Avro имеет малоизвестную жемчужину функции, которая позволяет вам контролировать, какие поля в записи Avro используются для разделения , сортировки и группировки в MapReduce. На следующем рисунке показано, что означают эти термины. Да, и не принимайте буквально расположение «сортировки» — сортировка фактически происходит как на карте, так и на стороне сокращения — но она всегда выполняется в контексте определенного раздела (т.е. для определенного редуктора).
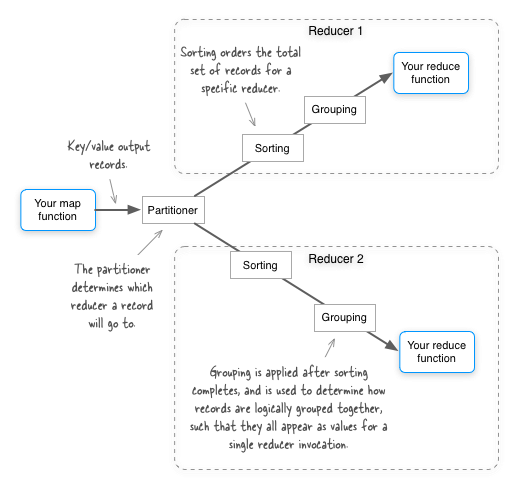
По умолчанию все поля в выходном ключе карты Avro используются для разделения, сортировки и группировки в MapReduce. Давайте рассмотрим пример и посмотрим, как это работает. Вы начнете с простой схемы GitHub source :
{"type": "record", "name": "com.alexholmes.avro.WeatherNoIgnore",
"doc": "A weather reading.",
"fields": [
{"name": "station", "type": "string"},
{"name": "time", "type": "long"},
{"name": "temp", "type": "int"},
{"name": "counter", "type": "int", "default": 0}
]
}
Мы посмотрим, что произойдет, когда мы запустим этот код для небольшого примера набора данных, который мы сгенерируем, используя исходный код Avro GitHub :
File input = tmpFolder.newFile("input.txt");
AvroFiles.createFile(input, WeatherNoIgnore.SCHEMA$, Arrays.asList(
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(1).setTemp(3).build(),
WeatherNoIgnore.newBuilder().setStation("IAD").setTime(1).setTemp(1).build(),
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(2).setTemp(1).build(),
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(1).setTemp(2).build(),
WeatherNoIgnore.newBuilder().setStation("SFO").setTime(1).setTemp(1).build()
).toArray());
Чтобы понять, как Avro разбивает, сортирует и группирует данные, мы напишем средство отображения и редуктор с небольшим улучшением редуктора, чтобы увеличить counter поле для каждой записи, которую мы видим в отдельном экземпляре источника GitHub редуктора :
package com.alexholmes.avro.sort.basic;
import com.alexholmes.avro.WeatherNoIgnore;
import org.apache.avro.mapred.AvroKey;
import org.apache.avro.mapred.AvroValue;
import org.apache.avro.mapreduce.AvroJob;
import org.apache.avro.mapreduce.AvroKeyInputFormat;
import org.apache.avro.mapreduce.AvroKeyOutputFormat;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class AvroSort {
private static class SortMapper
extends Mapper<AvroKey<WeatherNoIgnore>, NullWritable,
AvroKey<WeatherNoIgnore>, AvroValue<WeatherNoIgnore>> {
@Override
protected void map(AvroKey<WeatherNoIgnore> key, NullWritable value, Context context)
throws IOException, InterruptedException {
context.write(key, new AvroValue<WeatherNoIgnore>(key.datum()));
}
}
private static class SortReducer
extends Reducer<AvroKey<WeatherNoIgnore>, AvroValue<WeatherNoIgnore>,
AvroKey<WeatherNoIgnore>, NullWritable> {
@Override
protected void reduce(AvroKey<WeatherNoIgnore> key,
Iterable<AvroValue<WeatherNoIgnore>> values, Context context)
throws IOException, InterruptedException {
int counter = 1;
for (AvroValue<WeatherNoIgnore> WeatherNoIgnore : values) {
WeatherNoIgnore.datum().setCounter(counter++);
context.write(new AvroKey<WeatherNoIgnore>(WeatherNoIgnore.datum()),
NullWritable.get());
}
}
}
public boolean runMapReduce(final Job job, Path inputPath, Path outputPath)
throws Exception {
FileInputFormat.setInputPaths(job, inputPath);
job.setInputFormatClass(AvroKeyInputFormat.class);
AvroJob.setInputKeySchema(job, WeatherNoIgnore.SCHEMA$);
job.setMapperClass(SortMapper.class);
AvroJob.setMapOutputKeySchema(job, WeatherNoIgnore.SCHEMA$);
AvroJob.setMapOutputValueSchema(job, WeatherNoIgnore.SCHEMA$);
job.setReducerClass(SortReducer.class);
AvroJob.setOutputKeySchema(job, WeatherNoIgnore.SCHEMA$);
job.setOutputFormatClass(AvroKeyOutputFormat.class);
FileOutputFormat.setOutputPath(job, outputPath);
return job.waitForCompletion(true);
}
}
Если вы посмотрите на выходные данные задания ниже, вы увидите, что выходные данные отсортированы по всем полям, и что сортировка происходит по порядку полей. Это означает, что когда MapReduce сортирует эти записи, station сначала сравнивается поле, затем time поле и т. Д. В соответствии с порядком расположения полей в схеме Avro. Это в значительной степени то, что вы ожидаете, если напишите свой собственный сложный Writable тип, и ваш компаратор сравнил все поля по порядку.
{"station": "IAD", "time": 1, "temp": 1, "counter": 1}
{"station": "SFO", "time": 1, "temp": 1, "counter": 1}
{"station": "SFO", "time": 1, "temp": 2, "counter": 1}
{"station": "SFO", "time": 1, "temp": 3, "counter": 1}
{"station": "SFO", "time": 2, "temp": 1, "counter": 1}
Да, и прежде чем мы обратим внимание на то, что значение для counter поля всегда 1, это означает, что каждому редуктору была подана только одна пара ключ / vaue, что имеет смысл, поскольку наш преобразователь идентификаторов выдал только одно значение для каждого ключа, ключи уникальный, а разделитель, сортировщик и группировщик MapReduce использовали все поля в записи.
Исключая поля для сортировки
Avro дает нам возможность указать, что определенные поля следует игнорировать при выполнении функций упорядочения. В MapReduce эти поля игнорируются для сортировки / разбиения и группировки в MapReduce, что в основном означает, что у нас есть возможность выполнить вторичную сортировку. Давайте рассмотрим следующую схему GitHub source :
{"type": "record", "name": "com.alexholmes.avro.Weather",
"doc": "A weather reading.",
"fields": [
{"name": "station", "type": "string"},
{"name": "time", "type": "long"},
{"name": "temp", "type": "int", "order": "ignore"},
{"name": "counter", "type": "int", "order": "ignore", "default": 0}
]
}
Она в значительной степени идентична первой схеме, с той лишь разницей, что последние два поля помечаются как «игнорируемые» для сортировки / разбиения / группировки. Давайте запустим тот же (но не модифицированный для работы с другой схемой) исходный код GitHub кода MapReduce, как описано выше, для этой новой схемы и изучим выходные данные.
{"station": "IAD", "time": 1, "temp": 1, "counter": 1}
{"station": "SFO", "time": 1, "temp": 3, "counter": 1}
{"station": "SFO", "time": 1, "temp": 2, "counter": 2}
{"station": "SFO", "time": 1, "temp": 1, "counter": 3}
{"station": "SFO", "time": 2, "temp": 1, "counter": 1}
Есть несколько заметных различий между этим выводом и выводом из предыдущей схемы, в которой не было пропущенных полей. Во-первых, ясно, что temp поле не используется при сортировке, что имеет смысл, поскольку мы указали, что оно должно игнорироваться в схеме. Однако, что более интересно, обратите внимание на значение counter поля. Все записи , которые имели одинаковые station и time значения пошли в тот же редуктор вызова, свидетельствует рост стоимости counter. Это по сути вторичный вид!
Теперь все это величие не без ограничений:
- Вы не можете поддерживать два задания MapReduce, которые используют один и тот же ключ Avro, но имеют разные требования к сортировке / разбиению / группированию. Хотя вполне возможно, что вы можете создать новый экземпляр схемы Avro и установить флажки игнорирования для этих полей самостоятельно.
- Функции работы с разделителями, сортировщиками и группировками в MapReduce работают от одних и тех же полей (т. Е. Все они игнорируют поля, которые установлены как игнорируемые в схеме). Это означает, что ваши варианты вторичной сортировки ограничены. Например, вы не сможете разделить все станции на один и тот же редуктор, а затем сгруппировать по станциям и времени.
- Порядок использует порядковый номер поля для определения его порядка в общем наборе полей, которые нужно упорядочить. Другими словами, в записи с двумя полями первое поле всегда сравнивается перед вторым. Нет никакого способа изменить это поведение, кроме изменения порядка полей в записи.
Сказав все это, функция «игнорирования полей» для сортировки довольно удивительна, и то, что, без сомнения, пригодится в моей будущей работе над MapReduce.