Вступление
R — это язык программирования и программный пакет, используемый для анализа данных, статистических вычислений и визуализации данных. Он очень расширяемый, обладает объектно-ориентированными функциями и мощными графическими возможностями. В основе R лежит интерпретируемый язык, и он поставляется с интерпретатором командной строки, доступным для компьютеров с Linux, Windows и Mac, но также есть IDE для поддержки разработки, такие как
RStudio или
JGR. R и Hadoop могут очень хорошо дополнять друг друга, они являются естественным совпадением в аналитике и визуализации больших данных. Одним из наиболее известных пакетов R для поддержки функциональности Hadoop является
RHadoop , разработанный RevolutionAnalytics.
Установка RHadoop
RHadoop — это коллекция из трех пакетов R: rmr, rhdfs и rhbase. Пакет rmr обеспечивает функциональность Hadoop MapReduce в R, rhdfs обеспечивает управление файлами HDFS в R, а rhbase обеспечивает управление базой данных HBase изнутри R. Чтобы установить эти пакеты R, сначала нам нужно установить базовый пакет R. На Ubuntu 12.04 LTS мы можем сделать это, запустив:
$ sudo apt-get install r-base
Затем нам нужно установить пакеты RHadoop с их зависимостями. rmr требует RCpp, RJSONIO, дайджест, функционал, stringr и plyr, тогда как rhdfs требует rJava. В рамках установки нам необходимо перенастроить Java для пакета rJava, а также установить переменную HADOOP_CMD для пакета rhdfs. Для установки требуется загрузка соответствующих архивов tar.gz, а затем мы можем запустить команду R CMD INSTALL с привилегиями sudo.
sudo R CMD INSTALL Rcpp Rcpp_0.10.2.tar.gz sudo R CMD INSTALL RJSONIO RJSONIO_1.0-1.tar.gz sudo R CMD INSTALL digest digest_0.6.2.tar.gz sudo R CMD INSTALL functional functional_0.1.tar.gz sudo R CMD INSTALL stringr stringr_0.6.2.tar.g sudo R CMD INSTALL plyr plyr_1.8.tar.gz sudo R CMD INSTALL rmr rmr2_2.0.2.tar.gz sudo JAVA_HOME=/home/istvan/jdk1.6.0_38/jre R CMD javareconf sudo R CMD INSTALL rJava rJava_0.9-3.tar.gz sudo HADOOP_CMD=/home/istvan/hadoop/bin/hadoop R CMD INSTALL rhdfs rhdfs_1.0.5.tar.gz sudo R CMD INSTALL rhdfs rhdfs_1.0.5.tar.gz
Начало работы с RHadoop
В принципе, RHadoop MapReduce — это операция, аналогичная функции R lapply, которая применяет функцию к списку или вектору. Без функции mapreduce мы могли бы написать простой R-код для удвоения всех чисел от 1 до 100:
> ints = 1:100 > doubleInts = sapply(ints, function(x) 2*x) > head(doubleInts) [1] 2 4 6 8 10 12
С пакетом RHadoop rmr мы могли бы использовать функцию mapreduce для выполнения тех же вычислений — см. Скрипт doubleInts.R:
Sys.setenv(HADOOP_HOME="/home/istvan/hadoop") Sys.setenv(HADOOP_CMD="/home/istvan/hadoop/bin/hadoop") library(rmr2) library(rhdfs) ints = to.dfs(1:100) calc = mapreduce(input = ints, map = function(k, v) cbind(v, 2*v)) from.dfs(calc) $val v [1,] 1 2 [2,] 2 4 [3,] 3 6 [4,] 4 8 [5,] 5 10 .....
Если мы хотим запустить команды файловой системы HDFS из R, нам сначала нужно инициализировать rhdfs с помощью функции hdfs.init (), а затем мы можем запустить хорошо известные команды ls, rm, mkdir, stat и т.д:
> hdfs.init()
> hdfs.ls("/tmp")
permission owner group size modtime file
1 drwxr-xr-x istvan supergroup 0 2013-02-25 21:59 /tmp/RtmpC94L4R
2 drwxr-xr-x istvan supergroup 0 2013-02-25 21:49 /tmp/hadoop-istvan
> hdfs.stat("/tmp")
perms isDir block replication owner group size modtime path
1 rwxr-xr-x TRUE 0 0 istvan supergroup 0 45124-08-29 23:58:48 /tmp
Анализ данных с помощью RHadoop
В следующем примере показано, как использовать RHadoop для анализа данных. Предположим , что нам нужно определить , сколько стран имеют больший ВВП , чем доход от Apple Inc. в 2012 году (это было 156508 миллионов долларов, подробнее
http://www.google.com/finance?q=NASDAQ% 3AAAPL & fstype = ii & ei = 5eErUcCpB8KOwAOkQQ ) Данные о ВВП можно загрузить с
сайта каталога данных Всемирного банка . Данные должны быть скорректированы для соответствия алгоритму MapReduce. Последний формат, который мы использовали для анализа данных, выглядит следующим образом (где последний столбец — это ВВП данной страны в миллионах долларов США):
Country Code,Number,Country Name,GDP, USA,1,United States,14991300 CHN,2,China,7318499 JPN,3,Japan,5867154 DEU,4,Germany,3600833 FRA,5,France,2773032 ....
Сценарий gdp.R выглядит так:
Sys.setenv(HADOOP_HOME="/home/istvan/hadoop")
Sys.setenv(HADOOP_CMD="/home/istvan/hadoop/bin/hadoop")
library(rmr2)
library(rhdfs)
setwd("/home/istvan/rhadoop/blogs/")
gdp <- read.csv("GDP_converted.csv")
head(gdp)
hdfs.init()
gdp.values <- to.dfs(gdp)
# AAPL revenue in 2012 in millions USD
aaplRevenue = 156508
gdp.map.fn <- function(k,v) {
key <- ifelse(v[4] < aaplRevenue, "less", "greater")
keyval(key, 1)
}
count.reduce.fn <- function(k,v) {
keyval(k, length(v))
}
count <- mapreduce(input=gdp.values,
map = gdp.map.fn,
reduce = count.reduce.fn)
from.dfs(count)
R запустит потоковое задание Hadoop для обработки данных с использованием алгоритма mapreduce.
packageJobJar: [/tmp/Rtmp4llUjl/rmr-local-env1e025ac0444f, /tmp/Rtmp4llUjl/rmr-global-env1e027a86f559, /tmp/Rtmp4llUjl/rmr-streaming-map1e0214a61fa5, /tmp/Rtmp4llUjl/rmr-streaming-reduce1e026da4f6c9, /tmp/hadoop-istvan/hadoop-unjar1158187086349476064/] [] /tmp/streamjob430878637581358129.jar tmpDir=null 13/02/25 22:28:12 INFO mapred.FileInputFormat: Total input paths to process : 1 13/02/25 22:28:12 INFO streaming.StreamJob: getLocalDirs(): [/tmp/hadoop-istvan/mapred/local] 13/02/25 22:28:12 INFO streaming.StreamJob: Running job: job_201302252148_0006 13/02/25 22:28:12 INFO streaming.StreamJob: To kill this job, run: 13/02/25 22:28:12 INFO streaming.StreamJob: /home/istvan/hadoop-1.0.4/libexec/../bin/hadoop job -Dmapred.job.tracker=localhost:9001 -kill job_201302252148_0006 13/02/25 22:28:12 INFO streaming.StreamJob: Tracking URL: http://localhost:50030/jobdetails.jsp?jobid=job_201302252148_0006 13/02/25 22:28:13 INFO streaming.StreamJob: map 0% reduce 0% 13/02/25 22:28:25 INFO streaming.StreamJob: map 100% reduce 0% 13/02/25 22:28:37 INFO streaming.StreamJob: map 100% reduce 100% 13/02/25 22:28:43 INFO streaming.StreamJob: Job complete: job_201302252148_0006 13/02/25 22:28:43 INFO streaming.StreamJob: Output: /tmp/Rtmp4llUjl/file1e025f146f8f
Затем мы получим данные о том, сколько стран имеют больший объем и сколько стран имеют меньший ВВП, чем выручка Apple Inc. в 2012 году. В результате 55 стран имели больший ВВП, чем Apple, и 138 стран — меньше.
$key GDP 1 "greater" 56 "less" $val [1] 55 138
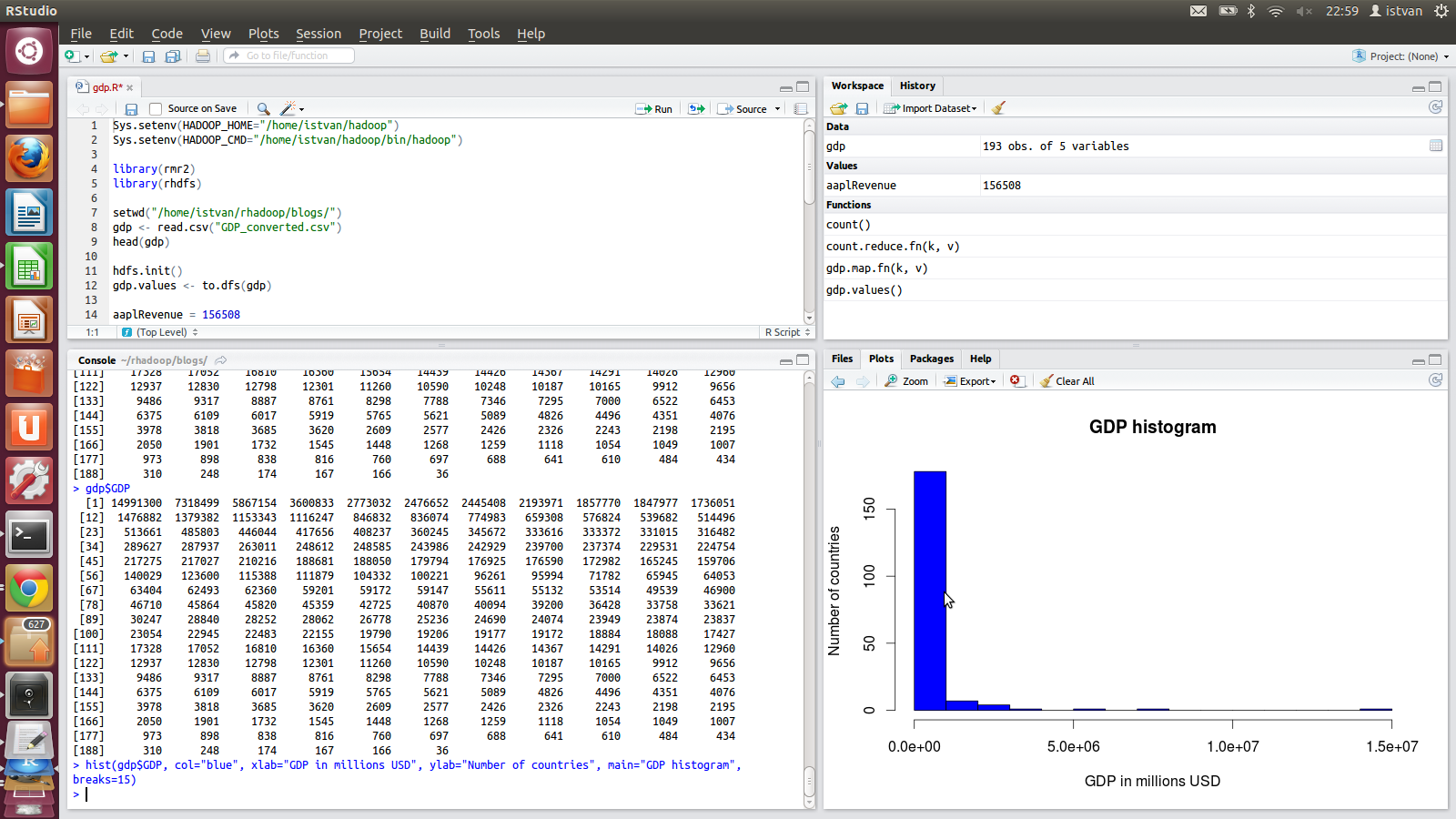
На следующем скриншоте с RStudio показана гистограмма ВВП — в 15 странах ВВП превышает 1000 миллионов долларов США; 1 страна находится в диапазоне от 14 000 до 15 000 миллионов долларов США, 1 страна находится в диапазоне от 7 000 до 8 000 миллионов долларов США, а 1 страна находится в диапазоне от 5 000 до 6 000 долларов США.
Вывод
Если кому-то нужно объединить мощные функции анализа данных и визуализации с возможностями больших данных, поддерживаемыми Hadoop, безусловно, стоит поближе познакомиться с функциями RHadoop. У него есть пакеты для интеграции R с MapReduce, HDFS и HBase, ключевыми компонентами экосистемы Hadoop. Для получения более подробной информации, пожалуйста, прочитайте технический документ
R и Hadoop Big Data Analytics .