В обсуждении предыдущего поста из нашей серии мы упомянули две основные причины, по которым моделирование данных RDF (и, следовательно, механизмы запросов SPARQL ) невыгодно с интерактивным и ассоциативным исследованием данных и интеграцией данных QlikView и Qliksense . Это наименования предикатных терминов, которые связывают ресурсы и литералы и однонаправленный архитектурный дизайн ребер.
Мы уже продемонстрировали эту проблему с дизайном схемы ассоциативной модели домена Movies во Freebase ( рисунок 10 ), моделированием нашего примера игрушки из каталога Supplier-Parts-Catalog в предложениях, рисунок 15 , рисунок 16 , и графиком свойств OrientDB ( рисунок 4 ) В этом посте мы продолжим наше путешествие с ассоциативной моделью данных Qlik.
Ассоциативная архитектура в памяти Qlik
Конкурентное преимущество Qlik перед другими инструментами BI заключается в том, что он управляет ассоциациями в памяти на уровне механизма, а не на уровне приложения. Это управление данными глубоко на атомарном уровне данных ( гранулярность ), т. Е. Каждая точка данных в каждом поле таблицы связана с любой другой точкой данных в любом месте всей схемы. Мы будем следовать пошаговому подходу механизма Qlik’x QIX с целью интерактивного исследования данных нашего набора данных поставщиков-запчастей.
Загрузка данных
Первый шаг — перенести данные в память. Создана многотабличная модель только для чтения, сжатая, двоичная, столбцовая в памяти. Данные из каждой исходной таблицы данных преобразуются в два типа структур данных в памяти .
- Набор столбцов, которые содержат двоичные значения, то есть ссылки, для каждого отдельного исходного значения .
- Сжатая таблица двоичных данных путем замены каждой ячейки строки и столбца значением двоичной ссылки .
Например, эти операторы о синтаксисе скрипта QlikView загружают данные из таблиц Parts и Suppliers , которые хранятся в файлах Excel, и восстанавливают одиннадцать уникальных столбцов и два двоичных представления этих таблиц только для чтения в памяти.
LOAD prtID, prtName, prtColor, prtWeight, prtUnit
FROM [F:\tmp\SupplierPartCatalogue\SuppliersPartsCatalogue.xlsx]
(ooxml, embedded labels, table is Part);
LOAD supID, supName, supAddress, supCity, supCountry, supStatus
FROM [F:\tmp\SupplierPartCatalogue\SuppliersPartsCatalogue.xlsx]
(ooxml, embedded labels, table is Supplier);Если два поля имеют одно и то же имя в двух разных таблицах (то есть, отношение), то они имеют одинаковое столбчатое двоичное представление. Чтобы устранить неоднозначности и связать поля с одинаковыми именами, требуется уникальное именование столбцов. Это относится к нашей третьей ассоциативной, т. Е. Бридж, соединительной таблице. Имена полей catSIDи catPIDуже были загружены и представлены с колонками supIDи prtID. Следующий LOADоператор использует псевдоним operator ( as) для обработки уникального именования столбцов.
LOAD catSID as supID, catPID as prtID, catPrice, catTotal, catDate, catChk
FROM [F:\tmp\SupplierPartCatalogue\SuppliersPartsCatalogue.xlsx]
(ooxml, embedded labels, table is Catalogue);
Рисунок 1: QlikView внутреннее / исходное табличное представление.
После выполнения скрипта мы можем просмотреть структуру таблицы данных с помощью средства просмотра таблиц. Три таблицы связаны с двумя соединителями, которые двунаправленно связывают их через свои общие поля. Этот макет очень похож на схему сущностей-отношений схемы базы данных Microsoft Access . Ассоциация QlikView напоминает естественное внешнее соединение SQL. Однако внешнее соединение в SQL является однонаправленным. Ассоциация всегда приводит к полной (двунаправленной) связи. На практике у нас есть два совершенно разных подхода. В типичном запросе на соединение SQL мы неоднократно ищем индекс из-за условия соединения.
Ассоциативный механизм QlikView (QIX) знает, как связана каждая точка данных, поэтому он может эффективно определять (выводить) и помечать все различные значения столбцов и все строки в каждой таблице данных по выбору пользователя. — Фергюсон
Слепое пятно
В зависимости только от памяти, QlikView может загружать много целых таблиц без объединений вместо ограниченного представления из основного набора данных. Другие основанные на запросах инструменты BI обычно объединяют извлеченное подмножество данных и возвращают его в форме набора результатов. Этот набор результатов полностью отделен от исходного набора данных, и этот акт извлечения нарушает ассоциации. Например, выясните, как часть данных, содержащихся в запросе, связана с другой частью данных вне запроса .
Можно подумать и об аналогии с двигателем внутреннего сгорания. С помощью основанной на запросе парадигмы мы будем рассматривать отдельные части движка изолированно (см. Изображение заголовка нашего поста). Используя ассоциативную технологию QlikView, мы получаем доступ к цифровой модели полностью работающего движка и можем настроить любую деталь, чтобы увидеть, как это влияет на другие детали и движок в целом.
Исследуйте и фильтруйте данные с помощью выбора
В этом разделе мы рассмотрим ассоциативный аспект QlikView с точки зрения пользовательского опыта.
Центральное место в QlikView занимает концепция пользовательского состояния выбора. Когда пользователи щелкают в документе QlikView, они указывают, какие подмножества данных они заинтересованы в анализе и какие подмножества следует игнорировать.
—
QlikView Whitepaper
Чтобы продемонстрировать визуальный эффект ассоциаций, т. Е. Взаимосвязи между значением в одном поле и значением в другом, мы разместили несколько объектов листа в нашей основной рабочей таблице. Мы выбрали табличные блоки для представления строк данных из наших таблиц и списков для отображения списка всех возможных значений определенного поля. Мы также добавили поле текущего выбора, чтобы перечислить значения выбранных пользователем полей и объект поиска для поиска информации в любом месте документа .

Рисунок 2: Объект листа QlikView в невыбранном состоянии с полями таблицы, текущими выделениями и полем поиска с левой стороны, а также контейнером со списками для полей в правой части.
Теперь вы можете визуально увидеть, что связано и не связано с каким-либо конкретным выбором. Например, на рисунке 3 показано состояние нашей рабочей таблицы, когда пользователь выбрал элемент Part со значением ID, равным 998. List BoxПоля (prtID) со значением 998отображается зеленым цветом , и он также был добавлен в Current Selectionsсписок.
В других случаях List Boxesнесвязанные значения во всех других полях отображаются серым, а те, которые связаны, отображаются белым. В то же время, когда пользователь взаимодействует с этим конкретным объектом, List Boxвсе строки Table Boxesмгновенно фильтруются для отражения этого нового контекста.
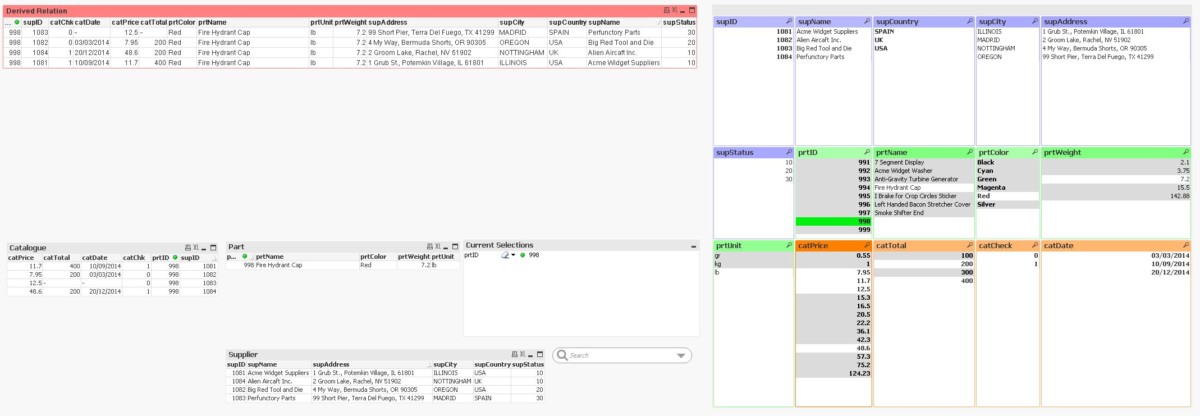
Рисунок 3: Табличные поля слева фильтруются, а значения списков справа отображаются белым или серым цветом в соответствии с текущим выбором (зеленый).
До сих пор мы видели, как мы можем получить результирующие данные после выбора пользователя в двух возможных форматах: список значений ( List Box) для каждого поля таблицы данных и сетка ( Table Box) с кортежами (записями). Вы также можете заметить в нашей визуальной настройке, что у нас есть Derived Relationкрасная сетка с выбранными полями из всех трех таблиц нашего набора данных. Эта сетка автоматически создается из тех кортежей, которые появляются в трех других сетках ( Catalogue Table Box, Part Table Boxи Supplier Table Box).
Мы должны прояснить, что это обновление Derived Relationне выполняет никаких операций Join (SQL) . Эффект фильтрации кортежей и затенения значений списка демонстрируется с помощью анимированных изображений GIF в трех состояниях. Есть невыбранное состояние, затем есть состояние с 998выбранным значением детали с идентификатором , и из этих Catalogзаписей для этого конкретного Part(4 записи, по одной для каждой Supplier) мы выбираем Supplierс минимальной Catalogценой, и это наше третье состояние.

Рисунок 4: Анимированные сетки кортежей.
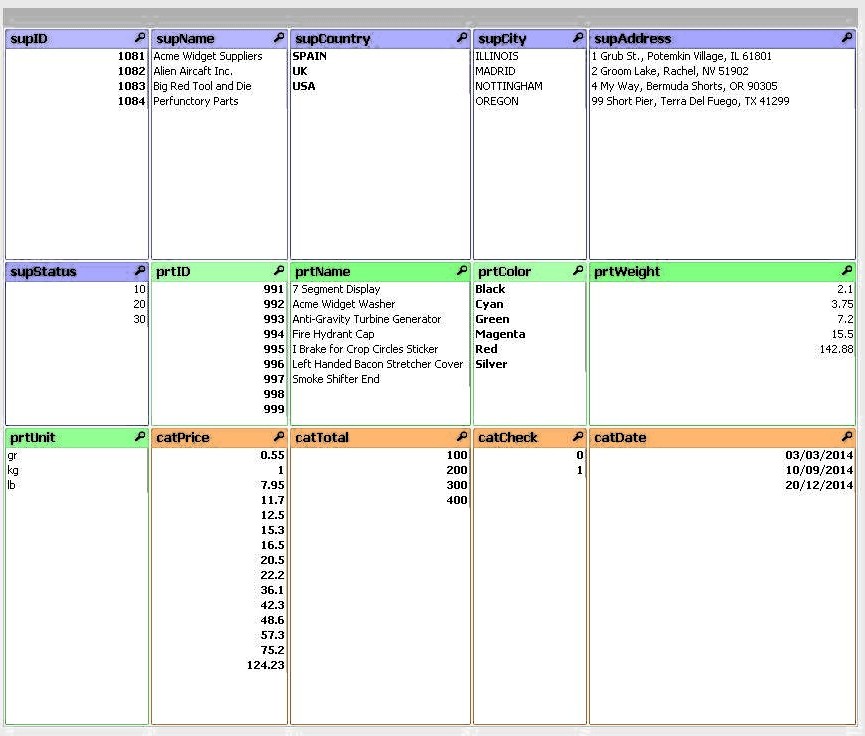
Рисунок 5: Анимированные списки значений из полей таблицы.
Представление гиперграфа R3DM
С ассоциативным моделированием данных может быть третий способ представления данных. Это тот, который привлекает пользователя к визуализации сетевых графиков. В предыдущем посте нашей серии мы нарисовали гиперграф R3DM и описали ассоциации в соответствии с терминологией R3DM. Мы использовали точно такие же данные из этого примера, например, нашли Поставщика с минимальной ценой по каталогу для части со prtIDстоимостью 998, чтобы нарисовать рисунки с 1 по 5.
На этот раз мы перерисовали гиперграф на рисунке 14 с помощью редактора графиков OrientDB , рисунок 6 . Каждая строковая метка и числовое значение на рисунке 14 были заменены уникальным идентификатором записи OrientDB (RID — clusterID: clusterPosition) . По сути, это то , как мы реализовали R3DM / S3DM Signслой . Каждый элемент данных становится элементом атомного информационного ресурса (AIR) с символическим представлением 2D-вектора (тип объекта / атрибута: экземпляр).
Воздушные Единицы
Единицы AIR могут единообразно представлять все, что угодно, т.е. объекты, атрибуты, значения, типы, базы данных и т. Д. Их векторная форма может быть проиндексирована, связана, извлечена, эффективно сохранена, и мы можем использовать единицы AIR для создания ассоциаций и усвоения составной информации. структуры, такие как записи (кортежи).
Чтобы визуализировать ассоциации R3DM с использованием модулей AIR, мы пометили цветовую диаграмму графика и добавили легенду в левой части рисунка 6. Объекты отличаются от атрибутов размером диска, а группировка объектов и атрибутов обозначена разными оттенками цвет (зеленый для поставщиков, коричневый для деталей, фиолетовый для элементов каталога).
Мы можем легко увидеть четыре Catalogэлемента (# 70: 7, # 70: 11, # 70: 12, # 70: 16), связанные с четырьмя Suppliers(# 68: 0, # 68: 1, # 68: 2, # 68: 3) и Part(# 69: 7) со значением ID 998(# 77: 7), которое рисуется в центре графика с черным диском вокруг него. Американские поставщики (# 68: 0, # 68: 1) разделяют значение своего общего supCountryатрибута (# 75: 0). Один из них (# 68: 1) имеет запись в каталоге (# 70: 11) с минимальной ценой каталога catPrice, (# 82: 9). Мы также можем увидеть формирование кортежей для поставщика (4), каталога (4) и части (1).

Рис. 6: Цветовые ассоциации R3DM с устройствами AIR.
Что касается огромного преимущества использования модулей AIR для реконструкции иерархических, табличных или графических структур, мы также можем обратиться к следующему патенту QlikTech. В разделе « Краткое описание изобретения » мы читаем:
Каждому отдельному значению элемента данных каждого типа элемента данных назначается двоичный код, а записи данных хранятся в двоично-кодированном виде. Из-за двоичного кодирования в таблицах можно проводить очень быстрые поиски .
Планы на будущее
Весьма прискорбно, что основа эволюционной ассоциативной технологии QlikView была ограничена рынком проприетарных программных продуктов. В HEALIS мы сделали разницу, открыв эти ключевые принципы проектирования баз данных для обсуждения с экспертами в данной области, и мы сделали их частью нашей концептуальной структуры R3DM / S3DM.
Мы пошли еще дальше, чтобы реализовать нашу инфраструктуру поверх СУБД OrientDB и Intersystems Cache, и вместо написания SQL-запросов мы абстрагировали программирование набора функциональных операций, соответствующих выбору и фильтрации данных. Мы планируем продолжить с последней частью этой серии статей, чтобы полностью продемонстрировать, как мы строим нашу систему и как мы тестируем ее с набором данных Suppliers-Parts-Catalog.