В сегодняшнем посте мы постараемся охватить очень интересную и важную тему: трассировка распределенной системы. Практически это означает, что мы попытаемся отследить запрос с момента его выдачи клиентом до момента получения ответа на этот запрос. Сначала это выглядит довольно просто, но на самом деле это может включать в себя множество обращений к нескольким другим системам, базам данных, хранилищам NoSQL, кэшам, вы называете это …
В 2010 году Google опубликовал статью о Dapper , крупномасштабной инфраструктуре отслеживания распределенных систем (кстати, очень интересное чтение). Позже, Twitter построили свою собственную реализацию , основанную на Dapper бумаге, под названием Цыпкин , и это тот , который мы будем смотреть.
Мы создадим простой сервер JAX-RS 2.0 с использованием великолепной библиотеки Apache CXF . На стороне клиента мы будем использовать клиентский API JAX-RS 2.0, а с помощью Zipkin мы будем отслеживать все взаимодействия между клиентом и сервером (а также все, что происходит на стороне сервера). Чтобы сделать пример более наглядным, представим, что сервер использует какую-то базу данных для извлечения данных. Наш код будет представлять собой смесь чистой Java и немного Scala (выбор Scala скоро будет прояснен).
Еще одна зависимость для работы Zipkin — это Apache Zookeeper . Это необходимо для координации и должно быть начато заранее. К счастью, это очень легко сделать:
- загрузите релиз с http://zookeeper.apache.org/releases.html (текущая стабильная версия на момент написания статьи — 3.4.5 )
- распакуйте его в zookeeper-3.4.5
- скопируйте zookeeper-3.4.5 / conf / zoo_sample.cfg в zookeeper-3.4.5 / conf / zoo.cfg
- и просто запустите сервер Apache Zookeeper
Windows: zookeeper-3.4.5/bin/zkServer.cmd Linux: zookeeper-3.4.5/bin/zkServer.sh start
Теперь вернемся к Зипкину . Зипкин написан на Scala . Он все еще находится в активной разработке, и лучший способ начать с него — просто клонировать его репозиторий GitHub и собрать его из источников:
git clone https://github.com/twitter/zipkin.git
С точки зрения архитектуры Zipkin состоит из трех основных компонентов:
- сборщик : собирает следы по всей системе
- query : запрашивает собранные следы
- web : предоставляет веб-интерфейс для отображения следов
Чтобы запустить их, ребята из Zipkin предоставляют полезные скрипты в папке bin с единственным требованием, что JDK 1.7 должен быть установлен:
- бен / Коллектор
- бен / запрос
- бен / веб
Давайте выполним эти сценарии и убедимся, что каждый компонент был запущен успешно, без следов стека на консоли (для любопытных читателей я не смог заставить Zipkin работать в Windows, поэтому я предполагаю, что мы запускаем его в Linux). По умолчанию веб-интерфейс Zipkin доступен через порт 8080 . Хранилище для трасс — встроенный движок SQLite . Хотя это работает, лучшие хранилища (такие как удивительный Redis ) доступны.
Подготовка закончена, давайте сделаем немного кода. Мы начнем с клиентской части JAX-RS 2.0, поскольку она очень проста ( ClientStarter.java ):
package com.example.client;
import javax.ws.rs.client.Client;
import javax.ws.rs.client.ClientBuilder;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.Response;
import com.example.zipkin.Zipkin;
import com.example.zipkin.client.ZipkinRequestFilter;
import com.example.zipkin.client.ZipkinResponseFilter;
public class ClientStarter {
public static void main( final String[] args ) throws Exception {
final Client client = ClientBuilder
.newClient()
.register( new ZipkinRequestFilter( "People", Zipkin.tracer() ), 1 )
.register( new ZipkinResponseFilter( "People", Zipkin.tracer() ), 1 );
final Response response = client
.target( "http://localhost:8080/rest/api/people" )
.request( MediaType.APPLICATION_JSON )
.get();
if( response.getStatus() == 200 ) {
System.out.println( response.readEntity( String.class ) );
}
response.close();
client.close();
// Small delay to allow tracer to send the trace over the wire
Thread.sleep( 1000 );
}
}
За исключением пары импортов и классов с Zipkin , все должно выглядеть просто. Так для чего эти ZipkinRequestFilter и ZipkinResponseFilter ? Зипкин потрясающий, но это не волшебный инструмент. Чтобы отследить любой запрос в распределенной системе, должен быть передан некоторый контекст. В мире REST / HTTP это обычно заголовки запроса / ответа. Давайте сначала посмотрим на ZipkinRequestFilter ( ZipkinRequestFilter.scala ):
package com.example.zipkin.client
import javax.ws.rs.client.ClientRequestFilter
import javax.ws.rs.ext.Provider
import javax.ws.rs.client.ClientRequestContext
import com.twitter.finagle.http.HttpTracing
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.tracing.Annotation
import com.twitter.finagle.tracing.TraceId
import com.twitter.finagle.tracing.Tracer
@Provider
class ZipkinRequestFilter( val name: String, val tracer: Tracer ) extends ClientRequestFilter {
def filter( requestContext: ClientRequestContext ): Unit = {
Trace.pushTracerAndSetNextId( tracer, true )
requestContext.getHeaders().add( HttpTracing.Header.TraceId, Trace.id.traceId.toString )
requestContext.getHeaders().add( HttpTracing.Header.SpanId, Trace.id.spanId.toString )
Trace.id._parentId foreach { id =>
requestContext.getHeaders().add( HttpTracing.Header.ParentSpanId, id.toString )
}
Trace.id.sampled foreach { sampled =>
requestContext.getHeaders().add( HttpTracing.Header.Sampled, sampled.toString )
}
requestContext.getHeaders().add( HttpTracing.Header.Flags, Trace.id.flags.toLong.toString )
if( Trace.isActivelyTracing ) {
Trace.recordRpcname( name, requestContext.getMethod() )
Trace.recordBinary( "http.uri", requestContext.getUri().toString() )
Trace.record( Annotation.ClientSend() )
}
}
}
Небольшое количество внутренностей Zipkin сделает этот код неясным. Центральная часть Zipkin API — это класс Trace . Каждый раз, когда мы хотим инициировать трассировку, у нас должен быть Trace Id и трассировщик для его фактического отслеживания. Эта единственная строка генерирует новый идентификатор трассировки и регистрирует трассировщик (внутренне эти данные хранятся в локальном состоянии потока).
Trace.pushTracerAndSetNextId( tracer, true )
Трассы имеют иерархическую природу, как и идентификаторы трасс: каждый идентификатор трассы может быть корнем или частью другой трассы. В нашем примере мы точно знаем, что являемся первыми и, следовательно, корнем трассы. Позже Trace Id оборачивается в заголовки HTTP и будет передаваться по запросу (мы увидим на стороне сервера, как он используется). Последние три строки связывают полезную информацию с трассировкой: имя нашего API ( People ), HTTP-метод, URI и, самое главное, что клиент отправляет запрос на сервер.
Trace.recordRpcname( name, requestContext.getMethod() ) Trace.recordBinary( "http.uri", requestContext.getUri().toString() ) Trace.record( Annotation.ClientSend() )
ZipkinResponseFilter делает обратное к ZipkinRequestFilter и извлечь трассировки Id из заголовков запроса ( ZipkinResponseFilter.scala ):
package com.example.zipkin.client
import javax.ws.rs.client.ClientResponseFilter
import javax.ws.rs.client.ClientRequestContext
import javax.ws.rs.client.ClientResponseContext
import javax.ws.rs.ext.Provider
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.tracing.Annotation
import com.twitter.finagle.tracing.SpanId
import com.twitter.finagle.http.HttpTracing
import com.twitter.finagle.tracing.TraceId
import com.twitter.finagle.tracing.Flags
import com.twitter.finagle.tracing.Tracer
@Provider
class ZipkinResponseFilter( val name: String, val tracer: Tracer ) extends ClientResponseFilter {
def filter( requestContext: ClientRequestContext, responseContext: ClientResponseContext ): Unit = {
val spanId = SpanId.fromString( requestContext.getHeaders().getFirst( HttpTracing.Header.SpanId ).toString() )
spanId foreach { sid =>
val traceId = SpanId.fromString( requestContext.getHeaders().getFirst( HttpTracing.Header.TraceId ).toString() )
val parentSpanId = requestContext.getHeaders().getFirst( HttpTracing.Header.ParentSpanId ) match {
case s: String => SpanId.fromString( s.toString() )
case _ => None
}
val sampled = requestContext.getHeaders().getFirst( HttpTracing.Header.Sampled ) match {
case s: String => s.toString.toBoolean
case _ => true
}
val flags = Flags( requestContext.getHeaders().getFirst( HttpTracing.Header.Flags ).toString.toLong )
Trace.setId( TraceId( traceId, parentSpanId, sid, Option( sampled ), flags ) )
}
if( Trace.isActivelyTracing ) {
Trace.record( Annotation.ClientRecv() )
}
}
}
Строго говоря, в нашем примере нет необходимости извлекать Trace Id из запроса, поскольку оба фильтра должны выполняться одним потоком. Но последняя строка очень важна: она отмечает конец нашего следа, говоря, что клиент получил ответ .
Trace.record( Annotation.ClientRecv() )
На самом деле остается сам трассировщик ( Zipkin.scala ):
package com.example.zipkin
import com.twitter.finagle.stats.DefaultStatsReceiver
import com.twitter.finagle.zipkin.thrift.ZipkinTracer
import com.twitter.finagle.tracing.Trace
import javax.ws.rs.ext.Provider
object Zipkin {
lazy val tracer = ZipkinTracer.mk( host = "localhost", port = 9410, DefaultStatsReceiver, 1 )
}
Если в этот момент вы не понимаете, что означают все эти трассы и пролеты, просмотрите эту страницу документации , вы получите базовое понимание этих концепций.
На данный момент на стороне клиента ничего не осталось, и мы можем перейти на сторону сервера. Наш сервер JAX-RS 2.0 будет предоставлять единую конечную точку ( PeopleRestService.java ):
package com.example.server.rs;
import java.util.Arrays;
import java.util.Collection;
import java.util.concurrent.Callable;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import com.example.model.Person;
import com.example.zipkin.Zipkin;
@Path( "/people" )
public class PeopleRestService {
@Produces( { "application/json" } )
@GET
public Collection< Person > getPeople() {
return Zipkin.invoke( "DB", "FIND ALL", new Callable< Collection< Person > >() {
@Override
public Collection<person> call() throws Exception {
return Arrays.asList( new Person( "Tom", "Bombdil" ) );
}
} );
}
}
Как мы упоминали ранее, мы смоделируем доступ к базе данных и сгенерируем дочернюю трассировку с помощью оболочки Zipkin.invoke (которая выглядит очень просто, Zipkin.scala ):
package com.example.zipkin
import java.util.concurrent.Callable
import com.twitter.finagle.stats.DefaultStatsReceiver
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.zipkin.thrift.ZipkinTracer
import com.twitter.finagle.tracing.Annotation
object Zipkin {
lazy val tracer = ZipkinTracer.mk( host = "localhost", port = 9410, DefaultStatsReceiver, 1 )
def invoke[ R ]( service: String, method: String, callable: Callable[ R ] ): R = Trace.unwind {
Trace.pushTracerAndSetNextId( tracer, false )
Trace.recordRpcname( service, method );
Trace.record( new Annotation.ClientSend() );
try {
callable.call()
} finally {
Trace.record( new Annotation.ClientRecv() );
}
}
}
Как мы видим, в этом случае сам сервер становится клиентом для какого-либо другого сервиса (базы данных).
Последняя и самая важная часть сервера — перехватывать все HTTP- запросы, извлекать из них Trace Id, чтобы можно было связать больше данных с трассировкой (аннотировать трассировку). В Apache CXF это очень легко сделать, предоставив собственный invoker ( ZipkinTracingInvoker.scala ):
package com.example.zipkin.server
import org.apache.cxf.jaxrs.JAXRSInvoker
import com.twitter.finagle.tracing.TraceId
import org.apache.cxf.message.Exchange
import com.twitter.finagle.tracing.Trace
import com.twitter.finagle.tracing.Annotation
import org.apache.cxf.jaxrs.model.OperationResourceInfo
import org.apache.cxf.jaxrs.ext.MessageContextImpl
import com.twitter.finagle.tracing.SpanId
import com.twitter.finagle.http.HttpTracing
import com.twitter.finagle.tracing.Flags
import scala.collection.JavaConversions._
import com.twitter.finagle.tracing.Tracer
import javax.inject.Inject
class ZipkinTracingInvoker extends JAXRSInvoker {
@Inject val tracer: Tracer = null
def trace[ R ]( exchange: Exchange )( block: => R ): R = {
val context = new MessageContextImpl( exchange.getInMessage() )
Trace.pushTracer( tracer )
val id = Option( exchange.get( classOf[ OperationResourceInfo ] ) ) map { ori =>
context.getHttpHeaders().getRequestHeader( HttpTracing.Header.SpanId ).toList match {
case x :: xs => SpanId.fromString( x ) map { sid =>
val traceId = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.TraceId ).toList match {
case x :: xs => SpanId.fromString( x )
case _ => None
}
val parentSpanId = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.ParentSpanId ).toList match {
case x :: xs => SpanId.fromString( x )
case _ => None
}
val sampled = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.Sampled ).toList match {
case x :: xs => x.toBoolean
case _ => true
}
val flags = context.getHttpHeaders().getRequestHeader( HttpTracing.Header.Flags ).toList match {
case x :: xs => Flags( x.toLong )
case _ => Flags()
}
val id = TraceId( traceId, parentSpanId, sid, Option( sampled ), flags )
Trace.setId( id )
if( Trace.isActivelyTracing ) {
Trace.recordRpcname( context.getHttpServletRequest().getProtocol(), ori.getHttpMethod() )
Trace.record( Annotation.ServerRecv() )
}
id
}
case _ => None
}
}
val result = block
if( Trace.isActivelyTracing ) {
id map { id => Trace.record( new Annotation.ServerSend() ) }
}
result
}
@Override
override def invoke( exchange: Exchange, parametersList: AnyRef ): AnyRef = {
trace( exchange )( super.invoke( exchange, parametersList ) )
}
}
По сути, единственное, что делает этот код, — это извлечение Trace Id из запроса и его привязка к текущему потоку. Также обратите внимание, что мы связываем дополнительные данные с трассировкой, отмечающей участие сервера .
Trace.recordRpcname( context.getHttpServletRequest().getProtocol(), ori.getHttpMethod() ) Trace.record( Annotation.ServerRecv() )
Чтобы увидеть трассировку в реальном времени, давайте запустим наш сервер (обратите внимание, что sbt должен быть установлен ), предполагая, что все компоненты Zipkin и Apache Zookeeper уже запущены и работают:
sbt 'project server' 'run-main com.example.server.ServerStarter'
тогда клиент:
sbt 'project client' 'run-main com.example.client.ClientStarter'
и, наконец, откройте веб-интерфейс Zipkin по адресу http: // localhost: 8080 . Мы должны увидеть что-то подобное (в зависимости от того, сколько раз вы запускали клиент):
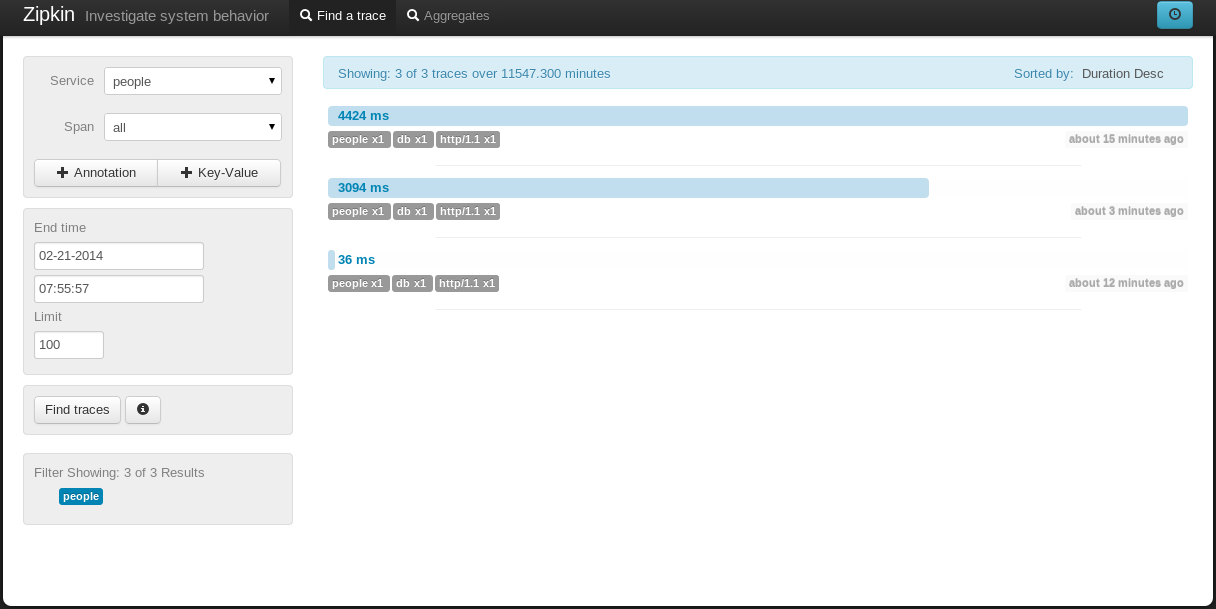
В качестве альтернативы, мы можем создавать и запускать толстые JAR-файлы, используя плагин sbt-assembly :
sbt assembly java -jar server/target/zipkin-jaxrs-2.0-server-assembly-0.0.1-SNAPSHOT.jar java -jar client/target/zipkin-jaxrs-2.0-client-assembly-0.0.1-SNAPSHOT.jar
Если щелкнуть какую-либо конкретную трассировку, будет показана более подробная информация, очень похожая на цепочку базы данных client <-> server <-> .
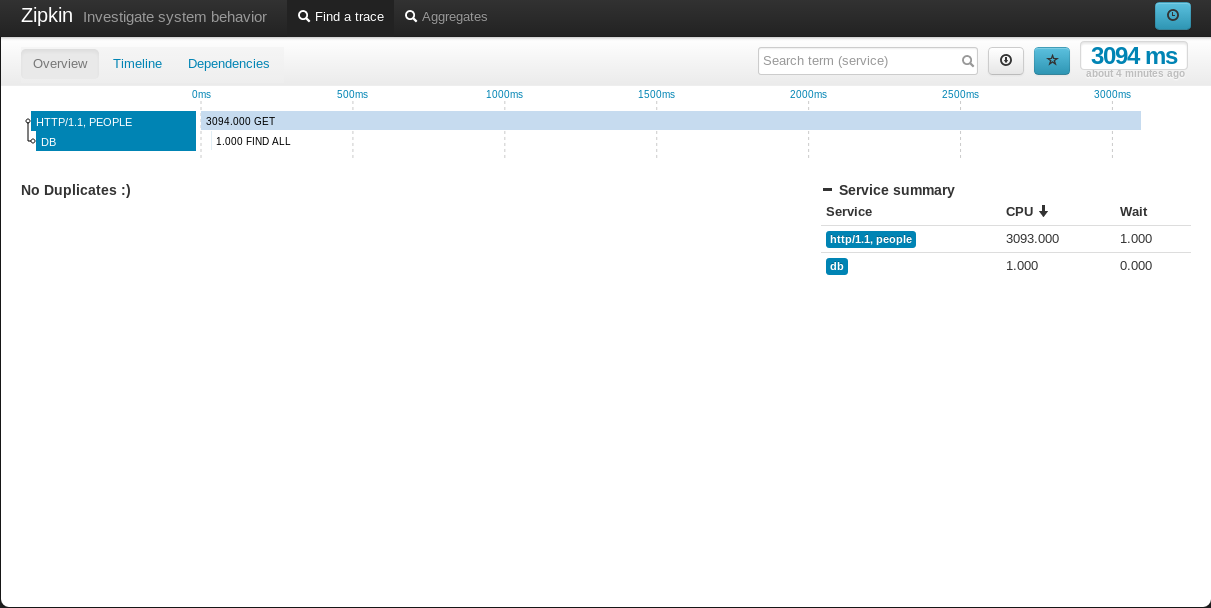
Еще больше деталей отображается, когда мы нажимаем на конкретный элемент в дереве.

Наконец, бонусной частью является график зависимости компонентов / услуг.

Как мы видим, все данные, связанные с трассировкой, находятся здесь и подчиняются иерархической структуре. Обнаружены и показаны корневая и дочерняя трассы, а также временные рамки для цепочек отправки / получения клиента и приема / отправки сервера . Наш пример довольно наивен и прост, но даже в этом случае он демонстрирует, насколько мощной и полезной является трассировка распределенной системы. Спасибо Зипкину, ребята.
Полный исходный код доступен на GitHub .