В моем блоге много статей о микросервисах с Spring Boot и Spring Cloud ( https://piotrminkowski.wordpress.com/?s=microservices ). Основная цель этой статьи — предоставить краткое описание наиболее важных компонентов, предоставляемых этими платформами, которые помогут вам в создании микросервисов. Темы, рассматриваемые в этой статье:
- Использование Spring Boot 2.0 в облачной разработке
- Обеспечение обнаружения сервисов для всех микросервисов с Spring Cloud Netflix Eureka
- Распределенная конфигурация с Spring Cloud Config
- Шаблон API Gateway с использованием нового проекта в Spring Cloud: Spring Cloud Gateway
- Корреляция журналов с помощью Spring Cloud Sleuth
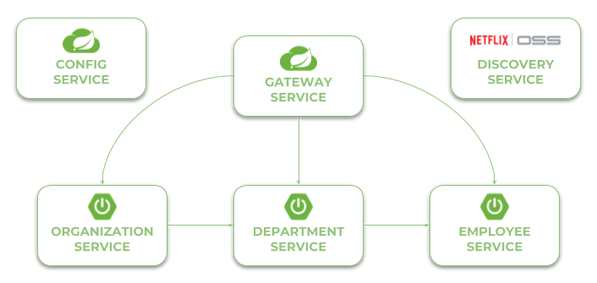
Прежде чем мы перейдем к исходному коду, давайте взглянем на следующую диаграмму. Это иллюстрирует архитектуру нашей системы образцов. У нас есть три независимых микросервиса, которые регистрируют себя в сервисе обнаружения, выбирают свойства из сервиса конфигурации и общаются друг с другом. Вся система скрыта за шлюзом API.
В настоящее время самая новая версия Spring Cloud Finchley.M9. Эта версия spring-cloud-dependenciesдолжна быть объявлена как спецификация для управления зависимостями.
<?xml version="1.0" encoding="UTF-8"?>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Finchley.M9</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>Теперь давайте рассмотрим дальнейшие шаги, которые необходимо предпринять для создания работающей системы на основе микросервисов с использованием Spring Cloud. Мы начнем с сервера конфигурации .
Исходный код примеров приложений, представленных в этой статье, доступен в этом репозитории GitHub .
Шаг 1. Создание сервера конфигурации с помощью Spring Cloud Config
Чтобы включить функцию Spring Cloud Config для приложения, сначала включите spring-cloud-config-serverв свой проект зависимости.
<?xml version="1.0" encoding="UTF-8"?>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>Затем включите запуск встроенного сервера конфигурации во время загрузки приложения с помощью @EnableConfigServerаннотации.
@SpringBootApplication
@EnableConfigServer
public class ConfigApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(ConfigApplication.class).run(args);
}
}По умолчанию Spring Cloud Config Server хранит данные конфигурации в репозитории Git. Это очень хороший выбор в рабочем режиме, но для примера серверной файловой системы этого будет достаточно. Это действительно легко начать с сервера конфигурации, потому что мы можем поместить все свойства в classpath. Spring Cloud Config по умолчанию поиск источников собственности внутри следующих местах: classpath:/, classpath:/config, file:./, file:./config.
Мы размещаем все источники собственности внутри src/main/resources/config. Имя файла YAML будет таким же, как имя службы. Например, файл YAML для открытия-службы будет располагаться здесь: src/main/resources/config/discovery-service.yml.
Две последние важные вещи. Если вы хотите запустить сервер конфигурации с бэкэндом файловой системы, вам нужно активировать собственный профиль Spring Boot. Это может быть достигнуто установкой параметра --spring.profiles.active=nativeво время загрузки приложения. Я также изменил порт сервера конфигурации по умолчанию (8888) на 8061 , установив свойство server.portв bootstrap.ymlфайле.
Шаг 2. Создание службы обнаружения с помощью Spring Cloud Netflix Eureka
Более подробно о настройке сервера. Теперь всем другим приложениям, включая discovery-service, необходимо добавить spring-cloud-starter-configзависимость, чтобы включить клиент конфигурации. Мы также должны добавить зависимость spring-cloud-starter-netflix-eureka-server.
<?xml version="1.0" encoding="UTF-8"?>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>Затем вы должны включить запуск встроенного сервера обнаружения во время загрузки приложения, установив @EnableEurekaServerаннотацию для основного класса.
@SpringBootApplication
@EnableEurekaServer
public class DiscoveryApplication {
public static void main(String[] args) {
new SpringApplicationBuilder(DiscoveryApplication.class).run(args);
}
}Приложение должно получить источник свойства с сервера конфигурации. Минимальная конфигурация, необходимая на стороне клиента, — это имя приложения и параметры подключения сервера конфигурации.
spring:
application:
name: discovery-service
cloud:
config:
uri: http://localhost:8088Как я уже упоминал, файл конфигурации discovery-service.ymlдолжен быть размещен внутри config-serviceмодуля. Тем не менее, я должен сказать несколько слов о конфигурации, видимой ниже. Мы изменили рабочий порт Eureka со значения по умолчанию (8761) на 8061 . Для автономного экземпляра Eureka мы должны отключить регистрацию и загрузку реестра.
server:
port: 8061
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/Теперь, когда вы запускаете приложение со встроенным сервером Eureka, вы должны увидеть следующие журналы.

После успешного запуска приложения вы можете посетить панель инструментов Eureka, доступную по адресу http: // localhost: 8061 / .
Шаг 3. Построение микросервиса с использованием Spring Boot и Spring Cloud
Наш микросервис должен выполнить некоторые операции во время загрузки. Необходимо получить конфигурацию config-service, зарегистрироваться в discovery-service, предоставить HTTP API и автоматически сгенерировать документацию API. Чтобы включить все эти механизмы, нам нужно включить некоторые зависимости в pom.xml. Чтобы включить клиент конфигурации, мы должны включить стартер spring-cloud-starter-config. Клиент обнаружения будет включен для микросервиса после включения spring-cloud-starter-netflix-eureka-clientи аннотирования основного класса с помощью @EnableDiscoveryClient. Чтобы заставить приложение Spring Boot генерировать документацию по API, мы должны включить springfox-swagger2зависимость и добавить аннотацию @EnableSwagger2.
Вот полный список зависимостей, определенных для моего примера микросервиса:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.8.0</version>
</dependency>А вот основной класс приложения, которое включает Discovery Client и Swagger2 для микросервиса:
@SpringBootApplication
@EnableDiscoveryClient
@EnableSwagger2
public class EmployeeApplication {
public static void main(String[] args) {
SpringApplication.run(EmployeeApplication.class, args);
}
@Bean
public Docket swaggerApi() {
return new Docket(DocumentationType.SWAGGER_2)
.select()
.apis(RequestHandlerSelectors.basePackage("pl.piomin.services.employee.controller"))
.paths(PathSelectors.any())
.build()
.apiInfo(new ApiInfoBuilder().version("1.0").title("Employee API").description("Documentation Employee API v1.0").build());
}
...
}Прикладная программа должна получать конфигурацию с удаленного сервера, поэтому мы должны предоставить только bootstrap.ymlфайл с именем службы и URL-адрес сервера. Фактически, это пример подхода Config First Bootstrap , когда приложение сначала подключается к серверу конфигурации и получает адрес сервера обнаружения из удаленного источника свойств. Существует также Discovery First Bootstrap , где адрес сервера конфигурации выбирается с сервера обнаружения.
spring:
application:
name: employee-service
cloud:
config:
uri: http://localhost:8088Там не так много настроек конфигурации. Вот файл конфигурации приложения, хранящийся на удаленном сервере. Он хранит только HTTP-порт и Eureka URL. Однако я также разместил файл employee-service-instance2.ymlна удаленном сервере конфигурации. Он устанавливает другой порт HTTP для приложения, поэтому вы можете легко запустить два экземпляра одной и той же службы локально на основе удаленных свойств. Теперь вы можете запустить второй экземпляр employee-serviceна порту 9090 после передачи аргумента spring.profiles.active=instance2во время запуска приложения. С настройками по умолчанию вы запустите микросервис на порту 8090 .
server:
port: 9090
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8061/eureka/Вот код с реализацией класса контроллера REST. Он обеспечивает реализацию для добавления новых сотрудников и поиска сотрудников с использованием различных фильтров.
@RestController
public class EmployeeController {
private static final Logger LOGGER = LoggerFactory.getLogger(EmployeeController.class);
@Autowired
EmployeeRepository repository;
@PostMapping
public Employee add(@RequestBody Employee employee) {
LOGGER.info("Employee add: {}", employee);
return repository.add(employee);
}
@GetMapping("/{id}")
public Employee findById(@PathVariable("id") Long id) {
LOGGER.info("Employee find: id={}", id);
return repository.findById(id);
}
@GetMapping
public List findAll() {
LOGGER.info("Employee find");
return repository.findAll();
}
@GetMapping("/department/{departmentId}")
public List findByDepartment(@PathVariable("departmentId") Long departmentId) {
LOGGER.info("Employee find: departmentId={}", departmentId);
return repository.findByDepartment(departmentId);
}
@GetMapping("/organization/{organizationId}")
public List findByOrganization(@PathVariable("organizationId") Long organizationId) {
LOGGER.info("Employee find: organizationId={}", organizationId);
return repository.findByOrganization(organizationId);
}
}Шаг 4. Связь между микросервисами с помощью Spring Cloud Open Feign
Наш первый микросервис был создан и запущен. Теперь мы добавим другие микросервисы, которые общаются друг с другом. Следующая диаграмма иллюстрирует поток связи между три образцом microservices: organization-service, department-serviceи employee-service. Микросервис organization-serviceсобирает список отделов с ( GET /organization/{organizationId}/with-employees)или без сотрудников ( GET /organization/{organizationId}) от department-serviceи список сотрудников, не разделяя их на разные отделы напрямую employee-service. Микросервис department-serviceможет собирать список сотрудников, назначенных конкретному отделу.
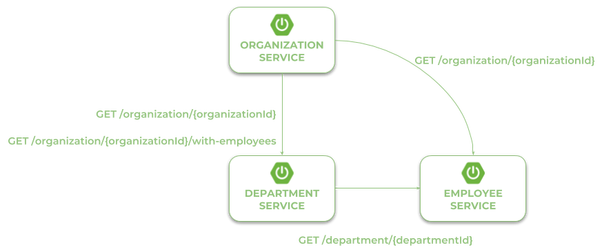
В описанном выше сценарии оба organization-serviceи department-serviceдолжны локализовать другие микросервисы и общаться с ними. Вот почему нам нужно включить дополнительную зависимость для этих модулей: spring-cloud-starter-openfeign. Spring Cloud Open Feign — это декларативный клиент REST, который использует балансировщик нагрузки на стороне клиента для связи с другими микросервисами.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>Альтернативным решением для Open Feign является Spring RestTemplatewith @LoadBalanced. Однако Feign предлагает более элегантный способ определения клиентов, поэтому я предпочитаю его вместо RestTemplate. После включения требуемой зависимости мы также должны включить клиентов Feign, используя @EnableFeignClientsаннотацию.
@SpringBootApplication
@EnableDiscoveryClient
@EnableFeignClients
@EnableSwagger2
public class OrganizationApplication {
public static void main(String[] args) {
SpringApplication.run(OrganizationApplication.class, args);
}
...
}Теперь нам нужно определить интерфейсы клиента. Поскольку organization-serviceсвязывается с двумя другими микросервисами, мы должны создать два интерфейса, по одному на каждый микросервис. Интерфейс каждого клиента должен быть аннотирован @FeignClient. Одно поле в аннотации обязательно для заполнения name. Это имя должно совпадать с именем целевой службы, зарегистрированной при обнаружении службы. Вот интерфейс клиента, который вызывает конечную точку, GET /organization/{organizationId}предоставляемую employee-service.
@FeignClient(name = "employee-service")
public interface EmployeeClient {
@GetMapping("/organization/{organizationId}")
List findByOrganization(@PathVariable("organizationId") Long organizationId);
}Интерфейс второго клиента, доступный внутри, organization-serviceвызывает две конечные точки из department-service. Первый из них GET /organization/{organizationId}возвращает организацию только со списком доступных отделов, а второй GET /organization/{organizationId}/with-employeesвозвращает тот же набор данных, включая список сотрудников, назначенных каждому отделу.
@FeignClient(name = "department-service")
public interface DepartmentClient {
@GetMapping("/organization/{organizationId}")
public List findByOrganization(@PathVariable("organizationId") Long organizationId);
@GetMapping("/organization/{organizationId}/with-employees")
public List findByOrganizationWithEmployees(@PathVariable("organizationId") Long organizationId);
}Наконец, мы должны ввести bean-компоненты клиента Feign в контроллер REST. Теперь мы можем вызывать методы, определенные внутри DepartmentClientи EmployeeClient, что эквивалентно вызову конечных точек REST.
@RestController
public class OrganizationController {
private static final Logger LOGGER = LoggerFactory.getLogger(OrganizationController.class);
@Autowired
OrganizationRepository repository;
@Autowired
DepartmentClient departmentClient;
@Autowired
EmployeeClient employeeClient;
...
@GetMapping("/{id}")
public Organization findById(@PathVariable("id") Long id) {
LOGGER.info("Organization find: id={}", id);
return repository.findById(id);
}
@GetMapping("/{id}/with-departments")
public Organization findByIdWithDepartments(@PathVariable("id") Long id) {
LOGGER.info("Organization find: id={}", id);
Organization organization = repository.findById(id);
organization.setDepartments(departmentClient.findByOrganization(organization.getId()));
return organization;
}
@GetMapping("/{id}/with-departments-and-employees")
public Organization findByIdWithDepartmentsAndEmployees(@PathVariable("id") Long id) {
LOGGER.info("Organization find: id={}", id);
Organization organization = repository.findById(id);
organization.setDepartments(departmentClient.findByOrganizationWithEmployees(organization.getId()));
return organization;
}
@GetMapping("/{id}/with-employees")
public Organization findByIdWithEmployees(@PathVariable("id") Long id) {
LOGGER.info("Organization find: id={}", id);
Organization organization = repository.findById(id);
organization.setEmployees(employeeClient.findByOrganization(organization.getId()));
return organization;
}
}Шаг 5. Создание API-шлюза с использованием Spring Cloud Gateway
Spring Cloud Gateway — это относительно новый проект Spring Cloud. Он построен на основе Spring Framework 5, Project Reactor и Spring Boot 2.0. Для этого требуется среда выполнения Netty, предоставляемая Spring Boot и Spring Webflux. Это действительно хорошая альтернатива Spring Cloud Netflix Zuul, который до сих пор был единственным проектом Spring Cloud, предоставляющим шлюзы API для микросервисов.
Шлюз API реализован внутри модуля gateway-service. Во-первых, мы должны включить стартер spring-cloud-starter-gatewayв зависимости проекта.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>Нам также нужно включить клиент обнаружения, поскольку он gateway-serviceинтегрируется с Eureka, чтобы иметь возможность выполнять маршрутизацию к последующим сервисам. Шлюз также будет предоставлять спецификации API всех конечных точек, предоставляемых нашими примерами микросервисов. Вот почему мы также включили Swagger2 на шлюзе.
@SpringBootApplication
@EnableDiscoveryClient
@EnableSwagger2
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}Spring Cloud Gateway предоставляет три основных компонента, используемых для настройки: маршруты, предикаты и фильтры. Маршрут является основным строительным блоком шлюза. Он содержит целевой URI и список определенных предикатов и фильтров. Предикат несет ответственность за соответствие на что — либо из запроса входящего HTTP, такие как заголовки или параметры. Фильтр может изменить запрос и ответ до и после отправки его вниз по течению услуг. Все эти компоненты могут быть установлены с использованием свойств конфигурации. Мы создадим и поместим его в файл сервера конфигурации gateway-service.yml с маршрутами, определенными для наших примеров микросервисов.
Но сначала мы должны включить интеграцию с сервером обнаружения для маршрутов, установив для свойства spring.cloud.gateway.discovery.locator.enabledзначение true. Затем мы можем приступить к определению правил маршрута. Мы используем Factory Predicate Path Route для сопоставления входящих запросов и RewritePath GatewayFilter Factory для изменения запрошенного пути, чтобы адаптировать его к формату, предоставляемому последующими сервисами. Параметр URI указывает имя целевой службы, зарегистрированной на сервере обнаружения. Давайте посмотрим на следующее определение маршрутов. Например, чтобы сделать organization-serviceдоступным на шлюзе под путем /organization/**, мы должны определить предикат Path=/organization/**, а затем удалить префикс /organizationиз пути, потому что целевая служба предоставляется по пути/**, Адрес целевой службы выбирается для Eureka на основе значения URI lb://organization-service.
spring:
cloud:
gateway:
discovery:
locator:
enabled: true
routes:
- id: employee-service
uri: lb://employee-service
predicates:
- Path=/employee/**
filters:
- RewritePath=/employee/(?<path>.*), /$\{path}
- id: department-service
uri: lb://department-service
predicates:
- Path=/department/**
filters:
- RewritePath=/department/(?<path>.*), /$\{path}
- id: organization-service
uri: lb://organization-service
predicates:
- Path=/organization/**
filters:
- RewritePath=/organization/(?<path>.*), /$\{path}Шаг 6. Включение спецификации API на шлюзе с помощью Swagger2
Каждый микросервис Spring Boot, на котором есть примечание, @EnableSwagger2предоставляет документацию Swagger API по пути /v2/api-docs. Однако нам бы хотелось, чтобы эта документация находилась в одном месте — на шлюзе API. Чтобы достичь этого, нам нужно предоставить компонент, реализующий SwaggerResourcesProviderинтерфейс внутри gateway-serviceмодуля. Этот компонент отвечает за определение местоположения списка ресурсов Swagger, которые должны отображаться приложением. Вот реализация, SwaggerResourcesProviderкоторая берет необходимые местоположения из обнаружения службы на основе свойств конфигурации Spring Cloud Gateway.
К сожалению, SpringFox Swagger по-прежнему не обеспечивает поддержку Spring WebFlux. Это означает, что если вы включите в проект зависимости SpringFox Swagger, приложение не запустится … Я надеюсь, что поддержка WebFlux будет доступна в ближайшее время, но теперь мы должны использовать Spring Cloud Netflix Zuul в качестве шлюза, если мы хотим запустить встроенный Swagger2 на нем.
Я создал модуль, proxy-serviceкоторый является альтернативным API-шлюзом на основе Netflix Zuul на gateway-serviceоснове Spring Cloud Gateway. Вот бин с реализацией SwaggerResourcesProvider, доступной внутри proxy-service. Он использует ZuulPropertiesкомпонент для динамической загрузки определений маршрутов в компонент.
@Configuration
public class ProxyApi {
@Autowired
ZuulProperties properties;
@Primary
@Bean
public SwaggerResourcesProvider swaggerResourcesProvider() {
return () -> {
List resources = new ArrayList();
properties.getRoutes().values().stream()
.forEach(route -> resources.add(createResource(route.getServiceId(), route.getId(), "2.0")));
return resources;
};
}
private SwaggerResource createResource(String name, String location, String version) {
SwaggerResource swaggerResource = new SwaggerResource();
swaggerResource.setName(name);
swaggerResource.setLocation("/" + location + "/v2/api-docs");
swaggerResource.setSwaggerVersion(version);
return swaggerResource;
}
}Вот пользовательский интерфейс Swagger для нашего примера системы микросервисов, доступный по адресу http: // localhost: 8060 / swagger-ui.html .
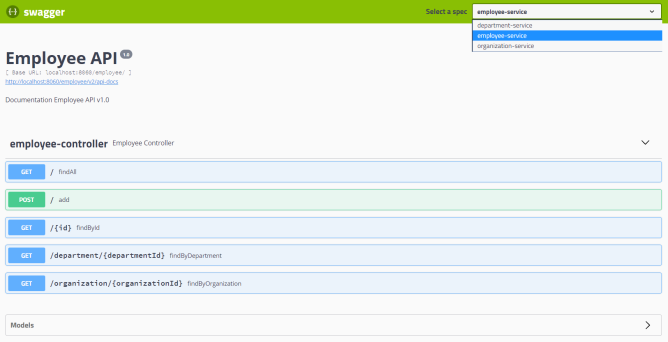
Шаг 7. Запуск приложений
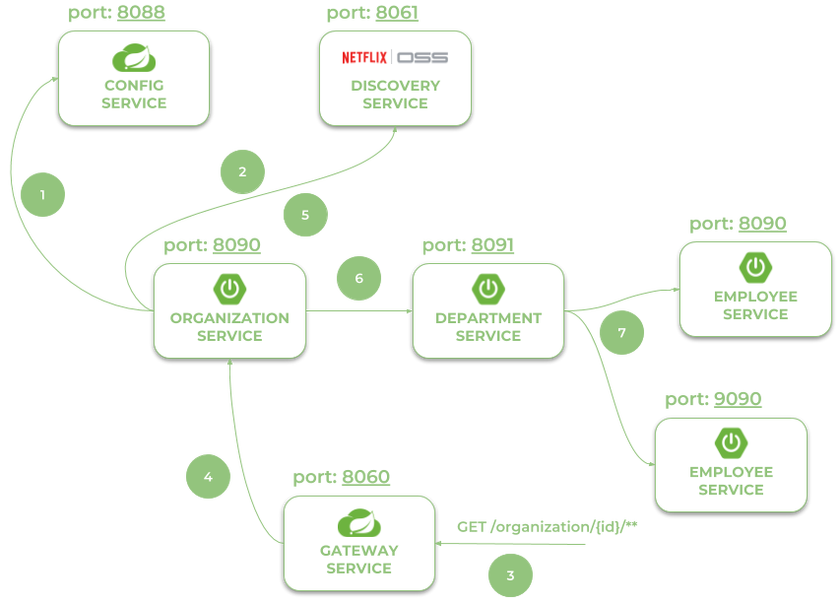
Давайте посмотрим на архитектуру нашей системы, показанную на следующей диаграмме. Мы обсудим это с organization-serviceточки зрения. После запуска organization-serviceподключается к config-serviceдоступному по адресу localhost: 8088 (1) . Основываясь на настройках удаленной конфигурации, он может зарегистрироваться в Eureka (2) . Когда конечная точка organization-serviceвызывается внешним клиентом через шлюз (3), доступный по адресу localhost: 8060, запрос перенаправляется в экземпляр на organization-serviceоснове записей из обнаружения службы (4) . Затем organization-serviceищем адрес department-serviceв Eureka (5) и вызываем его конечную точку (6) . В заключение, department-serviceвызывает конечную точку из employee-service. Запрос сбалансирован между двумя доступными экземплярами с employee-serviceпомощью ленты (7) .
Давайте посмотрим на панель инструментов Eureka, доступную по адресу http: // localhost: 8061 . Есть четыре экземпляра microservices зарегистрированного там: один экземпляр organization-serviceи department-service, и два экземпляра employee-service.

Теперь давайте назовем конечную точку http: // localhost: 8060 / organization / 1 / with-департаменты и сотрудники .
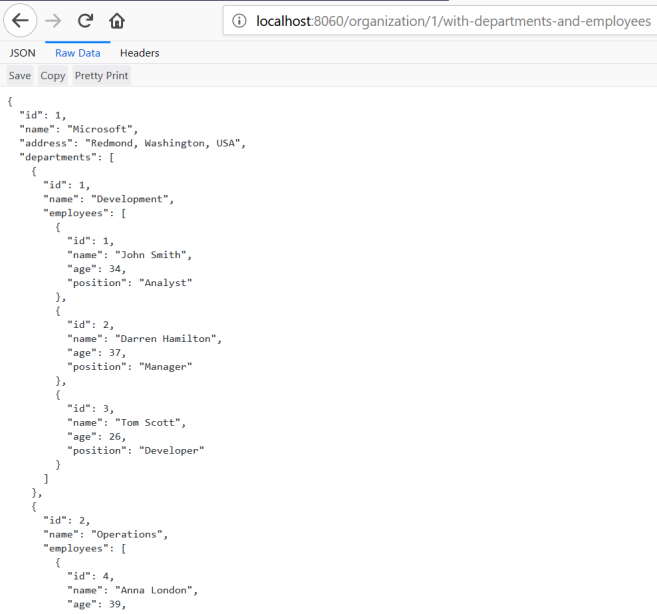
Шаг 8. Корреляция логов между независимыми микросервисами с использованием Spring Cloud Sleuth
Корреляция журналов между различными микроуслугами с помощью Spring Cloud Sleuth очень проста. Фактически, единственное, что вам нужно сделать, это добавить стартер spring-cloud-starter-sleuthв зависимости каждого микросервиса и шлюза.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>Для уточнения, мы будем менять по умолчанию формат журнала немного: %d{yyyy-MM-dd HH:mm:ss} ${LOG_LEVEL_PATTERN:-%5p} %m%n. Вот журналы, сгенерированные нашими тремя примерами микросервисов. Внутри фигурных скобок, []созданных Spring Cloud Stream, есть четыре записи . Наиболее важной для нас является вторая запись, которая указывает на то traceId, что устанавливается один раз для каждого входящего HTTP-запроса на границе системы.