Что такое токенизация?
Токенизация — это процесс, посредством которого большое количество текста делится на более мелкие части, называемые токенами .
Обработка естественного языка используется для создания приложений, таких как классификация текста, интеллектуальный чат-бот, сентиментальный анализ, языковой перевод и т. Д. Для достижения вышеуказанной цели становится жизненно важным понять закономерность в тексте. Эти токены очень полезны для нахождения таких паттернов, а также рассматриваются как базовый шаг для обобщения и лемматизации.
В настоящее время не нужно беспокоиться об обрезке и лемматизации, а относитесь к ним как к шагам по очистке текстовых данных с использованием NLP (обработка на естественном языке). Мы обсудим основы и лемматизацию позже в этом уроке. Такие задачи, как классификация текста или фильтрация спама, используют NLP наряду с библиотеками глубокого изучения, такими как Keras и Tensorflow.
Набор инструментов Natural Language имеет очень важный модуль tokenize, который дополнительно состоит из подмодулей.
- слово токенизировать
- приговор токенизировать
Токенизация слов
Мы используем метод word_tokenize (), чтобы разбить предложение на слова. Вывод слова токенизации может быть преобразован в Data Frame для лучшего понимания текста в приложениях машинного обучения. Он также может быть предоставлен в качестве входных данных для следующих этапов очистки текста, таких как удаление знаков препинания, удаление числовых символов или выделение. Модели машинного обучения нуждаются в числовых данных для обучения и прогнозирования. Слово токенизация становится важной частью преобразования текста (строки) в числовые данные. Пожалуйста, прочитайте о Bag of Words или CountVectorizer . Пожалуйста, обратитесь к приведенному ниже примеру, чтобы лучше понять теорию.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
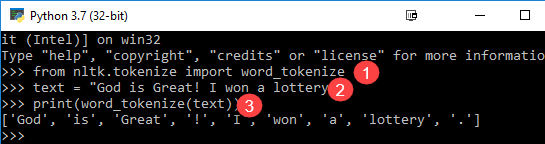
Код Объяснение
- Модуль word_tokenize импортирован из библиотеки NLTK.
- Переменная «текст» инициализируется двумя предложениями.
- Текстовая переменная передается в модуль word_tokenize и печатает результат. Этот модуль разбивает каждое слово пунктуацией, которую вы можете увидеть в выводе.
Токенизация предложений
Подмодуль, доступный для вышеупомянутого, это sent_tokenize. Очевидный вопрос, который вы себе представляете, заключается в том, почему токенизация предложений необходима, когда у нас есть опция токенизации слов . Представьте, что вам нужно посчитать среднее количество слов в предложении, как вы будете рассчитывать? Для выполнения такой задачи вам понадобится как токенизация предложения, так и слова для вычисления отношения. Такой вывод служит важной особенностью для машинного обучения, поскольку ответ будет числовым.
Посмотрите на приведенный ниже пример, чтобы узнать, чем токенизация предложений отличается от токенизации слов.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
У нас есть 12 слов и два предложения для одного и того же ввода.
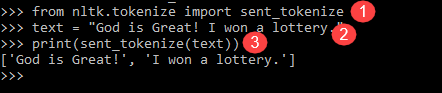
Объяснение программы:
- В строке, аналогичной предыдущей программе, импортирован модуль sent_tokenize.
- Мы приняли одно и то же предложение. Далее отправленный модуль анализирует эти предложения и показывает вывод. Понятно, что эта функция разбивает каждое предложение.
Выше приведены примеры хороших настроек камней для понимания механики слова и предложения токенизации.