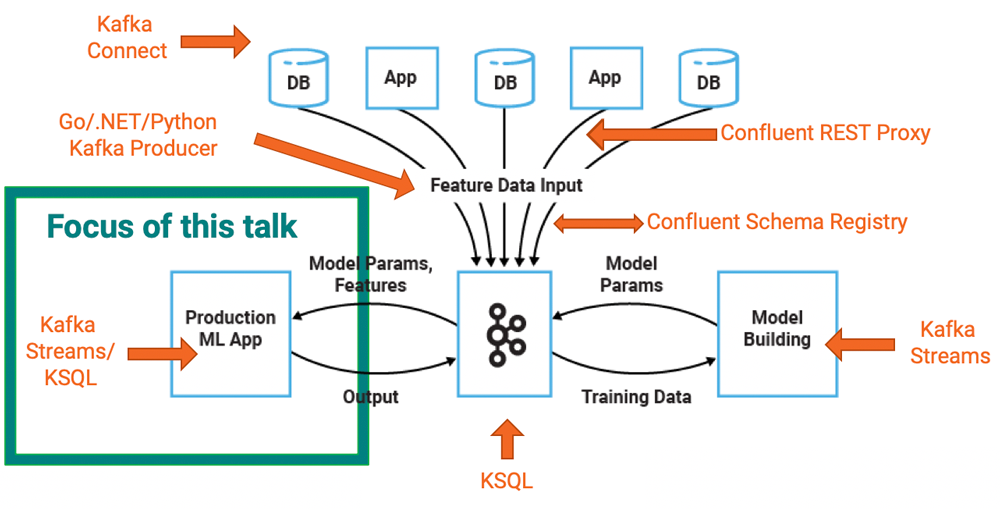
Взаимоотношения между Apache Kafka и машинным обучением (ML) интересны, о которых я написал довольно много в « Как создать и развернуть масштабируемое машинное обучение в производстве с помощью Apache Kafka» и « Использование Apache Kafka для ускоренного машинного обучения» .
В этом посте рассматривается конкретная часть построения инфраструктуры машинного обучения: развертывание аналитической модели в приложении Kafka для прогнозов в реальном времени.
Обучение модели и развертывание модели могут быть двумя отдельными процессами. Тем не менее, вы также можете использовать многие из этих шагов для интеграции и предварительной обработки данных, потому что вам часто нужно выполнять одинаковую интеграцию, фильтрацию, обогащение и агрегирование данных для обучения модели и выведения модели.
Мы обсудим и сравним два различных варианта развертывания моделей: серверы моделей с удаленными вызовами процедур (RPC) и встроенные модели в клиентские приложения Kafka. В нашем примере специально используется TensorFlow, но базовые принципы также действительны для других систем машинного обучения / глубокого обучения, таких как H2O.ai, Deeplearning4j, Google Cloud Machine Learning Engine и SAS.
Вам также может понравиться:
Создание аналитических API в реальном времени в Scale
TensorFlow — библиотека с открытым исходным кодом для машинного обучения / глубокого обучения
TensorFlow — это программная библиотека с открытым исходным кодом для высокопроизводительных численных расчетов. Его гибкая архитектура позволяет легко развертывать вычисления на различных платформах (процессорах, графических процессорах, TPU и т. Д.), От настольных компьютеров до кластеров серверов, мобильных и периферийных устройств. Первоначально разработанный исследователями и инженерами из команды Google Brain в рамках организации по искусственному интеллекту Google, он имеет мощную поддержку машинного обучения и глубокого обучения и используется во многих областях. TensorFlow — это целая экосистема, а не просто один компонент.
Учитывая, что этот блог посвящен обслуживанию моделей, нас в первую очередь интересует объект SavedModel, в котором хранится обученная модель и TensorFlow Serving в качестве сервера моделей:
SavedModel — это, по сути, двоичный файл, сериализованный с использованием буферов протокола (Protobuf). Созданные классы в C, Python, Java и т. Д. Могут загружать, сохранять и получать доступ к данным. Формат файла — либо читаемый человеком TextFormat (.pbtxt), либо сжатые двоичные буферы протокола (.pb). Графовый объект является основой вычислений в TensorFlow. Веса хранятся в отдельных файлах контрольных точек.
Поскольку мы сосредоточены на развертывании модели TensorFlow, то, как модель была обучена заранее, не имеет значения. Вы можете использовать облачный сервис и конвейер интеграции, такой как Cloud ML Engine и его экосистему Google Cloud Platform (GCP), или создать свой собственный конвейер для обучения модели. Kafka может сыграть ключевую роль не только в развертывании модели, но и в интеграции данных, предварительной обработке и мониторинге.
Потоковая обработка с модельными серверами и RPC
Сервер модели управляется либо самостоятельно, либо размещается поставщиком аналитики или поставщиком облачных услуг. Серверы моделей не только разворачивают и кэшируют модели для вывода модели, но и предоставляют дополнительные функции, такие как управление версиями или A / B-тестирование. Связь между вашим приложением и модельным сервером обычно осуществляется с помощью RPC через HTTP или gRPC. Эта связь запрос-ответ между приложением Kafka и сервером модели происходит для каждого отдельного события.
Многие модели серверов доступны. Вы можете выбрать один из серверов моделей с открытым исходным кодом, таких как Seldon Server, PredictionIO и Hydrosphere.io, или использовать серверы моделей от поставщиков аналитики, таких как H2O.ai, DataRobot, IBM или SAS.
В этой статье используется TensorFlow Serving, модель сервера от TensorFlow. Он может быть размещен самостоятельно или использовать сервис Cloud ML Engine. TensorFlow Serving обладает следующими характеристиками:
- Содержит конечные точки gRPC и HTTP
- Выполняет управление версиями модели без изменения кода клиента
- Планирует группирование отдельных запросов на вывод в пакеты для совместного выполнения
- Оптимизирует время вывода для минимальной задержки
- Поддерживает множество обслуживаемых объектов (обслуживаемая — это либо модель, либо задача для обслуживания данных, которые соответствуют вашей модели):
- Модели TensorFlow
- вложениях
- Словарные справочные таблицы
- Преобразования функций
- Не основанные на TensorFlow модели
- Способен канарейке и A / B тестированию
Вот как взаимодействует сервер приложений и моделей Kafka: 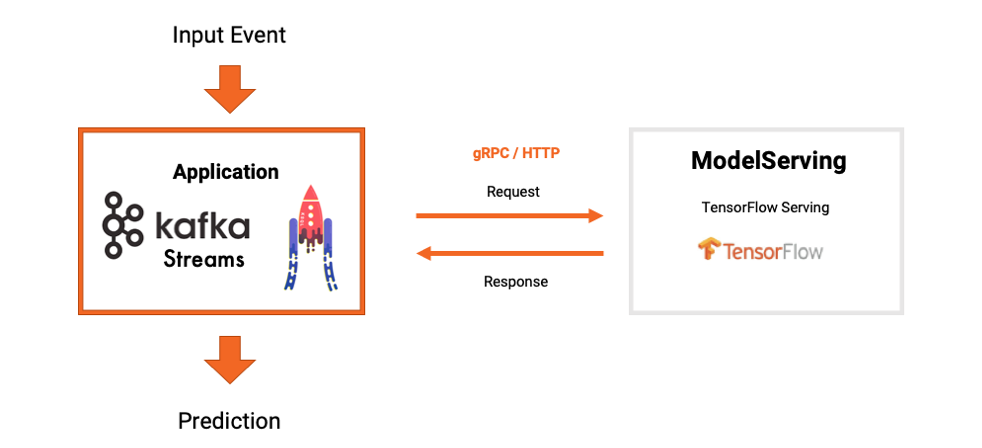
Процесс внедрения приложения Kafka прост. Вот фрагменты кода для приложения Kafka Streams и RPC для обслуживания TensorFlow:
1. Импорт Kafka и API обслуживания TensorFlow:
Джава
1
import org.apache.kafka.common.serialization.Serdes;
2
import org.apache.kafka.streams.KafkaStreams;
3
import org.apache.kafka.streams.StreamsBuilder;
4
import org.apache.kafka.streams.StreamsConfig;
5
import org.apache.kafka.streams.kstream.KStream;
6
import com.github.megachucky.kafka.streams.machinelearning.TensorflowObjectRecogniser;
2. Настройте приложение Kafka Streams:
Джава
xxxxxxxxxx
1
// Configure Kafka Streams Application
2
final String bootstrapServers = args.length > 0 ? args[0] : "localhost:9092";
3
final Properties streamsConfiguration = new Properties();
5
// Give the Streams application a unique name. The name must be unique
7
// in the Kafka cluster against which the application is run.
8
streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-streams-tensorflow-serving-gRPC-example");
9
// Where to find Kafka broker(s).
11
streamsConfiguration.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
3. Выполните RPC для обслуживания TensorFlow (и перехватывайте исключения в случае сбоя RPC):
Джава
xxxxxxxxxx
1
KStream<String, Object> transformedMessage = imageInputLines.mapValues(value -> {
2
System.out.println("Image path: " + value);
4
imagePath = value;
6
TensorflowObjectRecogniser recogniser = new TensorflowObjectRecogniser(server, port);
8
System.out.println("Image = " + imagePath);
10
InputStream jpegStream;
11
try {
12
jpegStream = new FileInputStream(imagePath);
13
14
// Prediction of the TensorFlow Image Recognition model:
15
List<Map.Entry<String, Double>> list = recogniser.recognise(jpegStream);
16
String prediction = list.toString();
17
System.out.println("Prediction: " + prediction);
18
recogniser.close();
19
jpegStream.close();
20
21
return prediction;
22
} catch (Exception e) {
23
e.printStackTrace();
24
25
return Collections.emptyList().toString();
26
}
27
});
4. Запустите приложение Kafka:
Джава
xxxxxxxxxx
1
// Start Kafka Streams Application to process new incoming images from the Input Topic
2
final KafkaStreams streams = new KafkaStreams(builder.build(), streamsConfiguration);
4
streams.start();
Вы можете найти полный пример вывода модели с помощью Apache Kafka и Kafka Streams, используя обслуживание TensorFlow на GitHub.
Потоковая обработка со встроенными моделями
Вместо использования сервера модели и связи RPC вы также можете встроить модель непосредственно в приложение Kafka. Это может быть либо приложение для обработки потоков Kafka, использующее Kafka Streams или KSQL, либо вы можете использовать клиентский API Kafka, такой как Java, Scala, Python или Go.
В этом случае нет зависимости от внешнего модельного сервера. Модель загружается в приложение, например, с использованием API-интерфейса TensorFlow Java в приложении Kafka Streams:
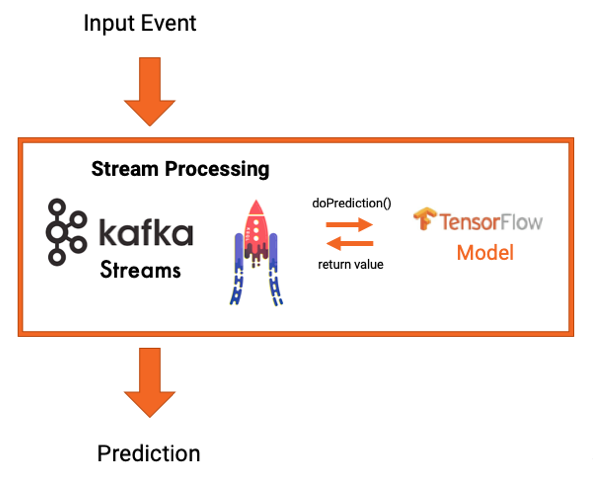
Опять же, реализация приложения Kafka проста. Вот фрагменты кода для встраивания модели TensorFlow в приложение Kafka Streams для предсказаний в реальном времени:
1. Импорт Kafka и API TensorFlow:
Джава
xxxxxxxxxx
1
import org.apache.kafka.streams.KafkaStreams;
2
import org.apache.kafka.streams.KeyValue;
3
import org.apache.kafka.streams.StreamsBuilder;
4
import org.apache.kafka.streams.StreamsConfig;
5
import org.apache.kafka.streams.integration.utils.EmbeddedKafkaCluster;
6
import org.apache.kafka.streams.integration.utils.IntegrationTestUtils;
7
import org.apache.kafka.streams.kstream.KStream;
8
import org.deeplearning4j.nn.modelimport.keras.KerasModelImport;
9
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
2. Загрузите модель TensorFlow - либо из хранилища данных (например, ссылки Amazon S3), либо из памяти (например, полученной из раздела Kafka):
Джава
xxxxxxxxxx
1
// Step 1: Load Keras TensorFlow Model using DeepLearning4J API
2
String simpleMlp = new ClassPathResource("generatedModels/Keras/simple_mlp.h5").getFile().getPath();
3
System.out.println(simpleMlp.toString());
4
MultiLayerNetwork model = KerasModelImport.importKerasSequentialModelAndWeights(simpleMlp);
3. Настройте приложение Kafka Streams:
Джава
xxxxxxxxxx
1
// Configure Kafka Streams Application
2
Properties streamsConfiguration = new Properties();
3
streamsConfiguration.put(StreamsConfig.APPLICATION_ID_CONFIG, "kafka-streams-tensorflow-keras-integration-test");
5
streamsConfiguration.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, CLUSTER.bootstrapServers());
6
// Specify default (de)serializers for record keys and for record values
8
streamsConfiguration.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
9
streamsConfiguration.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
4. Примените модель TensorFlow для потоковой передачи данных:
Джава
xxxxxxxxxx
1
final KStream<String, String> inputEvents = builder.stream(inputTopic);
2
inputEvents.foreach((key, value) -> {
4
// Transform input values (list of Strings) to expected DL4J parameters (two Integer values):
6
String[] valuesAsArray = value.split(",");
7
INDArray input = Nd4j.create(Integer.parseInt(valuesAsArray[0]), Integer.parseInt(valuesAsArray[1]));
8
// Model inference in real time:
10
output = model.output(input);
11
prediction = output.toString();
12
});
5. Запустите приложение Kafka:
Джава
xxxxxxxxxx
1
final KafkaStreams streams = new TestKafkaStreams(builder.build(), streamsConfiguration);
2
streams.cleanUp();
3
streams.start();
Дополнительные примеры встраивания моделей, созданных с помощью TensorFlow, H2O и Deeplearning4j, в приложение Kafka Streams доступны на GitHub.
Вы можете даже написать модульные тесты, используя известные библиотеки тестирования, как показано в этом примере модульного теста с использованием библиотек тестирования JUnit и Kafka Streams .
А ниже приведен пример развертывания модели с использованием пользовательской функции KSQL (UDF) :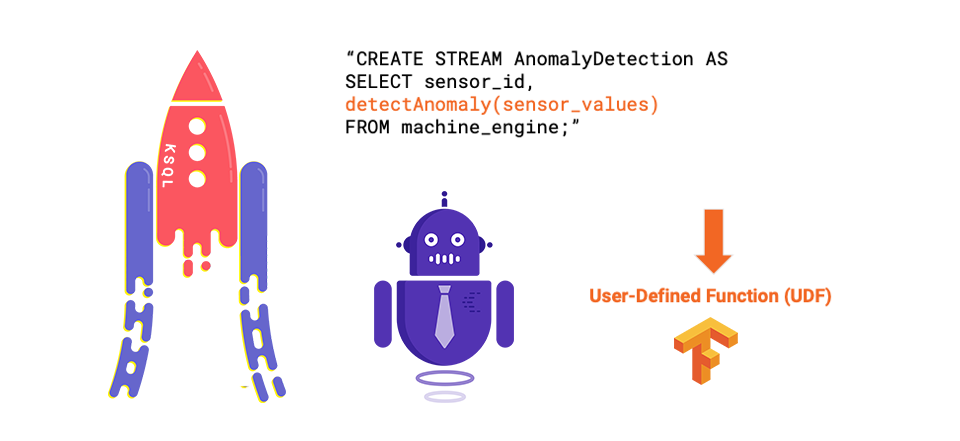
Все, что вам нужно сделать, это реализовать Java-интерфейс KSQL UDF, а затем развернуть UDF на сервере KSQL. Подробное объяснение того, как создать свой собственный KSQL UDF , описано в предыдущем сообщении в блоге. При таком подходе конечный пользователь пишет запросы SQL для применения аналитической модели в режиме реального времени.
Какие модели должны быть непосредственно встроены в приложение?
Не каждая модель идеально подходит для встраивания в приложение. При принятии решения о том, имеет ли смысл встраивание, следует учитывать следующие факторы:
- Производительность модели: чем быстрее, тем лучше
- Модель двоичного формата: в лучшем случае это скомпилированный Java байт-код
- Размер модели: меньше МБ и меньше памяти предпочтительнее
- Возможности модели сервера: готовые и готовые, а не нужные
Модели, написанные на языке Python, работают медленно, потому что это динамический язык, который должен интерпретировать множество переменных и команд во время выполнения.
Java-классы H2O (например, деревья решений) выполняются очень быстро, часто за микросекунды.
Небольшая нейронная сеть TensorFlow Protobuf, которая загружается всего за несколько МБ или меньше.
Большая нейронная сеть TensorFlow Protobuf объемом 100 МБ или более требует большого объема памяти и обеспечивает относительно медленное выполнение.
Стандартные модели (например, XML / JSON, основанные на PMML или ONNX) включают другие этапы помимо обработки моделей, такие как предварительная обработка данных. Часто используются организационные проблемы и технические ограничения / ограничения для использования этих стандартов, а производительность, как правило, хуже, чем у серийно выпускаемых моделей, таких как SavedModel TensorFlow.
В конечном счете, должна ли модель быть встроена непосредственно в ваше приложение, зависит от самой модели, вашей аппаратной инфраструктуры и требований вашего проекта.
Восстановление функций модельного сервера в приложении Kafka не сложно
Внедрение модели в приложение означает, что у вас нет функций сервера модели из коробки. Вы должны были бы реализовать их самостоятельно. Первый вопрос, который нужно задать себе: нужны ли мне функции модельного сервера? Нужно ли обновлять мою модель динамически? А как насчет версий? A / B тестирование? Канарейки?
Хорошей новостью является то, что реализовать эти функции не сложно. В зависимости от ваших требований и набора инструментов вы можете:
- Запустите новую версию приложения (например, модуль Kubernetes)
- Отправить и потреблять модель или веса через тему Кафки
- Динамически загружать новую версию через API (например, Java API TensorFlow)
- Используйте сервисную сетку (например, Envoy, Linkerd или Istio) вместо модельного сервера для A / B-тестирования, зеленого / синего развертываний, темных запусков и т. Д.
Давайте оценим компромиссы обоих подходов к использованию аналитических моделей в приложении Kafka.
Компромисс модели сервера против встраивания модели
Вы можете развернуть аналитические модели на сервере моделей и использовать связь RPC, или вы можете встроить их непосредственно в свое приложение. Нет лучшего варианта, потому что это зависит от вашей инфраструктуры, требований и возможностей.
Зачем использовать сервер моделей и RPC вместе с приложением потоковой передачи событий?
- Простая интеграция с существующими технологиями и организационными процессами
- Проще понять, если вы приехали из мира, где нет событий
- Позже возможен переход на реальную потоковую передачу
- Встроенное управление моделями для разных моделей, управление версиями и A / B-тестирование
- Встроенный мониторинг
Зачем вставлять модель в приложение потоковой передачи событий?
- Лучшая задержка с локальным выводом вместо необходимости выполнять удаленный вызов
- Автономный вывод (устройства, обработка ребер и т. Д.)
- Нет связи между доступностью, масштабируемостью и задержкой / пропускной способностью вашего приложения Kafka Streams с SLA интерфейса RPC
- Отсутствие побочных эффектов (например, в случае сбоя) - обработка Кафкой охватывает все (например, ровно один раз)
Оба варианта имеют свои плюсы и минусы и рекомендуются в разных случаях, в зависимости от сценария.
Развертывание облачной модели с Kubernetes
В облачных инфраструктурах можно получить преимущества обоих подходов. Давайте использовать Kubernetes в качестве нашей облачной среды, хотя другие облачные технологии могут предоставлять аналогичные функции.
Если вы встраиваете аналитическую модель в приложение Kafka, вы получаете все преимущества отдельного модуля, в котором есть контейнер для обработки потока и вывода модели. Внешняя зависимость от модельного сервера отсутствует.
В следующем примере вы можете независимо масштабировать приложение Kafka Streams со встроенной моделью, запускать новую версию, участвовать в A / B-тестировании или другой маршрутизации и выполнять обработку ошибок с помощью собственных облачных прокси, таких как Envoy или Linkerd:
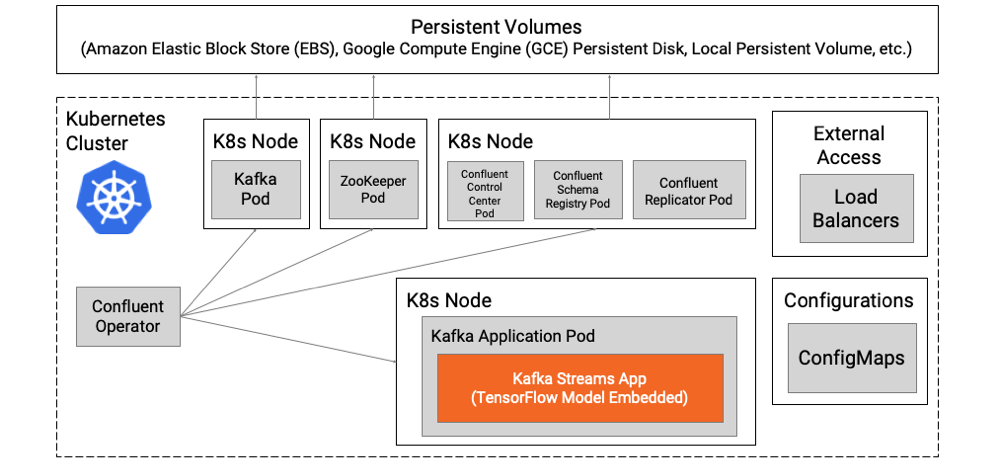
Если вы все еще хотите получить преимущества и возможности модельного сервера, тогда можно использовать шаблон проектирования коляски. Kubernetes поддерживает добавление дополнительных контейнеров со специфическими задачами в ваш модуль. В следующем примере приложение Kafka Streams развертывается в одном контейнере, а сервер модели - в качестве коляски в другом контейнере в том же модуле.
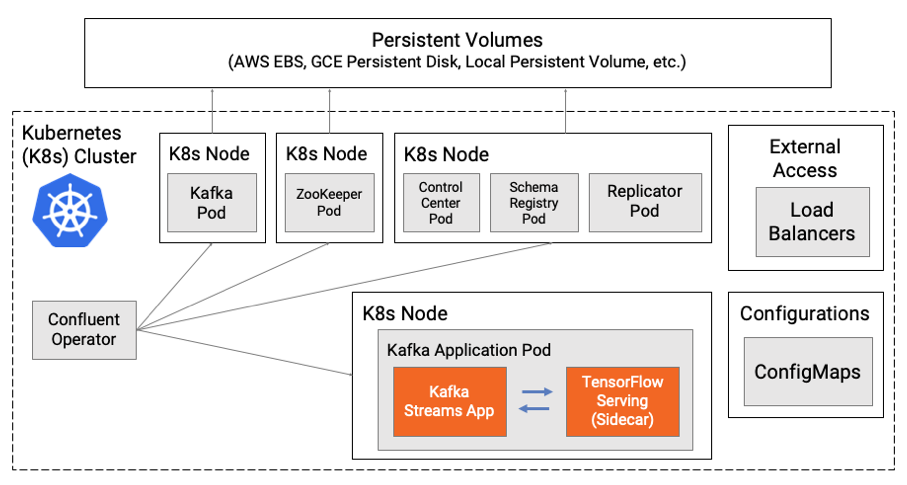
Это делает возможным использование возможностей модельного сервера с надежностью и масштабируемостью одного модуля. У него все еще есть недостаток использования RPC между каждым контейнером. С обоими контейнерами, развернутыми в одном модуле, вы можете минимизировать задержку и вероятность ошибки.
Развертывание модели на грани
Модели не всегда развертываются в облаке или в центре обработки данных. В некоторых случаях модели развертываются по краю . Краевое развертывание может означать:
- Edge датацентр или краевое устройство / машина
- Кластер Kafka, один брокер Kafka или клиент Kafka на краю
- Мощный клиент (такой как KSQL или Java) или легкий клиент (такой как C или JavaScript)
- Внедрение или вывод модели RPC
- Местное или дистанционное обучение
- Правовые и нормативные последствия
Для некоторых телекоммуникационных провайдеров определение периферийных вычислений - это сверхнизкая задержка при сквозной связи менее 100 мс. Это реализуется с помощью таких платформ, как стек программного обеспечения с открытым исходным кодом для облачной инфраструктуры StarlingX , для которого требуется полный кластер и хранилище объектов OpenStack и Kubernetes. Для других это означает мобильное устройство, облегченную плату или сенсор, на котором развернуты очень маленькие и легкие приложения и модели на языке C.
С точки зрения Кафки, есть много вариантов. Вы можете создавать легкие граничные приложения с помощью librdkafka, собственной клиентской библиотеки Kafka C / C ++, которая полностью поддерживается Confluent. Также возможно встроить модели в мобильное приложение, используя JavaScript и используя интеграцию REST Proxy или WebSocket для связи Kafka.
Развертывание независимой от технологии модели с помощью Kafka
Развертывание модели может быть полностью отделено от обучения модели с точки зрения процесса и технологии. Инфраструктура развертывания может работать с различными моделями, даже с моделями, обученными с использованием различных систем машинного обучения. Kafka также предоставляет отличную основу для мониторинга машинного обучения, включая технический мониторинг инфраструктуры и мониторинг конкретной модели, такой как производительность или точность модели.
Kafka - это превосходный и дополняющий инструмент для инфраструктуры машинного обучения, независимо от того, реализуете ли вы все с помощью Kafka, включая интеграцию данных, предварительную обработку, развертывание моделей и мониторинг, или же вы просто используете клиенты Kafka для встраивания моделей в реальные клиент Time Kafka (который полностью отделен от предварительной обработки данных и обучения модели).
Существует две альтернативы для развертывания модели: серверы моделей (RPC) и встроенные модели. Понимание плюсов и минусов каждого подхода поможет вам принять правильное решение для вашего проекта. В действительности, встраивание аналитических моделей в приложения Kafka является простым и может быть очень полезным.