Что такое вложение слов?
Вложение слов — это тип представления слов, который позволяет алгоритмам машинного обучения понимать слова со схожим значением. Технически говоря, это отображение слов в векторы действительных чисел с использованием нейронной сети, вероятностной модели или сокращения размеров в матрице совпадений слов. Это языковое моделирование и методика обучения. Встраивание слов — это способ отображения с помощью нейронной сети. Доступны различные модели встраивания слов, такие как word2vec (Google), Glove (Stanford) и fasttest (Facebook).
Вложение слова также называется распределенной семантической моделью или распределенным представленным или семантическим векторным пространством или моделью векторного пространства. Когда вы читаете эти имена, вы сталкиваетесь со словом semantic, которое означает категоризацию похожих слов. Например, фрукты, такие как яблоко, манго, банан, должны быть расположены близко, тогда как книги будут находиться далеко от этих слов. В более широком смысле, встраивание слов создаст вектор фруктов, который будет расположен далеко от векторного представления книг.
В этом уроке вы узнаете
- Что такое вложение слов?
- Где используется Word Embedding?
- Что такое word2vec?
- Что делает word2vec?
- Почему Word2vec?
- Word2vec Архитектура
- Непрерывная сумка слов.
- Модель Skip-Gram
- Связь между Word2vec и NLTK
- Активаторы и Word2Vec
- Что такое Генсим?
- Реализация кода word2vec с использованием Gensim
Где используется Word Embedding?
Встраивание слов помогает в создании функций, кластеризации документов, классификации текста и задачах обработки естественного языка. Давайте перечислим их и обсудим каждое из этих приложений.
- Вычислить похожие слова: Вложение слова используется для предложения слов, похожих на слово, которое подвергается модели прогнозирования. Наряду с этим он также предлагает разные слова, а также наиболее распространенные слова.
- Создайте группу связанных слов: она используется для семантической группировки, которая группирует вещи с одинаковыми характеристиками вместе и разнородно далеко.
- Функция для классификации текста: текст сопоставляется с массивами векторов, которые передаются в модель для обучения и прогнозирования. Текстовые модели классификаторов не могут быть обучены на строке, поэтому это преобразует текст в обучаемую машиной форму. Далее его особенности построения семантической помощи в текстовой классификации.
- Кластеризация документов — еще одно приложение, в котором широко используется встраивание слов.
- Обработка естественного языка. Существует много приложений, в которых встраивание слов полезно и выигрывает на этапах извлечения признаков, таких как теги речи, сентиментальный анализ и синтаксический анализ.
Теперь у нас есть некоторые знания о встраивании слов. Некоторый свет также проливается на различные модели для реализации встраивания слов. Весь этот учебник ориентирован на одну из моделей (word2vec).
Что такое word2vec?
Word2vec — это методика / модель для встраивания слов для лучшего представления слов. Он фиксирует большое количество точных синтаксических и семантических словосочетаний. Это мелкая двухслойная нейронная сеть. Прежде чем идти дальше, просмотрите разницу между мелкой и глубокой нейронной сетью:
Мелкая нейронная сеть состоит из единственного скрытого слоя между входом и выходом, тогда как глубокая нейронная сеть содержит несколько скрытых слоев между входом и выходом. Вход подвергается узлам, тогда как скрытый слой, как и выходной слой, содержит нейроны.
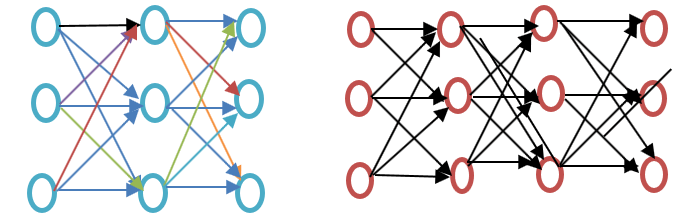
Рисунок: неглубокое и глубокое обучение
word2vec is a two-layer network where there is input one hidden layer and output.
Word2vec was developed by a group of researcher headed by Tomas Mikolov at Google. Word2vec is better and more efficient that latent semantic analysis model.
What word2vec does?
Word2vec represents words in vector space representation. Words are represented in the form of vectors and placement is done in such a way that similar meaning words appear together and dissimilar words are located far away. This is also termed as a semantic relationship. Neural networks do not understand text instead they understand only numbers. Word Embedding provides a way to convert text to a numeric vector.
Word2vec reconstructs the linguistic context of words. Before going further let us understand, what is linguistic context? In general life scenario when we speak or write to communicate, other people try to figure out what is objective of the sentence. For example, «What is the temperature of India», here the context is the user wants to know «temperature of India» which is context. In short, the main objective of a sentence is context. Word or sentence surrounding spoken or written language (disclosure) helps in determining the meaning of context. Word2vec learns vector representation of words through the contexts.
Why Word2vec?
Before Word Embedding
It is important to know which approach is used before word embedding and what are its demerits and then we will move to the topic of how demerits are overcome by Word embedding using word2vec approach. Finally, we will move how word2vec works because it is important to understand it’s working.
Approach for Latent Semantic Analysis
This is the approach which was used before word embedding. It used the concept of Bag of words where words are represented in the form of encoded vectors. It is a sparse vector representation where the dimension is equal to the size of vocabulary. If the word occurs in the dictionary, it is counted, else not. To understand more, please see the below program.
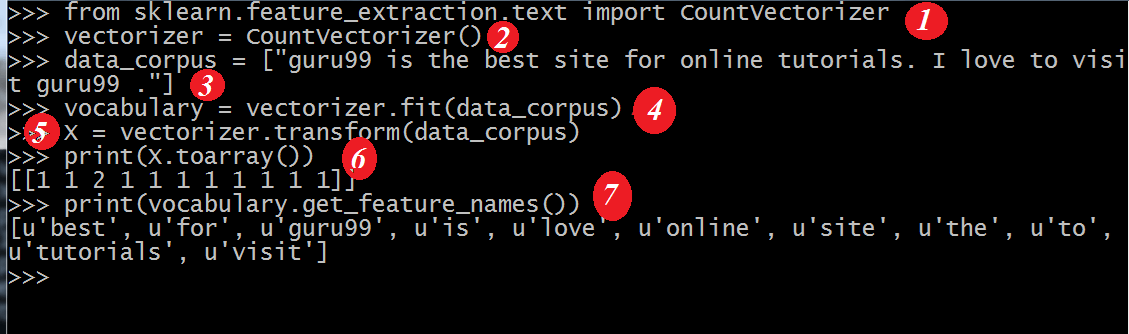
from sklearn.feature_extraction.text import CountVectorizer vectorizer=CountVectorizer() data_corpus=["guru99 is the best sitefor online tutorials. I love to visit guru99."] vocabulary=vectorizer.fit(data_corpus) X= vectorizer.transform(data_corpus) print(X.toarray()) print(vocabulary.get_feature_names())
Output:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Explanation
- CountVectorizer is the module which is used to store the vocabulary based on fitting the words in it. This is imported from the sklearn
- Make the object using the class CountVectorizer.
- Write the data in the list which is to be fitted in the CountVectorizer.
- Data is fit in the object created from the class CountVectorizer.
- Apply a bag of word approach to count words in the data using vocabulary. If word or token is not available in the vocabulary, then such index position is set to zero.
- Variable in line 5 which is x is converted to an array (method available for x). This will provide the count of each token in the sentence or list provided in Line 3.
- This will show the features which are part of the vocabulary when it is fitted using the data in Line 4.
In Latent Semantic approach, the row represents unique words whereas the column represents the number of time that word appears in the document. It is a representation of words in the form of the document matrix. Term-Frequency inverse document frequency (TFIDF) is used to count the frequency of words in the document which is the frequency of the term in the document/ frequency of the term in the entire corpus.
Shortcoming of Bag of Words method
- It ignores the order of the word, for example, this is bad = bad is this.
- Он игнорирует контекст слов. Предположим, если я напишу предложение «Он любил книги. Образование лучше всего найти в книгах». Это создаст два вектора: «Он любил книги», а другой — «Образование лучше всего найти в книгах». Это будет относиться к обоим из них ортогонально, что делает их независимыми, но в действительности они связаны друг с другом
Чтобы преодолеть эти ограничения, было разработано встраивание слов, и word2vec — это подход для их реализации.
Как работает Word2vec?
Word2vec изучает слово, предсказывая его окружающий контекст. Например, давайте возьмем слово «Он любит футбол».
Мы хотим вычислить word2vec для слова: любит.
предполагать
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Слово любит движется над каждым словом в корпусе. Синтаксические и семантические отношения между словами закодированы. Это помогает в поиске похожих и аналогичных слов.
Все случайные черты слова любит вычисляется. Эти функции изменяются или обновляются в отношении соседних или контекстных слов с помощью метода обратного распространения.
Другой способ изучения заключается в том, что если контекст двух слов похож или два слова имеют сходные черты, то такие слова связаны между собой.
Word2vec Архитектура
Word2vec использует две архитектуры
- Непрерывная сумка слов (CBOW)
- пропустить грамм
Прежде чем идти дальше, давайте обсудим, почему эти архитектуры или модели важны с точки зрения представления слов. Изучение представления слов по существу не контролируется, но цели / метки необходимы для обучения модели. Skip-грамма и CBOW преобразуют неконтролируемое представление в контролируемую форму для обучения модели.
В CBOW текущее слово прогнозируется с использованием окна окружающих контекстных окон. Например, если w i-1 , w i-2 , w i + 1 , w i + 2 — слова или контекст, эта модель будет предоставлять w i
Skip-Gram выполняет противоположность CBOW, что подразумевает, что он предсказывает данную последовательность или контекст из слова. Вы можете изменить пример, чтобы понять это. Если задано w i , это будет предсказывать контекст или w i-1 , w i-2 , w i + 1 , w i + 2.
Word2vec предоставляет возможность выбора между CBOW (непрерывный пакет слов) и ским-граммой. Такие параметры предоставляются при обучении модели. Можно иметь возможность использовать отрицательную выборку или иерархический слой softmax.
Непрерывная сумка слов.
Давайте нарисуем простую диаграмму, чтобы понять непрерывный пакет слов архитектуры.
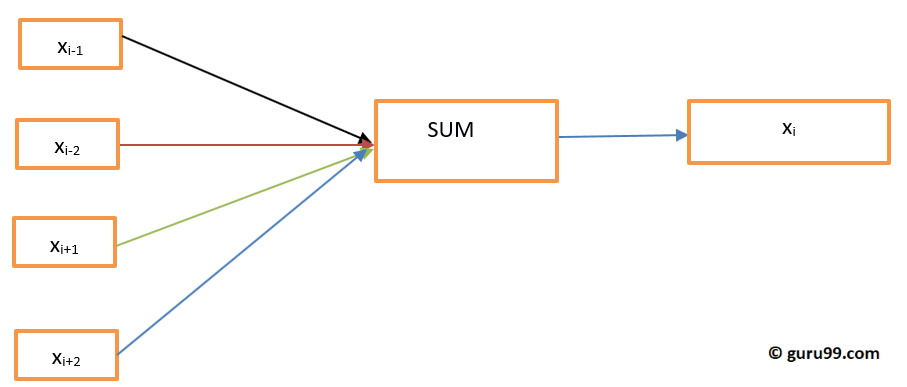
Рисунок Непрерывный Мешок Слова Архитектура
Давайте вычислим уравнения математически. Предположим, что V — это размер словаря, а N — размер скрытого слоя. Ввод определяется как {x i-1 , x i-2, x i + 1, x i + 2 }. Мы получаем весовую матрицу умножением V * N. Другая матрица получается умножением входного вектора на весовую матрицу. Это также можно понять с помощью следующего уравнения.
h = xi t W
где xi t ∧ W — входной вектор и весовая матрица соответственно,
Чтобы вычислить соответствие между контекстом и следующим словом, пожалуйста, обратитесь к уравнению ниже
и = predictedrepresentation * ч
где прогнозируемое представление получается модель∧h в приведенном выше уравнении.
Модель Skip-Gram
Подход Skip-Gram используется для прогнозирования предложения по вводимому слову. Чтобы лучше это понять, давайте нарисуем диаграмму.
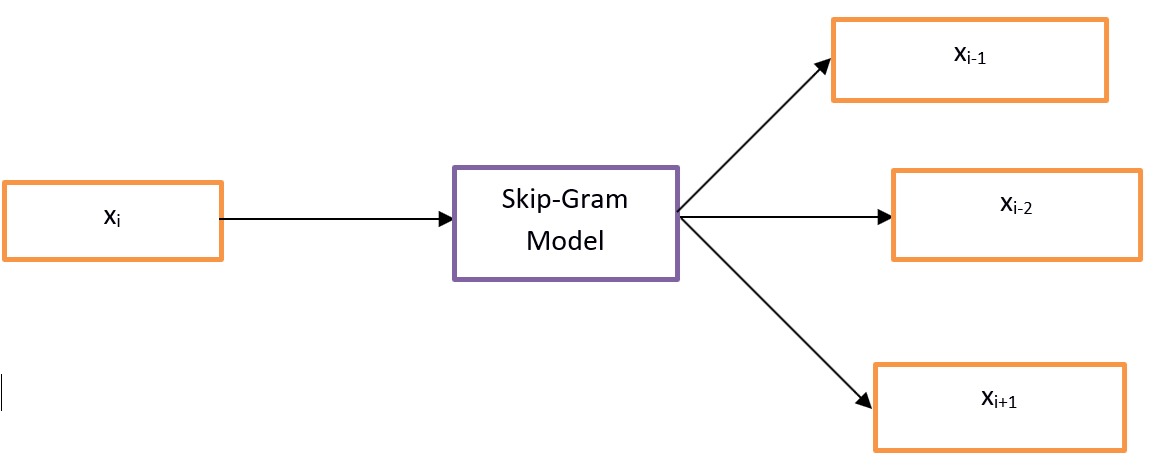
Модель Skip-Gram
Можно рассматривать это как обратную модель непрерывного пакета слов, где вводом является слово, а модель обеспечивает контекст или последовательность. Мы также можем сделать вывод, что цель подается на входной и выходной слой, который повторяется несколько раз, чтобы вместить выбранное количество контекстных слов. Вектор ошибок со всего выходного слоя суммируется для корректировки весов методом обратного распространения.
Какую модель выбрать?
CBOW в несколько раз быстрее, чем пропуск грамма, и обеспечивает более высокую частоту для часто употребляемых слов, тогда как пропуск грамма требует небольшого количества обучающих данных и представляет даже редкие слова или фразы.
Связь между Word2vec и NLTK
NLTK — это инструментарий естественного языка. Используется для предварительной обработки текста. Можно выполнять различные операции, такие как пометки речевых тегов, лемматизирование, определение текста, удаление стоп-слов, удаление редких или наименее используемых слов. Это помогает в очистке текста, а также помогает в подготовке функций из эффективных слов. С другой стороны, word2vec используется для семантического (тесно связанных между собой элементов) и синтаксического (последовательности) сопоставления. Используя word2vec, можно найти похожие слова, разнородные слова, сокращение размеров и многие другие. Еще одной важной особенностью word2vec является преобразование более высокого размерного представления текста в более низкое размерное векторов.
Где использовать NLTK и Word2vec?
Если необходимо выполнить некоторые задачи общего назначения, как упомянуто выше, такие как токенизация, пометка POS и разбор, необходимо использовать NLTK, тогда как для прогнозирования слов в соответствии с некоторым контекстом, моделирования темы или сходства документов необходимо использовать Word2vec.
Связь NLTK и Word2vec с помощью кода
NLTK и Word2vec могут использоваться вместе, чтобы найти похожее представление слов или синтаксическое соответствие. Инструментарий NLTK можно использовать для загрузки многих пакетов, которые поставляются с NLTK, а модель можно создавать с помощью word2vec. Затем можно проверить слова в реальном времени. Давайте посмотрим на комбинацию обоих в следующем коде. Перед дальнейшей обработкой, пожалуйста, посмотрите на корпусы, которые предоставляет NLTK. Вы можете скачать с помощью командыnltk(nltk.download('all'))

Рисунок Корпора скачан с использованием NLTK
Пожалуйста, смотрите скриншот для кода.
import nltk
import gensim
from nltk.corpus import abc
model= gensim.models.Word2Vec(abc.sents())
X= list(model.wv.vocab)
data=model.most_similar('science')
print(data)

Вывод:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Объяснение кода
- Импортируется библиотека nltk, откуда вы можете скачать корпус abc, который мы будем использовать на следующем шаге.
- Генсим импортируется. Если Gensim не установлен, пожалуйста, установите его с помощью команды «pip3 install gensim». Пожалуйста, смотрите скриншот ниже.

Рисунок Установка Gensim с использованием PIP
- импортировать корпус abc, который был загружен с помощью nltk.download (‘abc’).
- Передайте файлы модели word2vec, которая импортируется с использованием Gensim в качестве предложений.
- Словарь хранится в виде переменной.
- Модель проверена на примере слова науки, так как эти файлы связаны с наукой.
- Здесь подобное слово «наука» предсказывается моделью.
Активаторы и Word2Vec
Функция активации нейрона определяет выход этого нейрона с учетом набора входов. Биологически вдохновлен деятельностью в нашем мозге, где разные нейроны активируются с помощью разных стимулов. Давайте разберемся с функцией активации через следующую диаграмму.
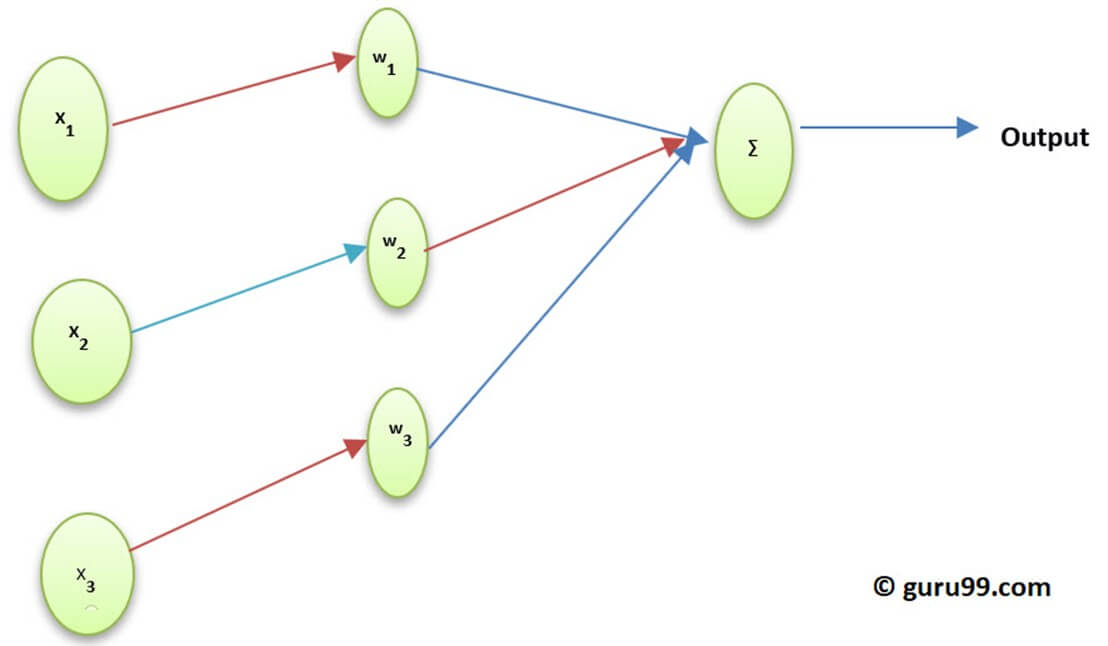
Рисунок Понимание функции активации
Здесь x1, x2, .. x4 — узел нейронной сети.
w1, w2, w3 — вес узла,
∑ — сумма всех весов и значений узлов, которые работают как функция активации.
Почему функция активации?
Если функция активации не используется, выход будет линейным, но функциональность линейной функции ограничена. Для достижения сложной функциональности, такой как обнаружение объекта, классификация изображений, ввод текста с использованием голоса и многие другие нелинейные выходные данные, что достигается с помощью функции активации.
Как слой активации вычисляется при встраивании слова (word2vec)
Softmax Layer (нормализованная экспоненциальная функция) — это функция выходного слоя, которая активирует или запускает каждый узел. Другой используемый подход — это иерархический softmax, где сложность вычисляется как O (log 2 V), где softmax — это O (V), где V — размер словаря. Разница между ними заключается в уменьшении сложности в иерархическом слое softmax. Чтобы понять его (иерархическую функциональность Softmax), пожалуйста, посмотрите на приведенный ниже пример:
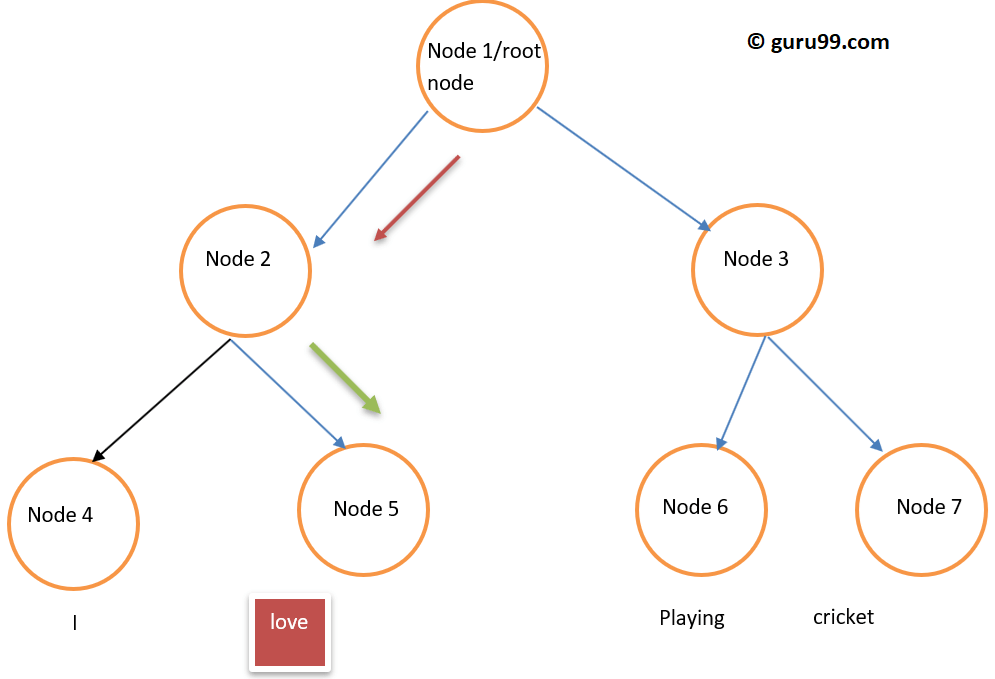
Рисунок Иерархическая структура softmax в виде дерева
Предположим, мы хотим вычислить вероятность соблюдения слова « любовь» в определенном контексте. Поток от корневого узла к конечному узлу будет первым переходом к узлу 2, а затем к узлу 5. Таким образом, если у нас был размер словаря, равный 8, потребуются только три вычисления. Так что это позволяет разложить, вычислить вероятность одного слова ( любовь ).
Какие другие опции доступны кроме Иерархического Softmax?
Если говорить в общем смысле для вариантов встраивания слов, доступны: Дифференцированный Softmax, CNN-Softmax, Выборка по важности, Выборка по адаптивной важности, Оценки с контрастом по шуму, Отрицательная выборка, Самонормализация и нечастая нормализация.
Говоря конкретно о Word2vec, мы имеем негативную выборку.
Отрицательная выборка — это способ выборки обучающих данных. Это что-то вроде стохастического градиентного спуска, но с некоторой разницей. Отрицательная выборка ищет только отрицательные обучающие примеры. Он основан на контрастной оценке шума и случайных выборок слов, а не в контексте. Это быстрый метод обучения и случайный выбор контекста. Если предсказанное слово появляется в случайно выбранном контексте, оба вектора близки друг к другу.
Какой вывод можно сделать?
Активаторы запускают нейроны так же, как наши нейроны запускаются с помощью внешних раздражителей. Слой Softmax является одной из функций выходного слоя, которая запускает нейроны в случае встраивания слов. В word2vec у нас есть такие опции, как иерархический softmax и отрицательная выборка. Используя активаторы, можно преобразовать линейную функцию в нелинейную функцию, и с ее помощью можно реализовать сложный алгоритм машинного обучения.
Что такое Генсим?
Gensim — это инструмент для моделирования тем, который реализован на python. Моделирование темы — это обнаружение скрытой структуры в теле текста. Word2vec импортируется из инструментария Gensim. Обратите внимание, что Gensim предоставляет не только реализацию word2vec, но также Doc2vec и FastText, но этот урок посвящен word2vec, поэтому мы будем придерживаться текущей темы.
Реализация word2vec с использованием Gensim
До сих пор мы обсуждали, что такое word2vec, его различные архитектуры, почему происходит переход от пакета слов к word2vec, отношения между word2vec и NLTK с живым кодом и функциями активации. В этом разделе будет реализован Word2vec с использованием Gensim
Шаг 1) Сбор данных
Первым этапом реализации любой модели машинного обучения или обработки естественного языка является сбор данных.
Пожалуйста, ознакомьтесь с данными для создания интеллектуального чат-бота.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here"," Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", " Can I pay using Mastercard?", " Can I pay using cash only?" ],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don’t worry"]
}
]
Вот что мы понимаем из данных
- Эти данные содержат три вещи: тег, шаблон и ответы. Тег является намерением (что является темой обсуждения).
- Данные в формате JSON.
- Шаблон — это вопрос, который пользователи задают боту.
- Ответы — это ответ, который чатбот предоставит на соответствующий вопрос / шаблон.
Шаг 2) Предварительная обработка данных.
Очень важно обрабатывать необработанные данные. Если очищенные данные поступают на машину, то модель будет реагировать более точно и более эффективно изучать данные.
Этот шаг включает в себя удаление стоп-слов, стволовых, ненужных слов и т. Д. Прежде чем продолжить, важно загрузить данные и преобразовать их в фрейм данных. Пожалуйста, смотрите код ниже для таких
import json
json_file =’intents.json'
with open('intents.json','r') as f:
data = json.load(f)
Объяснение КОДА.
- Поскольку данные представлены в формате json, следовательно, json импортируется
- Файл хранится в переменной
- Файл открыт и загружен в переменную данных
Теперь данные импортируются, и пришло время преобразовать данные во фрейм данных. Пожалуйста, смотрите код ниже, чтобы увидеть следующий шаг
import pandas as pd
df = pd.DataFrame(data)
df['patterns'] = df['patterns'].apply(', '.join)
Объяснение КОДА
1. Данные преобразуются во фрейм данных с использованием панд, которые были импортированы выше.
2. Он преобразует список в шаблонах столбцов в строку.
from nltk.corpus import stopwords
from textblob import Word
stop = stopwords.words('english')
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x.lower() for x in x.split()))
df['patterns't']= df['patterns''].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)
df['patterns']= df['patterns'].str.replace('[^\w\s]','')
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit()))
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x for x in x.split() if not x in stop))
df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Код Объяснение
1. Английские стоп-слова импортируются с использованием модуля стоп-слов из набора инструментов nltk
2. Все слова текста преобразуются в нижний регистр с использованием для условия и лямбда-функции. Лямбда-функция является анонимной функцией.
3. Все строки текста во фрейме данных проверяются на пунктуацию строк, и они фильтруются.
4. Такие символы, как цифры или точки, удаляются с помощью регулярного выражения.
5. Цифры удалены из текста.
6. Стоп-слова на этом этапе удаляются.
7. Слова теперь фильтруются, и разные формы одного и того же слова удаляются с помощью лемматизации. На этом мы завершили предварительную обработку данных.
Вывод:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please don’t worry']",payments
Шаг 3) Построение нейронной сети с использованием word2vec
Теперь пришло время построить модель, используя модуль Gensim word2vec. Мы должны импортировать word2vec из Gensim. Давайте сделаем это, а затем построим и на последнем этапе проверим модель на данных в реальном времени.
from gensim.models import Word2Vec
Теперь мы можем успешно построить модель, используя Word2Vec. Пожалуйста, обратитесь к следующей строке кода, чтобы узнать, как создать модель с помощью Word2Vec. Текст предоставляется модели в виде списка, поэтому мы преобразуем текст из фрейма данных в список, используя приведенный ниже код
Bigger_list=[]
for i in df['patterns']
li = list(i.split(""))
Bigger_list.append(li)
Model= Word2Vec(Bigger_list,min_count=1,size=300,workers=4)
Пояснения к коду
1. Создан больший_список, к которому добавляется внутренний список. Это формат, который подается на модель Word2Vec.
2. Цикл реализован, и каждая запись столбца шаблонов фрейма данных повторяется.
3. Каждый элемент шаблонов столбцов разделяется и сохраняется во внутреннем списке.
4. Внутренний список дополняется внешним списком.
5. Этот список предоставляется модели Word2Vec. Давайте разберемся с некоторыми из приведенных здесь параметров
Min_count: он будет игнорировать все слова с общей частотой ниже, чем эта.
Размер: говорит о размерности векторов слова.
Рабочие: это темы для обучения модели
Есть также другие доступные варианты, и некоторые важные объяснены ниже
Окно: Максимальное расстояние между текущим и прогнозируемым словом в предложении.
Sg: Это тренировочный алгоритм и 1 для скип-граммы и 0 для непрерывного пакета слов. Мы обсудили это подробно выше.
Hs: если это 1, то мы используем иерархический softmax для обучения, а если 0, то используется отрицательная выборка.
Альфа: начальная скорость обучения
Давайте покажем окончательный код ниже
#list of libraries used by the code
import string
from gensim.models import Word2Vec
import logging
from nltk.corpus import stopwords
from textblob import Word
import json
import pandas as pd
#data in json format
json_file = 'intents.json'
with open('intents.json','r') as f:
data = json.load(f)
#displaying the list of stopwords
stop = stopwords.words('english')
#dataframe
df = pd.DataFrame(data)
df['patterns'] = df['patterns'].apply(', '.join)
# print(df['patterns'])
#print(df['patterns'])
#cleaning the data using the NLP approach
print(df)
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x.lower() for x in x.split()))
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation))
df['patterns']= df['patterns'].str.replace('[^\w\s]','')
df['patterns']= df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit()))
df['patterns'] = df['patterns'].apply(lambda x:' '.join(x for x in x.split() if not x in stop))
df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
#taking the outer list
bigger_list=[]
for i in df['patterns']:
li = list(i.split(" "))
bigger_list.append(li)
#structure of data to be taken by the model.word2vec
print("Data format for the overall list:",bigger_list)
#custom data is fed to machine for further processing
model = Word2Vec(bigger_list, min_count=1,size=300,workers=4)
#print(model)
Шаг 4) Сохранение модели
Модель может быть сохранена в виде корзины и формы модели. Бин это двоичный формат. Пожалуйста, смотрите строки ниже, чтобы сохранить модель
model.save("word2vec.model")
model.save("model.bin")
Объяснение приведенного выше кода
1. Модель сохраняется в виде файла .model.
2. модель сохраняется в виде файла .bin
Мы будем использовать эту модель для тестирования в реальном времени, таких как похожие слова, разнородные слова и наиболее распространенные слова.
Шаг 5) Загрузка модели и выполнение тестирования в реальном времени
Модель загружается с использованием кода ниже
model = Word2Vec.load('model.bin')
Если вы хотите вывести из него словарь, выполните команду ниже
Пожалуйста, посмотрите результат
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Шаг 6) Проверка большинства похожих слов
Давайте реализовывать вещи практически
similar_words = model.most_similar('thanks')
print(similar_words)
Пожалуйста, посмотрите результат
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Шаг 7) Не совпадает слово из поставленных слов
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split())
print(dissimlar_words)
Мы предоставили слова «Увидимся позже, спасибо за посещение». Это напечатает самые разные слова из этих слов. Давайте запустим этот код и найдем результат
Результат после выполнения приведенного выше кода.
Thanks
Шаг 8) Нахождение сходства между двумя словами
Это скажет результат в вероятности подобия между двумя словами. Пожалуйста, посмотрите код ниже, как выполнить этот раздел.
similarity_two_words = model.similarity('please','see')
print("Please provide the similarity between these two words:")
print(similarity_two_words)
Результат приведенного выше кода, как показано ниже
0,13706
Вы также можете найти похожие слова, выполнив приведенный ниже код
similar = model.similar_by_word('kind')
print(similar)
Вывод вышеуказанного кода
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]
Вывод
- Вложение слов — это тип представления слов, который позволяет алгоритмам машинного обучения понимать слова со схожим значением.
- Вложение слов используется для вычисления похожих слов, создания группы связанных слов, функции для классификации текста, кластеризации документов, обработки естественного языка
- Word2vec является мелкой двухслойной моделью нейронной сети, обеспечивающей встраивание слов для лучшего представления слов
- Word2vec представляет слова в представлении векторного пространства. Слова представлены в виде векторов, а размещение выполняется таким образом, что слова одинакового значения появляются вместе, а разнородные слова расположены далеко.
- Word2vec использовал 2 архитектуры Continuous Bag of words (CBOW) и пропускал грамм
- CBOW в несколько раз быстрее, чем пропуск грамма, и обеспечивает более высокую частоту для часто употребляемых слов, тогда как пропуск грамма требует небольшого количества обучающих данных и представляет даже редкие слова или фразы.
- NLTK и word2vec могут использоваться вместе для создания мощных приложений
- Функция активации нейрона определяет выход этого нейрона с учетом набора входов. В word2vec. Softmax Layer (нормализованная экспоненциальная функция) — это функция выходного слоя, которая активирует или запускает каждый узел. Word2vec также имеет отрицательную выборку
- Gensim — это инструмент для моделирования тем, который реализован на python