Первоначально Написано Петрой Сельмер
Вы видели волнение вокруг Neo4j 2.2 Release и, возможно, видели несколько пунктов о языке запросов Cypher. Мы в команде Cypher рады, что наш новый Cypher Query Optimizer под кодовым названием «Ronja» стал важной частью релиза, и мы хотели бы поделиться некоторыми деталями с вами.
Ronja — это новый компилятор запросов на основе стоимости, целью которого является создание оптимизированного плана запросов, что приводит к сокращению времени выполнения запросов Cypher. В этом выпуске Ronja используется для запросов только для чтения со следующей структурой:
[MATCH WHERE]
[OPTIONAL MATCH WHERE]
[WITH [ORDER BY] [SKIP] [LIMIT]]
RETURN [ORDER BY] [SKIP] [LIMIT]В этом посте мы представим обзор того, как выполняются запросы Cypher, чтобы показать, как помогает Ronja.
Выполнение запроса Cypher происходит в следующих шагах, где Ronja обрабатывает шаги 2 — 5:
- Преобразовать строку входного запроса в абстрактное синтаксическое дерево (AST)
- Оптимизировать и нормализовать АСТ
- Создать график запроса из нормализованного AST
- Создайте логический план из X
- Перепишите логический план
- Создать план выполнения из логического плана
- Выполнить запрос, используя план выполнения
Давайте рассмотрим каждый из них более подробно. Это немного отвратительно, но довольно весело, если вы любите языки.
Преобразовать строку входного запроса в абстрактное синтаксическое дерево (AST)
Входная строка запроса сначала маркируется, а затем анализируется в AST .
Используя этот AST, мы выполняем семантическую проверку типов переменных и определение области видимости переменных в дереве. Любые ошибки, связанные с основной информацией о наборе — например, попытка разделить две строки — выявляются и возвращаются пользователю.
На этом этапе AST размечен семантической информацией, и мы сохраняем ссылку на исходную строку входного запроса.
Оптимизировать и нормализовать АСТ
Ronja начинает с выполнения простых оптимизаций и нормализаций на AST; некоторые из них включают в себя:
- Перемещение всех меток и типов из предложения MATCH в WHERE
- Подавление избыточных СО
- Расширение псевдонимов; например, RETURN * => RETURN x как x, y как y
- Складывание констант; например, 1 + 2 * 4 => 9
- Присвоение имен узлам анонимных шаблонов; например, MATCH () => MATCH (n)
- Преобразование оператора равенства в ‘IN’: MATCH (n) WHERE id (n) = 12 => MATCH n WHERE id (n) IN [12]
- Другие нормализации
Создать график запроса из нормализованного AST
Мы используем нормализованный AST для создания графа запросов, который является более абстрактным представлением запроса высокого уровня. Использование графа запросов вместо непосредственной работы с AST позволяет нам вычислять затраты и выполнять оптимизацию гораздо более эффективно, как мы подробно рассмотрим в шаге ниже.
Создать логический план из графа запросов
Логический план — это дерево с двумя дочерними элементами, состоящее из операторов, аналогичных тем, которые используются логическими планами реляционных баз данных.
Логический план создается для каждого графа запросов (в зависимости от запроса граф запросов может состоять из графиков подзапросов). Это делается поэтапно, следуя подходу снизу вверх.
На каждом этапе мы сначала получаем данные, такие как селективность индекса и метки, из нашего нового хранилища статистики. Затем эти данные используются для оценки количества элементов — это количество совпадающих строк — с использованием информации из графа запросов. При этом мы можем оценить стоимость, которая используется для построения кандидата логического плана.
Стоимость логического плана — это оценка объема работы, которую база данных должна выполнить для выполнения логического плана, в которой преобладают операции чтения ввода-вывода из хранилища и индексов, а также вычислительная работа в памяти, такая как расширение графа путем прохождения большего количества отношений и, следовательно, сбора большего количества узлов.
Таким образом, на каждом этапе создается несколько возможных логических планов для графа запросов. Ronja использует жадную стратегию поиска, чтобы выбрать самый дешевый логический план из нескольких кандидатов, поскольку этот процесс просачивается в граф запросов. Из-за жадного поиска выбранный логический план может быть не самым оптимальным, но он гарантированно не будет самым дорогим.
Перепишите логический план
Логический план теперь переписан с использованием раскроя, слияния и упрощения различных компонентов; например, любой оператор равенства, преобразованный в ‘IN на шаге 2, снова превращается в операторы равенства. В конце этого этапа Роня достиг своей цели.
Создать план выполнения из логического плана
План выполнения создается из логического плана путем выбора физической реализации для логических операторов и впоследствии кэшируется. Это дерево, состоящее из операторов, где каждый не-лист питается от одного или двух дочерних элементов; Более подробную информацию об операторах можно найти в руководстве . Ниже показано визуальное представление плана выполнения запроса:
MATCH (a1:Artist {name: ‘Artist-1′}), (a2:Artist),
p = shortestPath((a1)-[*..3]-(a2))
RETURN p LIMIT 5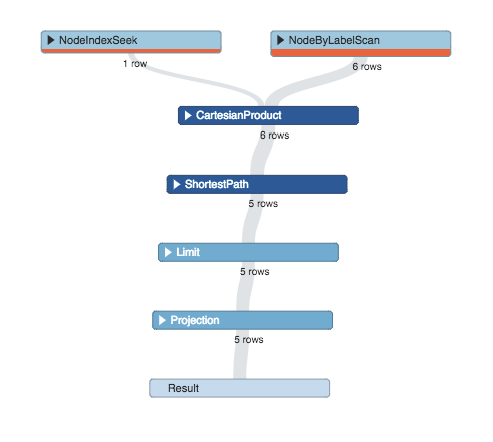
Выполнить запрос, используя план выполнения
После того, как план выполнения был преобразован во вложенные итераторы, результат получается конвейерным способом путем извлечения из верхнего итератора, который извлекает из следующего итератора и так далее.
Следующий рисунок иллюстрирует весь процесс; Роня является частью этапа «Семантического анализа» до конца этапа «Логический план».
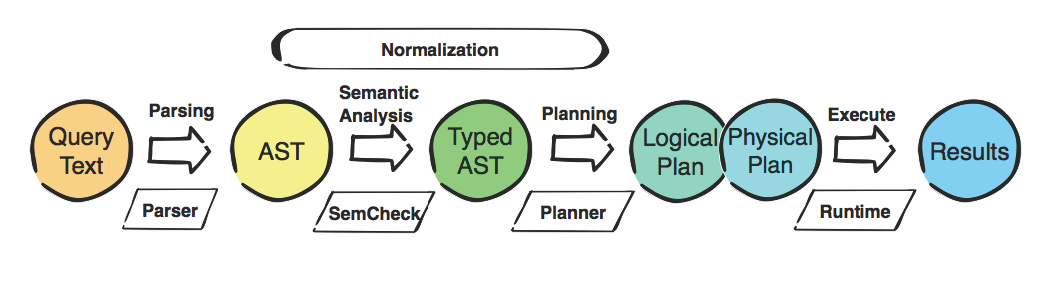
Роня на практике
Итак, для каких типов запросов Ronja дает лучшие улучшения? Мы провели обширные сравнительные тесты, и, эмпирически, запросы, содержащие несколько узлов, которые могут быть достигнуты с помощью индексов и / или предикатов шаблона, показывают наибольшее улучшение.
Следующие примеры иллюстрируют эти типы запросов. Для первого запроса недорогой поиск индекса по a1 (поиск узла (ов), имеющих «Artist-1» в свойстве name) выполняется дважды, что эффективно приводит к двум ветвям выполнения. Каждый раз результат ветвления расширяется путем обхода исходящих отношений: первое расширение следует за всеми отношениями PERFORMED_AT, чтобы собрать все совпадающие узлы, помеченные как Concert; вторая следует за всеми отношениями SIGNED_WITH, получая совпадающие узлы компании. Далее следуют расширения в каждой ветви, после чего результаты двух ветвей объединяются. Способность строить планы, подобные этому, не существовала до Ронжи.
MATCH (a1:Artist {name: ‘Artist-1′})-[:PERFORMED_AT]->
(:Concert)<-[:PERFORMED_AT]-(a2:Artist)
MATCH (a1)-[:SIGNED_WITH]->(corp:Company)<-[:SIGNED_WITH]-(a2)
RETURN a2, COUNT(*)
ORDER BY COUNT(*) DESCДля запроса ниже, до Ronja, предикат WHERE (b) — [: SOLD_AT] -> (s: Store) AND s.SalesRank> 3 был бы просто выражением. Теперь предикат является фактическим подзапросом, что означает, что Ronja может учитывать затраты на него, что приводит к построению гораздо более точного логического плана.
MATCH (a:Author),
(a)-[:WROTE]->(b:Book),
(s:Store)
WHERE (b)-[:SOLD_AT]->(s:Store) AND s.SalesRank > 3 RETURN a.FullName, b.Title, s.StoreNameБудущая работа
Мы продолжим улучшать Ronja с нашей целью быть еще быстрее, чем созданный вручную Java-код. Мы также будем интегрировать Ronja в запросы чтения-записи и только для записи, чтобы они выполнялись намного быстрее в будущем. Помимо планирования запросов мы также работаем над улучшением выполнения запросов путем разработки новой среды выполнения, которая компилирует логические планы вплоть до исполняемого «машинного» кода.