Распределение частот — это таблица, показывающая частоту точек данных в наборе данных. Каждая запись в таблице содержит частоту или количество вхождений значений в определенной группе или интервале, и, таким образом, таблица суммирует распределение значений в выборке.
SAS предоставляет процедуру PROC FREQ для расчета частотного распределения точек данных в наборе данных.
Синтаксис
Основной синтаксис для вычисления распределения частот в SAS —
PROC FREQ DATA = Dataset ; TABLES Variable_1 ; BY Variable_2 ;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
Переменные_1 — это имена переменных набора данных, распределение частот которого необходимо рассчитать.
-
Переменные_2 — это переменные, которые классифицировали результат распределения частоты.
Набор данных — это имя набора данных.
Переменные_1 — это имена переменных набора данных, распределение частот которого необходимо рассчитать.
Переменные_2 — это переменные, которые классифицировали результат распределения частоты.
Распределение частоты одной переменной
Мы можем определить распределение частоты одной переменной с помощью PROC FREQ. В этом случае результат покажет частоту каждого значения переменной. Результат также показывает процентное распределение, совокупную частоту и совокупный процент.
пример
В приведенном ниже примере мы находим частотное распределение переменной лошадиной силы для набора данных с именем CARS1, который создается из библиотеки SASHELP.CARS. Мы можем видеть результат, разделенный на две категории результатов. Один для каждой марки автомобиля.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
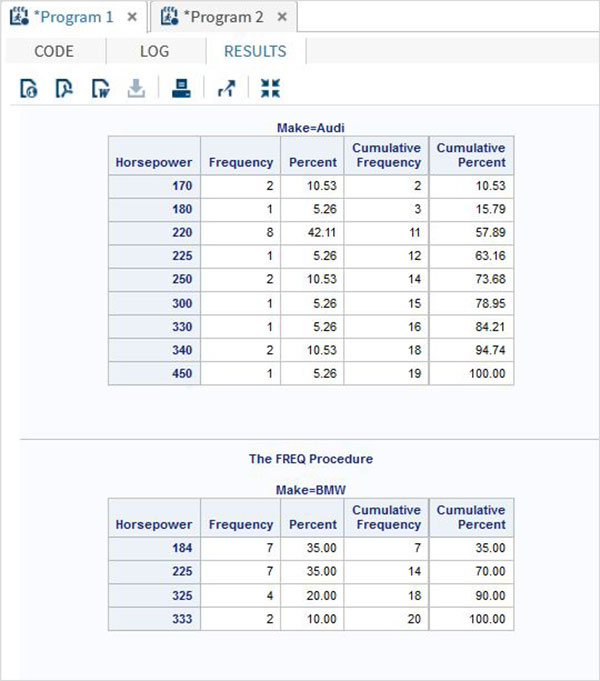
Многократное частотное распределение
Мы можем найти частотные распределения для нескольких переменных, которые группируют их во все возможные комбинации.
пример
В приведенном ниже примере мы рассчитываем распределение частоты для марки автомобиля, сгруппированного по типу автомобиля, а также распределение частоты для каждого типа автомобиля, сгруппированного по каждой марке.
proc FREQ data = CARS1 ; tables make type; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
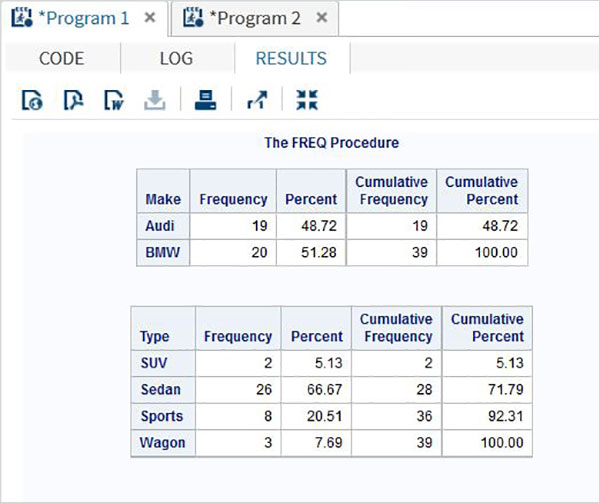
Распределение частот с весом
С помощью опции веса мы можем рассчитать распределение частоты, смещенное с весом переменной. Здесь значение переменной берется как количество наблюдений, а не как количество значений.
пример
В приведенном ниже примере мы рассчитываем распределение частот переменных и типа с весом, назначенным для лошадиных сил.
proc FREQ data = CARS1 ; tables make type; weight horsepower; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —