••• Обновление 6/4/2012: обновлена сметная стоимость выполнения рабочего процесса, добавлена доплата EMR в размере 0,015 долл. США в час для небольшого экземпляра.
•• Обновление 6/2/2012: Microsoft Брэд Сарсфилд (@ bradooop ), старший разработчик — Hadoop для Windows и Windows Azure, сообщил в ответ на мою « Какую версию Hive использует HadoopOnAzure? нить в HadoopOnAzure Yahoo! Группа :
Мы перенесем предварительный просмотр, чтобы использовать Hive 0.8.1 очень скоро, недели, а не месяцы. Мы работали над этим в рамках более масштабной версии, которая включает обновление ядра Hadoop до кодовой строки 1.0.x.
Некоторые из вас заметили, что мы недавно добавили несколько патчей в ядро Hadoop. Мы очень рады видеть, что патчи текут и начинают появляться.
Для тех из вас, кто использует предварительный просмотр Hadoop для Windows, который в настоящее время находится в режиме предварительного просмотра с ограниченным приглашением, обновленный MSI появится в тот же период времени.
Брэд Сарсфилд

В более раннем твите Брэд сообщал, что Apache Hadoop в Windows Azure Preview работает под управлением Apache Hive 0.7.1 .
• Обновление от 31.05.2012. Веб-сервисы Amazon сообщили по электронной почте сегодня утром:
Объявление о поддержке Amazon EMR для Hive 0.8.1
Мы рады объявить о выходе Hive 0.8.1 на Amazon Elastic MapReduce. Это вводит ряд важных новых функций в Hive, таких как двоичные и временные метки, функциональность экспорта / импорта, плагин для разработчика, поддержка SerDes для каждого раздела и возможность удаленной отладки Hive. Для получения дополнительной информации посетите страницу сведений о версии Hive в Руководстве разработчика EMR.
Фон
Amazon Web Services (AWS) представили свою функцию Elastic MapReduce (EMR) с сообщением об объявлении Amazon Elastic MapReduce, опубликованном Джеффом Барром 2 апреля 2009 года:
Сегодня мы представляем Amazon Elastic MapReduce , наш новый сервис обработки на основе Hadoop. Я потрачу несколько минут на обсуждение общей концепции MapReduce, а затем подробно расскажу об этом новом захватывающем сервисе.
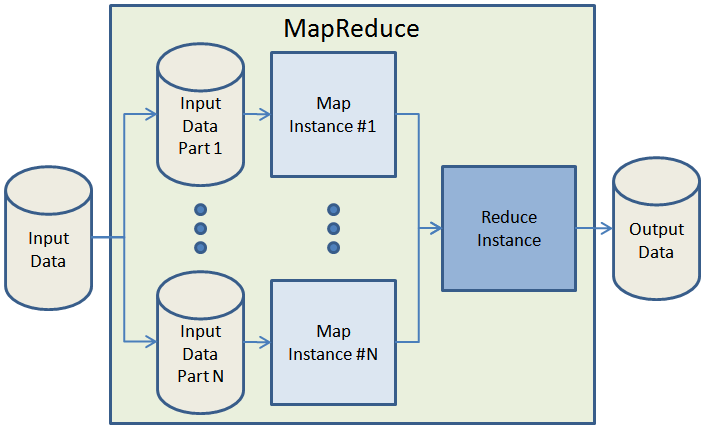
За последние 3 или 4 года ученые, исследователи и коммерческие разработчики признали и приняли модель программирования MapReduce . Изначально описанная в знаковой статье , модель MapReduce идеально подходит для обработки больших наборов данных на кластере процессоров. Легко масштабировать приложение MapReduce до заданий произвольного размера, просто добавляя больше вычислительной мощности. Вот очень простой обзор потока данных в типичном задании MapReduce:
Учитывая, что у вас достаточно вычислительного оборудования, MapReduce заботится о разбиении входных данных на куски более или менее одинакового размера, раскручивая несколько экземпляров обработки для фазы карты (которая по определению должна быть чем-то, что может быть нарушено). вплоть до независимых, распараллеливаемых рабочих блоков) распределение данных по каждому из картографов, отслеживание статуса каждого картографа, маршрутизация результатов карты в фазу сокращения и, наконец, отключение картографов и редукторов по завершении работы. MapReduce легко масштабировать для обработки больших заданий или получения результатов за более короткое время, просто запустив задание в более крупном кластере.
Hadoop — это реализация модели программирования MapReduce с открытым исходным кодом. Если у вас есть оборудование, вы можете следовать указаниям, приведенным в документации по установке кластера Hadoop, и, если повезет, вскоре начать работу. …
Следующие три более ранних публикации OakLeaf охватывают предварительный просмотр Apache Hadoop группы Microsoft SQL Server в Windows Azure (также известный как HadoopOnAzure):
- Импорт наборов данных DataMarket Marketplace Windows Azure в Apache Hadoop в базе данных кустов Windows Azure (4/2/2012)
- Использование данных из BLOB- объектов Windows Azure с Apache Hadoop в Windows Azure CTP (4/4/2012)
- Использование Excel 2010 и драйвера ODBC Hive для визуализации источников данных Hive в Apache Hadoop в Windows Azure (14.04.2012)
В этом руководстве предполагается, что у вас есть учетная запись AWS и вы знакомы с Консолью управления AWS, но не требуется предварительное знание Apache Hadoop, MapReduce или Hive.
Использование образца контекстной рекламы AWS для создания файла feature_index
Контекстная реклама — это название примера приложения AWS Apache Hive. Контекстная реклама Amazon с использованием Apache Hive и статьи Amazon EMR от 25.09.2009, последнее обновление от 15.02.2012, описывает пример сценария приложения следующим образом:
Компания, занимающаяся интернет-рекламой, управляет хранилищем данных, используя Hive и Amazon Elastic MapReduce. Эта компания использует в Amazon EC2 компьютеры, которые обслуживают показы рекламы и перенаправляют клики на рекламируемые сайты. Машины, работающие в Amazon EC2, сохраняют каждое впечатление и щелкают в файлах журналов, отправляемых в Amazon S3.
Хранение логов на Amazon S3
Машины для показа рекламы создают два типа файлов журналов: журналы показов и клики. Каждый раз, когда мы показываем рекламу покупателю, мы добавляем запись в журнал показов. Каждый раз, когда клиент нажимает на объявление, мы добавляем запись в журнал кликов.
Каждые пять минут рекламные автоматы отправляют файл журнала, содержащий последний набор журналов, на Amazon S3. Это позволяет нам производить своевременный анализ журналов. См. Следующую статью о мониторинге работоспособности программ показа объявлений: http://aws.amazon.com/articles/2854.
Машины рекламного сервера помещают свои журналы показов в Amazon S3. Например:
s3://elasticmapreduce/samples/hive-ads/tables/impressions/ dt=2009-04-13-08-05/ec2-12-64-12-12.amazon.com-2009-04-13-08-05.log We put the log data in the elasticmapreduce bucket and include it in a subdirectory called tables/impressions.The impressions directory contains additional directories named such that we can access the data as a partitioned table within Hive.The naming syntax is [Partition column]=[Partition value]. For example: dt=2009-04-13-05.Запуск процесса разработки
Наша первая задача — объединить журналы кликов и показов в одну таблицу, в которой указывается, был ли клик по конкретному объявлению, и информация об этом клике.
Прежде чем мы создадим таблицу, давайте запустим интерактивный поток работ, чтобы мы могли вводить наши команды Hive по одной за раз, чтобы проверить их работу. После проверки команд Hive мы можем использовать их для создания сценария, сохранения сценария в Amazon S3 и создания потока заданий, который выполняет сценарий.
Есть два способа запустить интерактивный поток работ. Вы можете использовать интерфейс командной строки Amazon Elastic MapReduce, доступный по адресу http://aws.amazon.com/developertools/2264, или использовать консоль управления AWS, доступную по адресу http://console.aws.amazon.com.
В этом руководстве используется консоль управления AWS.
Создание корзины S3 для хранения выходных файлов Feature_index приложения Hive
1. Перейдите по адресу http://console.aws.amazon.com , перейдите на вкладку S3 Консоли управления, чтобы открыть страницу Buckets, выберите Create Bucket в списке Actions, чтобы открыть форму с тем же именем, введите имя для bucket. и выберите ближайший к вам регион:

2. Нажмите Создать, чтобы создать корзину, закройте форму и перейдите на вкладку Elastic MapReduce.
Зарегистрируйте учетную запись EMR, если это необходимо
3. Если вы еще этого не сделали, вам будет предложено зарегистрировать учетную запись EMR:

4A. Нажмите кнопку «Зарегистрироваться в Elastic MapReduce», чтобы открыть страницу «Подтверждение личности по телефону», введите номер телефона, к которому у вас есть немедленный доступ, номер телефона и нажмите «Продолжить».
4В. Как правило, менее чем за минуту, робот-координатор попросит вас написать или сказать четырехзначный проверочный код, который отображается на шаге 2. Если он верен, шаг 3 будет отображаться так, как показано здесь:

4C. Нажмите «Продолжить», чтобы отобразить страницу «Обновление учетной записи»:

5. При получении электронного письма следуйте его инструкциям, чтобы вернуться на домашнюю страницу консоли управления EMR:

Добавьте файл feature_index в корзину с помощью запроса Hive
6. Выберите тот же регион, который вы выбрали для группы S3 для размещения проекта, и нажмите кнопку «Создать новый поток работ», чтобы открыть форму «Создать новый поток работ». Введите Имя потока работ, выберите «Запустить образец приложения» и выберите «Контекстная реклама» (скрипт Hive) из списка:

7. При желании нажмите ссылку «Подробнее», чтобы открыть контекстную рекламу с использованием учебника Apache Hive и Amazon EMR, упомянутого в начале этого раздела:

6. Нажмите «Продолжить», чтобы вернуться, чтобы открыть страницу формы «Задать параметры» с указанием местоположений для сценария Hive, входных файлов данных и дополнительных аргументов.

7. Замените заполнитель <yourbucket> на имя контейнера, указанное вами на шаге 1:

8. Нажмите «Продолжить», чтобы открыть страницу «Настройка экземпляров EC2» и принять значения по умолчанию для групп «Основной» (1), «Основной» (2) и «Задача» (0):

••• Примечание : Если выбран тип малого экземпляра, вам будет выставлен счет за использование минимального за один час трех / UNIX экземпляров EC2 Linux = US $ 0,27 плюс плату MapReduce в размере $ 0,045 = $ 0,315 для обработки плюс очень небольшое количество для передачи данных , Выбор рекомендуемых больших экземпляров обходится примерно в 4 раза дороже. Ниже приведен отчет об использовании сеанса, описанного в этой статье:

Операции куста из консоли управления автоматически прекращаются после сохранения окончательных данных в S3.
9. Нажмите «Продолжить», чтобы открыть страницу «Дополнительные параметры». Если вы хотите настроить или запустить задания из командной строки, примите ваши стандартные (или другие) пары ключей и оставшиеся значения по умолчанию:

10. Нажмите «Продолжить», чтобы открыть страницу «Действия Bootstrap» и принять опцию «No Bootstrap Actions» по умолчанию:

11. Нажмите Продолжить, чтобы открыть страницу обзора:

Примечание . Префикс s3n DNS представляет собственный (а не блочный) формат файла S3, что важно, когда вы используете Amazon S3 в качестве источника данных для интерактивных операций Hive с предварительным просмотром Apache Hadoop в Windows Azure в Windows Azure, который будет представлен ниже в этом руководстве.
12. Нажмите Создать поток работ, чтобы закрыть форму и запустить рабочий процесс:

13. Примерно через 10 минут для подготовки экземпляров состояние меняется на RUNNING:

14. Еще через 8 минут для обработки рабочего процесса состояние изменяется на SHUTTING_DOWN:

15. Еще через пару минут состояние изменится на ЗАВЕРШЕНО, а аргументы для операции Hive появятся в столбце Args нижней панели:

16. Click the S3 tab, select <YourBucket> in the navigation pane, double-click the folder names to navigate to the <YourBucket>/hive-ads/output/<Date>/feature_index folder, click the Properties button and Permissions tab, click Add More Permissions, select Everyone in the Grantee list, and mark the List check box to give public permission to view the file[s] in this folder. Select the select the 00000 file, click Add More Permissions again, select Everyone, and mark the Open/Download check box to give pubic access to the file:

17. Click Save to save your changes. If you have a text file editor that works well with large (~100 MB) files, such as TextPad, double-click the the filename, save it in your Downloads folder and open it with the text editor:

Note: The document’s format is Apache Hadoop SequenceFile, a standard format for Hive tables, uncompressed in this instance. You can import this format into Hive tables with the CREATE EXTERNAL TABLE command having a STORED AS SEQUENCEFILE modifier, as described later in this tutorial.
Creating an Interactive Hadoop on Azure Hive Table from Amazon’s feature_index File
My Using Data from Windows Azure Blobs with Apache Hadoop on Windows Azure CTP tutorial, mentioned earlier, describes how to specify a Windows Azure blob as the data source for an interactive Hive query using the SQL Server team’s HadoopOnAzure preview. This section describes a similar process that substitutes the file you created in the preceding steps as the Hive table’s data source.
This section assumes you’ve received an invitation to test the Apache Hadoop on Windows Azure preview. If not, go to this landing page, click the invitation link and complete a questionnaire to obtain an invitation code by e-mail:

To set up the S3 data source and execute HiveQL queries interactively, do the following:
1. Go to the HadoopOnAzure (HoA) landing page, click Sign In, and provide your Live ID and password to open the main HoA page (see step 2), if you have an active cluster, or the Request a Cluster page if you don’t. In this case, type a globally-unique DNS prefix for the cluster, select a Cluster Size, type your administrative login, password and password confirmation:

Note: Passwords must contain upper and lower case letters and numerals. Symbols aren’t allowed. When your password and confirmation passes muster, the Request Cluster button becomes enabled. If a Large cluster is available, choose it. No charges accrue during the preview period.
2. Click the Request Cluster button to start provisioning and display its status. After a few minutes the main HoA page opens:

Note: The cluster lifespan is 48 hours; you can renew the cluster during its last six hours of life only. Job History count will be 0, unless you’ve previously complete jobs.
3. Click the Manage Cluster tile to open the page of the same name:

4. Click the Set Up S3 button to open the Upload from Amazon S3 page, type your AWS Access Key and Secret Key, and accept the default S3N Native filesystem:

5. Click Save Settings to display an Amazon S3 Upload Successful message, despite the fact that you haven’t uploaded anything.
6. Click the back arrow twice to return to the main HoA page, click the Interactive Console tile to open the console and click the Hive button to select the Interactive Hive feature.
7. Type the following HiveQL DDL query in the text box at the bottom of the page to define the linked table:
CREATE EXTERNAL TABLE feature_index (
feature STRING,
ad_id STRING,
clicked_percent DOUBLE )
COMMENT ‘Amazon EMR Hive Output’
STORED AS SEQUENCEFILE
LOCATION ‘s3n://oakleaf-emr/hive-ads/output/2012-05-29/feature_index’;

8. Click the Evaluate button to execute the query and create the linked Hive table:

Note: Data isn’t downloaded until you execute a query that returns rows. Executing SELECT COUNT(*) FROM feature_index indicates that the table has 1,750,650 rows.
9. Open the Tables list which displays the table you just created and HoA’s hivesampletable. The Columns list displays a list of the select table’s column names.
10. To display the first 20 rows of the table, click Clear Screen, and then type and execute the following HiveQL query:
SELECT * FROM feature_index LIMIT 20

11. The “Applying the Heuristic” section of AWS’ Contextual Advertising using Apache Hive and Amazon EMR article suggests executing the following sample HiveQL query against the feature_index table “to see how it performs for the features ‘us:safari‘ and ‘ua:chrome‘”:
SELECT ad_id, -sum(log(if(0.0001 > clicked_percent, 0.0001, clicked_percent))) AS value
FROM feature_index
WHERE feature = ‘ua:safari’ OR feature = ‘ua:chrome’
GROUP BY ad_id
ORDER BY value DESC
LIMIT 100 ;
According to the article:
The result is advertisements ordered by a heuristic estimate of the chance of a click. At this point, we could look up the advertisements and see, perhaps, a predominance of advertisements for Apple products.
Note: The original query sorted ascending; sorting descending gives more interesting results (higher chances of a click) first:

Here’s the hidden Hive History’s significant content:
2012-05-30 18:34:58,774 Stage-1 map = 0%, reduce = 0%
2012-05-30 18:35:13,836 Stage-1 map = 1%, reduce = 0%
2012-05-30 18:35:16,852 Stage-1 map = 63%, reduce = 0%
2012-05-30 18:35:19,883 Stage-1 map = 100%, reduce = 0%
2012-05-30 18:35:34,899 Stage-1 map = 100%, reduce = 33%
2012-05-30 18:35:37,930 Stage-1 map = 100%, reduce = 100%
Ended Job = job_201205301808_0002
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
…
2012-05-30 18:36:05,649 Stage-2 map = 0%, reduce = 0%
2012-05-30 18:36:17,664 Stage-2 map = 50%, reduce = 0%
2012-05-30 18:36:20,680 Stage-2 map = 100%, reduce = 0%
2012-05-30 18:36:35,711 Stage-2 map = 100%, reduce = 100%
Ended Job = job_201205301808_0003
OK
Time taken: 133.969 seconds