Что такое стемминг?
Стемминг — это своего рода нормализация слов. Нормализация — это метод, при котором набор слов в предложении преобразуется в последовательность, чтобы сократить время поиска. Слова, которые имеют то же значение, но имеют некоторые различия в зависимости от контекста или предложения, нормализуются.
Другими словами, есть одно корневое слово, но есть много вариантов одних и тех же слов. Например, корневое слово «есть» и его вариации «есть, есть, есть и так далее». Точно так же, с помощью Stemming, мы можем найти корневое слово любых вариаций.
Например
He was riding. He was taking the ride.
В приведенных выше двух предложениях значение одно и то же, то есть верховая активность в прошлом. Человек может легко понять, что оба значения одинаковы. Но для машин оба предложения разные. Таким образом, стало трудно преобразовать его в одну строку данных. В случае, если мы не предоставляем тот же набор данных, машина не может предсказать. Поэтому необходимо дифференцировать значение каждого слова, чтобы подготовить набор данных для машинного обучения. И здесь используется stemming для классификации данных того же типа путем получения их корневого слова.
Давайте реализуем это с помощью программы на Python. В NLTK есть алгоритм с именем «PorterStemmer». Этот алгоритм принимает список токенизированного слова и превращает его в корневое слово.
Программа для понимания Stemming
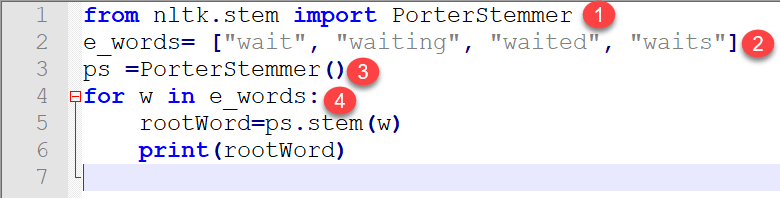
from nltk.stem import PorterStemmer
e_words= ["wait", "waiting", "waited", "waits"]
ps =PorterStemmer()
for w in e_words:
rootWord=ps.stem(w)
print(rootWord)
Выход :
wait wait wait wait
Объяснение кода:
- В NLTk есть модуль ствола, который импортируется. Если вы импортируете полный модуль, программа становится тяжелой, так как содержит тысячи строк кода. Таким образом, из всего модуля ствола мы импортировали только «PorterStemmer».
- Мы подготовили фиктивный список данных вариаций того же слова.
- Создается объект, который принадлежит классу nltk.stem.porter.PorterStemmer.
- Далее, мы передавали его PorterStemmer один за другим, используя цикл for. Наконец, мы получили выходное корневое слово каждого слова, указанного в списке.
Из вышеприведенного объяснения также можно сделать вывод, что создание основы считается важным этапом предварительной обработки, поскольку оно устраняет избыточность данных и вариации в одном и том же слове. В результате данные фильтруются, что поможет улучшить машинное обучение.
Теперь мы передаем полное предложение и проверяем его поведение в качестве вывода.
Программа:
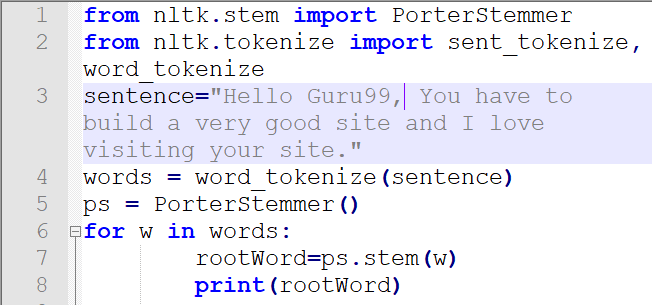
from nltk.stem import PorterStemmer from nltk.tokenize import sent_tokenize, word_tokenize sentence="Hello Guru99, You have to build a very good site and I love visiting your site." words = word_tokenize(sentence) ps = PorterStemmer() for w in words: rootWord=ps.stem(w) print(rootWord)
Вывод:
hello guru99 , you have build a veri good site and I love visit your site
Код Объяснение
- Пакет PorterStemer импортируется из модуля ствола
- Пакеты для токенизации предложения, а также слова импортируются
- Написано предложение, которое должно быть размечено на следующем шаге.
- На этом шаге реализовано слово токенизация.
- Здесь создается объект для PorterStemmer.
- Цикл запускается, и обработка каждого слова выполняется с использованием объекта, созданного в строке кода 5
Вывод:
Stemming — это модуль предварительной обработки данных. В английском языке есть много вариантов одного слова. Эти вариации создают неоднозначность в обучении и прогнозировании машинного обучения. Чтобы создать успешную модель, крайне важно отфильтровать такие слова и преобразовать их в последовательные данные того же типа, используя stemming. Кроме того, это важная техника для получения данных строки из набора предложений и удаления избыточных данных, также известных как нормализация.
Что такое лемматизация?
Лемматизация — это алгоритмический процесс нахождения леммы слова в зависимости от его значения. Лемматизация обычно относится к морфологическому анализу слов, целью которого является удаление флективных окончаний. Это помогает в возвращении базовой или словарной формы слова, которое известно как лемма. Метод лемматизации NLTK основан на встроенной морф-функции WorldNet. Предварительная обработка текста включает в себя как основы, так и лемматизации. Многие люди находят два термина запутанными. Некоторые относятся к ним как к одним и тем же, но между ними есть разница. Лемматизация предпочтительнее первой по следующей причине.
Почему лемматизация лучше стемминга?
Алгоритм Stemming работает, вырезая суффикс из слова. В более широком смысле отсекает начало или конец слова.
Наоборот, лемматизация является более мощной операцией и учитывает морфологический анализ слов. Он возвращает лемму, которая является базовой формой всех ее флективных форм. Для создания словарей и поиска правильной формы слова необходимы глубокие лингвистические знания. Стемминг — это общая операция, а лемматизация — интеллектуальная операция, в которой правильная форма будет выглядеть в словаре. Следовательно, лемматизация помогает в формировании лучших возможностей машинного обучения.
Код для разграничения лемматизации и стемминга
Код стемминга
import nltk
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
text = "studies studying cries cry"
tokenization = nltk.word_tokenize(text)
for w in tokenization:
print("Stemming for {} is {}".format(w,porter_stemmer.stem(w)))
Вывод:
Stemming for studies is studi Stemming for studying is studi Stemming for cries is cri Stemming for cry is cri
Код лемматизации
import nltk
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
text = "studies studying cries cry"
tokenization = nltk.word_tokenize(text)
for w in tokenization:
print("Lemma for {} is {}".format(w, wordnet_lemmatizer.lemmatize(w)))
Вывод:
Lemma for studies is study Lemma for studying is studying Lemma for cries is cry Lemma for cry is cry
Обсуждение результатов:
Если вы смотрите на учебу и учебу, результат такой же (студийный), но лемматизатор предоставляет разные леммы как для изучения токенов для обучения, так и для обучения. Поэтому, когда нам нужно сделать набор функций для обучения машины, было бы здорово, если бы лемматизация была предпочтительной.
Вариант использования лемматизатора:
Лемматизатор минимизирует неоднозначность текста. Примеры слов, таких как велосипед или велосипеды, преобразуются в базовое слово велосипед. По сути, он преобразует все слова, имеющие одинаковое значение, но разное представление, в их базовую форму. Это уменьшает плотность слова в данном тексте и помогает в подготовке точных характеристик для учебного автомата. Чем чище данные, тем интеллектуальнее и точнее будет ваша модель машинного обучения. Lemmatizer также экономит память и вычислительные затраты.
Пример реального времени, демонстрирующий использование лемматизации Wordnet и POS-тегов в Python
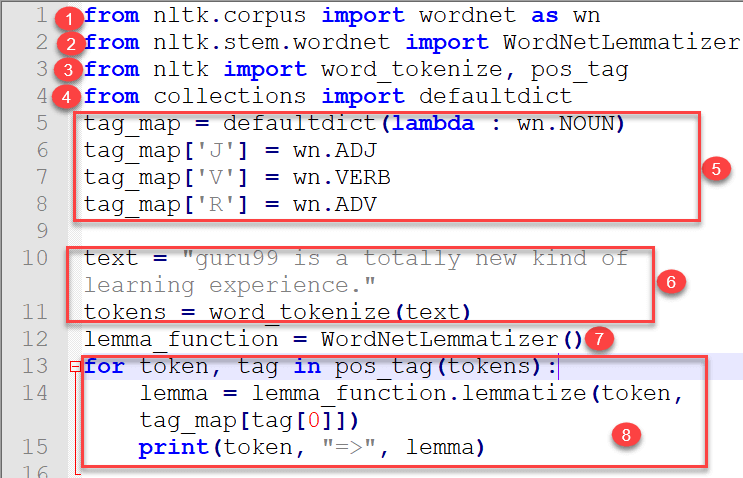
from nltk.corpus import wordnet as wn from nltk.stem.wordnet import WordNetLemmatizer from nltk import word_tokenize, pos_tag from collections import defaultdict tag_map = defaultdict(lambda : wn.NOUN) tag_map['J'] = wn.ADJ tag_map['V'] = wn.VERB tag_map['R'] = wn.ADV text = "guru99 is a totally new kind of learning experience." tokens = word_tokenize(text) lemma_function = WordNetLemmatizer() for token, tag in pos_tag(tokens): lemma = lemma_function.lemmatize(token, tag_map[tag[0]]) print(token, "=>", lemma)
Код Объяснение
- Во-первых, импортируется Wordnet корпуса.
- WordNetLemmatizer импортируется из Wordnet
- Word tokenize, а также части речевого тега импортируются из nltk
- Словарь по умолчанию импортируется из коллекций
- Создается словарь, в котором pos_tag (первая буква) — это ключевые значения, значения которых сопоставляются со значением из словаря wordnet. Мы взяли единственную первую букву, так как будем использовать ее позже в цикле.
- Текст написан и маркирован.
- Создается объект lemma_function, который будет использоваться внутри цикла
- Цикл запускается, и lemmatize принимает два аргумента, один из которых является токеном, а другой — отображением pos_tag со значением wordnet.
Вывод:
guru99 => guru99 is => be totally => totally new => new kind => kind of => of learning => learn experience => experience . => .
Лемматизация имеет тесную связь со словарем Wordnet, поэтому важно изучить эту тему, поэтому мы оставляем ее как следующую тему