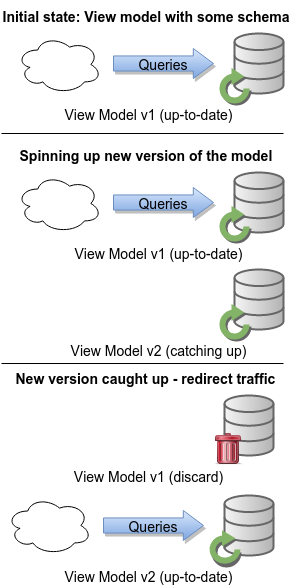
Очевидно, что этот подход имеет свои пределы. Повторная обработка всего хранилища событий в произвольный момент времени возможна только в очень небольших случаях или если события могут быть обработаны достаточно быстро.
В противном случае миграция может быть решена с помощью сценария миграции SQL, но у него есть свои ограничения. Это часто рискованно и сложно. Это может быть медленно. Самое главное, если изменения больше и включают данные, которые ранее не были включены в модель чтения (но доступны в событиях), использование сценария SQL просто не вариант.
Гораздо лучшее решение — указать проекцию (с новым кодом) на новую базу данных. Пусть он обработает журнал событий. Когда он догоняет, протестируйте модель представления, перенаправьте трафик и отбросьте старый экземпляр. Представленное решение прекрасно работает и с этим подходом.
| Ссылка: | Быстрое развитие с Hibernate в CQRS. Прочитайте модели нашего партнера JCG Конрада Гаруса в блоге Белки . |