Я был действительно впечатлен этим блог на подведение итогов Оценки с Graph от Макса и всегда ждал ч.2 , чтобы показать ?
В блоге рассказывается о действительно интересном подходе Кавиты Ганесан, который использует графическое представление предложений рецензируемого контента для извлечения наиболее значимых утверждений о продукте.
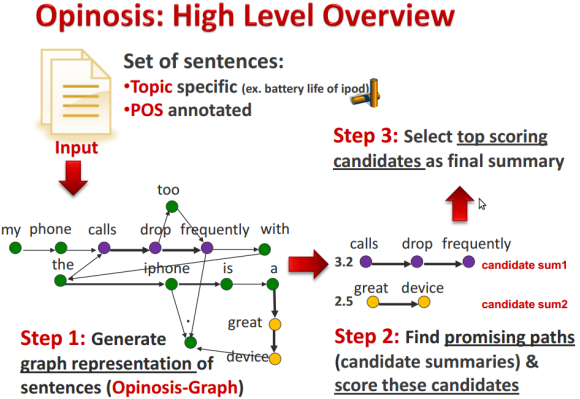
Каждое слово предложения представлено общим узлом в графе с порядком слов, отражаемым отношениями, указывающими на следующее слово, которое содержит идентификатор предложения и информацию о положении ведущего слова.
Просто глядя на структуру графика, оказывается, что наиболее значимые утверждения (положительные или отрицательные) повторяются во многих обзорах.
Различия в формулировке или вставленных словах заливки только минимально влияют на структуру графа, но усиливают ее для частей, где они перекрываются.
Вы можете найти все детали подхода в этой презентации или сопутствующем исследовании .
Я всегда шутил, что вы можете создать это представление графа без программирования, просто написав простое выражение Cypher, но на самом деле я никогда не пробовал.
До сих пор, честно говоря, я впечатлен тем, как легко было записать суть, а затем расширять и расширять утверждение, пока оно не охватит большое количество входных данных.
Суть создания графа можно сформулировать так: «Каждое слово предложения представлено общим узлом в графе с порядком слов, отражаемым отношениями, указывающими на следующее слово».
В Cypher:
// "Great device but the calls drop too frequently"
WITH split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
CREATE (w1)-[:NEXT]->(w2);WITH split("Great device but the calls drop too frequently"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2);Выполнение этого утверждения с двумя примерами обзоров из вышеупомянутого сообщения в блоге генерирует это графическое представление:

Довольно круто, я также могу запускать запросы, например, чтобы найти общие фразы (для телефонов):
MATCH path = (w:Word {name:"calls"})-[:NEXT*..3]->()
RETURN [n in nodes(path) | n.name] as phrase
LIMIT 5;|
фраза |
|
[звонки, падение] |
|
[звонки, падение, часто] |
|
[звонки, падение, часто, с] |
|
[звонки, брось тоже] |
|
[звонки, бросай тоже часто] |
Функции Cypher, используемые до сих пор:
-
WITHпредоставить данные для следующего оператора запроса -
split()разделить текст по разделителям -
size()для размера коллекций и строк -
range()создать диапазон чисел -
UNWINDпревратить коллекцию в строки результатов -
доступ к индексу коллекции, чтобы получить отдельные слова
-
MERGE для «поиска или создания» данных в графе с меткой
:Wordдля каждого узла и свойствомname -
CREATE для создания взаимосвязи между двумя узлами (в данном конкретном случае вы захотите использовать MERGE для взаимосвязи)
Для MERGEэффективной работы вы захотите создать ограничение на вашем графике, например так:
CREATE CONSTRAINT ON (w:Word) ASSERT w.name IS UNIQUE;
Но я хотел морские черты!
Так что я прибавил одно за другим в быстрой последовательности, становясь все счастливее, поскольку я не сталкивался с реальными камнями преткновения.
Я хочу записать частоту следования
Легко, используйте ON CREATE и ON MATCH с MERGE
WITH split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1 ON MATCH SET r.count = r.count +1;Я тоже хочу записать частоты слов
Тот же подход, только обратите внимание, что последнее слово объединяется только вторым утверждением
WITH split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
ON CREATE SET w1.count = 1 ON MATCH SET w1.count = w1.count + 1
MERGE (w2:Word {name:words[idx+1]})
ON CREATE SET w2.count = 1
ON MATCH SET w2.count = w2.count + (case when idx = size(words)-2 then 1 else 0 end)
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1
ON MATCH SET r.count = r.count +1;Я также хочу предложить число и положение слова
Я sidпередаю номер предложения снаружи как позиция «idx»
WITH 1 as sid, split("My phone calls drop frequently with the iPhone"," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
ON CREATE SET w1.count = 1 ON MATCH SET w1.count = w1.count + 1
MERGE (w2:Word {name:words[idx+1]})
ON CREATE SET w2.count = 1
ON MATCH SET w2.count = w2.count + (case when idx = size(words)-2 then 1 else 0 end)
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1, r.pos = [sid,idx]
ON MATCH SET r.count = r.count +1, r.pos = r.pos = [sid,idx];Я хочу, чтобы все слова были в нижнем регистре
Примените tolower () к тексту
WITH "My phone calls drop frequently with the iPhone" as text
WITH split(tolower(text)," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)Я хочу убрать пунктуацию
Просто используйте replace () несколько раз с текстом
with "Great device, but the calls drop too frequently." as text
with replace(replace(tolower(text),".",""),",","") as normalized
with split(normalized," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)Я хочу удалить много знаков препинания
Работа над коллекцией знаков препинания с помощью «уменьшить»
with "Great device, but the calls drop too frequently." as text
with reduce(t=tolower(text), delim in [",",".","!","?",'"',":",";","'","-"] | replace(t,delim,"")) as normalized
with split(normalized," ") as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)Я хочу обрезать пробелы
Используйте trim () с каждым словом коллекции
with "Great device, but the calls drop too frequently." as text
with replace(replace(tolower(text),".",""),",","") as normalized
with [w in split(normalized," ") | trim(w)] as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)Я хочу отфильтровать стоп-слова
Отфильтруйте слова после разбиения и обрезки, сравнив коллекцию с помощью `IN`
with "Great device, but the calls drop too frequently." as text
with replace(replace(tolower(text),".",""),",","") as normalized
with [w in split(normalized," ") | trim(w)] as words
with [w in words WHERE NOT w IN ["the","an","on"]] as words
UNWIND range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[:NEXT]->(w2)уборка
match (n) optional match (n)-[r]-() delete n,rЯ хочу загрузить текст из файла
LOAD CSV на самом деле не волнует, является ли файл CSV или нет
В качестве входных данных мы используем стихотворение «Властелин колец» « Единого кольца» , находящееся в текстовом файле выпадающего списка .
LOAD CSVзагружает каждую строку как массив строк (если не используется со строкой заголовка), используя предоставленный терминатор поля (запятая по умолчанию).
Если мы выберем точку остановки в качестве ограничителя поля, она фактически разбивается на конце предложения (в основном).
Таким образом, мы можем просто развернуть каждую строку в ее ячейки (фрагменты текста), а затем обработать каждую из них так же, как мы делали фрагмент текста ранее.
Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Nine for Mortal Men doomed to die, One for the Dark Lord on his dark throne In the Land of Mordor where the Shadows lie. One Ring to rule them all, One Ring to find them, One Ring to bring them all and in the darkness bind them In the Land of Mordor where the Shadows lie.
load csv from "https://dl.dropboxusercontent.com/u/14493611/one-ring.txt" as row fieldterminator "."
with row
unwind row as text
with reduce(t=tolower(text), delim in [",",".","!","?",'"',":",";","'","-"] | replace(t,delim,"")) as normalized
with [w in split(normalized," ") | trim(w)] as words
unwind range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[r:NEXT]->(w2)
ON CREATE SET r.count = 1 ON MATCH SET r.count = r.count +1Я хочу глотать действительно большие файлы
Префикс вашего CSV LOAD с ИСПОЛЬЗОВАНИЕМ PERIODIC COMMIT X для фиксации после X строк
using periodic commit 1000
load csv from "https://dl.dropboxusercontent.com/u/14493611/one-ring.txt" as row fieldterminator "."
with row
unwind row as text
with reduce(t=tolower(text), delim in [",",".","!","?",'"',":",";","'","-"] | replace(t,delim,"")) as normalized
with [w in split(normalized," ") | trim(w)] as words
unwind range(0,size(words)-2) as idx
MERGE (w1:Word {name:words[idx]})
MERGE (w2:Word {name:words[idx+1]})
MERGE (w1)-[r:NEXT]->(w2)
Есть много способов, как вы можете использовать данные, либо следовать указаниям Кавиты в своей статье, либо просто свободно играть с графиком, как я делал ниже.
Найти самую важную фразу в тексте легко.
Ищите пути с большим количеством ссылок и вычисляйте оценку общего количества ссылок путей и порядка по ним.
MATCH path = (w:Word)-[:NEXT*..5]->()
WHERE ALL (r IN rels(path) WHERE r.count > 1)
RETURN [w IN nodes(path)| w.name] AS phrase, reduce(sum=0,r IN rels(path)| sum + r.count) as score
ORDER BY score DESC
LIMIT 1|
фраза |
Гол |
|
[один, кольцо, чтобы] |
6 |