В середине ноября в Аргентине будет организован хороший семинар по большим данным и окружающей среде:

Мы будем много говорить о климатических моделях, и я хотел немного поиграть с данными, хранящимися здесь: http://dods.ipsl.jussieu.fr/mc2ipsl/ .
Поскольку Юэн (он же @ 3wen ) недавно работал над этими наборами данных, он любезно рассказал мне, как читать эти наборы данных (в каком- то формате ncdf ). Он показал мне интересные функции и поделился со мной некоторыми строками кода. Я упомяну некоторые из них в кратком посте, потому что я был впечатлен, увидев, что проблемы с памятью не имели большого значения, здесь … Но, прежде всего, нам нужно полдюжины пакетов
> library(ncdf)
> library(lubridate)
> library(dplyr)
> library(stringr)
> library(tidyr)
> library(ggplot2)Затем я скачаю один из этих файлов с января 2000 года по декабрь 2012 года.
> download.file("http://dods.ipsl.jussieu.fr/
mc2ipsl/CMIP5/output1/IPSL/IPSL-CM5A-MR/historicalNat/day/atmos/day/r1i1p1/latest/tas/tas_day_IPSL-CM5A-MR_historicalNat_r1i1p1_20000101-20121231.nc",destfile="temp.nc")
Эти файлы не очень большие. Но большой.
> file.size("temp.nc")
[1] 390965452Это почти файл 400Mo. Для одного файла (а на этих серверах их сотни). Теперь, если мы «прочитаем» этот файл, в R у нас будет довольно маленький объект R,
> nc <- open.ncdf("temp.nc")
> object.size(nc)
155344 bytesЭто всего 150Ko … Один из 2516 по сравнению с файлом в Интернете. Так или иначе, мы извлекаем здесь только частичную информацию. Мы полностью просканируем файл позже … Мы уже можем создать некоторые переменные, которые будут использоваться позже, такие как дата, широта, долгота и т. Д.
> lon <- get.var.ncdf(nc,"lon")
> (nlon <- dim(lon))
[1] 144
> lat <- get.var.ncdf(nc,"lat")
> nlat <- dim(lat)
> time <- get.var.ncdf(nc,"time")
> tunits <- att.get.ncdf(nc, "time", "units")
> orig <- as.Date(ymd_hms(str_replace(
tunits$value, "days since ", "")))
> dates <- orig+time
> ntime <- length(dates)Здесь у нас есть диапазон широты и долготы в наборе данных, а также дата. Теперь пришло время прочитать файл. На основании даты начала и запрашивая только температуру
> commencement <- 1
> dname <- "tas"мы можем покрасить файл
> tab_val <- get.var.ncdf(nc, dname, start=c(1,1,commencement))
> dim(tab_val)
[1] 144 143 4745
> object.size(tab_val)
781672528 bytesФайл сейчас большой, чуть меньше 800Мо.
> fill_value <- att.get.ncdf(nc, dname, "_FillValue")
> tab_val[tab_val == fill_value$value] <- NAДавайте теперь суммируем всю информацию в хороших фреймах данных, которые будут использоваться для генерации графиков.
> tab_val_vect <- as.vector(tab_val)
> tab_val_mat <- matrix(tab_val_vect, nrow =
nlon * nlat, ncol = ntime)
> lon_lat <- expand.grid(lon, lat)
> lon_lat <- lon_lat %>% mutate(Var1 =
as.vector(Var1), Var2 = as.vector(Var2))Обратите внимание, что файл по-прежнему большой (тот же размер, что и предыдущий файл, здесь мы просто изменили набор данных)
> res <- data.frame(cbind(lon_lat,
tab_val_mat))
> object.size(res)
782496048 bytesВот размер нашего набора данных
> dim(res)
[1] 20592 4747Мы можем дать понятные имена переменным
> noms <- str_c(year(dates),
+ month.abb[month(dates)] %>%
tolower, sprintf("%02s", day(dates)),
sep = "_")
> names(res) <- c("lon", "lat", noms)Теперь давайте сосредоточимся на части построения. Если мы сосредоточимся на Европе, нам нужно отфильтровать набор данных
> res <- res %>%
mutate(lon = ifelse(lon >= 180, yes = lon -
360, no = lon)) %>%
filter(lon < 40, lon > -20, lat < 75,
lat > 30) %>%
gather(key, value, -lon, -lat) %>%
separate(key, into = c("year", "month",
"day"), sep="_")Пусть использовать фильтр, только с 1986 по 2005 годы
> temp_moy_hist <- res %>%
+ filter(year >= 1986, year <= 2005) %>%
+ group_by(lon, lat, month) %>%
+ summarise(temp = mean(value, na.rm = TRUE)) %>%
+ ungroupТеперь мы можем построить это. С температурой в Европе в месяц.
> ggplot(data = temp_moy_hist,
aes(x = lon, y = lat, fill = temp)) +
geom_raster() + coord_quickmap() +
facet_wrap(~month)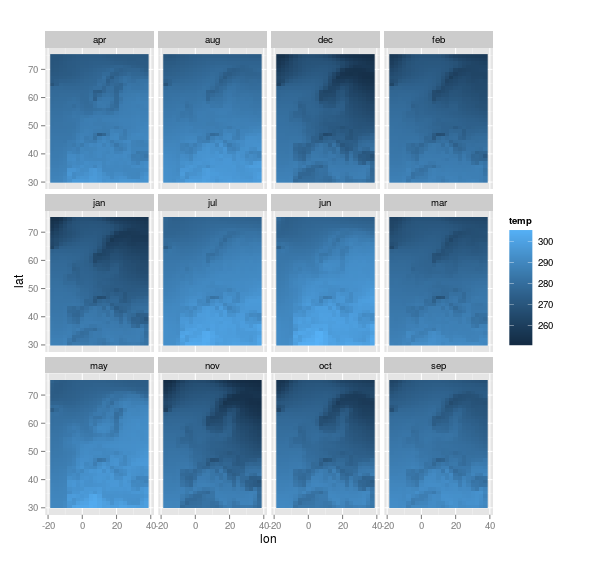
На самом деле, можно добавить контурные линии европейских стран,
> download.file(
"http://freakonometrics.free.fr/carte_europe_df.rda",destfile="carte_europe_df.rda")
> load("carte_europe_df.rda")Если мы агрегируем весь месяц и получаем только один график, мы имеем
> ggplot() +
geom_raster(data = temp_moy_hist,
aes(x = lon, y = lat, fill = temp)) +
geom_polygon(data = carte_pays_europe,
aes(x=long, y=lat, group=group), fill = NA,
col = "black") +
coord_quickmap(xlim = c(-20, 40),
ylim = c(30, 75))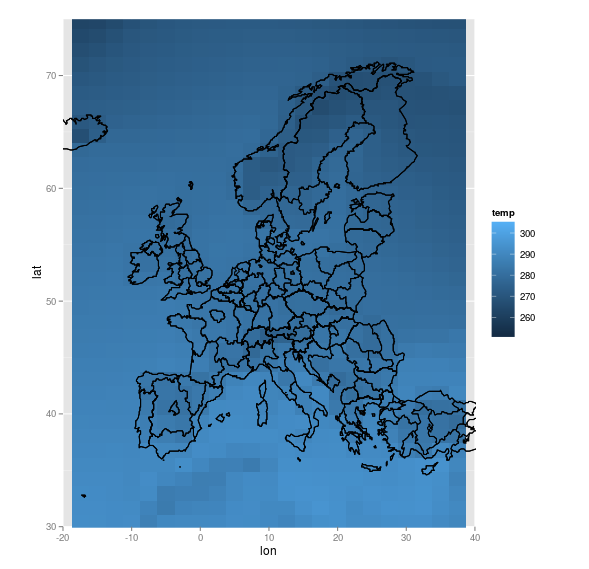
Сейчас я потрачу некоторое время на анализ карт, но меня по-настоящему впечатлили те функции, которые могут частично читать «большой» набор данных, чтобы извлечь некоторую информацию, а затем мы можем прочитать файл, чтобы создать набор данных, который можно используется для получения графика.