СЧЕТЫ POS
Мы обсудили различные pos_tag в предыдущем разделе. В этом конкретном руководстве вы узнаете, как считать эти теги. Подсчет тегов имеет решающее значение для классификации текста, а также для подготовки функций для операций на естественном языке. Я буду обсуждать с вами подход, которому следовал guru99 при подготовке кода, а также обсуждение результатов. Надеюсь, что это поможет вам.
Как считать Теги:
Здесь мы сначала напишем рабочий код, а затем напишем различные шаги для объяснения кода.
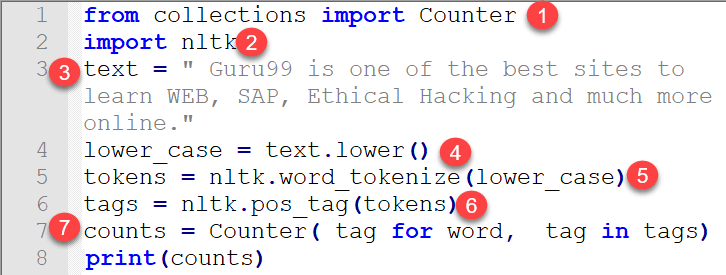
from collections import Counter import nltk text = " Guru99 is one of the best sites to learn WEB, SAP, Ethical Hacking and much more online." lower_case = text.lower() tokens = nltk.word_tokenize(lower_case) tags = nltk.pos_tag(tokens) counts = Counter( tag for word, tag in tags) print(counts)
Вывод:
Счетчик ({‘NN’: 5, ‘,’: 2, ‘TO’: 1, ‘CC’: 1, ‘VBZ’: 1, ‘NNS’: 1, ‘CD’: 1, ‘.’: 1 , ‘DT’: 1, ‘JJS’: 1, ‘JJ’: 1, ‘JJR’: 1, ‘IN’: 1, ‘VB’: 1, ‘RB’: 1})
Разработка кода
- Для подсчета тегов вы можете использовать пакет Counter из модуля коллекции. Счетчик — это подкласс словаря, который работает по принципу работы значения ключа. Это неупорядоченная коллекция, в которой элементы хранятся в виде словарного ключа, а их значение равно количеству.
- Импортируйте nltk, который содержит модули для токенизации текста.
- Напишите текст, чей pos_tag вы хотите посчитать.
- Некоторые слова в верхнем регистре, а некоторые в нижнем регистре, поэтому целесообразно преобразовать все слова в нижний регистр перед применением токенизации.
- Передайте слова через word_tokenize из nltk.
- Рассчитать pos_tag каждого токена
Output = [('guru99', 'NN'), ('is', 'VBZ'), ('one', 'CD'), ('of', 'IN'), ('the', 'DT'), ('best', 'JJS'), ('site', 'NN'), ('to', 'TO'), ('learn', 'VB'), ('web', 'NN'), (',', ','), ('sap', 'NN'), (',', ','), ('ethical', 'JJ'), ('hacking', 'NN'), ('and', 'CC'), ('much', 'RB'), ('more', 'JJR'), ('online', 'JJ')] - Теперь приходит роль счетчика словаря. Мы импортировали в строке кода 1. Слова — это ключ, а теги — это значение, а счетчик будет подсчитывать общее количество тегов, присутствующих в тексте.
Распределение частоты
Распределение частот называется количеством раз, когда происходит результат эксперимента. Он используется для определения частоты каждого слова, встречающегося в документе. Он использует FreqDistclass и определяется модулем nltk.probabilty .
Распределение частот обычно создается путем подсчета выборок при повторном запуске эксперимента. Количество отсчетов увеличивается на единицу каждый раз. Например
freq_dist = FreqDist ()
для токена в документе:
freq_dist.inc (token.type ())
Для любого слова мы можем проверить, сколько раз это произошло в конкретном документе. Например
- Метод подсчета : freq_dist.count (‘and’) Это выражение возвращает значение числа раз ‘и’ произошло. Это называется методом подсчета.
- Frequency Method: freq_dist.freq (‘and’) Это выражение возвращает частоту данного сэмпла.
Мы напишем небольшую программу и подробно расскажем о ее работе. Мы напишем некоторый текст и рассчитаем распределение частот каждого слова в тексте.
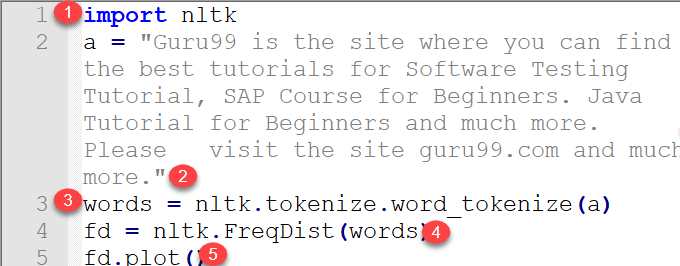
import nltk a = "Guru99 is the site where you can find the best tutorials for Software Testing Tutorial, SAP Course for Beginners. Java Tutorial for Beginners and much more. Please visit the site guru99.com and much more." words = nltk.tokenize.word_tokenize(a) fd = nltk.FreqDist(words) fd.plot()
Объяснение кода:
- Импортировать модуль nltk.
- Напишите текст, распределение слов которого вам нужно найти.
- Токенизируйте каждое слово в тексте, которое служит входом для модуля FreqDist nltk.
- Примените каждое слово к nlk.FreqDist в форме списка
- Нарисуйте слова на графике с помощью plot ()
Пожалуйста, визуализируйте график для лучшего понимания написанного текста
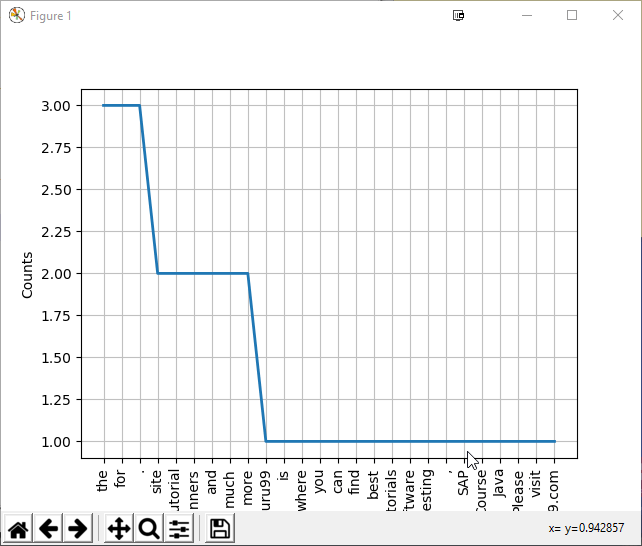
Распределение частот каждого слова в графе
ПРИМЕЧАНИЕ: вам нужно установить matplotlib, чтобы увидеть график выше.
Обратите внимание на график выше. Это соответствует подсчету вхождения каждого слова в тексте. Это помогает в изучении текста и в дальнейшем в реализации текстового сентиментального анализа. В двух словах, можно сделать вывод, что в nltk есть модуль для подсчета вхождения каждого слова в тексте, который помогает в подготовке статистики характеристик естественного языка. Он играет значительную роль в поиске ключевых слов в тексте. Вы также можете извлечь текст из PDF-файла, используя такие библиотеки, как extract, PyPDF2 и передать текст в nlk.FreqDist.
Ключевой термин «токенизировать». После токенизации он проверяет каждое слово в данном абзаце или текстовом документе, чтобы определить, сколько раз оно встречалось. Для этого вам не нужен инструментарий NLTK. Вы также можете сделать это с помощью своих собственных навыков программирования на Python. Инструментарий NLTK предоставляет только готовый код для различных операций.
Подсчет каждого слова может быть не очень полезным. Вместо этого следует сосредоточиться на словосочетании и биграммах, которые имеют дело с большим количеством слов в паре. Эти пары определяют полезные ключевые слова для улучшения характеристик естественного языка, которые можно подавать на машину. Пожалуйста, посмотрите ниже их детали.
Коллокации: биграммы и триграммы
Что такое коллокации?
Коллокации — это пары слов, встречающиеся в документе много раз. Он рассчитывается по количеству этих пар, встречающихся вместе, по общему количеству слов в документе.
Рассмотрим электромагнитный спектр с такими словами, как ультрафиолетовые лучи, инфракрасные лучи.
Слова ультрафиолет и лучи не используются по отдельности и, следовательно, могут рассматриваться как словосочетание. Другим примером является КТ. Мы не говорим CT и Scan отдельно, и, следовательно, они также рассматриваются как словосочетание.
Можно сказать, что нахождение словосочетаний требует вычисления частот слов и их появления в контексте других слов. Эти конкретные наборы слов требуют фильтрации, чтобы сохранить полезные термины содержания. Каждый грамм слов может быть затем оценен в соответствии с некоторой мерой ассоциации, чтобы определить относительную вероятность того, что каждая Инграм является коллокацией.
Коллокация может быть разделена на два типа:
- Биграммы c сочетанием двух слов
- Сочетание триграмм трех слов
Биграммы и триграммы предоставляют более значимые и полезные функции для этапа извлечения функций. Это особенно полезно в текстовом сентиментальном анализе.
Пример кода Bigrams
import nltk text = "Guru99 is a totally new kind of learning experience." Tokens = nltk.word_tokenize(text) output = list(nltk.bigrams(Tokens)) print(output)
Вывод
[('Guru99', 'is'), ('is', 'totally'), ('totally', 'new'), ('new', 'kind'), ('kind', 'of'), ('of', 'learning'), ('learning', 'experience'), ('experience', '.')]
Пример кода Trigrams
Иногда становится важным увидеть пару слов в предложении для статистического анализа и подсчета частоты. Это опять-таки играет решающую роль в формировании НЛП (функции обработки естественного языка), а также в текстовом сентиментальном прогнозировании.
Тот же код запускается для расчета триграмм.
import nltk text = “Guru99 is a totally new kind of learning experience.” Tokens = nltk.word_tokenize(text) output = list(nltk.trigrams(Tokens)) print(output)
Вывод
[('Guru99', 'is', 'totally'), ('is', 'totally', 'new'), ('totally', 'new', 'kind'), ('new', 'kind', 'of'), ('kind', 'of', 'learning'), ('of', 'learning', 'experience'), ('learning', 'experience', '.')]