блоге Аврелия .

Организации используют данные для принятия решений, улучшения характеристик своих продуктов и повышения эффективности своей повседневной деятельности. Данные сами по себе бесполезны. Тем не менее, с анализом данных , такие шаблоны, как тенденции, кластеры, прогнозы и т. Д. Могут быть извлечены. Способ анализа данных определяется тем, как структурированы данные. Формат таблиц, популяризируемый электронными таблицами и реляционными базами данных , полезен для определенных типов обработки. Однако основная цель этого поста — изучить относительно менее эксплуатируемую структуру, которую можно использовать при анализе данных организации — графа / сети .
Перспектива стола
Перед обсуждением графиков представлен краткий обзор структуры табличных данных с использованием игрушечного примера, содержащего 12 человек. Для каждого человека собираются его имя, возраст и общие расходы за год. Приведенный ниже фрагмент кода R Statistics загружает данные о населении в таблицу.
> people <- read.table(file='people.txt', sep='\t', header=TRUE) > people id name age spending 1 0 francis 57 100000 2 1 johan 37 150000 3 2 herbert 56 150000 4 3 mike 34 30000 5 4 richard 47 35000 6 5 alberto 31 70000 7 6 stephan 36 90000 8 7 dan 52 40000 9 8 jen 28 90000 10 9 john 53 120000 11 10 matt 34 90000 12 11 lisa 48 100000 13 12 ariana 34 110000
 Каждая строка представляет информацию о конкретном человеке. Каждый столбец представляет значения свойства всех людей. Наконец, каждая запись представляет отдельное значение для одного свойства для отдельного человека. Учитывая приведенную выше таблицу лиц, можно рассчитать различную описательную статистику ? Простые примеры включают в себя:
Каждая строка представляет информацию о конкретном человеке. Каждый столбец представляет значения свойства всех людей. Наконец, каждая запись представляет отдельное значение для одного свойства для отдельного человека. Учитывая приведенную выше таблицу лиц, можно рассчитать различную описательную статистику ? Простые примеры включают в себя:
- среднее, среднее и стандартное отклонение возраста (строка 1),
- среднее значение, медиана и стандартное отклонение расходов (строка 3),
- корреляция между возрастом и расходы (т.е. делают пожилые люди склонны тратить больше — строка 5),
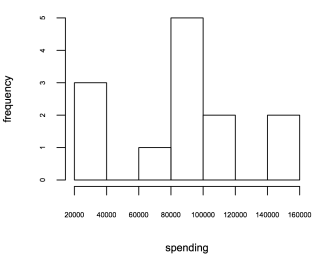
- распределение расходов (т.е. гистограмма расходов — строка 8).
> c(mean(people$age), median(people$age), sd(people$age))
[1] 42.07692 37.00000 10.29937
> c(mean(people$spending), median(people$spending), sd(people$spending))
[1] 90384.62 90000.00 38969.09
> cor.test(people$spending, people$age)$e
cor
0.1753667
> hist(people$spending, xlab='spending', ylab='frequency', cex.axis=0.5, cex.lab=0.75, main=NA)
В целом, представление таблицы полезно для статистических данных, таких как те, которые используются при анализе кубов данных . Однако, когда отношения между смоделированными объектами сложны / рекурсивны , тогда можно использовать методы анализа графа.
Граф Перспектива
Граф (или сеть) — это структура, состоящая из вершин (т. Е. Узлов, точек) и ребер (т. Е. Связей, линий). Предположим, что наряду с данными о людях, представленными ранее, существует набор данных, который включает шаблоны дружбы между людьми. Таким образом, люди — это вершины, а дружеские отношения — это края. Кроме того, характеристики человека (например, его имя, возраст и расходы) являются свойствами вершин. Эта структура широко известна как граф свойств . Используя iGraph в R, можно представлять и обрабатывать эти данные графика.
- Загрузите дружеские отношения в виде двухколоночной числовой таблицы (строка 1-2).
- Создайте неориентированный граф из таблицы с двумя столбцами (строка 3).
- Прикрепите свойства человека в качестве метаданных к вершинам (строки 4-6).
> friendships <- read.table(file='friendships.txt',sep='\t')
> friendships <- cbind(lapply(friendships, as.numeric)$V1, lapply(friendships, as.numeric)$V2)
> g <- graph.edgelist(as.matrix(friendships), directed=FALSE)
> V(g)$name <- as.character(people$name)
> V(g)$spending <- people$spending
> V(g)$age <- people$age
> g
Vertices: 13
Edges: 25
Directed: FALSE
Edges:
[0] 'francis' -- 'johan'
[1] 'francis' -- 'jen'
[2] 'johan' -- 'herbert'
[3] 'johan' -- 'alberto'
[4] 'johan' -- 'stephan'
[5] 'johan' -- 'jen'
[6] 'johan' -- 'lisa'
[7] 'herbert' -- 'alberto'
[8] 'herbert' -- 'stephan'
[9] 'herbert' -- 'jen'
[10] 'herbert' -- 'lisa'
...
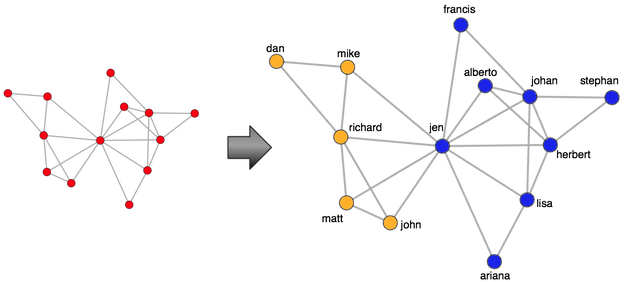
Одним из простых методов анализа графических данных является их визуализация, чтобы воспользоваться преимуществами системы визуальной обработки человека . Интересно, что человеческий глаз отлично умеет находить закономерности. В приведенном ниже примере кода используется алгоритм компоновки Fruchterman-Reingold для отображения графика на 2D-плоскости.
> layout <- layout.fruchterman.reingold(g) > plot(g, vertex.color='red',layout=layout, vertex.size=10, edge.arrow.size=0.5, edge.width=0.75, vertex.label.cex=0.75, vertex.label=V(g)$name, vertex.label.cex=0.5, vertex.label.dist=0.7, vertex.label.color='black')
Для больших графиков (которые выходят за рамки игрушечного примера) человеческий глаз может потеряться в массе граней между вершинами. К счастью, существует множество алгоритмов обнаружения сообщества . Эти алгоритмы используют шаблоны связности в графе для идентификации структурных подгрупп. Алгоритм обнаружения края сообщества промежуточность используется ниже идентифицирует два структурных сообществ в игрушечном графике (один цветной оранжевый и один синий цвет — линии 1-2). С помощью этой полученной информации сообщества можно извлечь одно из сообществ и проанализировать его изолированно (строка 19).
> V(g)$community = community.to.membership(g, edge.betweenness.community(g)$merges, steps=11)$membership+1
> data.frame(name=V(g)$name, community=V(g)$community)
name community
1 francis 1
2 johan 1
3 herbert 1
4 mike 2
5 richard 2
6 alberto 1
7 stephan 1
8 dan 2
9 jen 1
10 john 2
11 matt 2
12 lisa 1
13 ariana 1
> color <- c(colors()[631], colors()[498])
> plot(g, vertex.color=color[V(g)$community],layout=layout, vertex.size=10, edge.arrow.size=0.5, edge.width=0.75, vertex.label.cex=0.75, vertex.label=V(g)$name, vertex.label.cex=0.5, vertex.label.dist=0.7, vertex.label.color='black')
> h <- delete.vertices(g, V(g)[V(g)$community == 2])
> plot(h, vertex.color="red",layout=layout.fruchterman.reingold, vertex.size=10, edge.arrow.size=0.5, edge.width=0.75, vertex.label.cex=0.75, vertex.label=V(h)$name, vertex.label.cex=0.5, vertex.label.dist=0.7, vertex.label.color='black')
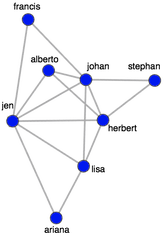 Изолированный подграф может быть подвергнут алгоритму централизации для определения наиболее важных / важных / влиятельных людей в сообществе. При использовании алгоритмов центральности важность определяется связностью человека в графе, и в этом примере используется популярный алгоритм PageRank (строка 1). Алгоритм выводит оценку для каждой вершины, где чем выше оценка, тем более центральная вершина. Вершины могут быть отсортированы (строки 2-3). На практике такие методы могут быть использованы для разработки маркетинговой кампании, Например, как показано ниже, можно задать такие вопросы, как «какой человек является влиятельным в своем сообществе и высокооплачиваемым?» В целом, графическая перспектива данных предоставляет новые статистические методы, которые в сочетании с табличными методами предоставляют аналитику богатый инструментарий для исследования и использования данных организации.
Изолированный подграф может быть подвергнут алгоритму централизации для определения наиболее важных / важных / влиятельных людей в сообществе. При использовании алгоритмов центральности важность определяется связностью человека в графе, и в этом примере используется популярный алгоритм PageRank (строка 1). Алгоритм выводит оценку для каждой вершины, где чем выше оценка, тем более центральная вершина. Вершины могут быть отсортированы (строки 2-3). На практике такие методы могут быть использованы для разработки маркетинговой кампании, Например, как показано ниже, можно задать такие вопросы, как «какой человек является влиятельным в своем сообществе и высокооплачиваемым?» В целом, графическая перспектива данных предоставляет новые статистические методы, которые в сочетании с табличными методами предоставляют аналитику богатый инструментарий для исследования и использования данных организации.
> V(h)$page.rank <- page.rank(h)$vector
> scores <- data.frame(name=V(h)$name, centrality=V(h)$page.rank, spending=V(h)$spending)
> scores[order(-centrality, spending),]
name centrality spending
6 jen 0.19269343 90000
2 johan 0.19241727 150000
3 herbert 0.16112886 150000
7 lisa 0.13220997 100000
4 alberto 0.10069925 70000
8 ariana 0.07414285 110000
5 stephan 0.07340102 90000
1 francis 0.07330735 100000
Важно понимать, что для крупномасштабного анализа графиков существуют различные технологии. Многие из этих технологий находятся в пространстве базы данных графа . Примеры включают в себя транзакционные механизмы персистентности, такие как Neo4j, и механизмы пакетной обработки на основе Hadoop, такие как Giraph и Pegasus . Наконец, исследовательский анализ с использованием языка R может использоваться для анализа графов в одной памяти, а также в кластерных средах с использованием таких технологий, как RHadoop и RHIPE., Все эти технологии могут быть объединены (вместе с технологиями на основе таблиц), чтобы помочь организации в понимании закономерностей, существующих в их данных.
Рекомендации
Ньюман, MEJ, « Структура и функции сложных сетей », SIAM Review, 45, 167–256, 2003.
Родригес М.А., Пепе А. « О взаимоотношениях структурных и социально-академических сообществ сети соавторов », журнал Informetrics, 2 (3), 195–2018, июль 2008 г.