Привет банда! Хорошо, я вернулся с новым сообщением, на этот раз с сообщением о нескольких причудах, с которыми я столкнулся при реализации некоторых тестовых примеров для Spring Data с использованием Neo4j. Они не ошибки ни в коем случае; это просто новое поведение, к которому нужно привыкнуть, когда вы отправляетесь в мир Spring Data (который, кстати, мне очень нравится). Во время моих обширных простоев (это нужно читать, когда я воображаю, что так круто закатываю глаза, что падаю на стул), я собирал небольшую игровую площадку, чтобы можно было поиграть и поиграть с Spring Data. Это определенно развивается и меняется, когда я меняю вещи и пробую новые идеи, и я полностью планирую поделиться этим в будущих постах.
На данный момент, я просто обсуждаю пару потенциальных подводных камней, которые новички в Spring Data могут стать жертвами (прошу прощения за предложную фразу; я уверен, что она не будет последней). Общие сведения Я хотел поиграть с Spring Data более серьезно в течение некоторого времени, поэтому я начал несколько недель назад, и, должен сказать, я люблю каждую секунду этого. (Я уже большой поклонник Spring, и аннотации продолжают облегчать мою жизнь.) Моя песочница выглядит примерно так: После просмотра документации для Spring Data (особенно « Хорошие отношения »), я подумал, что Попробуйте что-то подобное для себя, заимствуя всю концепцию «магазина» (как мне кажется, лучший, первый выбор для реализации графовой базы данных).
Вместо того чтобы использовать всю концепцию «магазина фильмов», я переключился на что-то немного другое, чтобы избежать повторного использования кода (я заимствую некоторый код по ссылке выше, но изменяю ее очень много). Для любого гика моего возраста (или старше) вы помните определенного продавца компьютерных программ под названием Babbage’s . У меня приятные воспоминания о том, что я просила родителей ходить в магазин каждый раз, когда мы проходили мимо, что было не часто (по крайней мере, я так не думаю …). Корпорация GameStop продолжала приобретать Babbage (и EB Games, и кучу других продавцов программного обеспечения), так что вы вряд ли увидите Babbage под таким названием.
После этого короткого перерыва в памяти (больше похоже на тупик памяти) я решил смоделировать свой домен после концепции розничной торговли программным обеспечением. Мой магазин достаточно умно будет называться Von Neumann’s (любой майор CS и большинство гиков в настоящее время стонут от этой шутки). Модель домена В настоящее время модель домена состоит из следующего:
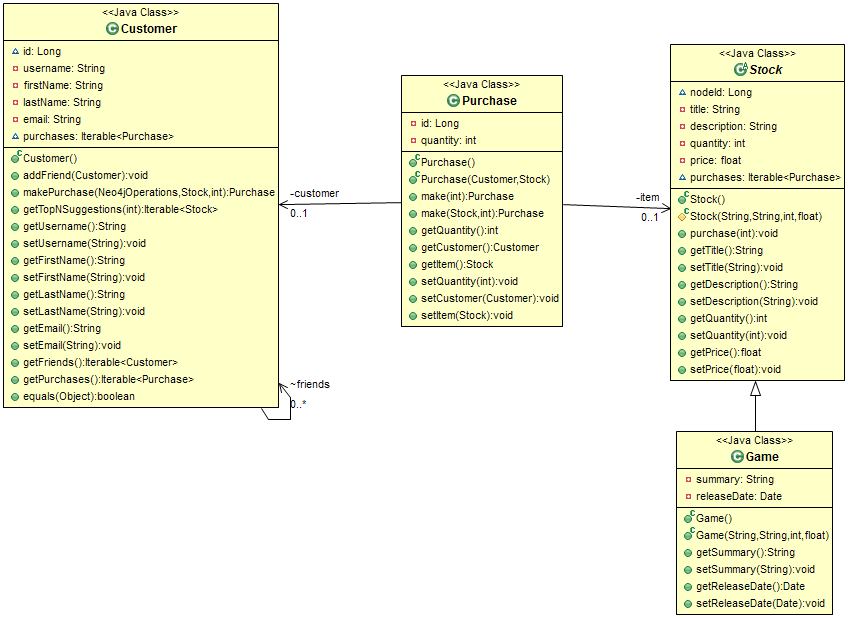
Даже глядя на диаграмму UML выше, мы видим, что она основана на графической модели (можете ли вы выбрать сущности и / или отношения (и)?). Настройка тестовых сценариев После настройки соответствующего проекта (который я сделал как проект Maven) я приступил к созданию некоторых задач с использованием JUnit. Перед созданием реальных тестовых случаев мне нужно было убедиться, что у меня настроен контекст тестирования. Мне также нужно было убедиться, что все сохраняемые данные стираются после каждого запуска. К счастью, вместо того, чтобы создавать такую функциональность для моего проекта, я узнал, что у Neo4j уже есть удобное решение! ImpermanentGraphDatabase . Этот маленький драгоценный камень можно найти в ядре Neo4j. В частности, я добавил эти строки в свой POM (вы также можете увидеть конкретную версию, которую я использую):
<dependency> <groupId>org.neo4j</groupId> <artifactId>neo4j-kernel</artifactId> <version>1.8.M03</version> </dependency>
<bean id="graphDBService" class="org.neo4j.test.ImpermanentGraphDatabase" destroy-method="shutdown"/>
И престо! Подходящая база данных графиков тестирования для моих тестовых случаев! (Предупреждение: я использую последнюю версию, которая, как мне показалось, работает лучше всего для меня и совместима со всеми моими другими зависимостями. ImpermanentGraphDatabase также доступен в более ранних версиях Neo4j.) Следует также отметить, что я использую оба Интерфейсы репозиториев Neo4j И класс Neo4jOperations для сохранения и извлечения. Еще одно замечание: я сделал весь тестовый класс @Transactional . Правильные тестовые случаи Я перечислю два из них ниже и несколько причуд, которые я заметил. Обеспечение того, что клиент может совершить покупку
Этот тестовый пример состоит из создания объекта Customer, пары объектов Game и проверки возможности создания, сохранения и извлечения покупок (вместе со связанными сущностями).
@Test
public void customerCanMakePurchases()
{
// setup our game constants
final int QTY = 1;
final String GAME_TITLE = "Space Weasel 3.5";
final String GAME_TITLE_2 = "The Space Testing Game";
final String GAME_DESC = "Rodent fun in space!";
final String GAME_DESC_2 = "Tests in space!";
final int STOCK_QTY = 10;
final float PRICE = 59.99f;
// setup our customer constants
final String FIRST_NAME = "Edgar";
final String LAST_NAME = "Neubauer";
// create our customer for this test
Customer customer1 = new Customer();
// set the customer's properties (NOTE: "firstName" is an indexed property in the Customer entity, but "lastName" is not!)
customer1.setFirstName(FIRST_NAME);
customer1.setLastName(LAST_NAME);
// create our games for this test
Stock game1 = new Game(GAME_TITLE, GAME_DESC, STOCK_QTY, PRICE);
Stock game2 = new Game(GAME_TITLE_2, GAME_DESC_2, STOCK_QTY + 5, PRICE + 5);
Сначала выполните настройку. (И ради краткости я опускаю аннотированные сущности.)
Ничего странного здесь не происходит — просто создаем две игры и одного покупателя. Стоит отметить (на будущее), что «firstName» является индексированным свойством объекта / узла Customer. Это означает, что он доступен для поиска (также напомним, что движком индексирования Neo4j по умолчанию является Lucene).
 |
| Это должно быть сделано. |
Игры, которые мы выбрали, явно являются играми AAA-title. Эти тесты должны быть интересными.
// save entities BEFORE saving the relationships! template.save(game1); template.save(game2); template.save(customer1); // make those purchases! Support our test economy! // (NOTE: "makePurchase" actually uses the "template" parameter to persist the relationship, so no need to do it again) Purchase p1 = customer1.makePurchase(template, game1, QTY); Purchase p2 = customer1.makePurchase(template, game2, QTY);
Выше мы обязательно сохраним 2 игры и одного покупателя. Мы также делаем это до сохранения любых отношений. Это необходимо . В этом случае я использую переменную экземпляра с именем «template», которая на самом деле является экземпляром
Neo4jOperations . Это один из способов доступа к необходимым функциям сохранения / извлечения, которые нам нужны. Затем мы создаем 2 объекта / отношения Покупка ( Покупка на самом деле является объектом отношения). Также стоит отметить, что вместо использования объекта «template» для сохранения отношений я следовал учебному пособию Neo4j «Хорошие отношения »
и попытался другой способ сделать постоянство, то есть путем передачи объекта «шаблона» в необходимый метод и заставить метод (в этом случае makePurchase ) фактически выполнить сохранение вновь созданной покупки. Опять же, оба «game1» и «game2» должны быть сохранены до сохранения каких-либо отношений между ними. Все еще со мной?
// retrieve the customer
Customer customer1Found = this.customerRepository.findByPropertyValue("firstName", FIRST_NAME);
//
// Tests
//
// can we find/retrieve the customer?
assertNotNull("Unable to find customer.", customer1Found);
// can we find the specific customer for which we are looking?
assertEquals("Returned customer but not the one searched for.", FIRST_NAME, customer1Found.getFirstName());
// does the retrieved customer have its non-indexed properties returned, as well?
assertEquals("Returned customer doesn't have non-indexed properties returned.", LAST_NAME, customer1Found.getLastName());
// retrieve the customer's purchases
// (NOTE: We case as a Collection just to make checking the number of puchases easier)
Iterable<purchase> purchasesIt = customer1Found.getPurchases();
Collection<purchase> purchases = IteratorUtil.asCollection(purchasesIt);
// do we have the correct number of purchases?
assertEquals("Number of purchases do not match.", 2, purchases.size());
Итак, теперь мы приступим к некоторым испытаниям.
Тесты выше все просто. Мы гарантируем следующее:
- Мы можем получить постоянный узел, в частности, через индексированное свойство.
- Мы можем получить правильный постоянный узел, который мы ищем.
- Мы можем просматривать неиндексированные свойства из найденного узла.
- Мы можем получить правильное количество отношений извлеченного узла.
// go through the actual purchases... Iterator<purchase> purchIt = purchasesIt.iterator(); Purchase purchase1 = purchIt.next(); // retrieving objects via Spring Data pulls lazily by default; for eager mapping, use @Fetch (but be forewarned!) // ...this means we have to use the fetch() method to finish loading related objects Stock s1 = template.fetch(purchase1.getItem());
Что если мы хотим просмотреть данные связанных узлов узла?
По умолчанию Spring Data загружает отношения сущности лениво, что имеет смысл (просто представьте, сколько памяти потребуется, если у вас очень большой, сильно связанный граф). Также помните, что существуют неявные отношения между сущностями, если сущность содержится в качестве свойства другой сущности.
 |
| (Любезно предоставлено Форрестом Гампом из Paramount Picture ) «Мама сказала, что нетерпеливая загрузка похожа на коробку конфет: никогда не знаешь, что получишь». Ну, по крайней мере, у конфет было легко определенное, конечное число в коробке … |
Можно получить активный поиск с помощью аннотации @Fetch (однако следует помнить , что в настоящее время она будет работать по умолчанию только на объектах узлов и коллекциях отношений, основанных на Collection , Set или Iterable; Spring Data может расширить это в более поздних выпусках, но я считаю, что вы можете расширить сопоставления для работы с другими классами, если вы того пожелаете). Итак, с нашими лениво загруженными отношениями мы можем использовать метод извлечения «шаблона», чтобы завершить загрузку отсутствующих данных. Это так просто! Любой, кто знаком с ORM, получит это немедленно.
// can we retrieve our first purchase successfully w/ its details?
assertEquals("Purchased item not persisted properly.", GAME_TITLE, s1.getTitle());
purchase1 = purchIt.next();
Stock s2 = template.fetch(purchase1.getItem());
// can we retrieve our second purchase successfully w/ its details?
assertEquals("Purchased item not persisted properly.", GAME_TITLE_2, s2.getTitle());
// if we're here, then all test ran succesfully. Hooray!
}
Выше мы запустили еще пару тестов, чтобы убедиться, что мы действительно можем извлекать и просматривать лениво загруженные объекты из Neo4j.
Ничего подобного! Подружиться легко: создавая их! Для этих тестов мы собираемся взглянуть на что-то более социальное, то есть клиентов, поддерживающих дружбу с другими клиентами (как это утопично!). Я полагаю, что мы могли бы сделать их «соперниками» или «врагами», но это слишком зловеще для этого блога (пока …). В любом случае, до этого метода тестирования у меня был метод установки (аннотированный аннотацией @Before JUnit), который создает 5 клиентов (если вам интересно, я сохраняю их, используя CustomerRespoitory, который я создал путем расширения интерфейсов GraphRepository и RelationshipOperationsRepository ).
@Test
public void customerFriends()
{
// add friends
c1.addFriend(c2);
c1.addFriend(c3);
c1.addFriend(c4);
c1.addFriend(c5);
// be careful! setting a "Direction.BOTH" relationship in one node entity will have the ENTIRE relationship saved (*including the adjoining node*) when saving just ONE of the two entities!
// ...if you save both, Neo4j will remove the duplication (and you'll be left wondering why c1 is a friend of c2, but not vice versa)
// save c1's friends
customerRepository.save(c1);
В приведенном выше коде у нас есть клиент «c1» подружиться с другими клиентами (он социальная бабочка). Теперь, пожалуй, самая важная часть всего этого блога показана здесь (и ниже). Это связано с отношениями, особенно с теми, которые отмечены как «Direction.BOTH». Как видно из комментариев в приведенном выше коде, мы должны быть осторожны с тем, как мы создаем отношения между узлами и сохраняем их. Если бы мы создали отношения между, скажем, «c1» и «c2», а затем сохранили каждый узел (и, следовательно, отношения, которые будет обрабатывать хранилище клиентов), мы бы заметили, что отношения пошли не так, и что повторяющиеся отношения из «c2» были удалены.
So, what we’re going to do is the following (keeping in mind that «c1» and «c2» have already been persisted in the setup method):
- Persist «c1» (and thereby its friendship to «c2»).
- Retrieve «c2».
- Add any other friends’ relationships to the retrieved «c2» (while not befriending back to «c1»).
- Persist «c2» (and thereby its friendships to those added in Step 3).
Step 1 is done above.
// we can't just continue to add friends to this.c2, as once we try to save this.c2, it'll remove the duplicate relationship between c1 and c2.
// ...so, to get around this, we retrieve the persisted object from the DB
Customer c2Found = customerRepository.findByPropertyValue("lastName", C2_LNAME);
c2Found.addFriend(c3);
c2Found.addFriend(c4);
c2Found.addFriend(c5);
// save c2's friends, which will preserve the existing relationship with c1! Old friends can remain friends!
customerRepository.save(c2Found);
As you can see above, we finish the remaining steps (2 through 4).
Again,
note that we DO NOT create a reciprocal relationship from «c2» to «c1».
(One would hope a friendship relationship would be reciprocal; unless
you have stalkers or something…)
 |
| This would totally help. |
All that’s left now is to run some tests to ensure that our friends have remained friends throughout all this persisting!
// retrieve c1 for some tests
Customer c1Found = customerRepository.findByPropertyValue("lastName", C1_LNAME);
Iterable<customer> c1Friends = c1Found.getFriends();
Collection<customer> c1FriendsSet = IteratorUtil.asCollection(c1Friends);
Iterator<customer> custIt = c1Friends.iterator();
int numFriends = 0;
// let's make sure all of c1's friends were retrieved
assertTrue("Friend not found.", c1FriendsSet.containsAll(IteratorUtil.asCollection(c1.getFriends())));
// let's also make sure that c1 and c2 are still buds specifically (these two are inseparable...you should see them at ComicCon!)
assertTrue("Friend not found.", c1FriendsSet.contains(c2));
// let's make sure the exact number of friends returned is correct
while (custIt.hasNext())
{
custIt.next();
numFriends++;
} // while
assertEquals("Number of friends returned incorrect.", 4, numFriends);
// if we're here, all is well! Huzzah!
}
Above, as in the
first test, we make sure that all of the friendships have been properly
preserved, both from «c1″‘s and «c2″‘s perspective.
Conclusion
In this post, we
have seen the basics of persisting with Spring Data and a couple of the
quirks I ran into. These are documented within the Spring Data
documentation, but it never hurts to bring these little nuances out into
the light even further.
We also saw that the ImpermanentGraphDatabase is
available to us through the Neo4j kernel which is a wonderful tool for
implementing test cases with quick setup and teardown—no needing to
write initializers and cleaners for a Neo4j installation!
So there we have it! A first pass through persisting with Spring Data and implementing some unit tests using Neo4j and JUnit.
If anyone has any questions or I’ve made a mistake, please feel free to leave feedback.
We’ll see you on the next post!