Закон Бенфорда в настоящее время чрезвычайно популярен (см., Например, http://en.wikipedia.org/… ). Обычно утверждается, что для заданного набора данных изменение единиц не влияет на распределение первой цифры. Таким образом, это должно быть связано с масштабно-инвариантным распределением. Эвристически, масштабная (или единичная) инвариантность означает, что плотность меры 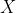 (или функции вероятности)
(или функции вероятности) 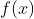 должна быть пропорциональна
должна быть пропорциональна 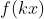 . Таким образом, поскольку плотности интегрируются в 1, коэффициент пропорциональности должен быть
. Таким образом, поскольку плотности интегрируются в 1, коэффициент пропорциональности должен быть 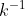 и, следовательно,
и, следовательно, 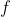 должен удовлетворять следующему функциональному уравнению
должен удовлетворять следующему функциональному уравнению 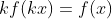 для всех
для всех 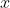 в
в 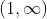 и
и 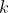 в
в 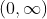 . Решение этого функционального уравнения
. Решение этого функционального уравнения 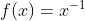 Думаю, это легко доказать, решив обыкновенное дифференциальное уравнение
Думаю, это легко доказать, решив обыкновенное дифференциальное уравнение
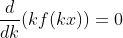
Теперь, если 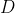 обозначает первую цифру , в базе 10, то
обозначает первую цифру , в базе 10, то
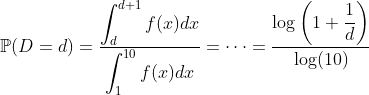 Что является так называемым законом Бенфорда . Итак, это распределение выглядит так
Что является так называемым законом Бенфорда . Итак, это распределение выглядит так
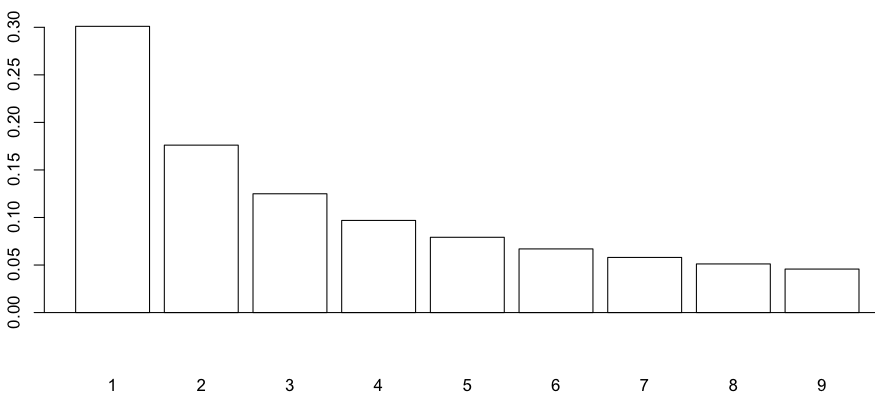
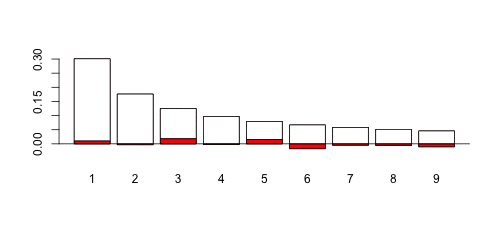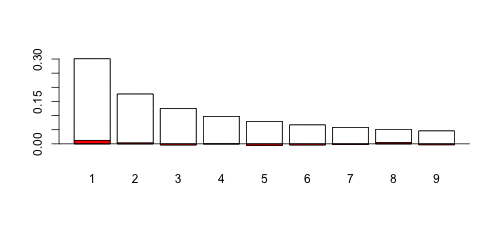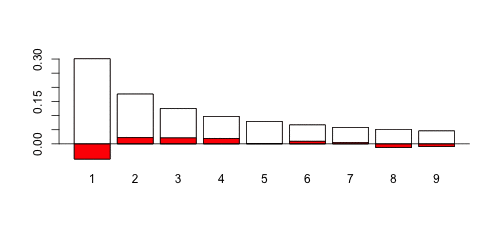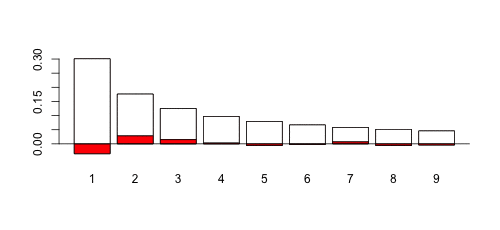
> (benford=log(1+1/(1:9))/log(10)) [1] 0.30103000 0.17609126 0.12493874 0.09691001 0.07918125 [6] 0.06694679 0.05799195 0.05115252 0.04575749 > names(benford)=1:9 > sum(benford) [1] 1 > barplot(benford,col="white",ylim=c(-.045,.3)) > abline(h=0)
Чтобы вычислить эмпирическое распределение из выборки, используйте следующую функцию
> firstdigit=function(x){
+ if(x>=1){x=as.numeric(substr(as.character(x),1,1)); zero=FALSE}
+ if(x<1){zero=TRUE}
+ while(zero==TRUE){
+ x=x*10; zero=FALSE
+ if(trunc(x)==0){zero=TRUE}
+ }
+ return(trunc(x))
+ }
а потом
> Xd=sapply(X,firstdigit) > table(Xd)/1000
В законе Бенфорда: эмпирическое исследование и новое объяснение мы можем прочитать
![]()
Это не математическая статья, поэтому не ожидайте никаких формальных доказательств в этой статье. По крайней мере, мы можем запустить симуляцию Монте-Карло и посмотреть, что происходит, если мы сгенерируем выборки из логнормального распределения с дисперсией 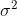 . Например, с единицей дисперсии,
. Например, с единицей дисперсии,
> set.seed(1)
> s=1
> X=rlnorm(n=1000,0,s)
> Xd=sapply(X,firstdigit)
> table(Xd)/1000
Xd
1 2 3 4 5 6 7 8 9
0.288 0.172 0.121 0.086 0.075 0.072 0.073 0.053 0.060
> T=rbind(benford,-table(Xd)/1000)
> barplot(T,col=c("red","white"),ylim=c(-.045,.3))
> abline(h=0)
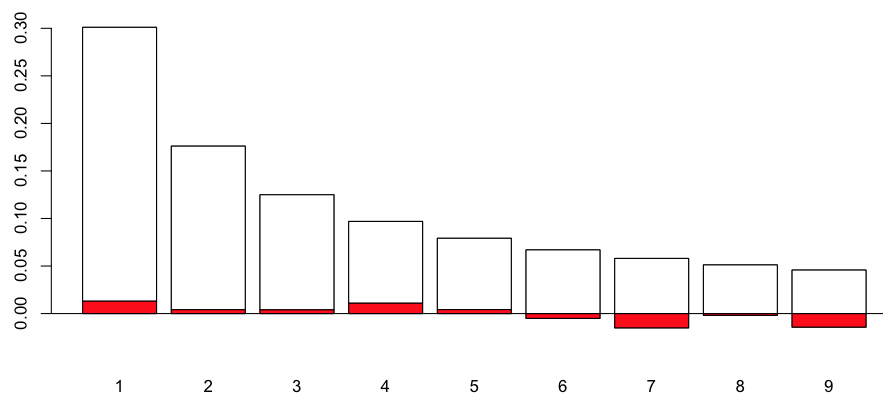
Понятно, что это недалеко от закона Бенфорда. Возможно, можно рассмотреть более формальный тест, например, тест Пирсона  (на соответствие).
(на соответствие).
> chisq.test(T,p=benford) Chi-squared test for given probabilities data: T X-squared = 10.9976, df = 8, p-value = 0.2018
Так что да, закон Бенфорда допустим! Теперь, если мы рассмотрим случай, когда  меньше (скажем, 0,9), это довольно другая история,
меньше (скажем, 0,9), это довольно другая история,
по сравнению со случаем, где больше (скажем, 1,1)
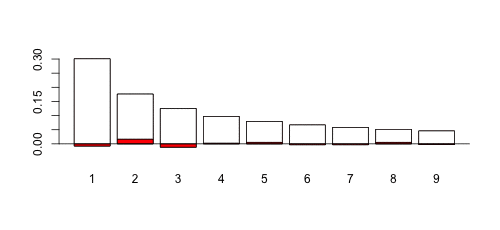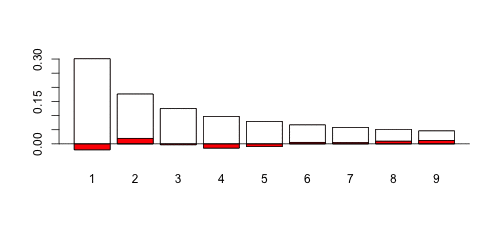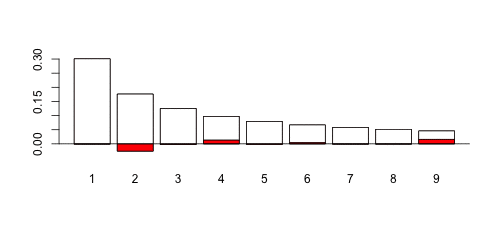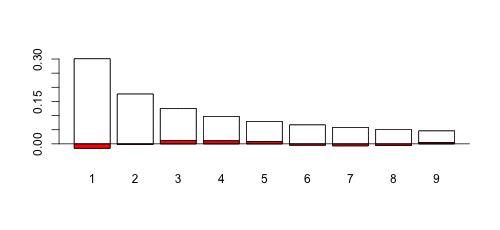
Можно сгенерировать несколько выборок (всегда одного размера, здесь 1000 наблюдений), просто изменить параметр дисперсии и вычислить  -значение теста. Может быть одна сложная часть: при генерации выборок из логнормальных распределений с малой дисперсией может быть возможно, что некоторые цифры вообще не появятся. В этом случае есть проблема с тестом. Так что мы просто используем здесь
-значение теста. Может быть одна сложная часть: при генерации выборок из логнормальных распределений с малой дисперсией может быть возможно, что некоторые цифры вообще не появятся. В этом случае есть проблема с тестом. Так что мы просто используем здесь
> T=table(Xd) > T=T[as.character(1:9)] > T[is.na(T)]=0 > PVAL[i]=chisq.test(T,p=benford)$p.value
Боксплоты -значения теста следующие,
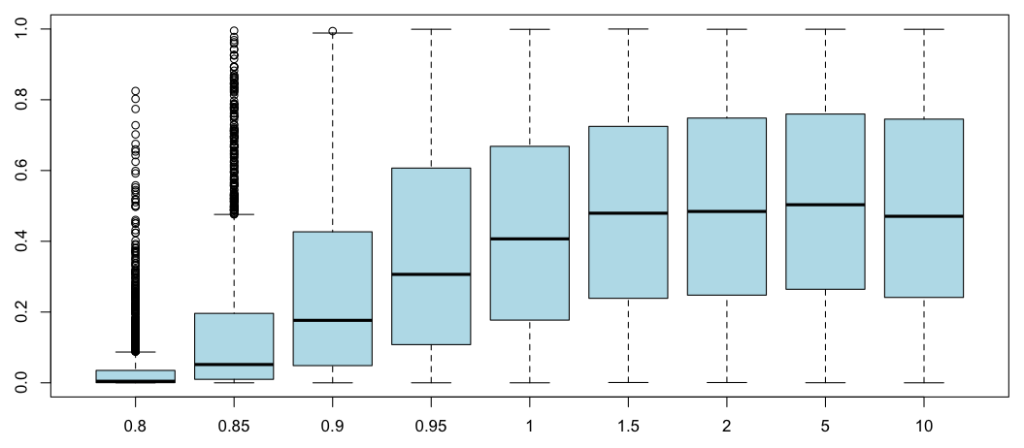
Когда он слишком мал, это явно не распределение Бенфорда: для половины (или более) наших выборок -значение меньше 5%. С другой стороны, когда оно велико (достаточно), распределение Бенфорда представляет собой распределение первой цифры логнормальных выборок, поскольку 95% наших выборок имеют -значения выше 5% (а распределение -значения практически однородно на единичный интервал). Вот доля выборок, где -значение было ниже 5% (по 5000 поколений каждый раз)

Обратите внимание, что также возможно вычислить -значение критерия Комогорова-Смирнова, проверяя, имеет ли -значение равномерное распределение,
> ks.test(PVAL[,s], "punif")$p.value
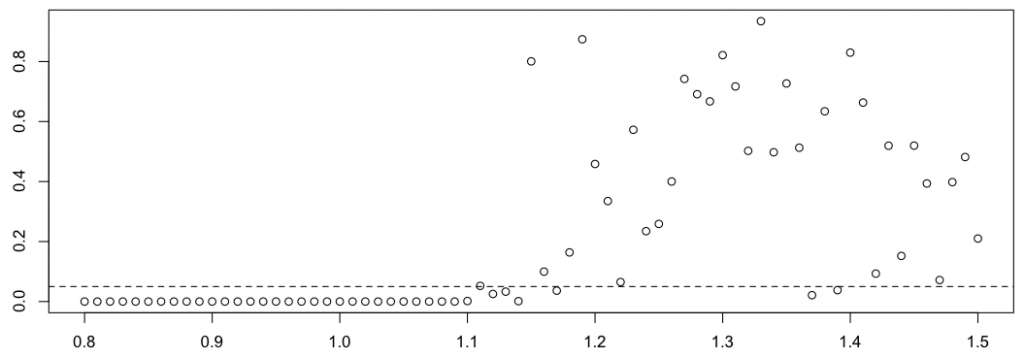
Действительно, если оно больше 1,15 (около этого значения), похоже, что закон Бенфорда является подходящим распределением для первой цифры.