В этом уроке вы узнаете —
- Установка NLTK в Windows
- Установка Python в Windows
- Установка NLTK в Mac / Linux
- Установка НЛТК через Анаконду
- Набор данных NLTK
- Как скачать все пакеты НЛТК
- Запуск сценария НЛП
- Как запустить скрипт NLTK
Установка NLTK в Windows
В этой части мы узнаем, как выполнить настройку NLTK через терминал (командная строка в windows).
Инструкция, приведенная ниже, основана на предположении, что у вас не установлен Python. Итак, первый шаг — установить Python.
Установка Python в Windows:
Шаг 1) Перейдите по ссылке https://www.python.org/downloads/ , и выберите последнюю версию для окон.
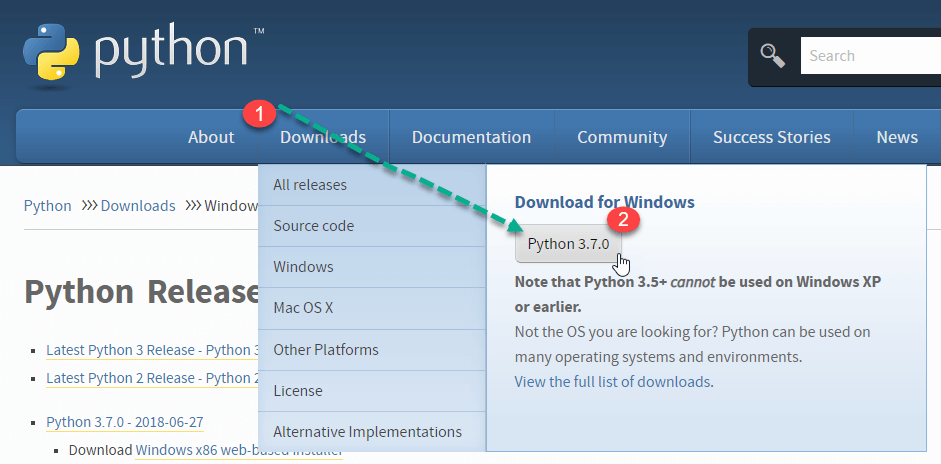
Примечание . Если вы не хотите загружать последнюю версию, вы можете посетить вкладку загрузки и просмотреть все выпуски.
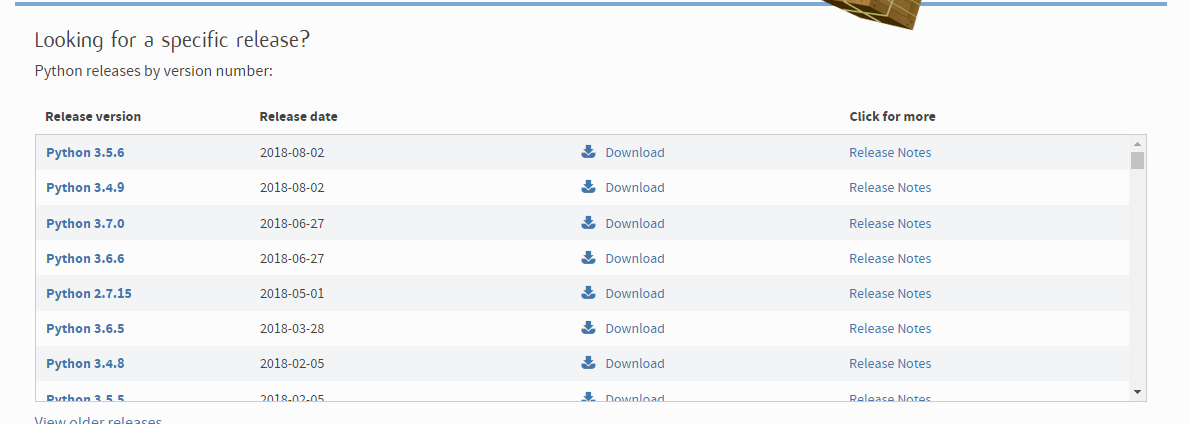
Шаг 2) Нажмите на загруженный файл

Шаг 3) Выберите «Настроить установку»
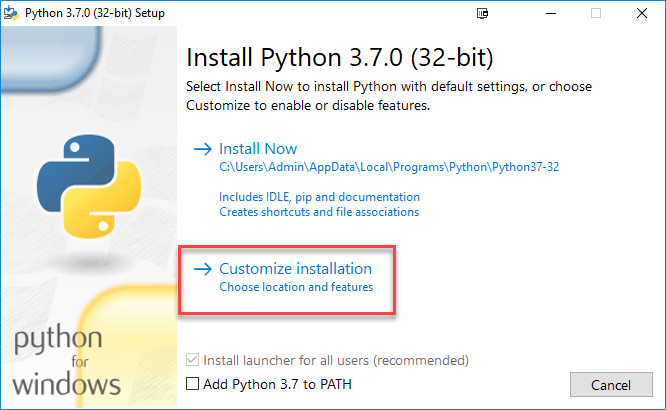
Шаг 4) Нажмите ДАЛЕЕ
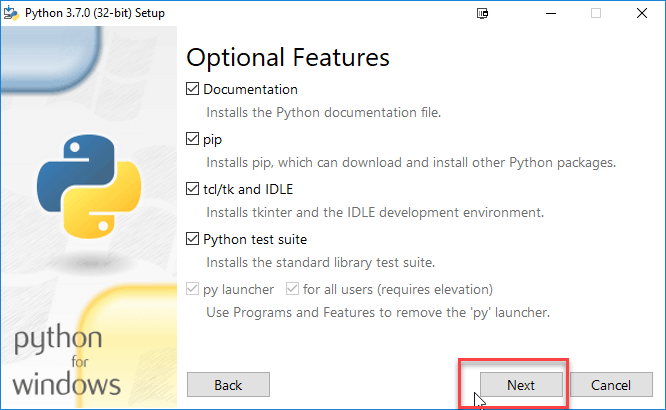
Шаг 5) На следующем экране
- Выберите дополнительные параметры
- Дайте выборочную установку. В моем случае папка на диске C выбрана для удобства работы
- Нажмите Установить
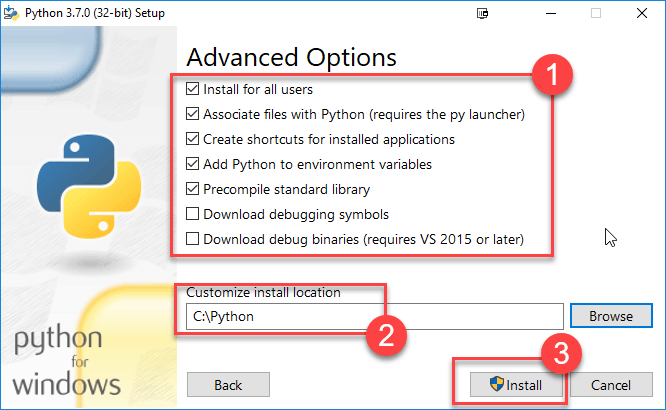
Шаг 6) Нажмите кнопку «Закрыть» после завершения установки.
Шаг 7) Скопируйте путь к вашей папке Scripts.

Шаг 8) В командной строке Windows
- Перейдите к местоположению папки pip
- Введите команду для установки NLTK
pip3 install nltk
- Установка должна быть выполнена успешно
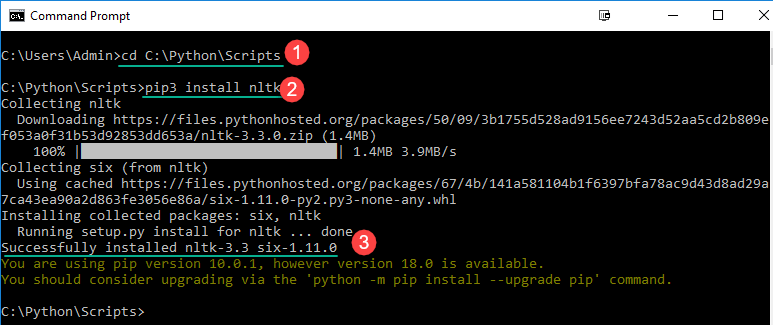
ПРИМЕЧАНИЕ : для Python2 используйте команду pip2 install nltk
Шаг 9) В меню «Пуск» Windows найдите и откройте PythonShell
Шаг 10) Вы можете проверить правильность установки, введя приведенную ниже команду
import nltk

Если вы не видите ошибки, установка завершена.
Установка NLTK в Mac / Linux
Установка NLTK в Mac / Unix требует pip менеджера пакетов python для установки nltk. Если пункт не установлен, пожалуйста, следуйте инструкциям ниже, чтобы завершить процесс
Шаг 1) Обновите индекс пакета, введя следующую команду
sudo apt update
Шаг 2) Установка pip для Python 3:
sudo apt install python3-pip
Вы также можете установить pip с помощью easy_install.
sudo apt-get install python-setuptools python-dev build-essential
Теперь easy_install установлен. Запустите приведенную ниже команду для установки pip
sudo easy_install pip
Шаг 3) Используйте следующую команду для установки NLTK
sudo pip install -U nltk sudo pip3 install -U nltk
Установка НЛТК через Анаконду
Шаг 1) Пожалуйста, установите anaconda (которая также может использоваться для установки различных пакетов), посетив https://www.anaconda.com/download/ и выберите, какую версию python вам нужно установить для anaconda.
Примечание. Обратитесь к этому руководству за подробными инструкциями по установке Anaconda.
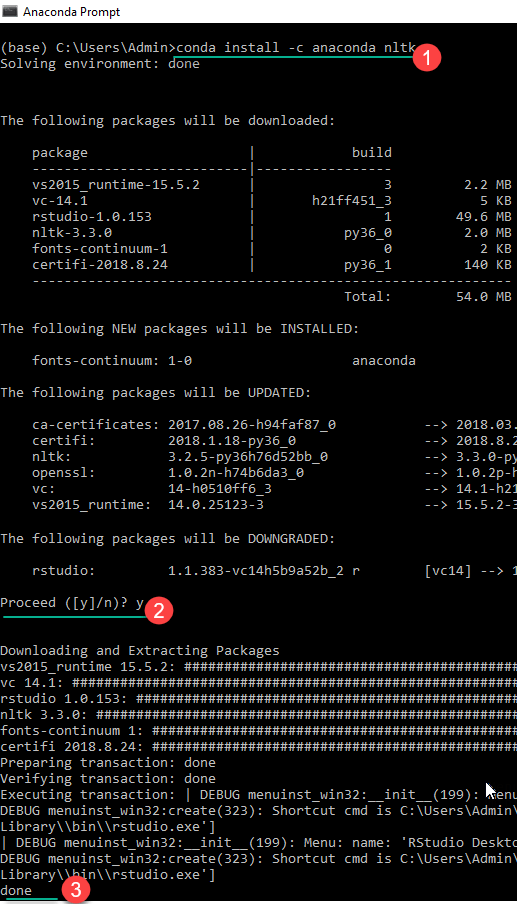
Шаг 2) В приглашении Anaconda
- Введите команду
conda install -c anaconda nltk
- Просмотрите обновление пакета, понизьте версию, установите информацию и введите yes
- NLTK загружен и установлен
Набор данных NLTK
Модуль NLTK имеет множество доступных наборов данных, которые необходимо загрузить для использования. Более технически это называется корпус . Некоторые из примеров игнорируемых слов , Гутенберг , framenet_v15 , large_grammars и так далее.
Как скачать все пакеты НЛТК
Шаг 1) Запустите интерпретатор Python в Windows или Linux
Шаг 2)
- Введите команды
import nltk nltk.download ()
- Открывается загруженное окно NLTK. Нажмите кнопку «Загрузить», чтобы загрузить набор данных. Этот процесс займет время, в зависимости от вашего интернет-соединения
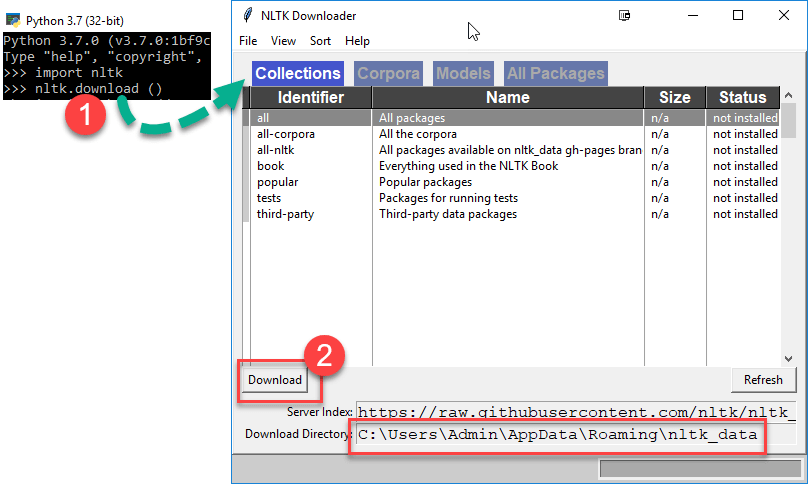
ПРИМЕЧАНИЕ. Вы можете изменить местоположение загрузки, нажав «Файл»> «Изменить каталог загрузки».

Шаг 3) Для проверки установленных данных используйте следующий код
>>> from nltk.corpus import brown >>>brown.words()
[‘The’, ‘Fulton’, ‘County’, ‘Grand’, ‘Jury’, ‘сказали’, …]

Запуск сценария НЛП
Мы собираемся обсудить, как скрипт NLP будет выполняться на нашем локальном ПК. На рынке представлено множество библиотек для обработки естественного языка. Поэтому выбор библиотеки зависит от ваших требований. Вот список библиотек НЛП .
Как запустить скрипт NLTK
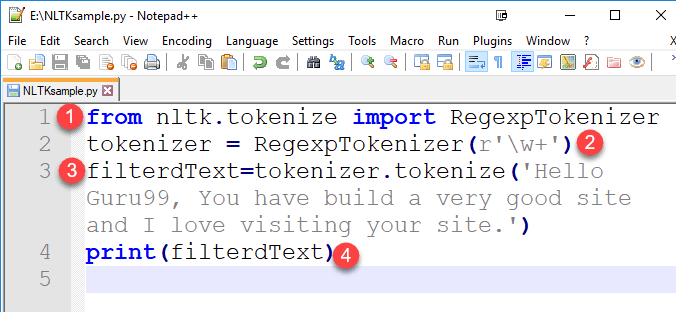
Шаг 1) В вашем любимом редакторе кода скопируйте код и сохраните файл как « NLTKsample.py »
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)
Объяснение кода:
- В этой программе целью было удалить все типы знаков препинания из данного текста. Мы импортировали «RegexpTokenizer», который является модулем NLTK. Он удаляет все выражения, символы, символы, цифры или все, что вы хотите.
- Вы только что передали регулярное выражение в модуль «RegexpTokenizer».
- Далее мы токенизировали слово с помощью модуля «токенизировать». Вывод сохраняется в переменной filterdText.
- И распечатал их, используя «print ()».
Шаг 2) В командной строке
- Перейдите к месту, где вы сохранили файл
- Запустите команду Python NLTKsample.py
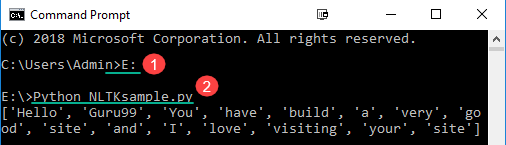
Это покажет вывод как:
[‘Hello’, ‘Guru99’, ‘You’, ‘have’, ‘build’, ‘a’, ‘very’, ‘good’, ‘site’, ‘and’, ‘I’, ‘love’, ‘ посещая ‘,’ ваш ‘,’ сайт ‘]