Пометка предложений
Пометка предложения в более широком смысле означает добавление меток глагола, существительного и т. Д. В контексте предложения. Идентификация POS-тегов — сложный процесс. Таким образом, общая маркировка POS вручную невозможна, поскольку некоторые слова могут иметь разные (неоднозначные) значения в зависимости от структуры предложения. Преобразование текста в виде списка является важным шагом перед тегированием, поскольку каждое слово в списке зацикливается и подсчитывается для определенного тега. Пожалуйста, смотрите код ниже, чтобы понять это лучше
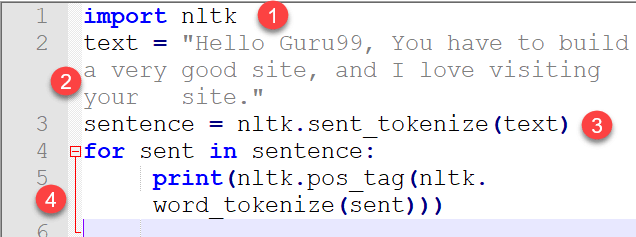
import nltk text = "Hello Guru99, You have to build a very good site, and I love visiting your site." sentence = nltk.sent_tokenize(text) for sent in sentence: print(nltk.pos_tag(nltk.word_tokenize(sent)))
ВЫВОД
[('Hello', 'NNP'), ('Guru99', 'NNP'), (',', ','), ('You', 'PRP'), ('have', 'VBP'), ('build', 'VBN'), ('a', 'DT'), ('very', 'RB'), ('good', 'JJ'), ('site', 'NN'), ('and', 'CC'), ('I', 'PRP'), ('love', 'VBP'), ('visiting', 'VBG'), ('your', 'PRP$'), ('site', 'NN'), ('.', '.')]
Код Объяснение
- Код для импорта nltk (инструментарий естественного языка, который содержит подмодули, такие как токенизация предложений и слово токенов).
- Текст, чьи теги должны быть напечатаны.
- Токенизация Приговора
- Реализован цикл for, в котором слова токенизируются из предложения, а тег каждого слова выводится на печать.
В корпусе есть два типа POS-тегеров:
- Основанной на правилах
- Stochastic POS Taggers
1. POS Tagger на основе правил : Для слов, имеющих неоднозначное значение, применяется основанный на правилах подход на основе контекстной информации. Это делается путем проверки или анализа значения предыдущего или следующего слова. Информация анализируется из окружения слова или внутри себя. Поэтому слова помечены грамматическими правилами определенного языка, такими как использование заглавных букв и знаков препинания. например, тэггер Брилла.
2.Stochastic POS Tagger: при этом методе применяются разные подходы, такие как частота или вероятность. Если слово в большинстве случаев помечено определенным тегом в обучающем наборе, то в тестовом предложении ему присваивается этот конкретный тег. Слово тег зависит не только от собственного тега, но и от предыдущего тега. Этот метод не всегда точен. Другим способом является вычисление вероятности появления определенного тега в предложении. Таким образом, окончательный тег вычисляется путем проверки наибольшей вероятности слова с определенным тегом.
Скрытая Марковская Модель:
Проблемы с тегами также можно смоделировать с помощью HMM. Он рассматривает входные токены как наблюдаемую последовательность, в то время как теги рассматриваются как скрытые состояния, и цель состоит в том, чтобы определить последовательность скрытых состояний. Например, x = x 1 , x 2 , …………, x n, где x — последовательность токенов, а y = y 1 , y 2 , y 3 , y 4 …. ….. y n — скрытая последовательность.
Как работает модель HMM?
HMM использует распределение соединений, которое представляет собой P (x, y), где x — последовательность ввода / последовательности токенов, а y — последовательность тегов.
Последовательность тегов для x будет иметь вид argmax y1 …. yn p (x1, x2, …. xn, y1, y2, y3, …..). Мы категоризировали теги из текста, но статистика таких тегов имеет жизненно важное значение. Поэтому следующая часть подсчитывает эти теги для статистического исследования.