В первом посте этой серии мы увидели, как проводить модульное тестирование операций Spark Streaming с использованием Spark Testing Base . Здесь мы увидим, как выполнить интеграционное тестирование с помощью Docker Compose .
Что такое интеграционное тестирование
Ранее мы видели обсуждение модульного и интеграционного тестирования. Опять же, поскольку мы хотим сосредоточить внимание на публикации, мы будем работать с определением интеграционного тестирования, которое содержит следующие характеристики:
- Сетевая интеграция: наш код должен вызывать сеть для интеграции со сторонними зависимостями. Часть наших усилий по тестированию интеграции будет затем проверять поведение нашего кода при наличии сетевых проблем.
- Интеграция фреймворков: фреймворки пытаются создавать предсказуемые и интуитивно понятные API. Однако это не всегда так, и интеграционное тестирование дает нам подтверждение наших предположений.
Что такое Docker Compose
Docker предоставляет легкую и безопасную парадигму для виртуализации. Как следствие, Docker является идеальным кандидатом для установки и утилизации контейнера (процессов) для интеграционного тестирования. Вы можете обернуть свое приложение или внешние зависимости в контейнеры Docker и легко управлять их жизненным циклом.
Организация отношений, порядка выполнения или общих ресурсов группы контейнеров может быть громоздкой и утомительной. Вместо того, чтобы создавать собственные решения с помощью скриптов Bash, мы можем использовать Docker Compose .
Управление жизненным циклом
Управление тем, как и когда процесс должен запускаться, останавливаться или переходить в другие состояния, является частью управления жизненным циклом процесса. Давайте сделаем некоторые соображения об этом управлении при интеграционном тестировании.
- Если процесс дорогостоящий в настройке, с точки зрения времени или пространства, поддержание процесса, запущенного для всего набора тестов, может быть удобным.
- Это может быть проблематично, если процесс находится в состоянии. Если это так, мы должны быть уверены, что данные разделены между тестами, поэтому тесты не будут наступать друг на друга.
- Если изоляция данных становится слишком сложной, мы можем распорядиться процессом, связанным с каждым тестом или логической группой тестов, чтобы быть уверенными, что мы работаем с чистого листа.
- Другой подход — удаление данных, сгенерированных тестом. При удалении данных после теста возникают следующие проблемы: сложнее диагностировать, если тест не пройден, и риск не удалять данные, если тест терпит неудачу катастрофически в середине. Мой предпочтительный подход — удаление данных перед началом каждого теста.
- Убедиться в том, что процесс «ускорился» полностью, сложно. Некоторые процессы могут работать с назначенным PID, но не готовы к приему сообщений, пока не произойдет прогрев. Это значительно усложняет управление, поскольку нет общего решения.
Сопоставление зависимостей тестирования с вашей системой сборки.
В этом посте мы рассмотрим Docker Compose для управления внешними зависимостями. Docker Compose — это легкий способ упаковки приложений, но даже для запуска контейнеров требуется некоторое время (часто это связано со временем запуска самих процессов).
Поэтому мы пойдем с подходом запуска контейнеров один раз для набора тестов.
plugins.sbt
|
1
|
addSbtPlugin("com.tapad" % "sbt-docker-compose" % "1.0.11") |
build.sbt
|
1
2
3
4
5
6
7
8
|
lazy val dockerComposeTag = "DockerComposeTag"enablePlugins(DockerComposePlugin)testOptions in Test += Tests.Argument(TestFrameworks.ScalaTest, "-l", dockerComposeTag), composeFile := baseDirectory.value + "/docker/sbt-docker-compose.yml", testTagsToExecute := dockerComposeTag ) |
Я скопировал наиболее важные фрагменты из нашего примера. Как видите, мы используем библиотеку sbt-docker-compose . Это означает, что мы связываем наши тесты (по крайней мере, их зависимости) с системой сборки ( sbt ). Это может быть проблемой, поскольку мы заблокированы в нашем решении для этого конкретного поставщика сборки, но, как обычно, в каждом техническом решении есть компромисс.
Каждый тест с тегом DockerComposeTag будет выполняться при запуске sbt dockerComposeTest . Эта команда установит и разрушит контейнеры, определенные в sbt-docker-compose.yml :
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
version: '2'services: cassandra: image: cassandra:2.1.14 ports: - "9042:9042" kafka: image: spotify/kafka:latest ports: - "9092:9092" - "2181:2181" environment: ADVERTISED_HOST: localhost # this must match the docker host ip ADVERTISED_PORT: 9092 |
Написание интеграционного теста Spark Streaming
Теперь, когда у нас есть готовая тестовая инфраструктура, мы можем написать наш первый интеграционный тест. Давайте вспомним код, который мы хотим протестировать:
|
1
2
3
4
5
6
7
|
val lines = ingestEventsFromKafka(ssc, brokers, topic).map(_._2)val specialWords = ssc.sparkContext.cassandraTable(keyspace, specialWordsTable) .map(_.getString("word"))countWithSpecialWords(lines, specialWords) .saveToCassandra(keyspace, wordCountTable) |
|
1
2
3
4
5
6
7
8
|
def countWithSpecialWords(lines: DStream[String], specialWords: RDD[String]): DStream[(String, Int)] = { val words = lines.flatMap(_.split(" ")) val bonusWords = words.transform(_.intersection(specialWords)) words.union(bonusWords) .map(word => (word, 1)) .reduceByKey(_ + _)} |
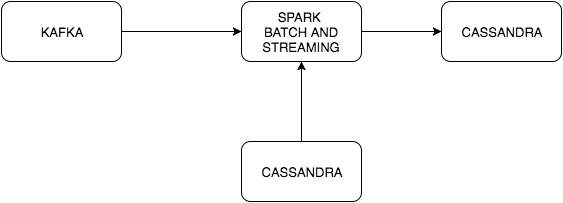
События получены от Kafka, этот поток объединен с таблицей Cassandra, которая содержит специальные слова. Эти события содержат слова, разделенные пробелом, и мы хотим посчитать (если слово появляется дважды) слова в этом потоке. Есть две внешние зависимости, поэтому наш sbt-docker-compose.yml должен будет запустить их для нас.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
class WordCountIT extends WordSpec with BeforeAndAfterEach with Eventually with Matchers with IntegrationPatience { object DockerComposeTag extends Tag("DockerComposeTag") var kafkaProducer: KafkaProducer[String, String] = null val sparkMaster = "local[*]" val cassandraKeySpace = "kafka_streaming" val cassandraWordCountTable = "word_count" val cassandraSpecialWordsTable = "special_words" val zookeeperHostInfo = "localhost:2181" val kafkaTopic = "line_created" val kafkaTopicPartitions = 3 val kafkaBrokers = "localhost:9092" val cassandraHost = "localhost" override protected def beforeEach(): Unit = { val conf = new Properties() conf.put("bootstrap.servers", kafkaBrokers) conf.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") conf.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer") kafkaProducer = new KafkaProducer[String, String](conf) } |
Мы определили тест с WordSpec от ScalaTest . Остальная часть кода в основном является подготовкой к нашему тесту.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
"Word Count" should { "count normal words" taggedAs (DockerComposeTag) in { val sparkConf = new SparkConf() .setAppName("SampleStreaming") .setMaster(sparkMaster) .set(CassandraConnectorConf.ConnectionHostParam.name, cassandraHost) .set(WriteConf.ConsistencyLevelParam.name, ConsistencyLevel.LOCAL_ONE.toString) eventually { CassandraConnector(sparkConf).withSessionDo { session => session.execute(s"DROP KEYSPACE IF EXISTS $cassandraKeySpace") session.execute(s"CREATE KEYSPACE IF NOT EXISTS $cassandraKeySpace WITH REPLICATION = {'class': 'SimpleStrategy', 'replication_factor': 1 };") session.execute( s"""CREATE TABLE IF NOT EXISTS $cassandraKeySpace.$cassandraWordCountTable |(word TEXT PRIMARY KEY, |count COUNTER); """.stripMargin ) session.execute( s"""CREATE TABLE IF NOT EXISTS $cassandraKeySpace.$cassandraSpecialWordsTable |(word TEXT PRIMARY KEY); """.stripMargin ) session.execute(s"TRUNCATE $cassandraKeySpace.$cassandraWordCountTable;") session.execute(s"TRUNCATE $cassandraKeySpace.$cassandraSpecialWordsTable;") } createTopic(zookeeperHostInfo, kafkaTopic, kafkaTopicPartitions) val ssc = new StreamingContext(sparkConf, Seconds(1)) SampleStreaming.start(ssc, kafkaTopic, kafkaTopicPartitions, cassandraHost, kafkaBrokers, cassandraKeySpace, cassandraWordCountTable, cassandraSpecialWordsTable) import ExecutionContext.Implicits.global Future { ssc.awaitTermination() } produceKafkaMessages() eventually { ssc.cassandraTable(cassandraKeySpace, cassandraWordCountTable).cassandraCount shouldEqual 2 } } } } |
Существует много шума, но этот тест в основном делает следующее:
- Настройка Spark Conf. Мы должны сделать это в первую очередь, так как это необходимо для спарк-кассандра-разъем
- Выполнение некоторых DDL и DMLs в Кассандре. Keyspace и таблицы, если они еще не существуют, и усечение таблиц на всякий случай, так что мы можем начать с чистого листа. В этом конкретном примере мы просто хотим подсчитать количество сгенерированных строк, поэтому нам не нужны специальные слова, но было бы легче заполнить эту таблицу данными.
- Мы создаем тему Kafka, которую Spark Streaming будет использовать для получения данных.
|
1
2
3
4
5
6
7
8
|
def createTopic(zookeeperHostInfo: String, topic: String, numPartitions: Int) = { val timeoutMs = 10000 val zkClient = new ZkClient(zookeeperHostInfo, timeoutMs, timeoutMs, ZKStringSerializer) val replicationFactor = 1 val topicConfig = new Properties AdminUtils.createTopic(zkClient, topic, numPartitions, replicationFactor, topicConfig)} |
- Мы запускаем наше приложение для потокового воспроизведения с использованием контекста потокового воспроизведения.
- Теперь, когда наша потоковая передача искры готова к потреблению сообщений, мы публикуем одно сообщение в этой теме Kafka.
|
1
2
3
4
|
def produceKafkaMessages() = { val record = new ProducerRecord[String, String](kafkaTopic, "Hi friend Hi") kafkaProducer.send(record)} |
- Результат этого вычисления будет выглядеть примерно так: Hi -> 2, friend -> 1. Это две строки в таблице «word_count» в Cassandra. И это утверждение, которое мы, наконец, сделаем в нашем тесте (в реальном приложении утверждение было бы более громоздким, но пример просто показывает точку).
Вывод
Даже если кажется, что кода много, большая часть битов для тестирования интеграции приложений потоковой передачи связана с настройкой данных во внешних зависимостях. С этими тестами будет приятно работать, используя правильные абстракции.
В следующем посте мы увидим, как выполнить интеграционное тестирование без Docker Compose, контролируя эти зависимости непосредственно из ScalaTest.
| Ссылка: | Тестирование Spark Streaming: интеграционное тестирование с Docker Compose от нашего партнера по JCG Фелипе Фернандеса в блоге Crafted Software . |