В последних нескольких статьях этой серии ( один , два , три и четыре ) я показал вам, как сохранять иерархические данные в виде плоской таблицы базы данных с использованием расширения Postgres LTREE . Я объяснил, что вы представляете узлы дерева, используя строки пути, и как искать данные в дереве, используя специальные операторы SQL, которые предоставляет LTREE.
Но реальная ценность LTREE не в операторах и функциях, которые она вам дает — внутренне они сводятся к довольно простым строковым операциям. Вместо этого, что делает LTREE полезным, так это то, что он интегрирует эти новые операторы с индексным кодом Postgres, который позволяет вам быстро находить и находить подходящие пути дерева . Чтобы достичь этого, LTREE использует проект Обобщенного дерева поиска (GiST), API, который позволяет разработчикам C расширять систему индексации Postgres.
Но что делает GiST API? И что конкретно означает расширение системы индексации Postgres? Читай дальше что бы узнать!
Поиск без индекса
Здесь снова таблица дерева, которую я использовал в качестве примера в предыдущих статьях этой серии:
create table tree(
id serial primary key,
letter char,
path ltree
);Обратите внимание, что в path столбце используется пользовательский ltree тип данных, предоставляемый расширением LTREE. Если вы пропустили предыдущие записи, ltree столбцы представляют иерархические данные, объединяя строки с точками, то есть A.B.C.D или Europe.Estonia.Tallinn.
Ранее в качестве примера я использовал простое дерево с семью узлами. Операции SQL на такой маленькой таблице всегда будут быстрыми. Сегодня я хотел бы представить гораздо большее дерево для изучения преимуществ, которые могут дать индексы. Предположим, что вместо этого у меня есть дерево, содержащее сотни или тысячи записей в столбце пути:

Теперь предположим, что я ищу один узел дерева, используя select инструкцию:
select letter from tree where path = 'A.B.T.V'Без индекса в этой таблице Postgres вынужден прибегать к сканированию последовательности , что является техническим способом сказать, что Postgres должен перебирать все записи в таблице:
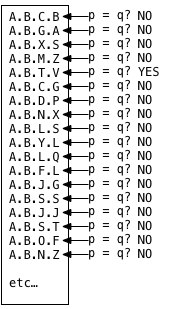
Для каждой записи в таблице Postgres выполняет сравнение, p == q где p — значение столбца пути для каждой записи в таблице, а q — запрос или значение, которое я ищу ( A.B.V.T в этом примере). Этот цикл может быть очень медленным, если имеется много записей. Postgres должен проверить их все, потому что они могут появляться в любом порядке, и невозможно заранее узнать, сколько совпадений может быть в данных.
Поиск по индексу B-дерева
Конечно, есть простое решение этой проблемы. Мне просто нужно создать индекс по столбцу пути:
create index tree_path_idx on tree (path);Как вы, вероятно, знаете, выполнение поиска по индексу выполняется намного быстрее. Если вы видите проблему производительности с оператором SQL в вашем приложении, первое, что вы должны проверить, это отсутствие индекса. Но почему? Почему создание индекса ускоряет поиск? Причина в том, что индекс является отсортированной копией данных целевого столбца:

За счет предварительной сортировки значений Postgres может искать их намного быстрее. Он использует алгоритм двоичного поиска:

Postgres начинает с проверки значения в середине индекса. Если сохраненное значение ( p) слишком велико и больше, чем query ( q) p > q, оно перемещается вверх и проверяет значение в позиции 25%. Если значение слишком мало, p < qоно перемещается вниз и проверяет значение в позиции 75%. Повторно разделяя индекс на более мелкие фрагменты, Postgres нужно выполнить поиск только несколько раз, прежде чем найдет соответствующую запись или записи.
Однако для больших таблиц с тысячами или миллионами строк Postgres не может сохранить все отсортированные значения данных в одном сегменте памяти. Вместо этого индексы Postgres (и индексы в любой системе реляционных баз данных) сохраняют значения в двоичном или сбалансированном дереве (B-Tree):
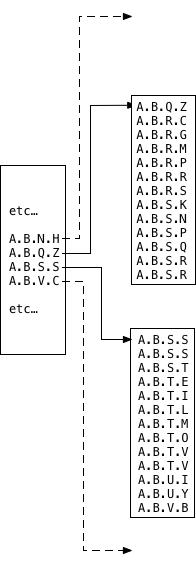
Теперь мои значения сохраняются в серии различных сегментов памяти, расположенных в древовидной структуре. Разделение индекса на части позволяет Postgres правильно управлять памятью, сохраняя, возможно, миллионы значений в индексе. Обратите внимание, что это не дерево из моего набора данных LTREE; B-деревья — это внутренние структуры данных Postgres, к которым у меня нет доступа. Чтобы узнать больше об этой информатике, прочитайте мою статью 2014 года « Обнаружение информатики за индексами Postgres» .
Теперь Postgres использует повторяющиеся двоичные поиски — по одному для каждого сегмента памяти в B-дереве — чтобы найти значение:

Каждое значение в родительском или корневом сегменте действительно является указателем на дочерний сегмент. Postgres сначала ищет корневой сегмент, используя двоичный поиск, чтобы найти правильный указатель, а затем переходит вниз к дочернему сегменту, чтобы найти фактические совпадающие записи, используя другой двоичный поиск. Алгоритм является рекурсивным; B-дерево может содержать много уровней, и в этом случае дочерние сегменты будут содержать указатели на сегменты внука и т. д.
В чем проблема со стандартными индексами Postgres?
Но здесь есть серьезная проблема, которую я пока упустил. Индексный поисковый код Postgres поддерживает только определенные операторы. Выше я искал с помощью этого оператора select:
select letter from tree where path = 'A.B.T.V'Я искал записи , которые были равны моему запросу p == q. Используя индекс B-Tree, я также мог бы искать записи больше или меньше, чем мой запрос: p < q или p > q.
Но что, если я хочу использовать пользовательский LTREE <@ оператор (предок)? Что если я хочу выполнить это selectутверждение?
select letter from tree where path <@ 'A.B.V'Как мы видели в предыдущих статьях этой серии, этот поиск вернет все записи LTREE, которые появляются где-то в ветке под ABV и являются потомками узла дерева ABV.
Стандартный индекс Postgres здесь не работает. Для выполнения этого поиска эффективного использования индекса, Postgres должен выполнить это сравнение , как он гуляет B-Tree: p <@ q. Но стандартный код поиска индекса Postgres не поддерживает p <@ q. Вместо этого, если я выполню этот поиск, Postgres снова начнет медленное сканирование последовательности, даже если я создам индекс для столбца ltree.
Для эффективного поиска в древовидных данных нам нужен индекс Postgres, который будет выполнять как p <@ qсравнения, так p == qи p < qсравнения. Нам нужен индекс GiST!
Проект обобщенного дерева поиска (GiST)
Почти 20 лет назад проект с открытым исходным кодом в Калифорнийском университете в Беркли решил именно эту проблему. Проект Generalized Search Tree (GiST) добавил API в Postgres, что позволило разработчикам на C расширить набор типов данных, которые можно использовать в индексе Postgres.
Цитирование с веб-страницы проекта:
В начале было B-дерево. Все деревья поиска в базе данных начиная с B-дерева были вариациями по своей теме. Признавая это, мы разработали новый вид индекса, называемый Обобщенным деревом поиска (GiST), который обеспечивает функциональность всех этих деревьев в одном пакете. GiST — это расширяемая структура данных, которая позволяет пользователям разрабатывать индексы для любых типов данных, поддерживая любой поиск этих данных.
GiST достигает этого, добавляя API в систему индексирования Postgres, которую каждый может реализовать для своего конкретного типа данных. GiST реализует общий код индексации и поиска, но обращается к пользовательскому коду в четыре ключевых момента процесса индексации. Снова приведем цитату с веб-страницы проекта. Вот краткое объяснение четырех методов в GiST API:

В индексах GiST используется древовидная структура, аналогичная B-дереву, которое мы видели выше. Но Postgres не создает структуру дерева индексов GiST сама по себе; Postgres работает с реализациями API-функций GiST Union, Penalty и PickSplit, описанными выше. И когда вы выполняете оператор SQL, который ищет значение в индексе GiST, Postgres использует функцию Consistent для поиска целевых значений.
Ключевым моментом здесь является то, что разработчик API GiST может решить, какой тип данных индексировать и как расположить эти значения данных в дереве GiST. Postgres не волнует, что представляют собой значения данных или как выглядит дерево. Postgres просто вызывает Consistent в любое время, когда ему нужно найти значение, и позволяет разработчику GiST API найти это значение.
Пример может помочь понять это, и у нас есть пример реализации GiST API: расширение LTREE!
Реализация API GiST для дерева путей
Начиная примерно с 2001 года, два студента МГУ нашли API из проекта GiST и решили использовать его для создания поддержки индексации для древовидных данных. Олег Бартунов и Теодор Сигаев, по сути, написали функцию «Согласование путей дерева», функцию «Объединение путей дерева» и т. Д. Код C, который реализует этот API, является расширением LTREE. Вы можете найти эти функции ltree_consistentи ltree_union, среди других функций, в файле с именем ltree_gist.c, расположенном в contrib/ltree каталоге в исходном коде Postgres. Они также реализовали Penalty, PickSplit и различные другие функции, связанные с алгоритмом GiST.
Я могу использовать эти пользовательские функции для своих собственных данных, просто создав индекс GiST. Возвращаясь к моему примеру с LTREE, я отброшу свой индекс B-Tree и вместо этого создам индекс GiST:
drop index tree_path_idx;
create index tree_path_idx on tree using gist (path);Обратите внимание на использование ключевых слов gist в команде create index. Это все, что нужно; Postgres автоматически находит, загружает и использует функции ltree_union, ltree_picksplitи т. Д. Всякий раз, когда я вставляю новое значение в таблицу. (Он также сразу вставит все существующие записи в индекс.) Конечно, ранее я также установил расширение LTREE .
Посмотрим, как это работает. Предположим, я добавил несколько случайных записей дерева в свою пустую таблицу дерева после создания индекса:
insert into tree (letter, path) values ('A', 'A.B.G.A');
insert into tree (letter, path) values ('E', 'A.B.T.E');
insert into tree (letter, path) values ('M', 'A.B.R.M');
insert into tree (letter, path) values ('F', 'A.B.E.F');
insert into tree (letter, path) values ('P', 'A.B.R.P');Для начала Postgres выделит новый сегмент памяти для индекса GiST и вставит мои пять записей:

Если я сейчас ищу с помощью оператора предка:
select count(*) from tree where path <@ 'A.B.T'… Postgres просто перебирает записи в том же порядке, который я вставил, и вызывает ltree_consistentфункцию для каждой из них. Здесь снова то, что API GiST вызывает для выполнения функции Consistent:

В этом случае Postgres будет сравнивать p <@ A.B.T для каждой из этих пяти записей:

Поскольку значения pключей дерева страниц являются простыми строками пути, они ltree_consistent напрямую сравниваются с ними A.B.T и сразу же определяют, является ли каждое значение узлом-потомком дерева A.B.T. Прямо сейчас индекс GiST не дал большой ценности; Postgres должен перебирать все значения, как при сканировании последовательности.
Теперь предположим, что я начинаю добавлять все больше и больше записей в свою таблицу. Postgres может разместить до 136 записей LTREE в корневом сегменте памяти GiST, и сканирование индекса работает так же, как сканирование последовательности, проверяя все значения.

Но если я вставлю еще одну запись, 137-я запись не подходит. На этом этапе Postgres должен сделать что-то другое:
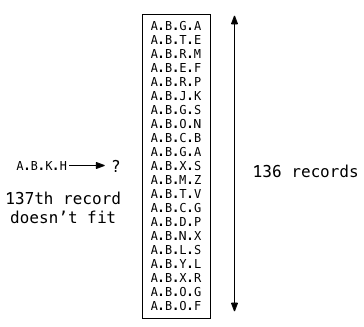
Теперь Postgres «разбивает» сегмент памяти, чтобы освободить место для большего количества значений. Он создает два новых дочерних сегмента памяти и указатели на них из родительского или корневого сегмента.
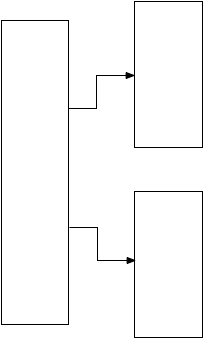
Что Postgres делает дальше? Что это помещает в каждый дочерний сегмент? Postgres оставляет это решение API GiST, расширению LTREE, вызывая ltree_picksplit функцию. Вот снова спецификация API для PickSplit:

ltree_picksplit Функция — реализация LTREE из сути API — сортирует пути дерев в алфавитном порядке и копию каждой половины в одну из двух новых сегментов ребенка. Обратите внимание, что индексы GiST обычно не сортируют свое содержимое; однако индексы GiST, созданные специально с помощью расширения LTREE, делают это из-за способа ltree_picksplitработы. Мы увидим, почему он сортирует данные в данный момент.
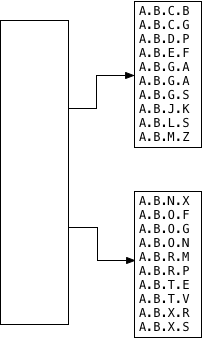
Теперь Postgres должен решить, что оставить в корневом сегменте. Для этого он вызывает API-интерфейс Union GiST:

В этом примере каждый из дочерних сегментов является набором S. И ltree_union функция должна возвращать «объединенное» значение для каждого дочернего сегмента, которое как-то описывает, какие значения присутствуют в этом сегменте:
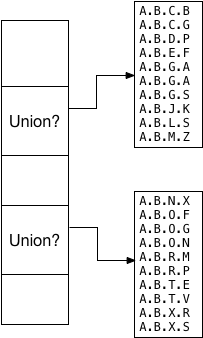
Олег и Теодор решили, что это значение объединения должно быть парой левых / правых значений, указывающих минимальную и максимальную ветви дерева, внутри которых все значения соответствуют алфавиту. Вот почему функция ltree_picksplit сортирует значения. Например, поскольку первый дочерний сегмент содержит отсортированные значения от ABCB до ABMZ, объединение слева / справа становится A и ABM:
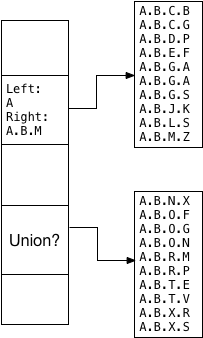
Обратите внимание, что A.B.M здесь достаточно сформировать объединенное значение, исключая A.B.N.X и все следующие значения; LTREE не нужно сохранять A.B.M.Z.
Аналогично, левый / правый союз для второго дочернего сегмента становится A.B.N/ A.B.X:
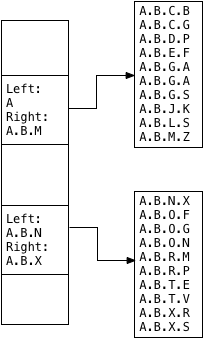
Вот как выглядит индекс GiST — или, в частности, как выглядит индекс LTREE GiST. Сила API GiST заключается в том, что любой может использовать его для создания индекса Postgres для любого типа данных. Postgres всегда будет использовать один и тот же шаблон: родительская индексная страница содержит набор значений объединения, каждое из которых так или иначе описывает содержимое каждой дочерней индексной страницы.
Для индексов LTREE GiST Postgres сохраняет пары левых / правых значений, чтобы описать объединение значений, которые появляются в каждом дочернем сегменте индекса. Для других типов индексов GiST значения объединения могут быть любыми. Например, индекс GiST может хранить географическую информацию, такую как координаты широты / долготы, или цвета, или любые данные вообще. Важно то, что каждое значение объединения описывает набор возможных значений, которые могут появляться в определенной ветви индекса. Как и в случае с B-деревьями, этот шаблон объединенного значения / дочерней страницы является рекурсивным: индекс GiST может содержать миллионы значений в дереве, а многие страницы сохраняются в большом многоуровневом дереве.
Поиск в индексе GiST
После создания этого дерева индексов GiST поиск значения является простым. Postgres использует функцию ltree_consistent. В качестве примера давайте повторим тот же SQL-запрос сверху:
select count(*) from tree where path <@ 'A.B.T'Чтобы выполнить это, используя индекс GiST, Postgres перебирает значения объединения в корневом сегменте памяти и вызывает ltree_consistent функцию для каждого из них:
Теперь Postgres передает каждое значение объединения ltree_consistentдля вычисления p <@ q формулы. Код внутри ltree_consistentзатем возвращает MAYBE if q > left и q < right. В противном случае он возвращается NO.
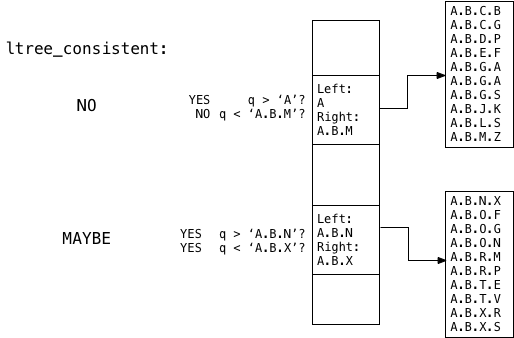
В этом примере вы можете увидеть ltree_consistentнаходки , что запрос A.B.T, или q, MAYBE расположен внутри второго сегмента детской памяти, но не первый.
Для первой структуры дочернего союза ltree_consistentнаходит, q > A true но q < A.B.M неверно. Следовательно, он ltree_consistentзнает, что в верхнем дочернем сегменте не может быть совпадений, поэтому он переходит ко второй структуре объединения.
Для второй структуры дочернего объединения ltree_consistentнаходит как q > A.B.N истина, так и q < A.B.Xистина. Следовательно, он возвращает MAYBEзначение, означающее, что поиск продолжается в нижнем дочернем сегменте:

Обратите внимание, что Postgres никогда не приходилось искать первый дочерний сегмент: древовидная структура ограничивает сравнение только необходимыми значениями p <@ A.B.T.
Представьте, что моя таблица содержит миллион строк. Поиск с использованием индекса GiST будет по-прежнему быстрым, поскольку дерево GiST ограничивает область поиска. Вместо выполнения p <@ q на каждой из миллиона строк, Postgres нужно запускать p <@ q всего несколько раз, на нескольких записях объединения и на дочерних сегментах дерева, которые содержат значения, которые могут совпадать.
Отправить им открытку
Олег Бартунов и Теодор Сигаев, авторы расширения LTREE, объясняют его использование и алгоритмы, которые я подробно описал выше, здесь, на их веб-странице . Они включали больше примеров поиска SQL по древовидным данным, в том числе те, которые используют LTREE[] тип данных, который я не успел осветить в этих сообщениях в блоге.
Но самое главное, они включили эту заметку внизу:

Вы сохраняете данные дерева в Postgres? Использует ли ваше приложение расширение LTREE? Если это так, отправьте Олегу и Теодору открытку! Я только что сделал.