Вопрос эффективности.
Итак, вы начинаете работать над некоторым кодом, и чудовищный интерфейс замирает на вас, выбирая из зубов куски предыдущего программиста, который осмелился подойти. У него двадцать пять методов, и вам просто нужно добавить еще один маленький метод. Должны ли вы сжать и добавить его, или вы должны слушать этот голос, говорящий вам, что пришло время провести рефакторинг? Принцип сегрегации интерфейса гласит, что вы должны взломать этого зверя в интерфейсный салат, но сроки не минуют, и менеджеры никогда не поймут. Как вы можете быстро увидеть, какое подмножество интерфейсов вы должны выбрать?
Существуют два подхода: семантический и синтаксический.
Семантически, программист разбивает большой интерфейс на более мелкие, изучая назначение каждого метода, определяя, какие методы «принадлежат» вместе, и создавая интерфейсы на основе этих общностей. Не заблуждайтесь: это лучшая стратегия. Единственная проблема с этим подходом состоит в том, что разные программисты по-разному оценивают разные общности. Попросите шесть программистов разделить большой интерфейс, и вы можете найти шесть различных декомпозиций.
Другой синтаксический подход. В то время как семантика касается значения, синтаксика удаляет все значения и рассматривает только грубый факт связи между клиентом и интерфейсным методом. Семантические понятия живут в голове программиста, субъективны; Синтаксические понятия живут в исходном коде, цель. Будучи объективным, синтаксический подход должен позволить объективно оценить, насколько «плохим» интерфейс является до операции, и насколько «хорошим» являются пациенты (?) После.
Просто ради интереса, давайте попробуем такую оценку.
ISP говорит , что «Ни один клиент не должен быть вынужден зависеть от методов не использует. Интерфейсы ISP расколов , которые являются очень большими , на более мелкие и более специфические , так что клиенты будут иметь только знать о методах, которые представляют интерес для них «. Итак, рассмотрим рисунок 1, показывающий клиентский класс ClientA и его три зависимости от интерфейса I , пять методов.
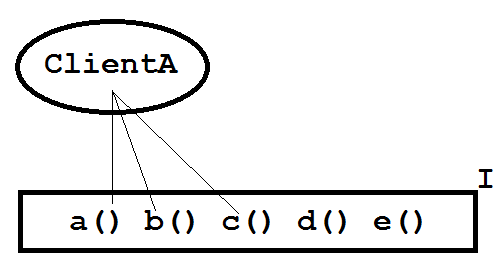
Рисунок 1: Клиентский класс ClientA и интерфейс I.
Интерфейс у меня плохой? Хорошо, интерфейс предоставляет ClientA трем методам, которые он использует, и двум методам, которые он не использует. Возможно, вопрос не в том, нарушен ли провайдер, а в какой степени. Можно ли поэтому спросить, насколько эффективно интерфейс I используется его клиентами?
Давайте определим, что эффективность использования интерфейса клиентом — это число методов, которые клиент вызывает на интерфейсе, деленное на общее количество методов в этом интерфейсе, выраженное в процентах. Так как ClientA использует только 3/5 интерфейса I, мы можем сказать, что интерфейс I эффективен на 60% по отношению к этому клиенту. А что, если два клиента покусали интерфейс? Смотрите рисунок 2.
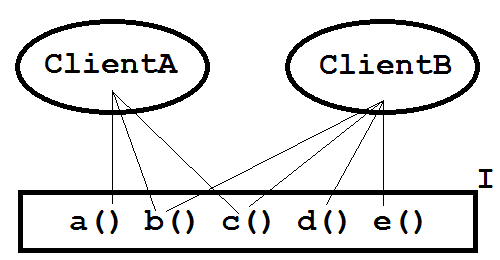
Рисунок 1: Два клиентских класса и интерфейс I.
На рисунке 2 добавлен второй класс, ClientB , который зависит от четырех методов интерфейса I , что дает ему эффективность использования 80%. Общая эффективность I в этом случае является суммой обеих эффективностей, деленных на количество клиентов: (60% + 80%) / 2 = 70%.
Конечно, мы можем определить такую арифметическую акробатику так, как нам нравится, но эта модель эффективности интерфейса пытается охватить интересные аспекты. Так как «ни одного клиента не следует заставлять зависеть от методов, которые он не использует», тогда мы хотели бы, чтобы эффективность нашего интерфейса падала по мере роста интерфейсов, а клиенты зависели от относительно меньшего количества методов (что он делает), и мы хотели бы, чтобы он рос поскольку интерфейсы сокращаются, и клиенты зависят от относительно большего количества методов (что он делает).
И с помощью объективного критерия, мы можем сделать так, чтобы машины выполняли за нас работу, объединяя вычисления в алгоритм и вставляя их в анализатор кода, чтобы он мог выявить наименее эффективные интерфейсы в наших системах. Как мы можем использовать такой алгоритм?
Мы могли бы сделать несколько образованных предположений, разделив большой интерфейс на более мелкие, с помощью нашего алгоритма, рассчитывающего эффективность до и после, и предложив эти разделения с наивысшей эффективностью.
Но мы можем быть еще ленивее.
Интерфейс имеет низкую эффективность, потому что один или несколько его клиентов зависят от слишком немногих его методов; Так что, если у нас есть наш алгоритм, который сканирует всех клиентов нашего интерфейса, гипотетически извлекает из интерфейса методы, которые вызывает каждый клиент, а затем прогнозирует эффективность оставшегося интерфейса? Это может помочь определить, какие подмножества методов в интерфейсе, «принадлежащие», вместе взятые, поскольку извлеченные интерфейсы отражают не понятие общности программиста, а фактическое использование клиента. Затем мы могли бы извлечь те методы, которые дают исходному интерфейсу лучший прирост эффективности, и начать процесс заново.
Но мы можем быть еще ленивее.
Что если мы скажем нашему алгоритму: «Послушайте, не просто дайте мне список потенциальных извлечений интерфейса, но и смоделируйте извлечение наиболее эффективного, а затем повторите процесс на этом оставшемся интерфейсе, совокупно прогнозируя путь, который делает исходный интерфейс становится все более эффективным. И продолжайте идти, пока не останется ничего, что можно извлечь. Тогда это даст нам не просто предложение интерфейса для извлечения, но и полную дорожную карту извлечений, которые приведут к отдаленной, но высокой эффективности.
Конечно, тогда мы не будем слепо следовать этой дорожной карте: семантическая декомпозиция превосходит все. Однако эти синтаксические предложения могут помочь нам оценить наш выбор. Если мы обнаружим, что они поддерживают наши хорошие догадки общности, тем лучше.
Puddings’n’proof.
Давайте попробуем это. Давайте возьмем честный трудолюбивый Java-код и добавим его в алгоритм, чтобы посмотреть, что получится. ( Spoiklin Soice был обновлен по алгоритму: щелкните правой кнопкой мыши на классе и выберите «Предложить извлечение».)
Как обычно, самое последнее структурное исследование — в настоящее время FitNesse — предоставит аналитические мельницы. Средняя эффективность интерфейса FitNesse впечатляюще высока. Интерфейсы имеют тенденцию быть маленькими, и найти большие неэффективные интерфейсы оказывается трудным, но мы находим кандидата в интерфейсе WikiPage .
WikiPage имеет 19 методов (поэтому не слишком страдает ожирением) и эффективен только на 15%, отчасти из-за огромного количества клиентов, 104 из которых немногие вызывают все свои методы. В приведенном ниже списке представлены эти методы, а также их процентное использование (да, вы также можете рассчитать это по модели):
getPageCrawler: 68.3% getData: 61.5% getName: 32.7% commit: 23.1% getParent: 15.4% getChildren: 12.5% getChildPage: 9.6% addChildPage: 8.7% getExtension: 7.7% hasExtension: 6.7% getDataVersion: 5.8% getHelpText: 5.8% removeChildPage: 5.8% hasChildPage: 5.8% getActions: 4.8% getParentForVariables: 4.8% setParentForVariables: 3.8% getHeaderPage: 3.8% getFooterPage: 3.8%
Уделите немного времени: исходя из того, какое значение вы хотели бы извлечь из этих имен, как бы вы разбили этот интерфейс? Если наш алгоритм строит дорожную карту извлечений, он предполагает, что извлечение, которое повысит эффективность этого интерфейса (до 24%), будет следующим:
addChildPage getPageCrawler commit getData getParent hasChildPage getName getChildren removeChildPage
Идеальная семантическая декомпозиция привела бы к извлечению интерфейса, все методы которого имели бы некоторую очевидную общность, и вышеописанное не является такой декомпозицией. Например, этот commit () кажется немного странным. Тем не менее наши семантические братья, возможно, не слишком недовольны этим общим предложением: оно кажется тяжелым для «ребенка» и «родителя», а семантикам нравятся подобные вещи. Если бы мы додумались разорвать интерфейс меньшего размера, чтобы сосредоточиться на отношениях, то вышеприведенное может предложить некоторую проверку. Далее алгоритм предлагает следующее извлечение интерфейса, доведя эффективность остальных методов до колоссальных 63%:
getActions setParentForVariables getHelpText getHeaderPage getChildPage getParentForVariables getFooterPage
Опять же, грубый надежный метод setParentForVariables () выглядит так, как будто он забрел в отдел парфюмерии магазина, но предложение кажется довольно «страничным». Принимая во внимание, что первый интерфейс также имел дело со страницами — в конце концов, донором является WikiPage — этот интерфейс, похоже, меньше связан с отношениями и больше касается механики страниц: например, верхние и нижние колонтитулы, текст справки и действия. Так что еще раз это может предложить некоторое утешение, если бы мы изначально думали извлечь интерфейс на основе деталей веб-страницы.
Последнее предложение, которое принесет нам 100% эффективности, восхитительно:
getExtension hasExtension
Более последовательный интерфейс, который мы не могли желать. В самом деле, тот факт, что чисто синтаксический алгоритм может обнаружить настолько семантически согласованный интерфейс, намекает на тщательное размышление, заложенное в дизайн интерфейса FitNesse.
Вы получите точку, хотя еще один пример доступен здесь , и некоторые из собственного грязного белья Spoiklin находится здесь (о, позор!).
Резюме.
Машины не могут разработать для нас хорошие, маленькие и эффективные интерфейсы — алгоритмы не понимают методов, которые они изучают, — но они могут предложить статистическую перспективу использования клиентом. Если случается, что алгоритмы предлагают извлечение интерфейса, которое соответствует утверждению, это только отражает то, что разработчики исходного интерфейса имели хорошее представление о том, как клиенты будут использовать различные его части, если не целое.
Программисты — моряки. Они плавают не в спокойных тропических морях, а в замерзших арктических океанах, их корабли окружены постоянно меняющимся льдом, в котором основные конкурирующие силы — силы, обеспечивающие функциональность и поддержание конструкции — ежедневно угрожают разрушить их корпуса. Они не отказываются от навигационных инструментов, какими бы незначительными они ни были.
</purple>
Заметки.
Чуть более формально: дан набор из n интерфейсов, где i- й интерфейс — это I i, и набор из m клиентских классов, а также учитывая, что число методов в i- м интерфейсе равно | I i | и число клиентских классов i- го интерфейса равно | C i | и число методов, от которых зависит j- й клиент в i- м интерфейсе, определяется как | U ji | , то эффективность n интерфейсы задаются:
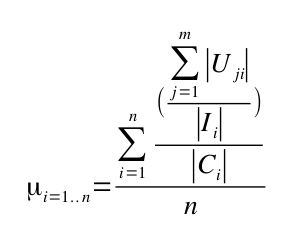
Кроме того, алгоритму нужно несколько больше ограничений, чем просто это уравнение: например, мы не хотим, чтобы он вытаскивал слишком много интерфейсов с одним методом, которые на 100% эффективны, но немного … излишни. Тем не менее, приведенное выше уравнение остается ключевым.
Наконец, кто-то может порекомендовать какой-нибудь общедоступный исходный код Java, который он хотел бы увидеть структурно проанализированным? Если это так, пожалуйста, укажите это в комментариях ниже. Пришло время для другого в серии …