Стандартное отклонение (SD) является мерой того, насколько разнообразны данные в наборе данных. Математически он измеряет, насколько далеко или близко каждое значение от среднего значения набора данных. Значение стандартного отклонения, близкое к 0, указывает, что точки данных, как правило, очень близки к среднему значению набора данных, а высокое стандартное отклонение указывает, что точки данных распределены по более широкому диапазону значений.
В SAS значения SD измеряются с помощью PROC MEAN, а также PROC SURVEYMEANS.
Использование PROC MEANS
Для измерения SD с помощью средств proc мы выбираем параметр STD на шаге PROC. Он выводит значения SD для каждой числовой переменной, присутствующей в наборе данных.
Синтаксис
Основной синтаксис для расчета стандартного отклонения в SAS —
PROC means DATA = dataset STD;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
Набор данных — это имя набора данных.
пример
В приведенном ниже примере мы создаем набор данных CARS1 из набора данных CARS в библиотеке SASHELP. Мы выбираем вариант STD с шагом PROC означает.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;
Когда мы выполняем приведенный выше код, он дает следующий вывод —
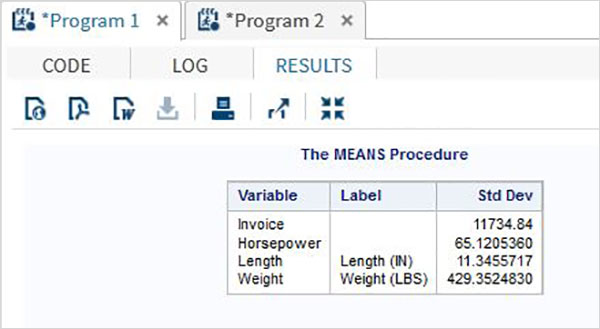
Использование PROC SURVEYMEANS
Эта процедура также используется для измерения SD наряду с некоторыми дополнительными функциями, такими как измерение SD для категориальных переменных, а также для получения оценок отклонений.
Синтаксис
Синтаксис использования PROC SURVEYMEANS —
PROC SURVEYMEANS options statistic-keywords ; BY variables ; CLASS variables ; VAR variables ;
Ниже приведено описание используемых параметров:
-
BY — указывает переменные, используемые для создания групп наблюдений.
-
CLASS — указывает переменные, используемые для категориальных переменных.
-
VAR — указывает переменные, для которых будет рассчитываться SD.
BY — указывает переменные, используемые для создания групп наблюдений.
CLASS — указывает переменные, используемые для категориальных переменных.
VAR — указывает переменные, для которых будет рассчитываться SD.
пример
В приведенном ниже примере описано использование опции класса, которая создает статистику для каждого из значений в переменной класса.
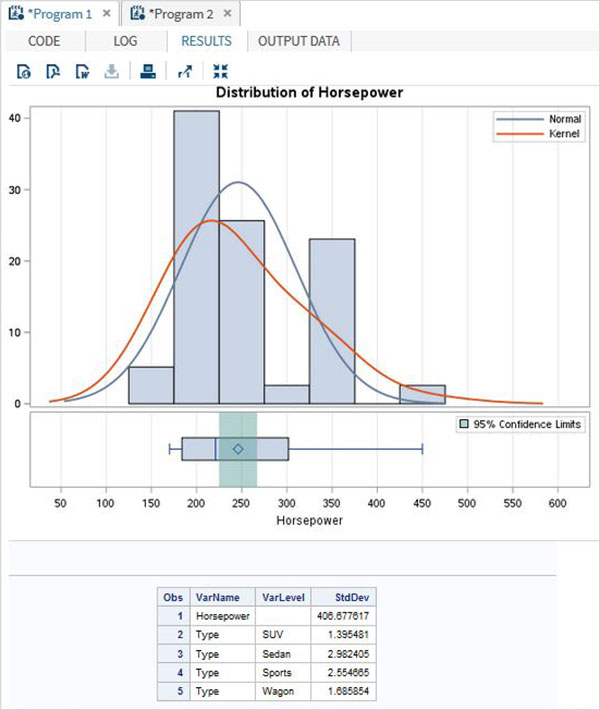
proc surveymeans data = CARS1 STD; class type; var type horsepower; ods output statistics = rectangle; run; proc print data = rectangle; run;
Когда мы выполняем приведенный выше код, он дает следующий вывод —
Использование опции BY
Приведенный ниже код дает пример опции BY. В нем результат группируется для каждого значения в опции BY.
пример
proc surveymeans data = CARS1 STD; var horsepower; BY make; ods output statistics = rectangle; run; proc print data = rectangle; run;
Когда мы выполняем приведенный выше код, он дает следующий вывод —