Дмитрий Сетракян недавно предоставил отличное объяснение для In-Memory Data Grid (IMDG) — теперь я постараюсь предоставить аналогичное описание для In-Memory Compute Grid (IMCG).
IMCG — сетка вычислений в памяти
Одной из основных идей, выдвинутых Дмитрием, является важность интеграции между хранением в памяти (IMDG) и обработкой в памяти (IMCG), чтобы иметь возможность создавать действительно масштабируемые приложения. Тем не менее — IMCG и его реализации видны реже, чем IMDG, в основном из-за исторической причины, описанной ниже.
Большинство поставщиков по сей день концентрируются в первую очередь на технологии хранения данных (IMDG, NoSQL или NewSQL). После того, как продукт для хранения будет создан, добавление любого типа не элементарной возможности IMCG поверх этого становится все более трудным, если не невозможным в целом (мы увидим, почему это так, ниже). Таким образом, как правило, возможности IMCG являются более фундаментальными для всего продукта и, следовательно, должны быть построены вначале или вместе, чтобы использоваться в ядре стороны хранения.
Между прочим, неудивительно, что GridGain и Hadoop по-прежнему являются единственными продуктами на рынке, которые успешно объединяют хранение и обработку в одном продукте (хотя и по-разному), в то время как доступны десятки проектов только для хранения (и вероятно сотни, если вы посчитаете каждую попытку NoSQL на GitHub).
Основные понятия
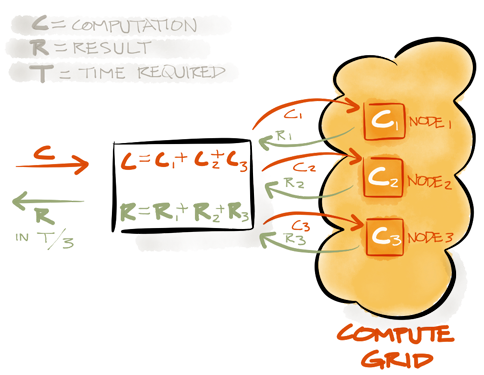
The easiest way to understand IMCGs is through a comparison to IMDGs. While IMDGs focus on distributed in-memory storage and management of large data sets by partitioning this data across available computers in the grid, IMCG concentrate on efficiently executing algorithms (i.e. user’s code or instructions) across the same set of computers on the same grid. And that’s all there’s to it: IMDG is all about storing and managing data in-memory, and IMCG is all about processing and computing across the same data.
When seen from this vantage point – it is pretty clear why tight integration between IMDG and IMCG is so important: they are practically two sides of the same coin – storage and processing, that both coalesce around your data.
Most of the functionality in any IMCG can be split into four individual groups:
- Distributed Deployment & Provisioning
- Distributed Resources Management
- Distributed Execution Models (a.k.a.
IMCG Breadth) - Distributed Execution Services (a.k.a.
IMCG Depth)
1. Distributed Deployment & Provisioning
Historically deployment and provisioning of the user’s code onto the grid for executionwas one of the core reasons why grid computing in general was considered awkward and cumbersome at best, and downright unusable at worst. From the early products like Globus, Grid Engine, DataSynapse, Platform Computing, and such, to today’s Hadoop and most of the NoSQL projects – deploying and re-deploying your changes is a manual step that involves rebuilding all of your libraries, copying them everywhere, and restarting your services. Some systems will do copying & restarting for you (Hadoop) and some will require you to do it manually via some UI-based crutch.
This problem is naturally exacerbated by the fact that IMCGs are a distributed technology to begin with and are routinely used on topologies consisting of dozens if not hundreds of computers. Stopping services, redeploying libraries and re-starting services during developing, CI testing and staging in such topologies becomes a major issue.
GridGain is the first IMCG that simplifies this issue by providing «zero deployment» capabilities. With «zero depoloyment» all necessary JVM classes and resources are loaded on demand. Further, GridGain provides three different modes of peer-to-peer deployment supporting the most complex deployment environments like custom class loaders, WAR/EAR files, etc.
Zero deployment technology enables users to simply bring default GridGain nodes online with these nodes then immediately becoming part of the data and compute grid topology that can store any user objects or perform any user tasks without any need for explicit deployment of user’s classes or resources.
2. Distributed Resources Management
Resource management in distributed systems usually refers to the ability to manage physical devices such as computers, networks, and storage as well as software components like JVM, runtimes and OSes. Specifics of that obviously differ based on whether or not the IMCG is deployed on some kind of managed infrastructure like AWS, how it is DevOps managed, etc.
One of the most important resource management functions of any IMCG is automaticdiscovery and maintaining consistent topology (i.e. the set of compute nodes). Automatic discovery allows the user to add and remove compute nodes from the IMCG topology at runtime while maintaining zero downtime for the tasks running on the IMCG. Consistent topology ensures that any topology changes (nodes failing and leaving, or new nodes joining) viewed by all compute nodes in the same order and consistently.
GridGain provides the most sophisticated discovery system among any IMCG. Pluggable and user-defined Discovery SPI is at the core of GridGain’s ability to provide fully automatic and consistent discovery functionality for GridGain nodes. GridGain is shipped with several out-of-the-box implementations including IP-multicast- and TCP/IP-based implementations with direct support for AWS S3 and Zookeeper.
3. Distributed Execution Models (a.k.a IMCG Breadth)
Support for different distributed execution models is what makes IMCG a compute framework. For clarity let’s draw a clear distinction between an execution model (such as MapReduce) and the particular algorithms that can be implemented using this model (i.e. Distributed Search): there is a finite set of execution models but practically an infinite set of possible algorithms.
Generally, the goal of any IMCG (as well as of any compute framework in general) is to support as many different execution models as possible, providing the end-user with the widest set of options on how a particular algorithm can be implemented and ultimately executed in the distributed environment. That’s why we often call it IMCG Breadth.
GridGain’s IMCG, for a example, provides direct support for the following execution models:
-
MapReduce Processing
GridGain provides general distributed fork-join type of processing optimized for in-memory. More specifically, MapReduce type processing defines the method of splitting original compute task into multiple sub-tasks, executing these sub-tasks in parallel on any managed infrastructure and aggregating (a.k.a. reducing) results back to one final result.
GridGain’s MapReduce is essentially a distributed computing paradigm that allows you to map your task into smaller jobs based on some key, execute these jobs on Grid nodes, and reduce multiple job results into one task result. This is essentially what GridGain’s MapReduce does. However, the difference of GridGain MapReduce from other MapReduce frameworks, like Hadoop for example, is that GridGain MapReduce is geared towards streaming low-latency in-memory processing.
If Hadoop MapReduce task takes input from disk, produces intermediate results on disk and outputs result onto disk, GridGain does everything Hadoop does in memory – it takes input from memory via direct API calls, produces intermediate results in memory and then creates result in-memory as well. Full in-memory processing allows GridGain provide results in sub-seconds whereas other MapReduce frameworks would take minutes.
-
Streaming Processing & CEP
Streaming processing and corresponding Complex Event Processing (CEP) is a type of processing where input data is not static but rather constantly «streaming» into the system. Unlike other MapReduce frameworks which spawn different external executable processes which work with data from disk files and produce output onto disk files (even when working in streaming mode), GridGain Streaming MapReduce seamlessly works on streaming data directly in-memory.
As the data comes in into the system, user can keep spawning MapReduce tasks and distribute them to any set of remote nodes on which the data is processed in parallel and result is returned back to the caller. The main advantage is that all MapReduce tasks execute directly in-memory and can take input and store results utilizing GridGain in-memory caching, thus providing very low latencies.
-
MPP/RPC Processing
GridGain also provides native support for classic MPP (massively parallel processing) and RPC (Remote Procedure Call) type of processing including direct remote closure execution, unicast/broadcast/reduce execution semantic, shared distribution sessions and many other features.
-
MPI-style Processing
GridGain’s high performance distributed messaging provides MPI-style (i.e. message passing based distribution) processing capabilities. Built on proprietary asynchronous IO and world’s fastest marshaling algorithm GridGain provides synchronous and asynchronous semantic, distributed events and pub-sub messaging in a distributed environment.
-
AOP/OOP/FP/SQL Integrated Processing
GridGain is the only platform that integrates compute grid capabilities into existing programming paradigms such as AOP, OOP, FP and SQL:
- You can use AOP to annotate your Java or Scala code for automatic MapReduce or MPP execution on the grid.
- You can use both OOP and pure FP APIs for MapReduce/MPP/RPC execution of your code.
- GridGain allows to inject executable closures into SQL execution plan allowing you to inject your own filters, local and remote reducers right into the ANSI SQL.
3. Distributed Execution Services (a.k.a IMCG Depth)
In many respects the distributed execution services is the «meat» around proverbial execution models’ «bones». Execution services refer to many dozens of deep IMCG features that support various execution strategies and models including services such as distributed failover, load balancing, collision resolution, etc. – hence the moniker ofIMCG Depths.
Many such features are shared between different IMCGs and general compute frameworks – but some are unique to a particular product. Here is a short list of some of the key execution services provided by GridGain’s IMCG:
-
Pluggable Failover
Failover management and resulting fault tolerance is a key property of any grid computing infrastructure. Based on its SPI-based architecture GridGain provides totally pluggable failover logic with several popular implementations available out-of-the-box. Unlike other grid computing frameworks GridGain allows to failover the logic and not only the data.
With grid task being the atomic unit of execution on the grid the fully customizable and pluggable failover logic enables developer to choose specific policy much the same way as one would choose concurrency policy in RDBMS transactions.
Moreover, GridGain allows to customize the failover logic for all tasks, for group of tasks or even for every individual task. Using meta-programming techniques the developer can even customize the failover logic for each task execution.
This allows to fine tune how grid task reacts to the failure, for example:
— Fail entire task immediately upon failure of any of its jobs (fail-fast approach)
— Failover failed job to other nodes until topology is exhausted (fail-slow approach) -
Pluggable Topology Resolution
GridGain provides the ability to either directly or automatically select a subset of grid nodes (i.e. a topology) on which MapReduce tasks will be executed. This ability gives tremendous flexibility to the developer in deciding where its task will be executed. The decision can be based on any arbitrary user or system information. For example, time of the day or day of the week, type of task, available resources on the grid, current or average stats from a given node or aggregate from a subset of nodes, network latencies, predefined SLAs, etc.
-
Pluggable Resource Matching
For cases when some grid nodes are more powerful or have more resources than others you can run into scenarios where nodes are not fully utilizes or over-utilized. Under-utilization and over-utilization are both equally bad for a grid – ideally all grid nodes in the grid should be equally utilized. GridGain provides several ways to achieve equal utilization across the grid including, for example:
Weighted Load Balancing
If you know in advance that some nodes are, say, 2 times more powerful than others, you can attach proportional weights to the nodes. For examples, part of your grid nodes would get weight of 1 and the other part would get weight of 2. In this case job distribution will be proportional to node weights and nodes with heavier weight will proportionally get more jobs assigned to them than nodes with lower weights. So nodes with weight 2 will get 2 times more jobs than nodes with weight 1.Adaptive Load Balancing
For cases when nodes are not equal and you don’t know exactly how different they are, GridGain will automatically adapt to differences in load and processing power and will send more jobs to more powerful nodes and less jobs to weaker nodes. GridGain achieves that by listening to various metrics on various nodes and constantly adapting its load balancing policy to the differences in load. -
Pluggable Collision Resolution
Collision resolution allows to regulate how grid jobs get executed when they arrive on a destination node for execution. Its functionality is similar to tasks management via customizable GCD (Great Central Dispatch) on Mac OS X as it allows developer to provide custom job dispatching on a single node. In general a grid node will have multiple jobs arriving to it for execution and potentially multiple jobs that are already executing or waiting for execution on it. There are multiple possible strategies dealing with this situation, like all jobs can proceed in parallel, or jobs can be serialized i.e., or only one job can execute in any given point of time, or only certain number or types of grid jobs can proceed in parallel, etc…
-
Pluggable Early and Late Load Balancing
GridGain provides both early and late load balancing for our Compute Grid that is defined by load balancing and collision resolution SPIs – effectively enabling full customization of the entire load balancing process. Early and late load balancing allows adapting the grid task execution to non-deterministic nature of execution on the grid.
Early load balancing is supported via mapping operation of MapReduce process. The mapping – the process of mapping jobs to nodes in the resolved topology – happens right at the beginning of task execution and therefore it is considered to be an early load balancing
Once jobs are scheduled and have arrived on the remote node for execution they get queued up on the remote node. How long this job will stay in the queue and when it’s going to get executed is controlled by the collision SPI – that effectively defines the late load balancing stage.
One implementation of the load balancing orchestrations provided out-of-the-box is a job stealing algorithm. This detects imbalances at a late stage and sends jobs from busy nodes to the nodes that are considered free right before the actual execution.
Grid and cloud environments are often heterogeneous and non-static, tasks can change their complexity profiles dynamically at runtime and external resources can affect execution of the task at any point. All these factors underscore the need for proactive load balancing during initial mapping operation as well as on destination nodes where jobs can be in waiting queues.
-
Distributed Task Session
A distributed task session is created for every task execution and allows for sharing state between different jobs within the task. Jobs can add, get, and wait for various attributes to be set, which allows grid jobs and tasks to remain connected in order to synchronize their execution with each other and opens a solution to a whole new range of problems.
Imagine for example that you need to compress a very large file (let’s say terabytes in size). To do that in a grid environment you would split such file into multiple sections and assign every section to a remote job for execution. Every job would have to scan its section to look for repetition patterns. Once this scan is done by all jobs in parallel, jobs would need to synchronize their results with their siblings so compression would happen consistently across the whole file. This can be achieved by setting repetition patterns discovered by every job into the session.
-
Redundant Mapping Support
In some cases a guarantee of a timely successful result is a lot more important than executing redundant jobs. In such cases GridGain allows you to spawn off multiple copies of the same job within your MapReduce task to execute in parallel on remote nodes. Whenever the first job completes successfully, the other identical jobs are cancelled and ignored. Such an approach gives a much higher guarantee of successful timely job completion at the expense of redundant executions. Use it whenever your grid is not overloaded and consuming CPU for redundancy is not costly.
-
Node Local Cache
When working in a distributed environment often you need to have a consistent local state per grid node that is reused between various job executions. For example, what if multiple jobs require a database connection pool for their execution – how do they get this connection pool to be initialized once and then reused by all jobs running on the same grid node? Essentially you can think about it as a per-grid-node singleton service, but the idea is not limited to services only, it can be just a regular Java bean that holds some state to be shared by all jobs running on the same grid node.
-
Cron-based Scheduling
In addition to running direct MapReduce tasks on the whole grid or any user-defined portion of the grid (virtual subgrid), you can schedule your tasks to run repetitively as often as you need. GridGain supports Cron-based scheduling syntax for the tasks, so you can schedule your tasks to run using the familiar standard Cron syntax that we are all used to.
-
Partial Asynchronous Reduction
Sometimes when executing MapReduce tasks you don’t need to wait for all the remote jobs to complete in order for your task to complete. A good example would be a simple search. Let’s assume, for example, that you are searching for some pattern from data cached in GridGain data grid on many remote nodes. Once the first job returns with found pattern you don’t need to wait for other jobs to complete as you already found what you were looking for. For cases like this GridGain allows you to reduce (i.e. complete) your task before all the results from remote jobs are received – hence the name “partial asynchronous reduction”. The remaining jobs belonging to your task will be cancelled across the grid in this case.
-
Pluggable Task Checkpoints
Checkpointing a job provides the ability to periodically save its state. This becomes especially useful in combination with fail-over functionality. Imagine a job that may take 5 minute to execute, but after the 4th minute the node on which it was running crashed. The job will be failed over to another node, but it would usually have to be restarted from scratch and would take another 5 minutes. However, if the job was checkpointed every minute, then the most amount of work that could be lost is the last minute of execution and upon failover the job would restart from the last saved checkpoint. GridGain allows you to easily checkpoint jobs to better control overall execution time of your jobs and tasks.
-
Distributed Continuations
Continuations are useful for cases when jobs need to be suspended and their resources need to be released. For example, if you spawn a new task from within a job, it would be wrong to wait for that task completion synchronously because the job thread will remain occupied while waiting, and therefore your grid may run out of threads. The proper approach is to suspend the job so it can be continued later, for example, whenever the newly spawned task completes.
This is where GridGain continuations become really helpful. GridGain allows users to suspend and restart thier jobs at any point. So in our example, where a remote job needs to spawn another task and wait for the result, our job would spawn the task execution and then suspend itself. Then, whenever the new task completes, our job would wake up and resume its execution. Such approach allows for easy task nesting and recursive task execution. It also allows you to have a lot more cross-dependent jobs and tasks in the system than there are available threads.
-
Integration with IMDG
Integration with IMDG based on affinity routing is one of the key concepts behind Compute and Data Grid technologies (whether they are in-memory or disk based). In general, affinity routing allows to co-locate a job and the data set this job needs to process.
The idea is pretty simple: if jobs and data are not co-located, then jobs will arrive on some remote node and will have to fetch the necessary data from yet another node where the data is stored. Once processed this data most likely will have to be discarded (since it’s already stored and backed up elsewhere). This process induces an expensive network trip plus all associated marshaling and demarshalling. At scale – this behavior can bring almost any system to a halt.
Affinity co-location solves this problem by co-locating the job with its necessary data set. We say that there is an affinity between processing (i.e. the job) and the data that this processing requires – and therefore we can route the job based on this affinity to a node where data is stored to avoid unnecessary network trips and extra marshaling and demarshaling. GridGain provides advanced capabilities for affinity co-location: from a simple single-method call to sophisticated APIs supporting complex affinity keys and non-trivial topologies.
Example
The following examples demonstrate a typical stateless computation task of Pi-number calculation on the grid (written in Scala – but can be easily done in Java or Groovy or Clojure as well). This example shows how tremendously simple the implementation can be with GridGain – literally just a dozen lines of code.
Note that this is a full source code – copy’n’paste it, compile it and run it. Note also that it works on one node – and just as well on a thousand nodes in the grid or cloud with no code change – just linearly faster. What is even more interesting is that this application automatically includes all these execution services:
- Auto topology discovery
- Auto load balancing
- Distributed failover
- Collision resolution
- Zero code deployment & provisioning
- Pluggable marshaling & communication
import org.gridgain.scalar._
import scalar._
import scala.math._
object ScalarPiCalculationExample {
private val N = 10000
def main(args: Array[String]) {
scalar {
println("Pi estimate: " +
grid$.spreadReduce(for (i <- 0 until grid$.size()) yield () => calcPi(i * N))(_.sum))
}
}
def calcPi(start: Int): Double =
// Nilakantha algorithm.
((max(start, 1) until (start + N)) map
(i => 4.0 * (2 * (i % 2) - 1) / (2 * i) / (2 * i + 1) / (2 * i + 2)))
.sum + (if (start == 0) 3 else 0)
}