В этой статье я собираюсь предложить свой список «золотых правил» для создания приложений Spring Boot , которые являются частью системы на основе микросервисов. Я основываюсь на своем опыте миграции монолитных приложений SOAP, работающих на серверах JEE, в небольшие приложения на основе REST, созданные на основе Spring Boot. В этом списке рекомендаций предполагается, что вы работаете с множеством микросервисов в условиях огромного входящего трафика. Давайте начнем.
Вам также может понравиться: Spring Boot Microservices: Создание приложения для микросервисов с использованием Spring Boot
Просто удивительно, как визуализация метрик может изменить подход к системному мониторингу в организации. После настройки мониторинга в Grafana мы можем распознать более 90% более серьезных проблем в наших системах, прежде чем они станут репортерами клиентов нашей службы поддержки. Благодаря этим двум мониторам с множеством диаграмм и предупреждений мы можем реагировать намного быстрее, чем раньше.
Если у вас есть микросервисные архитектуры, метрики становятся еще важнее, чем для монолитов.
Хорошей новостью для нас является то, что Spring Boot поставляется со встроенным механизмом сбора наиболее важных показателей. Нам просто нужно установить некоторые свойства конфигурации, чтобы представить предопределенный набор метрик, предоставляемых Spring Boot Actuator. Чтобы использовать его, нам нужно включить Actuator starter в качестве зависимости:
XML
1
<dependency>
2
<groupId> org.springframework.boot</groupId>
3
<artifactId>spring-boot-starter-actuator</artifactId>
4
</dependency>
Чтобы включить конечную точку метрики, мы должны установить свойство management.endpoint.metrics.enabledв true. Теперь вы можете проверить полный список сгенерированных метрик, вызвав конечную точку GET /actuator/metrics.
Одним из наиболее важных показателей для нас является то http.server.requests, что он предоставляет статистику с несколькими входящими запросами и временем ответа. Он автоматически помечается типом метода (POST, GET и т. Д.), Статусом HTTP и URI.
Метрики должны храниться где-то. Самые популярные инструменты для этого — InfluxDB и Prometheus . Они представляют две разные модели сбора данных. Прометей периодически извлекает данные из конечной точки, предоставляемой приложением, в то время как InfluxDB предоставляет REST API, который должен вызываться приложением. Интеграция с этими двумя инструментами и несколькими другими осуществляется с помощью библиотеки Micrometer . Чтобы включить поддержку InfluxDB, мы должны включить следующую зависимость.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>io.micrometer</groupId>
3
<artifactId>micrometer-registry-influx</artifactId>
4
</dependency>
Мы также должны предоставить как минимум URL и имя базы данных Influx внутри application.ymlфайла.
YAML
xxxxxxxxxx
1
management
2
metrics
3
export
4
influx
5
dbspringboot
6
urihttp//192.168.99.1008086
Чтобы включить конечную точку HTTP Prometheus, нам сначала нужно включить соответствующий модуль Micrometer, а также установить свойство management.endpoint.prometheus.enabledв true.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>io.micrometer</groupId>
3
<artifactId>micrometer-registry-prometheus</artifactId>
4
</dependency>
По умолчанию Прометей пытается собирать данные с определенной конечной точки раз в минуту. Остальная часть конфигурации должна быть предоставлена внутри Прометея. scrape_configРаздел отвечает за определение набора целевых показателей и параметров , описывающих , как связаться с ними.
YAML
xxxxxxxxxx
1
scrape_configs
2
job_name'springboot'
3
metrics_path'/actuator/prometheus'
4
static_configs- targets'person-service:2222'
Иногда полезно предоставить дополнительные метки для метрик, особенно если у нас есть много экземпляров одного микросервиса, который регистрирует в одной базе данных Influx. Вот пример тегов для приложений, работающих в Kubernetes.
Джава
x
1
class ConfigurationMetrics {
2
("\${spring.application.name}") lateinit var appName: String
3
("\${NAMESPACE:default}") lateinit var namespace: String
4
("\${HOSTNAME:default}") lateinit var hostname: String
5
fun tags(): MeterRegistryCustomizer<InfluxMeterRegistry> {
6
return MeterRegistryCustomizer { registry -> registry.config().commonTags("appName", appName).commonTags("namespace", namespace).commonTags("pod", hostname)
7
}
8
}
9
}
Вот диаграмма от Grafana, созданная для http.server.requestsметрики одного приложения.
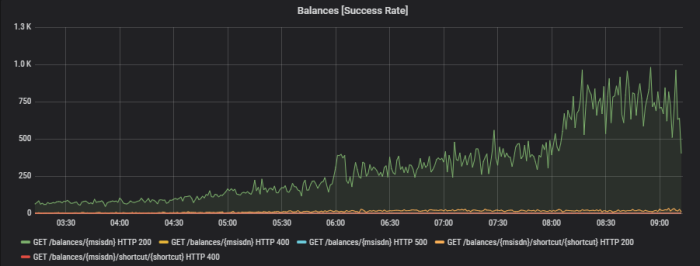
Ведение журнала — это то, что не очень важно во время разработки, но является ключевым моментом при обслуживании. Стоит помнить, что в организации ваше приложение будет рассматриваться через качество журналов. Обычно приложение обслуживается службой поддержки, поэтому ваши журналы должны быть значительными. Не пытайтесь поместить туда все, только самые важные события должны быть зарегистрированы.
Также важно использовать один и тот же стандарт регистрации для всех микросервисов. Например, если вы регистрируете информацию в формате JSON, делайте то же самое для каждого отдельного приложения. Если вы используете тег appNameдля указания имени приложения или instanceIdдля различения разных экземпляров одного и того же приложения, делайте это везде.
Зачем? Обычно вы хотите хранить журналы, собранные со всех микросервисов, в одном центральном месте. Самый популярный инструмент для этого (или, скорее, набор инструментов) — Elastic Stack (ELK). Чтобы воспользоваться преимуществами хранения журналов в одном месте, вы должны убедиться, что критерии запросов и структура ответов будут одинаковыми для всех приложений, особенно если вы будете сопоставлять журналы между различными микросервисами.
Как к этому? Конечно, с помощью внешней библиотеки. Я могу порекомендовать мою библиотеку для ведения журнала Spring Boot. Чтобы использовать его, вы должны включить его в свои зависимости.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>com.github.piomin</groupId>
3
<artifactId>logstash-logging-spring-boot-starter</artifactId>
4
<version>1.2.2.RELEASE</version>
5
</dependency>
Эта библиотека заставит вас использовать некоторые хорошие методы ведения журнала и автоматически интегрируется с Logstash (одним из трех инструментов ELK, отвечающих за сбор журналов). Его основными особенностями являются:
- возможность регистрировать все входящие HTTP-запросы и исходящие HTTP-ответы с полным телом и отправлять эти журналы в Logstash с соответствующими тегами, указывающими имя вызывающего метода или статус HTTP-ответа
- возможность рассчитывать и хранить время выполнения для каждого запроса
- возможность генерировать и распространять ID корреляции для нисходящих сервисов, вызываемых с помощью Spring
RestTemplate
Чтобы включить отправку журналов в Logstash мы должны , по крайней мере , предоставить свой адрес и недвижимость logging.logstash.enabledв true.
YAML
xxxxxxxxxx
1
logging.logstash
2
enabledtrue
3
url192.168.99.1005000
После включения библиотеки logstash-logging-spring-boot-starterвы можете воспользоваться тегами журналов в Logstash. Вот экран из Kibana для записи в журнале ответов.
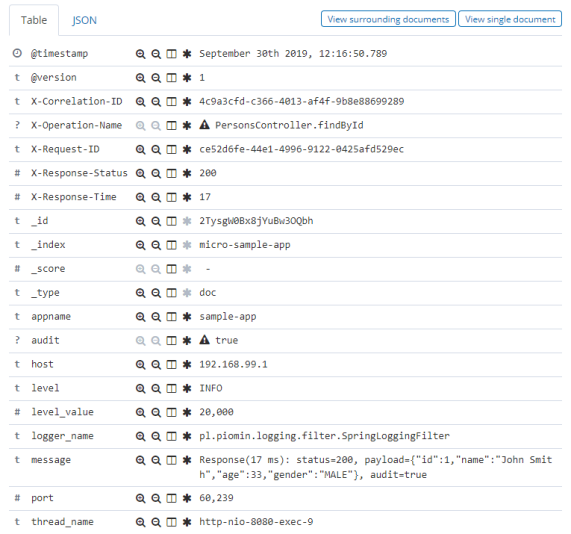
Мы также можем включить библиотеку Spring Cloud Sleuth в наши зависимости.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>org.springframework.cloud</groupId>
3
<artifactId>spring-cloud-starter-sleuth</artifactId>
4
</dependency>
Spring Cloud Sleuth распространяет заголовки, совместимые с Zipkin — популярным инструментом для распределенной трассировки. Его основными особенностями являются:
- Он добавляет трассировку (корреляцию запросов) и идентификаторы диапазонов в Slf4J MDC.
- Он записывает информацию о времени, чтобы помочь в анализе задержки.
- Он изменяет шаблон записи журнала, чтобы добавить некоторую информацию, например, дополнительные поля MDC.
- Он обеспечивает интеграцию с другими компонентами Spring, такими как OpenFeign, RestTemplate или Spring Cloud Netflix Zuul.
В большинстве случаев ваше приложение будет вызываться другими приложениями через API на основе REST. Поэтому стоит позаботиться о правильной и понятной документации. Документация должна быть сгенерирована вместе с кодом. Конечно, для этого есть несколько инструментов. Одним из самых популярных из них является Swagger .
Вы можете легко интегрировать Swagger 2 с приложением Spring Boot, используя проект SpringFox . Чтобы предоставить HTML-сайт Swagger с документацией API, нам необходимо включить следующие зависимости.
Первая библиотека отвечает за генерацию дескриптора Swagger из кода контроллеров Spring MVC, а вторая встраивает Swagger UI для отображения представления дескриптора Swagger YAML в вашем веб-браузере.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>io.springfox</groupId>
3
<artifactId>springfox-swagger2</artifactId>
4
<version>2.9.2</version>
5
</dependency>
6
<dependency>
7
<groupId>io.springfox</groupId>
8
<artifactId>springfox-swagger-ui</artifactId>
9
<version>2.9.2</version>
10
</dependency>
Это не все. Мы также должны предоставить некоторые bean-компоненты для настройки поведения генерации Swagger по умолчанию. Он должен документировать только методы, реализованные внутри наших контроллеров, например, а не методы, предоставляемые Spring Boot автоматически, такие как /actuator/*конечные точки. Мы также можем настроить внешний вид пользовательского интерфейса, определив UiConfigurationbean.
Джава
x
1
2
3
public class ConfigurationSwagger {
4
Optional<BuildProperties> build;
5
public Docket api() {
6
String version = "1.0.0";
7
if (build.isPresent())
8
version = build.get().getVersion();
9
return new Docket(DocumentationType.SWAGGER_2)
10
.apiInfo(apiInfo(version))
11
.select()
12
.apis(RequestHandlerSelectors.any())
13
.paths(PathSelectors.regex
14
("(/components.*)"))
15
.build()
16
.useDefaultResponseMessages(false)
17
.forCodeGeneration(true); }
18
public UiConfiguration uiConfig() {
19
return UiConfigurationBuilder.builder()
20
.docExpansion(DocExpansion.LIST)
21
.build(); }
22
private ApiInfo apiInfo(String version) {
23
return new ApiInfoBuilder()
24
.title("API - Components Service")
25
.description("Managing Components.")
26
.version(version) .build();
27
}
28
}
Вот пример Swagger 2 UI для одного микросервиса.
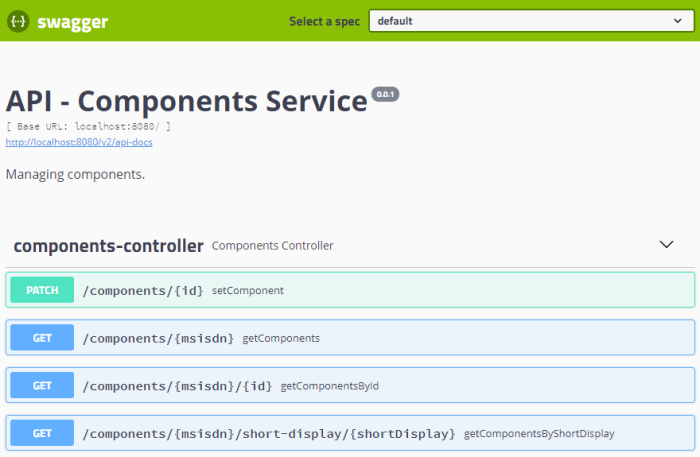
Следующий случай — определить одно и то же руководство по API REST для всех микросервисов. Если вы последовательно строите API-интерфейс ваших микросервисов, его гораздо проще интегрировать как для внешних, так и для внутренних клиентов. Руководство должно содержать инструкции о том, как создать свой API, какие заголовки необходимо установить в запросе и ответе, как генерировать коды ошибок и т. Д.
Такой рекомендацией следует поделиться со всеми разработчиками и поставщиками в вашей организации. Для более подробного объяснения создания документации Swagger для микросервисов Spring Boot, включая ее представление для всех приложений на API-шлюзе, вы можете обратиться к моей статье Документация по API Microservices с Swagger2 .
Если вы используете Spring Cloud для связи между микросервисами, вы можете использовать Spring Cloud Netflix Hystrix или Spring Cloud Circuit Breaker для реализации прерывания цепи. Однако первое решение уже переведено в режим обслуживания командой Pivotal, поскольку Netflix больше не разрабатывает Hystrix. Рекомендуемое решение — новый выключатель Spring Cloud, созданный на основе проекта resilience4j .
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>org.springframework.cloud</groupId>
3
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId> </dependency>
Затем нам нужно настроить требуемые параметры для автоматического выключателя, определив Customizerкомпонент, которому передается a Resilience4JCircuitBreakerFactory. Мы используем значения по умолчанию, как показано.
Джава
xxxxxxxxxx
1
2
public Customizer<Resilience4JCircuitBreakerFactory> defaultCustomizer() {
3
return factory -> factory.configureDefault(id -> new Resilience4JConfigBuilder(id)
4
.timeLimiterConfig(TimeLimiterConfig.custom()
5
.timeoutDuration(Duration.ofSeconds(5)).build()) .circuitBreakerConfig(CircuitBreakerConfig.ofDefaults())
6
.build());
7
}
Не следует забывать, что одной из важнейших причин перехода на архитектуру микросервисов является требование непрерывной доставки . Сегодня способность быстро доставлять изменения дает преимущество на рынке. Вы должны быть в состоянии даже внести изменения несколько раз в течение дня.
Поэтому важно, какая у вас текущая версия, где она была выпущена и какие изменения в нее включены.
При работе с Spring Boot и Maven мы можем легко публиковать такую информацию, как дата последних изменений, Git коммитов id или многочисленные версии приложения. Чтобы достичь этого, нам просто нужно включить следующие плагины Maven в наш pom.xml.
XML
xxxxxxxxxx
1
<plugins>
2
<plugin>
3
<groupId>org.springframework.boot</groupId>
4
<artifactId>spring-boot-maven-plugin</artifactId>
5
<executions>
6
<execution>
7
<goals>
8
<goal>build-info</goal>
9
</goals>
10
</execution>
11
</executions>
12
</plugin>
13
<plugin>
14
<groupId>pl.project13.maven</groupId>
15
<artifactId>git-commit-id-plugin</artifactId>
16
<configuration>
17
<failOnNoGitDirectory>false</failOnNoGitDirectory>
18
</configuration>
19
</plugin>
20
</plugins>
Предполагая, что вы уже включили Spring Boot Actuator (см. Раздел 1), вы должны разрешить /infoконечной точке отображать все интересные данные.
management.endpoint.info.enabled: true
Конечно, у нас есть много микросервисов, состоящих из нашей системы, и есть несколько запущенных экземпляров каждого микросервиса. Желательно отслеживать наши экземпляры в едином центральном месте — так же, как при сборе метрик и журналов.
К счастью, есть инструмент, предназначенный для приложения Spring Boot, который может собирать данные со всех конечных точек Actuator и отображать их в пользовательском интерфейсе. Это Spring Boot Admin, разработанный Codecentric. Наиболее удобный способ его запуска — создание специального приложения Spring Boot, которое включает в себя зависимости Spring Boot Admin и интегрируется с сервером обнаружения, например Spring Cloud Netflix Eureka.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>de.codecentric</groupId>
3
<artifactId>spring-boot-admin-starter-server</artifactId>
4
<version>2.1.6</version>
5
</dependency>
6
<dependency>
7
<groupId>org.springframework.cloud</groupId>
8
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
9
</dependency>
Затем мы должны включить его для приложения Spring Boot, пометив основной класс с помощью @EnableAdminServer.
Джава
x
1
2
3
4
5
public class Application {
6
public static void main(String[] args) {
7
SpringApplication.run(Application.class, args);
8
}
9
}
С помощью Spring Boot Admin мы можем легко просматривать список приложений, зарегистрированных на сервере обнаружения, и проверять версию или информацию о коммите для каждого из них.
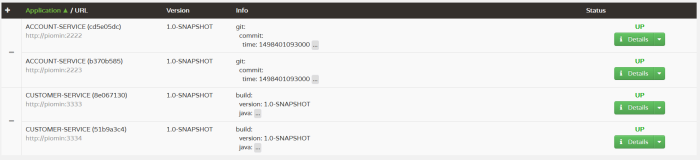
Мы можем расширить детали, чтобы увидеть все элементы, полученные из /infoконечной точки, и гораздо больше данных, собранных с других конечных точек привода.
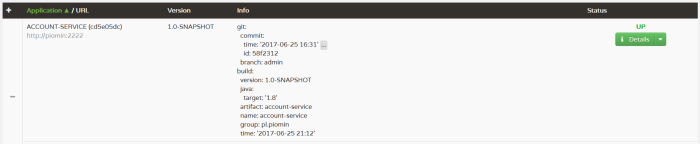
Тестирование по договору с потребителем ( CDC ) является одним из методов, позволяющих проверить интеграцию между приложениями в вашей системе. Количество таких взаимодействий может быть очень большим, особенно если вы поддерживаете архитектуру на основе микросервисов.
Начать с тестирования по контракту в Spring Boot относительно легко благодаря проекту Spring Cloud Contract . Есть некоторые другие фреймворки, разработанные специально для CDC, такие как Pact, но Spring Cloud Contract, вероятно, будет первым выбором, так как мы используем Spring Boot.
Чтобы использовать его на стороне производителя, нам нужно включить Spring Cloud Contract Verifier.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>org.springframework.cloud</groupId>
3
<artifactId>spring-cloud-starter-contract-verifier</artifactId>
4
<scope>test</scope>
5
</dependency>
На стороне потребителя мы должны включить Spring Cloud Contract Stub Runner.
XML
xxxxxxxxxx
1
<dependency>
2
<groupId>org.springframework.cloud</groupId>
3
<artifactId>spring-cloud-starter-contract-stub-runner</artifactId>
4
<scope>test</scope>
5
</dependency>
Первый шаг — определить контракт. Один из вариантов написать это — использовать язык Groovy. Контракт должен быть проверен как на стороне производителя, так и на стороне потребителя. Вот
Джава
x
1
import org.springframework.cloud.contract.spec.Contract
2
Contract.make
3
{ request
4
{ method 'GET' urlPath
5
('/persons/1') } response
6
{ status OK() body(
7
[ id: 1,
8
firstName: 'John',
9
lastName: 'Smith',
10
address:
11
([ city: $(regex(alphaNumeric())),
12
country: $(regex(alphaNumeric())),
13
postalCode: $(regex('[0-9]{2}-[0-9]{3}')),
14
houseNo: $(regex(positiveInt())),
15
street: $(regex(nonEmpty())) ]) ])
16
headers { contentType(applicationJson()) } } }
Контракт упакован внутри JAR вместе с заглушками. Он может быть опубликован в менеджере репозитория, таком как Artifactory или Nexus, и затем потребители могут загрузить его оттуда во время теста JUnit. Сгенерированный файл JAR имеет суффикс stubs.
Джава
xxxxxxxxxx
1
(SpringRunner.class) (webEnvironment =
2
WebEnvironment.NONE)
3
(ids = {"pl.piomin.services:person-
4
service:+:stubs:8090"}, consumerName = "letter-consumer", stubsPerConsumer =
5
true, stubsMode = StubsMode.REMOTE, repositoryRoot =
6
"http://192.168.99.100:8081/artifactory/libs-snapshot-local")
7
public class PersonConsumerContractTest {
8
private PersonClient personClient; public void verifyPerson() {
9
Person p = personClient.findPersonById(1); Assert.assertNotNull(p);
10
Assert.assertEquals(1, p.getId().intValue());
11
Assert.assertNotNull(p.getFirstName());
12
Assert.assertNotNull(p.getLastName());
13
Assert.assertNotNull(p.getAddress());
14
Assert.assertNotNull(p.getAddress().getCity());
15
Assert.assertNotNull(p.getAddress().getCountry());
16
Assert.assertNotNull(p.getAddress().getPostalCode());
17
Assert.assertNotNull(p.getAddress().getStreet());
18
Assert.assertNotEquals(0, p.getAddress().getHouseNo()); } }
Контрактное тестирование не будет проверять сложные варианты использования в вашей системе на основе микросервисов. Однако это первый этап тестирования взаимодействия между микросервисами. Убедившись, что контракты API между приложениями действительны, вы переходите к более сложной интеграции или сквозным тестам.
Spring Boot и Spring Cloud относительно часто выпускают новые версии своих фреймворков. Предполагая, что ваши микросервисы имеют небольшую кодовую базу, легко использовать версию используемых библиотек. Spring Cloud выпускает новые версии проектов с использованием шаблона выпуска, чтобы упростить управление зависимостями и избежать проблем с конфликтами между несовместимыми версиями библиотек.
Более того, Spring Boot систематически улучшает время запуска и объем памяти приложений, поэтому стоит обновить его именно из-за этого. Вот текущая стабильная версия Spring Boot и Spring Cloud.
XML
xxxxxxxxxx
1
<parent>
2
<groupId>org.springframework.boot</groupId>
3
<artifactId>spring-boot-starter-parent</artifactId>
4
<version>2.2.1.RELEASE</version>
5
</parent>
6
<dependencyManagement>
7
<dependencies>
8
<dependency>
9
<groupId>org.springframework.cloud</groupId>
10
<artifactId>spring-cloud-dependencies</artifactId>
11
<version>Hoxton.RELEASE</version>
12
<type>pom</type>
13
<scope>import</scope>
14
</dependency>
15
</dependencies>
16
</dependencyManagement>
Я показал вам, что нетрудно следовать рекомендациям с функциями Spring Boot и некоторыми дополнительными библиотеками, входящими в Spring Cloud. Эти рекомендации помогут вам перейти на архитектуру на основе микросервисов, а также запускать ваши приложения в контейнерах.
Дальнейшее чтение
Краткое руководство по микросервисам с Spring Boot 2.0, Eureka и Spring Cloud
Микросервисы с использованием Spring Boot и Spring Cloud. Часть 1. Обзор