Автор Хенрик Инго для блога MongoDB.
Два месяца назад я писал о том, как вы можете привязать оплог и к изолированному кластеру , и отфильтровать внутренние вставки и удаления, возникающие в процессе балансировки.
После того, как он был опубликован, я получил больше отзывов по этой теме, указав на два сценария, которые все еще проблематичны для приложений, которым необходимо вести оплог. Один из них на самом деле относится и к неэкранированным кластерам, второй по-прежнему является проблемой, связанной с сегментированием. Оба, возможно, немного более неясны, чем то, что обсуждалось в первом сообщении в блоге, но все еще очень реальны.
Отказоустойчивость и откат
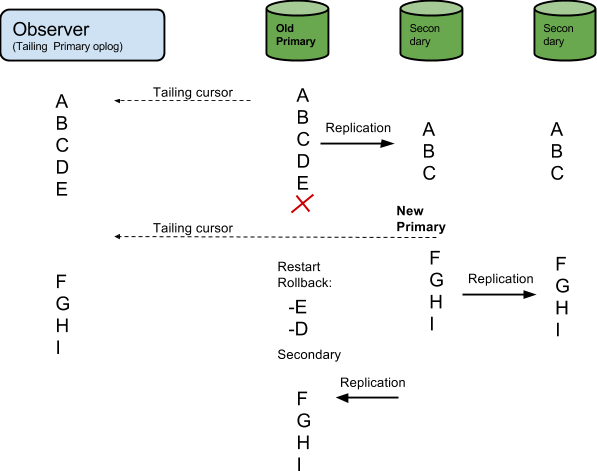
Первая проблема возникает из-за отказов. Скажем, вы подключаете оплог с первичного сервера, который испытывает некоторую сетевую проблему, которая заставляет другой узел быть выбранным в качестве нового первичного, в то время как старый первичный в конечном итоге выходит из строя. В этой ситуации возможно, что процесс, следящий за оплогом, прочитал бы некоторые события, которые фактически еще не были реплицированы на другой узел. Затем, когда был выбран новый первичный сервер, эти события фактически не являются частью текущего состояния базы данных. По сути, они никогда не происходили — тем не менее процесс, связанный с оплогом, считает, что они это сделали.
(Обратите внимание, что когда старый первичный сервер в какой-то момент хочет повторно присоединиться к набору реплик, он сначала должен откатить события, которые не были реплицированы и больше не являются частью базы данных.)
Картинка ниже иллюстрирует эту последовательность событий. Обратите внимание, что события D и E не существуют в конечном состоянии базы данных, но наблюдатель полагает, что они существуют.
К счастью, есть несколько решений, которые вы можете использовать для получения правильного чтения, даже в случае отказов и откатов:
Хорошая вещь с отказоустойчивостью состоит в том, что они заставят любое клиентское соединение закрыться, и поэтому клиенты должны повторно соединиться и повторно обнаружить первичное устройство в наборе реплик. В рамках этого процесса можно также сделать что-то, чтобы предотвратить описанную выше нежелательную ситуацию.
- Простое решение, которое, вероятно, было бы полезно для таких приложений, как Meteor, — это просто перезагрузить модель данных, как если бы приложение было перезапущено, а затем продолжить как обычно настраивать оплог на новом первичном сервере. Единственное, о чем стоит здесь беспокоиться, это то, что это не вызывает всплеска запросов, когда всем приложениям внезапно нужно выполнить много запросов для перезагрузки своей модели данных. Я мог бы придумать различные способы, чтобы попытаться смягчить это, но это будет выходить за рамки этого сообщения в блоге.
- ETL и системы репликации обычно имеют некоторые внутренние буферы, содержащие события, подлежащие репликации. Во многих случаях может быть достаточно просто остановить репликацию, сравнить буфер с оплогом на новом первичном сервере и при необходимости удалить все операции, которые, по-видимому, исчезли при отработке отказа. Если количество пропавших событий (т.е. откат) больше, чем в буфере инструмента ETL / средства репликации, он должен просто остановиться с ошибкой и позволить пользователю исправить и перезапустить ситуацию. Обратите внимание, что буфер может быть увеличен специально, чтобы минимизировать вероятность того, что это когда-либо произойдет.
Наконец, совершенно другой подход будет заключаться в оплогах большинства или даже всех узлов в наборе реплик. Поскольку пара ts & hполей однозначно идентифицирует каждую транзакцию, можно легко объединить результаты каждого оплога на стороне приложения, чтобы «выходные данные» хвостового потока были событиями, которые были возвращены, по крайней мере, большинством MongoDB узлы. При таком подходе вам не нужно заботиться о том, является ли узел первичным или вторичным, вы просто задаете оплог всех из них, и все события, возвращаемые большинством оплогов, считаются действительными. Если вы получаете события, которых нет в большинстве оплогов, такие события пропускаются и отбрасываются.
В MongoDB мы планируем улучшить пользовательский интерфейс для получения уведомлений об изменениях путем отслеживания оплога. Одно из улучшений заключалось бы в инкапсуляции одного или нескольких из вышеуказанных методов, которые будут прозрачно обрабатываться библиотекой (например, соединителем MongoDB). Еще одним будущим решением будет SERVER-18022 , который позволит считывать данные, в данном случае — оплог, из снимка, отражающего зафиксированное большинством состояние кластера.
Обновление бесхозных документов в кластере
В изолированном кластере потерянные документы — это документы, которые существуют на узле базы данных, даже если в соответствии с ключом шарда и текущим распределением порций документ действительно должен находиться на другом узле в данный момент времени. (Текущее распределение чанков хранится на серверах конфигурации в коллекции config.chunks .)
Даже если бесхозные документы — по их определению — не должны существовать, они могут появиться и безвредны. Например, они могут появиться из-за прерванной миграции фрагментов: документы были вставлены в новый сегмент, но по какой-то причине не удалены из старого.
В большинстве случаев MongoDB будет правильно обрабатывать их существование. Например, если вы подключаетесь к защищенной базе данных через mongos и выполняете find (), то процесс mongod отфильтровывает из результирующего набора любые потерянные документы, с которыми он может столкнуться. (Может быть, тот же документ возвращается другим mongod, где его существование является действительным в соответствии с текущим распределением чанков.) С другой стороны, если вы подключитесь напрямую к набору реплик и выполните то же самое find (), вы сможете чтобы увидеть находящийся там сиротский документ. Вы даже можете вставить () документ со значением ключа шарда вне допустимого диапазона в узел, чтобы искусственно создать для себя потерянный документ.
Один случай, когда к сожалению не обнаруженные и отфильтрованные документы в настоящее время не обнаружены, — это многократное обновление :
db.people.update(
{ age: { $gte: 65 } },
{ $set: { seniorCitizen: true } },
{ multi: true }
)
Если такое многократное обновление попадет в потерянный документ, потерянный документ будет обновлен, обновление будет записано в оплог и реплицировано. Следовательно, если вы отслеживаете оплог в изолированном кластере, вы можете увидеть эти обновления, которые с точки зрения всего кластера являются призрачными обновлениями — они никогда не происходили и не должны быть видны извне.
К сожалению, я не знаю ни одного общего и надежного способа обойти эту проблему. В некоторых приложениях вы можете минимизировать риск появления потерянных документов, отключив процесс балансировки и распределив фрагменты вручную:
- Отключить процесс балансировки .
- Разделите и распределите вручную фрагменты , желательно в пустой коллекции, прежде чем вставлять данные.
- Для большей уверенности запускайте cleanupOrphaned периодически, или когда вы считаете, что где-то могут быть документы-сироты. (Например, если вы вручную переместили несколько фрагментов.)
По сути, это проблема, которую необходимо решить в кодовой базе MongoDB. Мультиобновление должно обнаружить и пропустить потерянные документы. В рамках улучшения пользовательского опыта для случаев использования уведомлений об изменениях нам также придется как-то решить эту проблему. (Решения обсуждаются, но я не буду вдаваться в подробности в этом посте, так как больше внимания уделял списку решений или обходных путей, которые в настоящее время можно применять.)
Если вы хотите узнать больше об архитектуре MongoDB, скачайте наше руководство !