В предыдущей статье мы рассмотрели различные источники данных и обсудили наиболее подходящий формат данных для ввода данных в нашу среду больших данных.
В этой статье мы углубимся в HDFS, систему хранения Hadoop, которая является одной из самых надежных систем хранения в мире. Распределенное хранение и репликация данных — главная особенность HDFS, которая делает ее отказоустойчивой системой хранения. Функциональные возможности, которые делают HDFS пригодной для больших наборов данных для работы на стандартном оборудовании, включают отказоустойчивость, высокую доступность, надежность и масштабируемость.
В нашей предыдущей статье мы рассмотрели модель главного подчиненного устройства и типы узлов с помощью службы хранения облачных объектов (OSS) Alibaba и E-MapReduce . Давайте прямо посмотрим, как данные хранятся в HDFS. Помните мантру «напишите один раз для чтения», поскольку файл не может быть отредактирован после его создания и записи в HDFS. Его можно прочитать и обработать только с помощью другого инструмента, такого как Spark, и затем вы можете записать обратно в файл HDFS.
Предположим, вам нужно записать огромный файл в HDFS. Файл не будет напрямую записан в HDFS. Он будет разбит на мелкие кусочки, известные как блоки. Размер блока по умолчанию составляет 128 МБ, который также может быть увеличен в зависимости от требований. HDFS известна своим распределенным хранилищем. Таким образом, эти блоки распределяются между различными узлами кластера. Это позволяет MapReduce обрабатывать данные параллельно. В результате Hadoop получает распределенное хранилище и распределенную обработку, что делает его эффективным по-своему. Теперь сохраненные блоки реплицируются на другие узлы данных до тех пор, пока упомянутый коэффициент репликации не будет удовлетворен. Коэффициент репликации по умолчанию равен трем. HDFS обеспечивает репликацию блоков между двумя узлами кластера в одной стойке и другим узлом в другой стойке. Это может помочь улучшить приложениеотказоустойчивость, так что даже если вся стойка выйдет из строя, будет высокая доступность, поскольку реплика присутствует и в другой стойке.
Вы должны быть знакомы с некоторыми основными командами Hadoop, которые станут основой всего цикла. Команды Hadoop HDFS аналогичны среде Linux, поэтому просто добавьте к ним префикс hadoop fs.
Вот некоторые команды, которые мы будем использовать в этой статье:
-
Hadoop fs –ls
-
MkDir
-
кошка
-
copyFromLocal
-
moveFromLocal
-
ср
-
милливольт
-
ставить
-
получить
-
CHMOD
Мы будем использовать эти команды одну за другой в различных ситуациях, чтобы дать четкое представление об их использовании.
Давайте переключим пользователя на Hadoop через su hadoop. После этого перечислите содержимое под пользователем с помощью следующей команды:
$ hadoop fs –ls /user
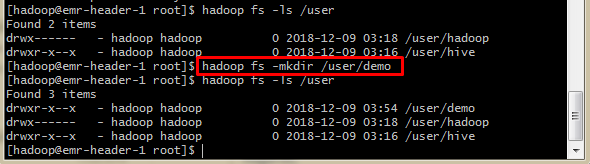
Есть только две директории с именем hadoop и hive под пользователем. Итак, давайте создадим новый каталог с именем ‘demo’, используя:
$ hadoop fs –mkdir /user/demo
Этот каталог может использоваться в дальнейшем как место для хранения наших загруженных и обработанных файлов.
SQOOP
Когда дело доходит до импорта данных из системы управления реляционными базами данных (RDBMS), такой как MySQL или Oracle, в HDFS, используется инструмент с открытым исходным кодом, называемый Sqoop. Sqoop использует MapReduce для импорта и экспорта данных. С Sqoop вы можете:
- Импорт отдельных таблиц или целых баз данных в файлы в HDFS.
- Импортируйте из баз данных SQL прямо в хранилище данных Hive.
Помимо этого, Sqoop также поддерживает дополнительные цели импорта, такие как импорт записей в HBase и Accumulo. Эта статья посвящена импорту данных из различных баз данных в HDFS, которая является основной для воспроизведения больших данных. Импорт в Hive и HBase будет рассмотрен в следующих статьях.
Вам не нужно устанавливать Sqoop отдельно, так как E-MapReduce поставляется с Sqoop интегрированным с версии 1.3. Давайте проверим перед использованием. Дайте sqoop-версию. Это покажет вам сообщение, что sqoop запущен и работает, и версия sqoop будет отображаться в соответствии с нашей командой.

Две важные функции для рассмотрения:
- Sqoop import
- Sqoop export
Для работы с этими двумя функциями существуют некоторые предварительные условия.
Namenode Местоположение
Нам понадобится расположение Namenode для чтения и записи файлов в HDFS. Файл core-site.xml содержит информацию о том, где Namenode работает в кластере, параметры ввода-вывода и т. Д. Есть два способа получить это. Либо на месте, либо в облаке, и обычный метод заключается в получении этого из файла «core-site.xml», который содержит все детали конфигурации. Это можно сделать, перейдя к местоположению файла, как показано на скриншотах ниже.

Используйте ls /usr/lib/Hadoop-current/etc/Hadoopдля отображения различных файлов конфигурации HDFS, MapReduce и Yarn. Этот путь немного варьируется в зависимости от провайдеров, таких как Cloudera. Из перечисленных файлов вы можете заметить некоторые основные файлы, такие как hdfs-site.xml и core-site.xml.

Но Alibaba Cloud предоставляет удобный пользовательский интерфейс, который сокращает усилия по поиску файлов конфигурации и изменению различных настроек с помощью команд Linux, что может быть непросто для начинающих.
Теперь давайте перейдем к кластеру, который мы создали. Перейдите в раздел «Кластеры и службы» на вкладке «Управление кластерами». Вы можете увидеть услуги в действии. Нажмите на HDFS

На следующем экране перейдите к «Конфигурация», и здесь вы можете просмотреть все файлы конфигурации, которые мы нашли с помощью команд Linux. Теперь изменение конфигурации становится проще, прямо!

На изображении выше вы можете увидеть фактор репликации, который находится в hdfs-site.xml. Давайте перейдем к core-site.xml и отметим расположение Namenode следующим образом:

Драйверы и разъемы
Если необходимые драйверы не поставляются Sqoop по умолчанию, загрузите их и сохраните в /usr/lib/sqoop-current/lib. Нижеследующие пункты объяснят это подробно.
Sqoop в основном работает на главном узле, но если вы настроили его для работы на любом из рабочих узлов, установите драйверы JDBC только на машине, на которой работает Sqoop. Нет необходимости устанавливать их на всех хостах вашего многоузлового кластера.
1. Предположим, что ваши данные находятся в базе данных Oracle. Примите лицензионное соглашение и загрузите драйвер JDBC для Oracle по приведенной ниже ссылке, поскольку он не будет доступен в драйверах по умолчанию:
http://www.oracle.com/technetwork/database/enterprise-edition/jdbc-112010-090769.html
Загрузите драйвер JDBC, который совместим с вашей версией базы данных, и скопируйте его в библиотеку Sqoop, как показано ниже:
$ sudo cp ojdbc6.jar /usr/lib/sqoop-current/lib
sudo дает вам привилегии суперпользователя и cp копирует файл по указанному пути.
Теперь перечислите содержимое в пути, чтобы убедиться, что файл скопирован:

Существует три формата для соединения с сервером Oracle:
—connect jdbc: oracle: thin: @OracleServer: OraclePort: OracleSID
—connect jdbc: oracle: thin: @ // OracleServer: OraclePort / OracleService
—connect jdbc: oracle: thin: @TNSName
2. Предположим, ваши данные в MySQL. Эта последняя версия EMR поставляется с встроенным коннектором MySQL (если вы видите коннектор MySQL на предыдущем скриншоте).
3. Предположим, ваши данные находятся на сервере Microsoft SQL, затем загрузите драйвер JDBC для Microsoft SQL Server по приведенной ниже ссылке и скопируйте его в библиотеку Sqoop, как мы делали ранее:
https://www.microsoft.com/en-us/download/details.aspx?displaylang=en&id=11774
$ sudo cp sqljdbc_6.0.81_enu.tar.gz /usr/lib/sqoop-current/lib
Форматы файлов
Вы можете импортировать данные в одном из двух форматов файла: текстовый файл с разделителями или файлы последовательности.
Формат импорта по умолчанию — текст с разделителями. Вы также можете указать это непосредственно в команде, используя --as-textfile команду, которая легко поддерживается для дальнейшего манипулирования другими инструментами, такими как Hive. Файлы последовательности представляют собой файлы двоичного формата, которые хранят отдельные записи в пользовательских типах данных, специфичных для записей. Используйте --as-sequencefile в этом случае.
Управлять параллелизмом
Sqoop импортирует данные параллельно. Чтобы выполнить импорт, вы можете указать количество задач на карте (количество параллельных процессов) с помощью –m. При выполнении параллельного импорта требуется разделительный столбец, по которому он может разделить рабочую нагрузку. По умолчанию этот столбец разделения будет столбцом первичного ключа (если он есть) в таблице. Если значения для первичного ключа распределены неравномерно, это приводит к несбалансированным задачам. Следовательно, явно выберите другой столбец с --split-by аргументом.
Sqoop Import
Теперь я загрузил лист tripadvisor_merged в базу данных Oracle, которую я использую.
Мне нужно переместить это в HDFS и, следовательно, я скачал и переместил необходимый файл JAR по указанному пути, как обсуждалось выше.
Прежде чем выполнять импорт или экспорт, давайте попробуем оценить запрос следующим образом
sqoop eval --connect jdbc:oracle:thin:@182.156.193.194:1556:ORCL --username xxx--password xxx --query "SELECT * FROM TRIP_ADVISOR LIMIT 3"
Приведенный выше запрос основан на следующих условиях:
-
Host: 182.156.193.194
-
Порт: 1556
-
SID: ORCL
Если запрос выполнен успешно, выходная таблица будет отображаться в терминале. Теперь все готово для импорта данных.
sqoop import --connect jdbc:oracle:thin:@182.156.193.194:1556:ORCL --username xxx --P --table TRIP_ADVISOR --target-dir hdfs://emr-header-1.cluster-88549:9000/user/demo/sqoop -m1
Чтобы указать количество задач карты, мы можем использовать -- m опцию, за которой следует числовое число.
Когда мы выполним вышеуказанную команду, будет выполнена только одна задача карты.
Если вы перечислите каталог, вы найдете только один выходной файл, помеченный как Part-m-00000. Если выходной каталог не указан, то Sqoop создает каталог с именем таблицы, которую вы загрузили в HDFS, и делит данные на part-m-00000, part-m-00001и так далее.
Здесь мы импортируем всю таблицу. Вы также можете импортировать определенные записи, используя where предложение. Мы также можем перечислить базы данных, перечислить таблицы и импортировать все таблицы, присутствующие в базе данных, используя различные команды Sqoop.

Устранение неполадок
1. Проблема : Отсутствует драйвер или использование неверного имени драйвера соответствующего jdbc гр Ласса.
Например, could not load db driver class: oracle.jdbc.OracleDriver

Решение : Поместите odbc6.jar в правильный путь /usr/lib/sqoop/libи повторите попытку. Если файл JAR не распознан, перезапустите сервер Sqoop и попробуйте снова. Вы также можете вручную указать драйвер в команде, используя --driver опцию в Sqoop, как показано ниже:
sqoop import --connect jdbc:oracle:thin:@192.168.6.23:1526:xxx --username xxx --P –table xxx --target-dir hdfs://emr-header-1.cluster-88549:9000/user/demo/sqoop -m1 --driver oracle.jdbc.driver.OracleDriver
Аналогично, для MySQL используйте --driver com.mysql.jdbc.Driver.
2. Проблема : сетевой адаптер не может установить соединение.
Решение : ошибка соединения отклонена из-за следующих сценариев:
- Служба Oracle может не работать на указанном хосте и порте.
- Брандмауэр может ограничить доступ клиента к серверу Oracle.
Поэтому на начальном этапе лучше подтвердить ограничение хоста, порта и межсетевого экрана Oracle между ними. Это можно легко проверить с помощью telnet.
3. Проблема : неправильный подход к предоставлению пароля или имени пользователя базы данных.
Например, WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead
Решение : вы получите это сообщение, когда вы явно упомянете пароль в команде, используя –password. Вместо этого попробуйте использовать –P в команде, которая позволяет вам вводить пароль во время выполнения, что более безопасно.
Лучшие практики
- Sqoop не поддерживает несколько форматов файлов Hadoop, таких как ORC или RC.
- Упоминание имен схем и таблиц заглавными буквами позволит избежать некоторых проблем.
- Используйте,
split-byесли вам нужно несколько картографов. - Избегайте использования имен столбцов, которые являются ключевыми словами в Sqoop.
- Если таблица не имеет первичный ключ определена , а
--split-byопция не предусмотрена в команде, то импорт будет ошибка , если количество картографов явно не установлено в единицу.
В следующей статье мы обсудим Spark для больших данных и покажем, как настроить его в Alibaba Cloud.
«Некоторые из лучших теоретизаций приходят после сбора данных, потому что тогда вы осознаете другую реальность». Роберт Дж. Шиллер
п