Помимо сохранения и извлечения данных, основной функцией реляционной базы данных является возможность выполнять запросы соединения, связывать данные в одной таблице с данными из другой. Хотя многие разработчики обращаются к решениям NoSQL, объединение одного набора значений данных с другим остается одним из наиболее распространенных и важных случаев использования при написании кода сервера.
Но что на самом деле означает слово «присоединиться»? И что на самом деле происходит, когда я выполняю запрос соединения? Слишком часто мы принимаем наши инструменты как должное, не понимая, что они делают. В этом месяце я решил взглянуть на исходный код популярного сервера баз данных с открытым исходным кодом PostgreSQL , чтобы узнать, как он реализует запросы на соединение.
Чтение и экспериментирование с исходным кодом Postgres оказалось отличным опытом обучения. Сегодня я хотел бы сообщить о своих наблюдениях; Я покажу вам, как Postgres выполнил крошечное соединение, состоящее из нескольких записей, используя алгоритм хеш-соединения . В следующих статьях я покажу вам некоторые интересные оптимизации, которые Postgres использует для больших объединений, и другие алгоритмы информатики, работающие внутри Postgres.
Что такое соединение?
Но прежде чем мы перейдем к исходному коду Postgres, давайте начнем с рассмотрения запросов на соединение. Вот введение из превосходной документации Postgres :

Затем в документах Postgres объясняется, как использовать объединения: внутренние и внешние объединения, соединение таблицы с самим собой и т. Д. Но я заинтригован выделенным отказом от ответственности. Что это за «более эффективный способ»? И как может Postgres обойтись без «фактического сравнения каждой возможной пары строк»?
Крошечное соединение
В качестве примера сегодня давайте поработаем с двумя таблицами: публикациями , которые содержат три новаторские статьи в журналах по информатике, которые я никогда не читал в колледже, и авторами , в которых записывается, где работал каждый автор.
> select * from publications;
title | author | year
--------------------------------------------------------+------------+------
A Relational Model of Data for Large Shared Data Banks | Edgar Codd | 1970
Relational Completeness of Data Base Sublanguages | Edgar Codd | 1972
The Transaction Concept: Virtues and Limitations | Jim Gray | 1981
(3 rows)
> select * from authors;
name | company
------------+-------------------------
Edgar Codd | IBM Research Laboratory
Jim Gray | Tandem Computers
(2 rows)
Сегодняшняя цель — понять, что именно происходит, когда Postgres соединяет одну таблицу с другой:
> select title, company from publications, authors where author = name;
title | company
--------------------------------------------------------+-------------------------
Relational Completeness of Data Base Sublanguages | IBM Research Laboratory
A Relational Model of Data for Large Shared Data Banks | IBM Research Laboratory
The Transaction Concept: Virtues and Limitations | Tandem Computers
(3 rows)
Концептуальная модель для объединения двух таблиц
Прежде чем мы рассмотрим алгоритм, который фактически использует Postgres, давайте рассмотрим, что концептуально делают запросы соединения. Выше документации говорилось, что Postgres реализует объединения, «сравнивая каждую возможную пару строк», а затем выбирая «пары строк, в которых эти значения совпадают».
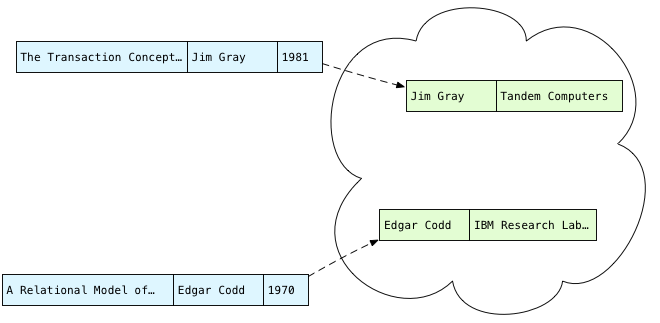
Читая это, я думаю, Postgres берет каждую публикацию и просматривает всех авторов, ища автора этой публикации:

Синим цветом слева находятся публикации, а справа я показываю записи автора зеленым цветом. Этот процесс перебора строк в таблице авторов называется сканированием в исходном коде Postgres. Мы просматриваем всех авторов для первой публикации, пытаясь найти подходящие имена.
Что мы делаем с каждой парой публикация-автор? Мы должны оценить предложение WHERE из моего примера оператора SQL:

Соответствуют ли имена? Да. Эта пара должна быть включена в набор результатов. Как насчет второй пары?
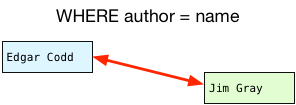
Эти имена совпадают? На этот раз они не — эта пара строк должна быть отфильтрована.
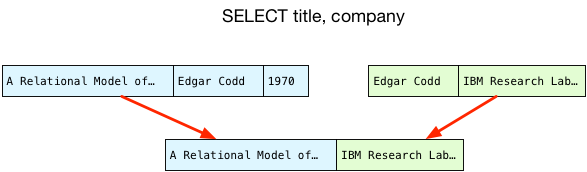
Как только у нас есть подходящая пара строк, мы копируем только выбранные столбцы в новую объединенную запись и возвращаем ее клиенту:
Вложенная петля
Что не так с этой концептуальной моделью? Это кажется очень простым, простым способом получения необходимых нам ценностей. Если мы перейдем к сканированию остальных публикаций, он даст тот же результат, что и Postgres, хотя и в другом порядке. (Мы увидим, почему заказ меняется позже.)
Проблема в том, что это очень неэффективно. Сначала мы просматриваем всех авторов для первого ряда в таблице публикаций:

И затем, мы повторяем ту же проверку таблицы авторов для второй публикации:

И снова для третьего ряда. Чтобы найти все совпадающие пары, нам нужно перебрать всех авторов для каждой публикации:

Для моего крошечного запроса это не проблема. Есть 3 * 2 или 6 комбинаций строк; сравнение имен 6 раз займет всего несколько микросекунд на современном компьютере. Однако по мере увеличения числа строк в любой из таблиц общее число сравнений будет взорвано. Если у нас 1000 публикаций и 1000 авторов, вдруг нам придется сравнивать строки имен 1000 * 1000 или 1 миллион раз! Компьютерные ученые описывают этот алгоритм как O (n 2 ).
Но нужно ли искать всю таблицу авторов по каждой публикации? «Эдгар Кодд» появляется в таблице публикаций дважды — зачем нам сканировать таблицу авторов на одно и то же имя более одного раза? После того как мы в первый раз найдем Эдгара, должен быть способ записи, где он был, чтобы мы могли найти его снова. И, даже если в публикациях не было повторных имен авторов, все равно кажется расточительным перебирать таблицу авторов снова и снова. Должен быть какой-то способ избежать всех этих повторных сканирований.
И есть; мы можем использовать хеш-таблицу .
Как избежать повторных сканирований
Проблема нашего наивного алгоритма, концептуальной модели из документации Postgres, заключается в том, что мы снова и снова перебираем таблицу авторов. Чтобы избежать этих повторяющихся циклов, представьте, что мы сканировали авторов только один раз, а затем сохранили их в какой-то структуре данных:
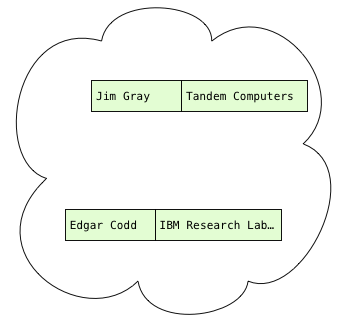
Теперь, когда у нас есть записи об авторах, что нам с ними делать? Что ж, мы должны отсканировать публикации, найти автора каждой публикации и найти подходящие записи автора, если таковые имеются. Другими словами, мы должны иметь возможность быстро и легко найти запись автора с заданным именем:
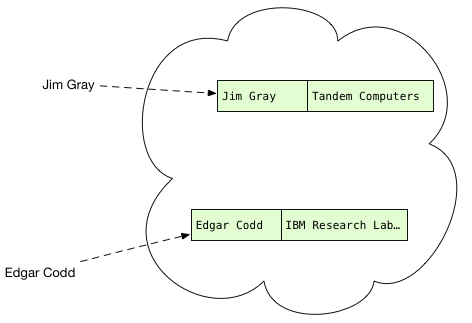
Вы, наверное, видели эту структуру данных раньше; фактически это может быть то, что вы используете каждый день в своем собственном коде. Если вы такой же Rubyist, как я, вы называете это хешем . Если вы предпочитаете Python, это словарь , или в Clojure это хеш-карта .
Со всеми авторами, упорядоченными по их именам, мы можем просмотреть публикации и быстро выяснить, есть ли подходящая запись об авторе:
Но что такое хеш-таблицы? И как они работают? Если бы мы только могли вернуться в прошлое и снова пробраться в наш класс по информатике в колледже. Но если вы установили Postgres из исходного кода, используя Homebrew или какой-то менеджер пакетов Linux, у вас уже есть реализация алгоритма хеш-таблицы с открытым исходным кодом мирового класса прямо на вашем компьютере! Чтобы узнать больше об этом, все, что нам нужно сделать, это прочитать исходный код Postgres.
Расчет хэшей
Оказывается, что для этого запроса Postgres фактически хеширует публикации, а затем перебирает авторов. Прежде чем начать выполнение запроса, Postgres сначала анализирует тот SQL, который мы ему даем, и генерирует «план запроса». Возможно, из-за того, что таблица публикаций больше (я не уверен), планировщик запросов Postgres решает сохранить публикации, а не авторов, в хэш-таблице.
Для этого Postgres должен сканировать публикации так же, как мы это делали выше:

И для каждой публикации Postgres выбирает только два из трех столбцов: автор и заголовок. Postgres ссылается на план запроса и выясняет, что ему понадобится автор для условия соединения WHERE, а также заголовок для финального SELECT, возвращающего набор результатов. Это оставляет значения года позади.

Эдгар Кодд
Этот процесс выбора требуемых атрибутов из соответствующей пары известен в исходном коде Postgres C как проекция . Мы «проецируем» несколько значений из одного набора столбцов в другой. (Термин « проект» на самом деле намного старше, чем Postgres; Эдгар Кодд впервые использовал его в этом контексте в реляционной модели данных для больших общих банков данных еще в 1970 году.)
Далее Postgres вычисляет хеш на основе строки автора. Хеш — это некое целое число, которое можно быстро вычислить воспроизводимым и воспроизводимым способом. Для одной и той же строки автора, например, «Эдгар Кодд», Postgres всегда вычисляет один и тот же хэш-номер. Как мы увидим через некоторое время, Postgres использует значение хеш-функции, чтобы решить, где сохранить имя автора в хеш-таблице.
Вы можете найти алгоритм хэширования Postgres в C-файле с именем hashfunc.c. Даже если вы не являетесь разработчиком C, есть обширные комментарии к коду, объясняющие, что происходит, а также ссылка на статью, написанную Бобом Дженкинсом , который разработал алгоритм в 1997 году.
(метод «hash_any» — просмотр на postgresql.org )
В моем примере Postgres передает «Edgar Codd», строковое значение в столбце автора в первой записи публикации, hash_any. Сложные побитовые вычисления в hash_any перебирают символы в имени Эдгара и возвращают это значение хеша:
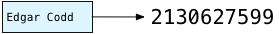
(Оставайтесь с нами для части 2 этой записи.)