SAS — Обзор
SAS означает ПО для статистического анализа . Он был создан в 1960 году Институтом SAS. С 1 января 1960 года SAS использовался для управления данными, бизнес-аналитики, прогнозного анализа, описательного и предписывающего анализа и т. Д. С тех пор в программное обеспечение было введено много новых статистических процедур и компонентов.
С введением JMP (Jump) для статистики SAS воспользовался графическим интерфейсом пользователя, который был представлен Macintosh. Jump в основном используется для таких приложений, как Six Sigma, проектирования, контроля качества, инженерного и научного анализа.
SAS не зависит от платформы, что означает, что вы можете запускать SAS в любой операционной системе — Linux или Windows. SAS управляется программистами SAS, которые используют несколько последовательностей операций над наборами данных SAS для создания надлежащих отчетов для анализа данных.
За эти годы SAS добавила множество решений в свой портфель продуктов. У него есть решение для управления данными, качества данных, аналитики больших данных, интеллектуального анализа текста, борьбы с мошенничеством, науки о здоровье и т. Д. Мы можем с уверенностью предположить, что у SAS есть решение для любой области бизнеса.
Чтобы ознакомиться с перечнем доступных продуктов, посетите раздел SAS Components.
Почему мы используем SAS
SAS в основном работает с большими наборами данных. С помощью программного обеспечения SAS вы можете выполнять различные операции с данными, как —
- Управление данными
- Статистический анализ
- Формирование отчета с идеальной графикой
- Планирование бизнеса
- Исследование операций и управление проектами
- Улучшение качества
- Разработка приложения
- Извлечение данных
- Преобразование данных
- Обновление и модификация данных
Если говорить о компонентах SAS, то в SAS доступно более 200 компонентов.
| Sr.No. | Компонент SAS и их использование |
|---|---|
| 1 |
База САС Это основной компонент, который содержит средство управления данными и язык программирования для анализа данных. Это также наиболее широко используемый. |
| 2 |
SAS / GRAPH Создавайте графики, презентации для лучшего понимания и демонстрации результатов в правильном формате. |
| 3 |
SAS / STAT Выполните статистический анализ с помощью дисперсионного анализа, регрессии, многомерного анализа, анализа выживаемости и психометрического анализа, анализа смешанной модели. |
| 4 |
SAS / ИЛИ Исследование операций. |
| 5 |
SAS / ETS Эконометрика и анализ временных рядов. |
| 6 |
SAS / IML Cинтерактивный матричный язык. |
| 7 |
SAS / AF Объекты приложений. |
| 8 |
SAS / QC Контроль качества. |
| 9 |
SAS / INSIGHT Сбор данных. |
| 10 |
SAS / PH Анализ клинических испытаний. |
| 11 |
SAS / Enterprise Miner Сбор данных. |
База САС
Это основной компонент, который содержит средство управления данными и язык программирования для анализа данных. Это также наиболее широко используемый.
SAS / GRAPH
Создавайте графики, презентации для лучшего понимания и демонстрации результатов в правильном формате.
SAS / STAT
Выполните статистический анализ с помощью дисперсионного анализа, регрессии, многомерного анализа, анализа выживаемости и психометрического анализа, анализа смешанной модели.
SAS / ИЛИ
Исследование операций.
SAS / ETS
Эконометрика и анализ временных рядов.
SAS / IML
Cинтерактивный матричный язык.
SAS / AF
Объекты приложений.
SAS / QC
Контроль качества.
SAS / INSIGHT
Сбор данных.
SAS / PH
Анализ клинических испытаний.
SAS / Enterprise Miner
Сбор данных.
Типы программного обеспечения SAS
- Windows или ПК SAS
- SAS EG (Руководство для предприятий)
- SAS EM (Enterprise Miner, т.е. для прогнозного анализа)
- SAS Средства
- SAS Stats
В основном мы используем Window SAS как в организации, так и в учебных заведениях. Некоторые организации используют Linux, но нет графического интерфейса пользователя, поэтому вы должны писать код для каждого запроса. Но в окне SAS есть много доступных утилит, которые очень помогают программистам, а также сокращают время написания кодов.
Окно SaS состоит из 5 частей.
| Sr.No. | Окно SAS и их использование |
|---|---|
| 1 |
Окно журнала Окно журнала похоже на окно выполнения, в котором мы можем проверить выполнение программы SAS. В этом окне мы также можем проверить ошибки. Очень важно каждый раз проверять окно журнала после запуска программы. Чтобы у нас было правильное представление о выполнении нашей программы. |
| 2 |
Окно редактора Окно редактора — это та часть SAS, где мы пишем все коды. Это как блокнот. |
| 3 |
Окно вывода Окно вывода — это окно результатов, в котором мы можем увидеть вывод нашей программы. |
| 4 |
Окно результатов Это как индекс для всех выходов. Все программы, которые мы запустили в одном сеансе SAS, перечислены там, и вы можете открыть вывод, нажав на результат вывода. Но они упоминаются только на одном заседании SAS. Если мы закроем программное обеспечение, а затем откроем его, окно результатов будет пустым. |
| 5 |
Исследовать Окно Здесь перечислены все библиотеки. Вы также можете просмотреть файлы, поддерживаемые вашей системой SAS, отсюда. |
Окно журнала
Окно журнала похоже на окно выполнения, в котором мы можем проверить выполнение программы SAS. В этом окне мы также можем проверить ошибки. Очень важно каждый раз проверять окно журнала после запуска программы. Чтобы у нас было правильное представление о выполнении нашей программы.
Окно редактора
Окно редактора — это та часть SAS, где мы пишем все коды. Это как блокнот.
Окно вывода
Окно вывода — это окно результатов, в котором мы можем увидеть вывод нашей программы.
Окно результатов
Это как индекс для всех выходов. Все программы, которые мы запустили в одном сеансе SAS, перечислены там, и вы можете открыть вывод, нажав на результат вывода. Но они упоминаются только на одном заседании SAS. Если мы закроем программное обеспечение, а затем откроем его, окно результатов будет пустым.
Исследовать Окно
Здесь перечислены все библиотеки. Вы также можете просмотреть файлы, поддерживаемые вашей системой SAS, отсюда.
Библиотеки в САС
Библиотеки как хранилище в SAS. Вы можете создать библиотеку и сохранить все похожие программы в этой библиотеке. SAS предоставляет вам возможность создавать несколько библиотек. Библиотека SAS имеет длину всего 8 символов.
В SAS доступны два типа библиотек:
| Sr.No. | Окно SAS и их использование |
|---|---|
| 1 |
Временная или рабочая библиотека Это библиотека SAS по умолчанию. Все программы, которые мы создаем, хранятся в этой рабочей библиотеке, если мы не назначаем им другую библиотеку. Вы можете проверить эту рабочую библиотеку в окне просмотра. Если вы создаете программу SAS и не назначаете ей постоянную библиотеку, то, если после этого вы снова завершите сеанс, вы запустите программное обеспечение, тогда эта программа не будет в рабочей библиотеке. Потому что он будет там только в библиотеке Work, пока сеанс идет. |
| 2 |
Постоянная библиотека Это постоянные библиотеки САС. Мы можем создать новую библиотеку SAS, используя утилиты SAS или написав коды в окне редактора. Эти библиотеки названы постоянными, потому что если мы создадим программу в SAS и сохраним ее в этих постоянных библиотеках, они будут доступны столько, сколько нам нужно. |
Временная или рабочая библиотека
Это библиотека SAS по умолчанию. Все программы, которые мы создаем, хранятся в этой рабочей библиотеке, если мы не назначаем им другую библиотеку. Вы можете проверить эту рабочую библиотеку в окне просмотра. Если вы создаете программу SAS и не назначаете ей постоянную библиотеку, то, если после этого вы снова завершите сеанс, вы запустите программное обеспечение, тогда эта программа не будет в рабочей библиотеке. Потому что он будет там только в библиотеке Work, пока сеанс идет.
Постоянная библиотека
Это постоянные библиотеки САС. Мы можем создать новую библиотеку SAS, используя утилиты SAS или написав коды в окне редактора. Эти библиотеки названы постоянными, потому что если мы создадим программу в SAS и сохраним ее в этих постоянных библиотеках, они будут доступны столько, сколько нам нужно.
SAS — Окружающая среда
SAS Institute Inc. выпустила бесплатную версию SAS University Edition, которая достаточно хороша для изучения программирования на SAS. Он предоставляет все функции, которые вам необходимо изучить в программировании BASE SAS, что, в свою очередь, позволяет изучать любой другой компонент SAS.
Процесс загрузки и установки SAS University Edition очень прост. Он доступен как виртуальная машина, которая должна работать в виртуальной среде. Прежде чем запускать программное обеспечение SAS, на вашем компьютере должно быть уже установлено программное обеспечение для виртуализации. В этом уроке мы будем использовать VMware . Ниже приведены подробные инструкции по загрузке, настройке среды SAS и проверке установки.
Скачать SAS University Edition
Выпуск SAS University Edition доступен для загрузки по адресу URL SAS University Edition . Пожалуйста, прокрутите вниз, чтобы прочитать системные требования, прежде чем начать загрузку. Следующий экран появляется при посещении этого URL.
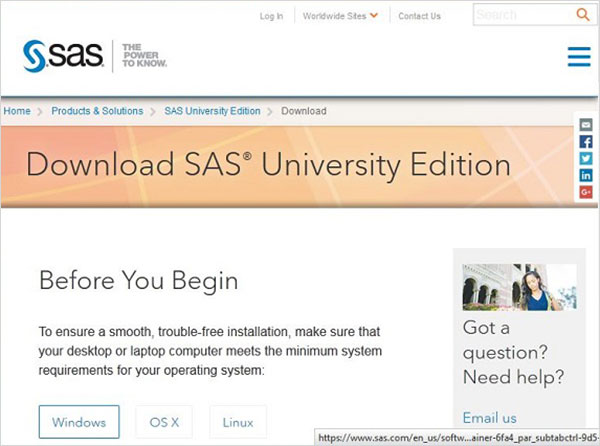
Настройка программного обеспечения для виртуализации
Прокрутите вниз на той же странице, чтобы найти установочный stpe-1. Этот шаг предоставляет ссылки для получения программного обеспечения для виртуализации, которое подходит вам. Если в вашей системе уже установлено какое-либо из этих программ, вы можете пропустить этот шаг.

Быстрый старт программного обеспечения для виртуализации
Если вы совершенно не знакомы со средой виртуализации, вы можете ознакомиться с ней, ознакомившись со следующими руководствами и видеороликами, доступными в шаге 2. Опять же, вы можете пропустить этот шаг, если вы уже знакомы.

Скачать файл Zip
На шаге 3 вы можете выбрать подходящую версию SAS University Edition, совместимую с имеющейся у вас средой виртуализации. Он загружается в виде zip-файла с именем, похожим на unvbasicvapp__9411005__vmx__en__sp0__1.zip
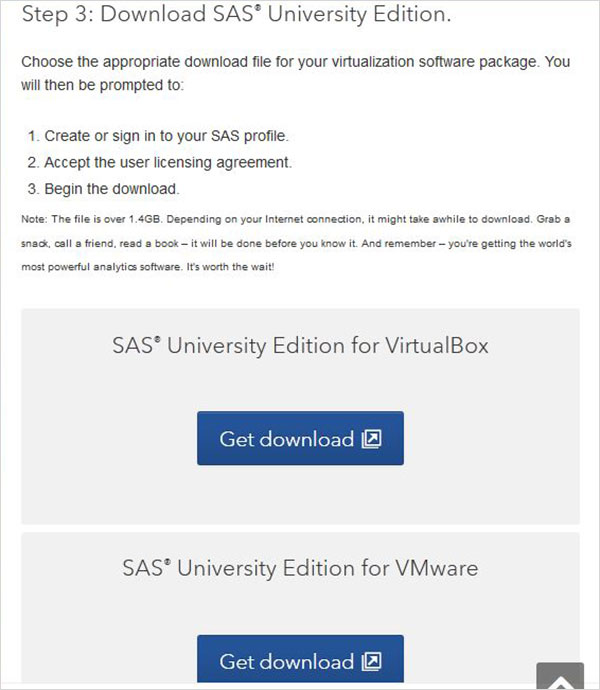
Разархивируйте zip-файл
Приведенный выше zip-файл необходимо распаковать и сохранить в соответствующем каталоге. В нашем случае мы выбрали zip-файл VMware, который показывает следующие файлы после распаковки.
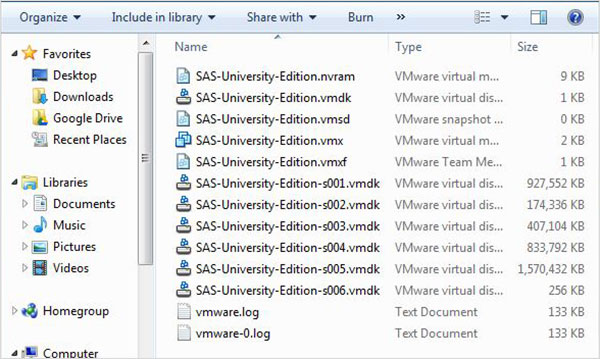
Загрузка виртуальной машины
Запустите проигрыватель VMware (или рабочую станцию) и откройте файл, который заканчивается расширением .vmx. Появится экран ниже. Обратите внимание на основные настройки, такие как память и место на жестком диске, выделенные для виртуальной машины.
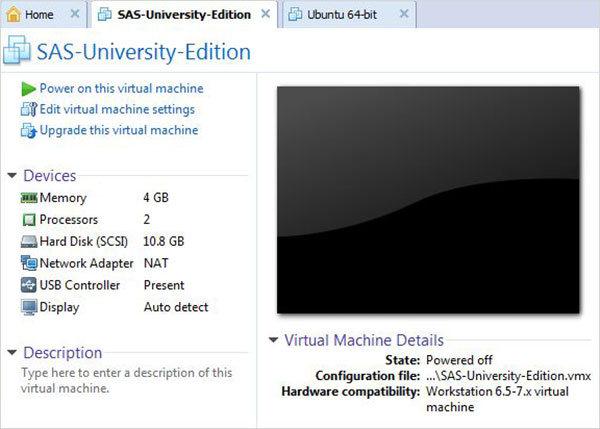
Включите виртуальную машину
Нажмите Power на этой виртуальной машине рядом с зеленой стрелкой, чтобы запустить виртуальную машину. Появится следующий экран.

Приведенный ниже экран появляется, когда виртуальный сервер SAS находится в состоянии загрузки, после чего запущенный виртуальный компьютер выдает запрос на переход к URL-адресу, который открывает среду SAS.
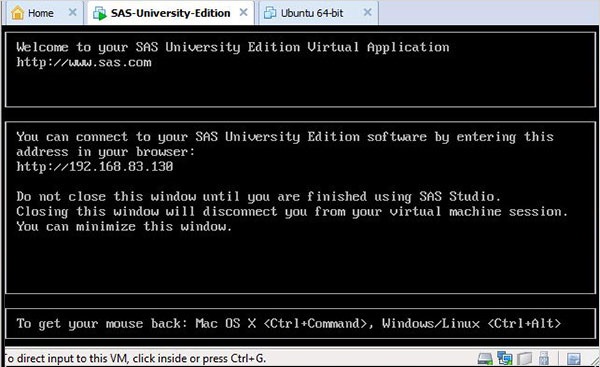
Запуск SAS studio
Откройте новую вкладку браузера и загрузите вышеуказанный URL (который отличается от одного компьютера к другому). Появится экран ниже, указывающий, что среда SAS готова.
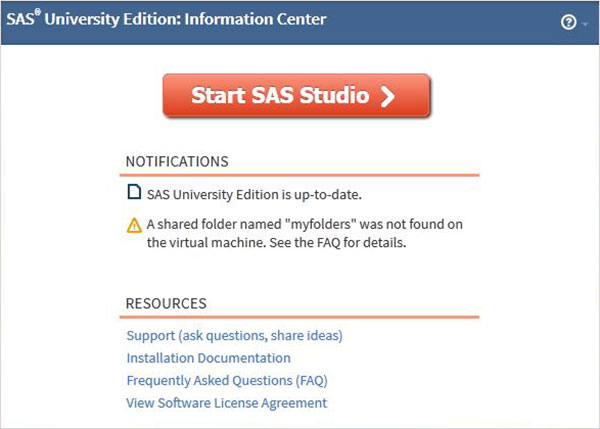
SAS Environment
При нажатии на кнопку « Запустить SAS Studio» мы получаем среду SAS, которая по умолчанию открывается в режиме визуального программиста, как показано ниже.
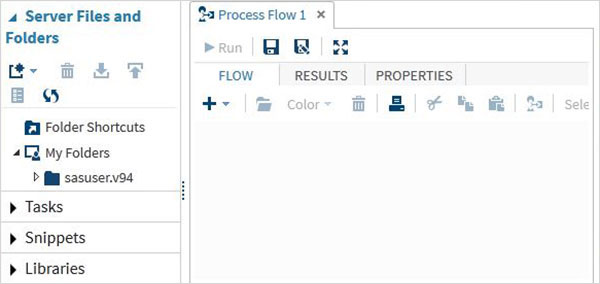
Мы также можем изменить его в режим SAS programmer, нажав на выпадающий список.
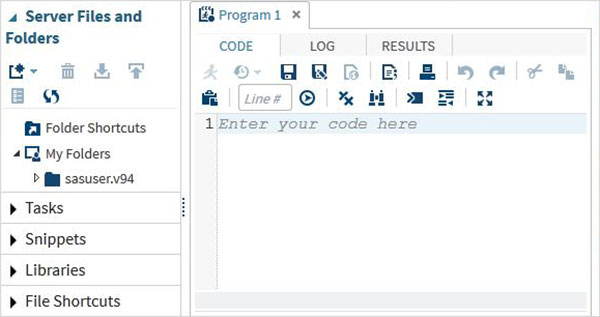
Теперь мы готовы писать программы SAS.
SAS — интерфейс пользователя
Программы SAS создаются с использованием пользовательского интерфейса, известного как SAS Studio .
Ниже приведено описание различных окон и их использования.
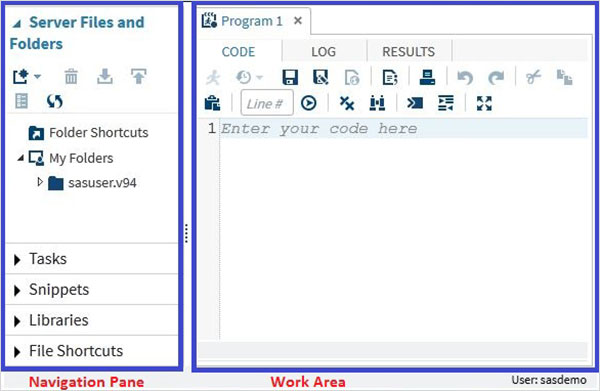
Главное окно SAS
Это окно, которое вы видите при входе в среду SAS. Слева находится панель навигации, используемая для навигации по различным функциям программирования. Справа находится Рабочая область, которая используется для написания кода и его выполнения.
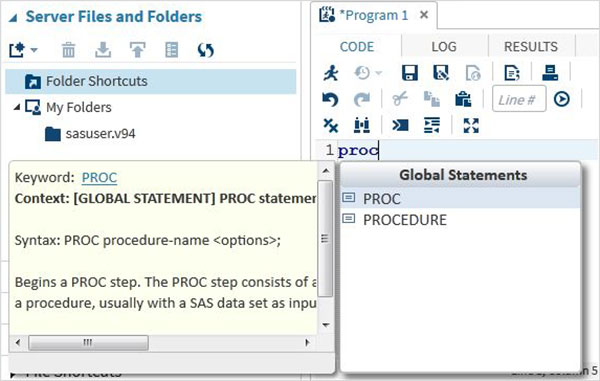
Автозаполнение кода
Это очень мощная функция, которая помогает получить правильный синтаксис ключевых слов SAS, а также предоставляет ссылку на документацию по этому ключевому слову.
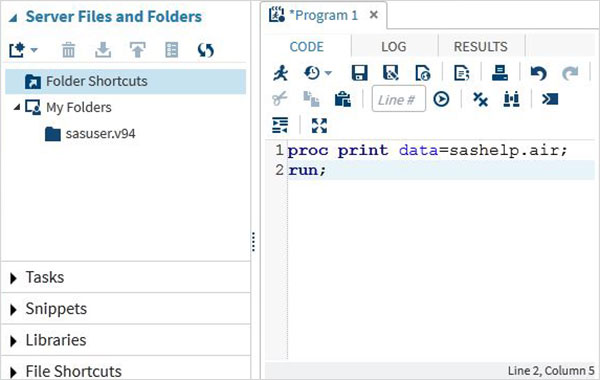
Выполнение программы
Выполнение кода выполняется нажатием на значок запуска, который является первым значком слева или кнопкой F3.
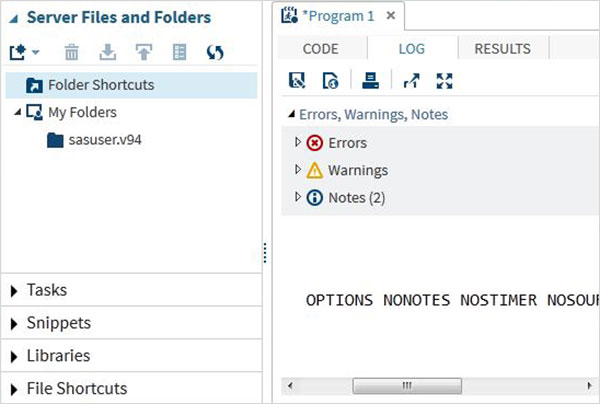
Журнал программы
Журнал выполненного кода доступен на вкладке Журнал . Описывает ошибки, предупреждения или заметки о выполнении программы. Это окно, где вы получаете все подсказки для устранения проблем вашего кода.
Результат программы
Результат выполнения кода отображается на вкладке РЕЗУЛЬТАТЫ. По умолчанию они форматируются как HTML-таблицы.
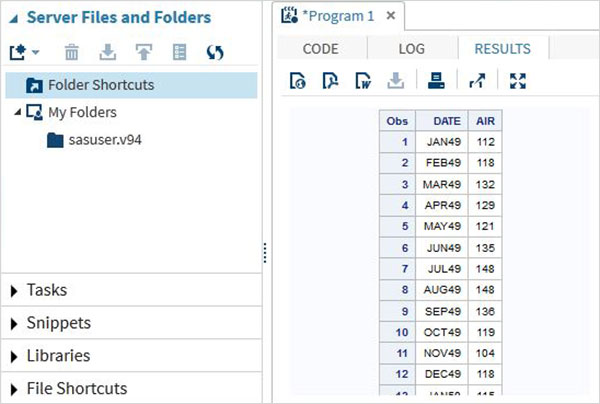
Вкладки программы
Область навигации содержит функции для создания и управления программами. Он также предоставляет встроенные функции, которые будут использоваться с вашей программой.
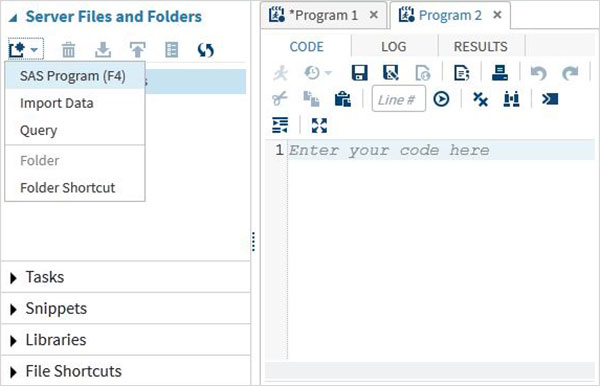
Серверные файлы и папки
На этой вкладке мы можем создавать дополнительные программы, импортировать данные для анализа и запрашивать существующие данные. Он также может быть использован для создания ярлыков папок.
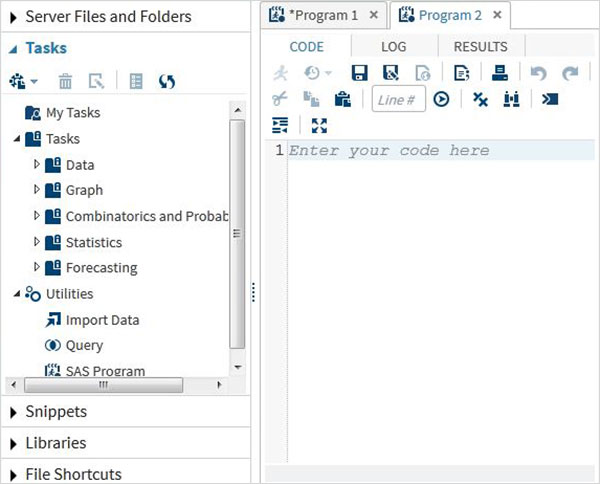
Задачи
Вкладка Tasks предоставляет функции для использования встроенных программ SAS, предоставляя только входные переменные. Например, в папке статистики вы можете найти программу SAS для выполнения линейной регрессии, предоставляя только имя набора данных SAS и имена переменных.
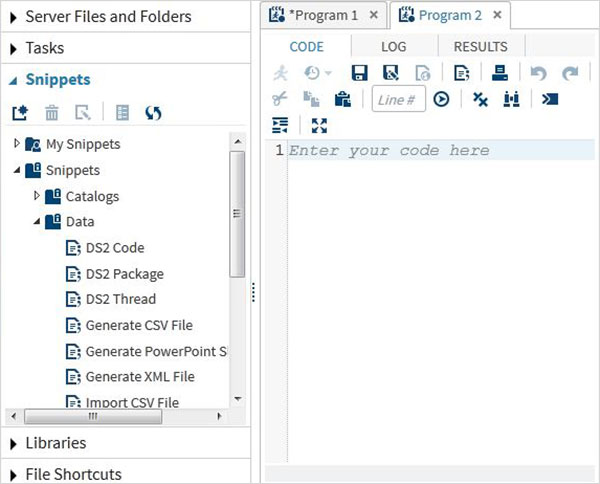
обрывки
На вкладке «Фрагменты кода» содержатся функции для записи макроса SAS и создания файлов из существующего набора данных.
Библиотеки программ
SAS хранит наборы данных в библиотеках SAS. Временная библиотека доступна только для одного сеанса и называется WORK. Но постоянные библиотеки доступны всегда.
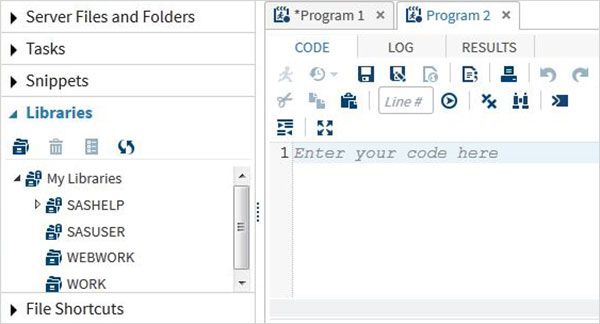
Ярлыки файлов
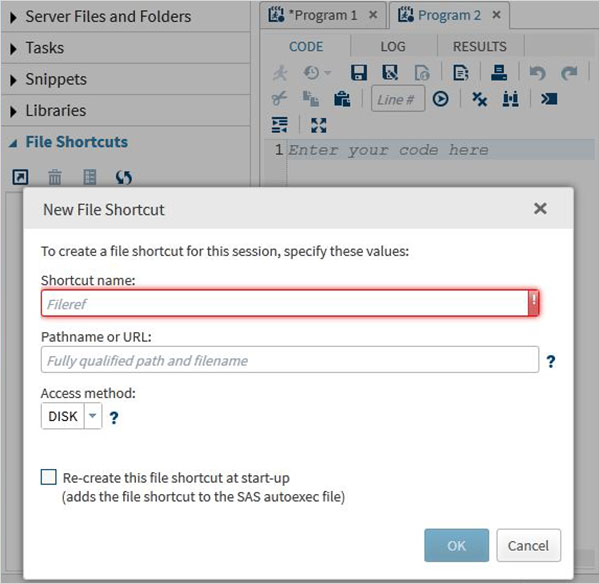
Эта вкладка используется для доступа к файлам, которые хранятся вне среды SAS. Ярлыки для таких файлов хранятся на этой вкладке.
SAS — Структура программы
Программирование SAS включает в себя сначала создание / чтение наборов данных в память, а затем выполнение анализа этих данных. Нам нужно понять поток, в котором написана программа, чтобы достичь этого.
Структура программы SAS
На приведенной ниже схеме показаны шаги, которые должны быть записаны в данной последовательности для создания программы SAS.
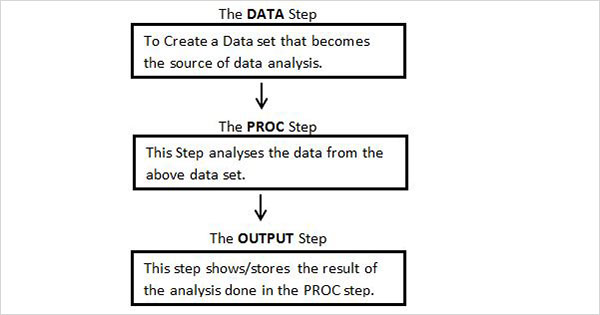
Каждая программа SAS должна иметь все эти шаги для завершения чтения входных данных, анализа данных и выдачи результатов анализа. Также оператор RUN в конце каждого шага необходим для завершения выполнения этого шага.
Шаг данных
Этот шаг включает в себя загрузку необходимого набора данных в память SAS и определение переменных (также называемых столбцами) набора данных. Он также фиксирует записи (также называемые наблюдениями или объектами). Синтаксис для оператора DATA такой, как показано ниже.
Синтаксис
DATA data_set_name; #Name the data set. INPUT var1,var2,var3; #Define the variables in this data set. NEW_VAR; #Create new variables. LABEL; #Assign labels to variables. DATALINES; #Enter the data. RUN;
пример
В приведенном ниже примере показан простой случай именования набора данных, определения переменных, создания новых переменных и ввода данных. Здесь строковые переменные имеют $ в конце, а числовые значения без него.
DATA TEMP; INPUT ID $ NAME $ SALARY DEPARTMENT $; comm = SALARY*0.25; LABEL ID = 'Employee ID' comm = 'COMMISION'; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 Operations 3 Michelle 611 IT 4 Ryan 729 HR 5 Gary 843.25 Finance 6 Nina 578 IT 7 Simon 632.8 Operations 8 Guru 722.5 Finance ; RUN;
PROC Step
Этот шаг включает в себя вызов встроенной процедуры SAS для анализа данных.
Синтаксис
PROC procedure_name options; #The name of the proc. RUN;
пример
В приведенном ниже примере показано использование процедуры MEANS для печати средних значений числовых переменных в наборе данных.
PROC MEANS; RUN;
Шаг ВЫХОДА
Данные из наборов данных могут отображаться с помощью условных операторов вывода.
Синтаксис
PROC PRINT DATA = data_set; OPTIONS; RUN;
пример
В приведенном ниже примере показано использование выражения where в выходных данных для создания только нескольких записей из набора данных.
PROC PRINT DATA = TEMP; WHERE SALARY > 700; RUN;
Полная программа SAS
Ниже приведен полный код для каждого из вышеуказанных шагов.
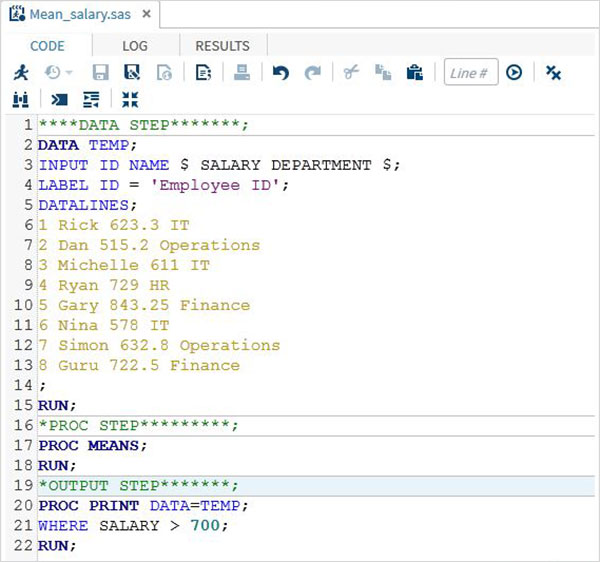
Выход программы
Вывод кода выше виден на вкладке РЕЗУЛЬТАТЫ .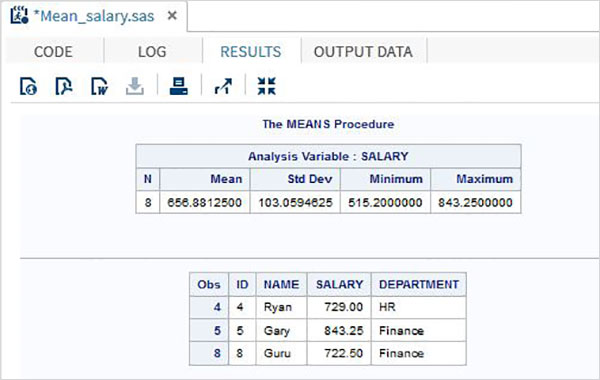
SAS — основной синтаксис
Как и любой другой язык программирования, язык SAS имеет свои собственные правила синтаксиса для создания программ SAS.
Три компонента любой программы SAS — операторы, переменные и наборы данных следуют приведенным ниже правилам синтаксиса.
Заявления SAS
-
Заявления могут начинаться где угодно и заканчиваться где угодно. Точка с запятой в конце последней строки обозначает конец оператора.
-
Многие операторы SAS могут находиться в одной строке, причем каждый оператор заканчивается точкой с запятой.
-
Пространство может использоваться для разделения компонентов в программной инструкции SAS.
-
Ключевые слова SAS не чувствительны к регистру.
-
Каждая программа SAS должна заканчиваться оператором RUN.
Заявления могут начинаться где угодно и заканчиваться где угодно. Точка с запятой в конце последней строки обозначает конец оператора.
Многие операторы SAS могут находиться в одной строке, причем каждый оператор заканчивается точкой с запятой.
Пространство может использоваться для разделения компонентов в программной инструкции SAS.
Ключевые слова SAS не чувствительны к регистру.
Каждая программа SAS должна заканчиваться оператором RUN.
Имена переменных SAS
Переменные в SAS представляют столбец в наборе данных SAS. Имена переменных следуют приведенным ниже правилам.
-
Это может быть максимум 32 символа.
-
Не может включать пробелы.
-
Он должен начинаться с букв от A до Z (без учета регистра) или подчеркивания (_).
-
Может включать цифры, но не в качестве первого символа.
-
Имена переменных нечувствительны к регистру.
Это может быть максимум 32 символа.
Не может включать пробелы.
Он должен начинаться с букв от A до Z (без учета регистра) или подчеркивания (_).
Может включать цифры, но не в качестве первого символа.
Имена переменных нечувствительны к регистру.
пример
# Valid Variable Names REVENUE_YEAR MaxVal _Length # Invalid variable Names Miles Per Liter #contains Space. RainfFall% # contains apecial character other than underscore. 90_high # Starts with a number.
Набор данных SAS
Оператор DATA отмечает создание нового набора данных SAS. Правила создания набора данных приведены ниже.
-
Одно слово после оператора DATA указывает имя временного набора данных. Это означает, что набор данных стирается в конце сеанса.
-
Имя набора данных может начинаться с имени библиотеки, что делает его постоянным набором данных. Это означает, что набор данных сохраняется после окончания сеанса.
-
Если имя набора данных SAS опущено, то SAS создает временный набор данных с именем, сгенерированным SAS, например — DATA1, DATA2 и т. Д.
Одно слово после оператора DATA указывает имя временного набора данных. Это означает, что набор данных стирается в конце сеанса.
Имя набора данных может начинаться с имени библиотеки, что делает его постоянным набором данных. Это означает, что набор данных сохраняется после окончания сеанса.
Если имя набора данных SAS опущено, то SAS создает временный набор данных с именем, сгенерированным SAS, например — DATA1, DATA2 и т. Д.
пример
# Temporary data sets. DATA TempData; DATA abc; DATA newdat; # Permanent data sets. DATA LIBRARY1.DATA1 DATA MYLIB.newdat;
Расширения файлов SAS
Программы SAS, файлы данных и результаты программ сохраняются с различными расширениями в окнах.
-
* .sas — представляет собой файл кода SAS, который можно редактировать с помощью редактора SAS или любого текстового редактора.
-
* .log — представляет собой файл журнала SAS, в котором содержится такая информация, как ошибки, предупреждения и сведения о наборе данных для представленной программы SAS.
-
* .mht / * .html — представляет файл результатов SAS.
-
* .sas7bdat — представляет файл данных SAS, который содержит набор данных SAS, включая имена переменных, метки и результаты расчетов.
* .sas — представляет собой файл кода SAS, который можно редактировать с помощью редактора SAS или любого текстового редактора.
* .log — представляет собой файл журнала SAS, в котором содержится такая информация, как ошибки, предупреждения и сведения о наборе данных для представленной программы SAS.
* .mht / * .html — представляет файл результатов SAS.
* .sas7bdat — представляет файл данных SAS, который содержит набор данных SAS, включая имена переменных, метки и результаты расчетов.
Комментарии в САС
Комментарии в коде SAS указываются двумя способами. Ниже приведены эти два формата.
*сообщение; введите комментарий
Комментарий в виде * сообщения; не может содержать точку с запятой или непревзойденную кавычку внутри него. Также не должно быть никаких ссылок на какие-либо макро-операторы внутри таких комментариев. Он может занимать несколько строк и иметь любую длину. Ниже приведен пример однострочного комментария —
* This is comment ;
Ниже приведен пример многострочного комментария:
* This is first line of the comment * This is second line of the comment;
/ * сообщение * / введите комментарий
Комментарий в виде / * message * / используется чаще и не может быть вложенным. Но он может занимать несколько строк и иметь любую длину. Ниже приведен пример однострочного комментария —
/* This is comment */
Ниже приведен пример многострочного комментария:
/* This is first line of the comment * This is second line of the comment */
SAS — Наборы данных
Данные, доступные для анализа в программе SAS, называются набором данных SAS. Он создается с использованием шага DATA. SAS может считывать различные файлы в качестве источников данных, таких как CSV, Excel, Access, SPSS, а также необработанные данные . Он также имеет много встроенных источников данных, доступных для использования.
-
Наборы данных называются временными наборами данных, если они используются программой SAS, а затем отбрасываются после запуска сеанса.
-
Но если он хранится постоянно для будущего использования, он называется постоянным набором данных . Все постоянные наборы данных хранятся в определенной библиотеке.
Наборы данных называются временными наборами данных, если они используются программой SAS, а затем отбрасываются после запуска сеанса.
Но если он хранится постоянно для будущего использования, он называется постоянным набором данных . Все постоянные наборы данных хранятся в определенной библиотеке.
Набор данных SAS хранится в виде строк и столбцов и также называется таблицей данных SAS. Ниже мы видим примеры постоянных наборов данных, которые встроены, а также выделены красным цветом из внешних источников.
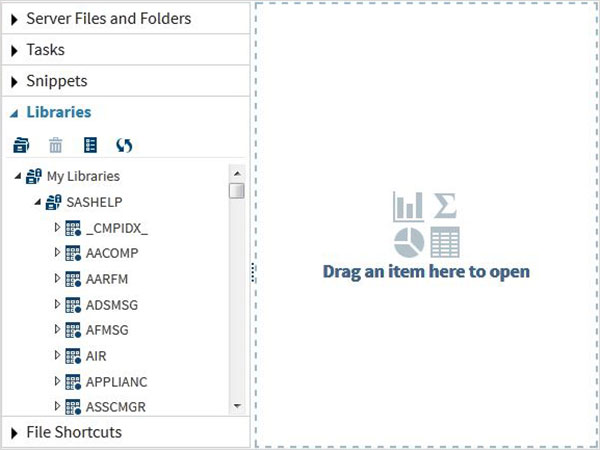
SAS Встроенные наборы данных
Эти наборы данных уже доступны в установленном программном обеспечении SAS. Их можно исследовать и использовать при формулировании выборочных выражений для анализа данных. Чтобы изучить эти наборы данных, перейдите в Библиотеки -> Мои библиотеки -> SASHELP . Расширяя его, мы видим список имен всех доступных встроенных наборов данных.
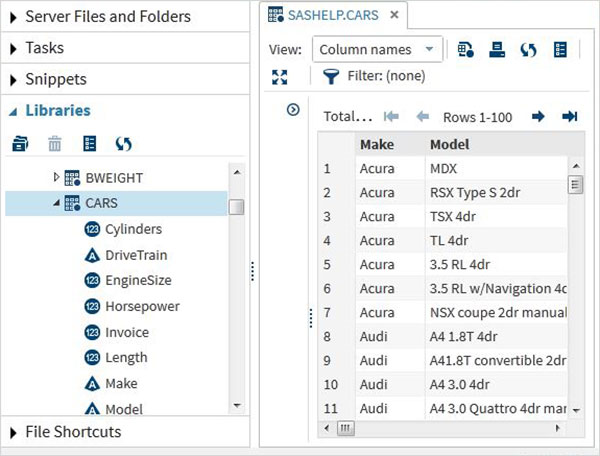
Прокрутите вниз, чтобы найти набор данных с именем CARS. Двойной щелчок по этому набору данных откроет его в правой части окна, где мы сможем изучить его дальше. Мы также можем свернуть левую панель, используя кнопку просмотра максимизации под правой панелью.
Мы можем прокрутить вправо, используя полосу прокрутки внизу, чтобы изучить все столбцы и их значения в таблице.
Импорт внешних наборов данных
Мы можем экспортировать наши собственные файлы в виде наборов данных с помощью функции импорта, доступной в SAS Studio. Но эти файлы должны быть доступны в папках сервера SAS. Таким образом, мы должны загрузить исходные файлы данных в папку SAS, используя опцию загрузки в разделе « Файлы и папки сервера» .
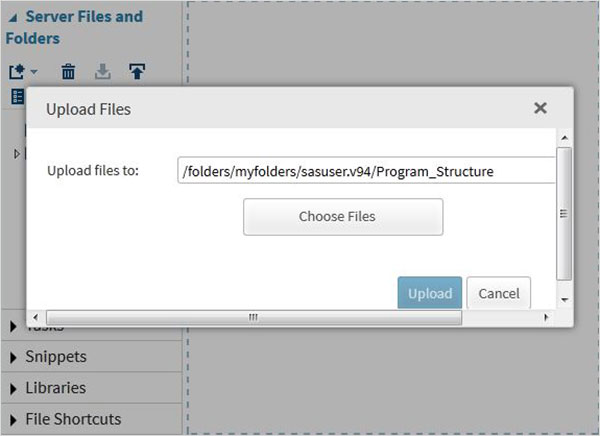
Далее мы используем указанный выше файл в программе SAS, импортируя его. Для этого мы используем опцию Задачи -> Утилиты -> Импорт данных, как показано ниже. Дважды щелкните кнопку «Импорт данных», которая откроет окно справа, чтобы выбрать файл для набора данных.
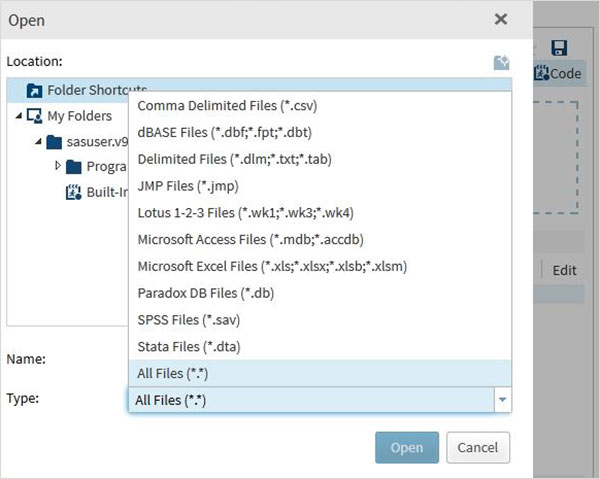
Далее Нажмите кнопку « Выбрать файлы» под программой импорта данных на правой панели. Ниже приведен список типов файлов, которые можно импортировать.
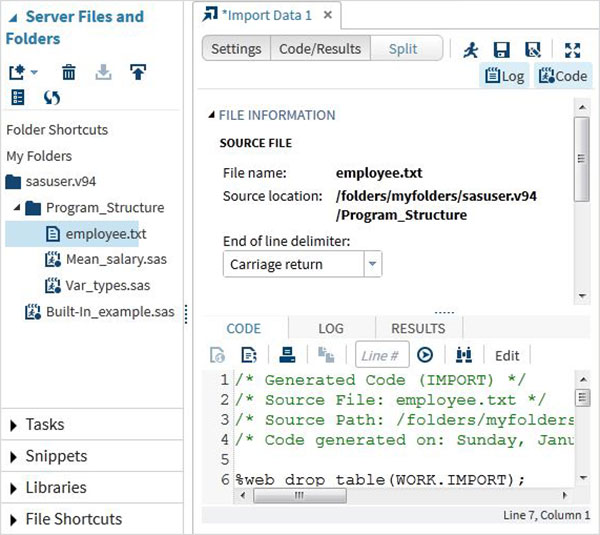
Мы выбираем файл employee.txt, хранящийся в локальной системе, и импортируем файл, как показано ниже.
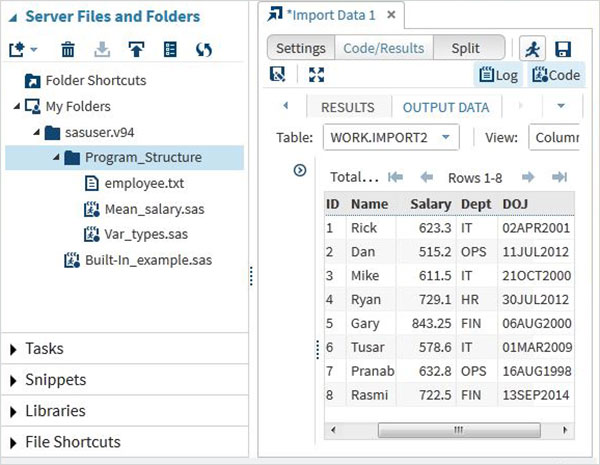
Просмотр импортированных данных
Мы можем просмотреть импортированные данные, запустив код импорта по умолчанию, созданный с помощью параметра «Выполнить».
Мы можем импортировать любые другие типы файлов, используя тот же подход, что и выше, и использовать его в различных программах SAS.
SAS — переменные
В общем случае переменные в SAS представляют имена столбцов таблиц данных, которые он анализирует. Но это также может быть использовано для других целей, таких как использование в качестве счетчика в цикле программирования. В текущей главе мы увидим использование переменных SAS в качестве имен столбцов набора данных SAS.
Типы переменных SAS
SAS имеет три типа переменных, как показано ниже:
Числовые переменные
Это тип переменной по умолчанию. Эти переменные используются в математических выражениях.
Синтаксис
INPUT VAR1 VAR2 VAR3; #Define numeric variables in the data set.
В приведенном выше синтаксисе оператор INPUT показывает объявление числовых переменных.
пример
INPUT ID SALARY COMM_PERCENT;
Символьные переменные
Символьные переменные используются для значений, которые не используются в математических выражениях. Они рассматриваются как текст или строки. Переменная становится символьной переменной, добавляя $ sing с пробелом в конце имени переменной.
Синтаксис
INPUT VAR1 $ VAR2 $ VAR3 $; #Define character variables in the data set.
В приведенном выше синтаксисе оператор INPUT показывает объявление символьных переменных.
пример
INPUT FNAME $ LNAME $ ADDRESS $;
Переменные даты
Эти переменные обрабатываются только как даты, и они должны быть в допустимых форматах даты. Переменная становится переменной даты, добавляя формат даты с пробелом в конце имени переменной.
Синтаксис
INPUT VAR1 DATE11. VAR2 MMDDYY10. ; #Define date variables in the data set.
В приведенном выше синтаксисе оператор INPUT показывает объявление переменных даты.
пример
INPUT DOB DATE11. START_DATE MMDDYY10. ;
Использование переменных в программе SAS
Перечисленные выше переменные используются в программе SAS, как показано в следующих примерах.
пример
Приведенный ниже код показывает, как три типа переменных объявляются и используются в программе SAS
DATA TEMP; INPUT ID NAME $ SALARY DEPT $ DOJ DATE9. ; FORMAT DOJ DATE9. ; DATALINES; 1 Rick 623.3 IT 02APR2001 2 Dan 515.2 OPS 11JUL2012 3 Michelle 611 IT 21OCT2000 4 Ryan 729 HR 30JUL2012 5 Gary 843.25 FIN 06AUG2000 6 Tusar 578 IT 01MAR2009 7 Pranab 632.8 OPS 16AUG1998 8 Rasmi 722.5 FIN 13SEP2014 ; PROC PRINT DATA = TEMP; RUN;
В приведенном выше примере все символьные переменные объявляются с последующим знаком $, а переменные даты объявляются с последующим форматом даты. Вывод вышеуказанной программы такой, как показано ниже.
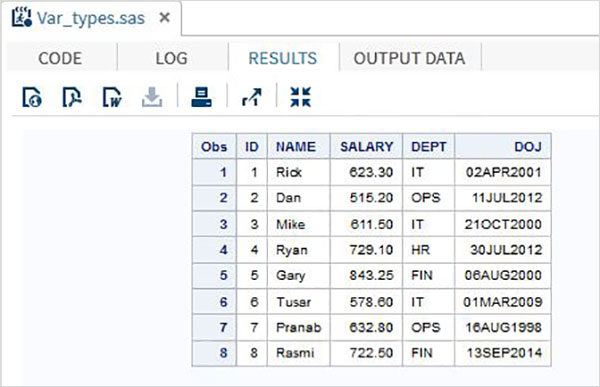
Использование переменных
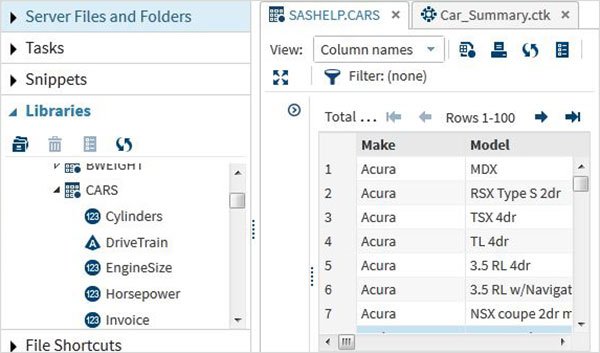
Переменные очень полезны при анализе данных. Они используются в выражениях, в которых применяется статистический анализ. Давайте рассмотрим пример анализа встроенного набора данных с именем CARS, который представлен в разделе Библиотеки → Мои библиотеки → SASHELP . Дважды щелкните по нему, чтобы изучить переменные и их типы данных.
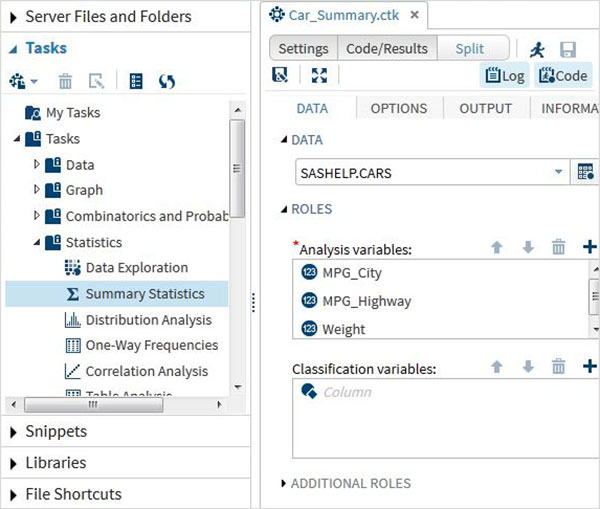
Затем мы можем получить сводную статистику по некоторым из этих переменных, используя параметры Задачи в SAS studio. Перейдите в Задачи -> Статистика -> Сводная статистика и дважды щелкните по ней, чтобы открыть окно, как показано ниже. Выберите набор данных SASHELP.CARS и выберите три переменные — MPG_CITY, MPG_Highway и Weight под переменными анализа. Удерживайте клавишу Ctrl при выборе переменных, нажав. Нажмите «Выполнить».
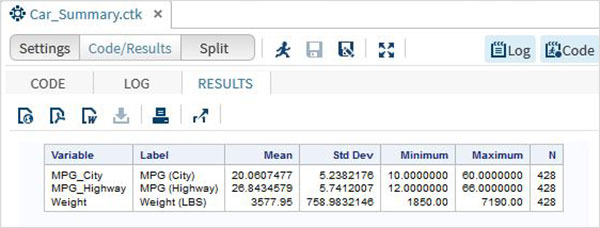
Нажмите на вкладку результатов после вышеуказанных шагов. Он показывает статистическую сводку трех выбранных переменных. В последнем столбце указано количество наблюдений (записей), использованных в анализе.
SAS — Струны
Строки в SAS — это значения, которые заключены в одинарные кавычки. Также строковые переменные объявляются путем добавления пробела и знака $ в конце объявления переменной. SAS имеет много мощных функций для анализа и манипулирования строками.
Объявление строковых переменных
Мы можем объявить строковые переменные и их значения, как показано ниже. В приведенном ниже коде мы объявляем две символьные переменные длиной 6 и 5. Ключевое слово LENGTH используется для объявления переменных без создания нескольких наблюдений.
data string_examples; LENGTH string1 $ 6 String2 $ 5; /*String variables of length 6 and 5 */ String1 = 'Hello'; String2 = 'World'; Joined_strings = String1 ||String2 ; run; proc print data = string_examples noobs; run;
Запустив приведенный выше код, мы получим вывод, который показывает имена переменных и их значения.
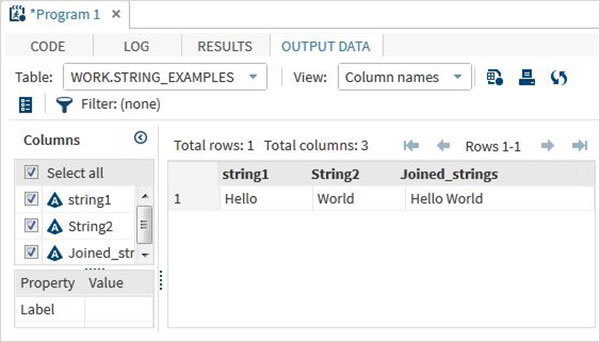
Строковые функции
Ниже приведены примеры некоторых функций SAS, которые часто используются.
SUBSTRN
Эта функция извлекает подстроку, используя начальную и конечную позиции. В случае отсутствия конечной позиции он извлекает все символы до конца строки.
Синтаксис
SUBSTRN('stringval',p1,p2)
Ниже приведено описание используемых параметров:
- stringval — это значение строковой переменной.
- p1 — начальная позиция извлечения.
- p2 — конечная позиция извлечения.
пример
data string_examples; LENGTH string1 $ 6 ; String1 = 'Hello'; sub_string1 = substrn(String1,2,4) ; /*Extract from position 2 to 4 */ sub_string2 = substrn(String1,3) ; /*Extract from position 3 onwards */ run; proc print data = string_examples noobs; run;
Запустив приведенный выше код, мы получаем вывод, который показывает результат функции substrn.
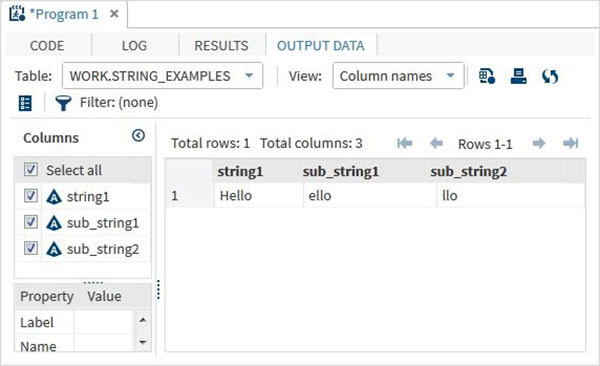
TRIMN
Эта функция удаляет завершающий пробел из строки.
Синтаксис
TRIMN('stringval')
Ниже приведено описание используемых параметров:
- stringval — это значение строковой переменной.
data string_examples; LENGTH string1 $ 7 ; String1='Hello '; length_string1 = lengthc(String1); length_trimmed_string = lengthc(TRIMN(String1)); run; proc print data = string_examples noobs; run;
Запустив приведенный выше код, мы получаем вывод, который показывает результат функции TRIMN.
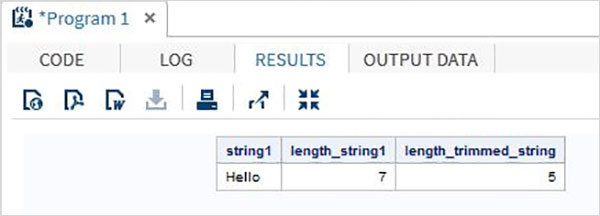
SAS — Массивы
Массивы в SAS используются для хранения и извлечения ряда значений с использованием значения индекса. Индекс представляет местоположение в зарезервированной области памяти.
Синтаксис
В SAS массив объявляется с использованием следующего синтаксиса —
ARRAY ARRAY-NAME(SUBSCRIPT) ($) VARIABLE-LIST ARRAY-VALUES
В приведенном выше синтаксисе —
-
ARRAY — это ключевое слово SAS для объявления массива.
-
ARRAY-NAME — это имя массива, которое следует тому же правилу, что и имена переменных.
-
SUBSCRIPT — это число значений, которые массив будет хранить.
-
($) является необязательным параметром, который используется только в том случае, если массив будет хранить символьные значения.
-
VARIABLE-LIST — необязательный список переменных, которые являются заполнителями для значений массива.
-
ARRAY-VALUES — это фактические значения, которые хранятся в массиве. Они могут быть объявлены здесь или могут быть прочитаны из файла или данных.
ARRAY — это ключевое слово SAS для объявления массива.
ARRAY-NAME — это имя массива, которое следует тому же правилу, что и имена переменных.
SUBSCRIPT — это число значений, которые массив будет хранить.
($) является необязательным параметром, который используется только в том случае, если массив будет хранить символьные значения.
VARIABLE-LIST — необязательный список переменных, которые являются заполнителями для значений массива.
ARRAY-VALUES — это фактические значения, которые хранятся в массиве. Они могут быть объявлены здесь или могут быть прочитаны из файла или данных.
Примеры декларации массива
Массивы могут быть объявлены разными способами с использованием приведенного выше синтаксиса. Ниже приведены примеры.
# Declare an array of length 5 named AGE with values. ARRAY AGE[5] (12 18 5 62 44); # Declare an array of length 5 named COUNTRIES with values starting at index 0. ARRAY COUNTRIES(0:8) A B C D E F G H I; # Declare an array of length 5 named QUESTS which contain character values. ARRAY QUESTS(1:5) $ Q1-Q5; # Declare an array of required length as per the number of values supplied. ARRAY ANSWER(*) A1-A100;
Доступ к значениям массива
Доступ к значениям, хранящимся в массиве, можно получить с помощью процедуры печати , как показано ниже. После того, как оно объявлено с использованием одного из вышеперечисленных методов, данные передаются с помощью оператора DATALINES.
DATA array_example; INPUT a1 $ a2 $ a3 $ a4 $ a5 $; ARRAY colours(5) $ a1-a5; mix = a1||'+'||a2; DATALINES; yello pink orange green blue ; RUN; PROC PRINT DATA = array_example; RUN;
Когда мы выполняем приведенный выше код, он дает следующий результат —
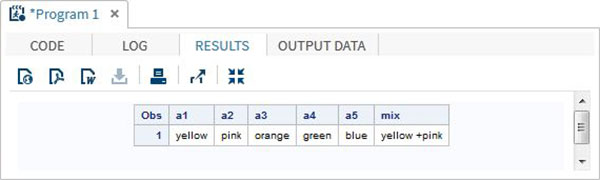
Использование оператора OF
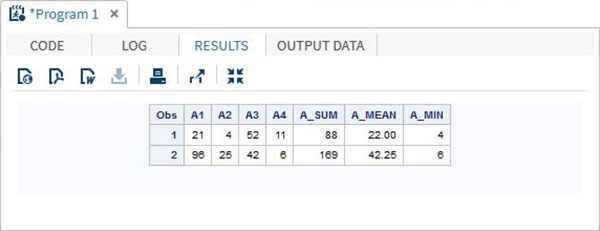
Оператор OF используется при анализе данных формата Array для выполнения вычислений по всей строке массива. В приведенном ниже примере мы применяем сумму и среднее значение в каждой строке.
DATA array_example_OF; INPUT A1 A2 A3 A4; ARRAY A(4) A1-A4; A_SUM = SUM(OF A(*)); A_MEAN = MEAN(OF A(*)); A_MIN = MIN(OF A(*)); DATALINES; 21 4 52 11 96 25 42 6 ; RUN; PROC PRINT DATA = array_example_OF; RUN;
Когда мы выполняем приведенный выше код, он дает следующий результат —
Использование оператора IN
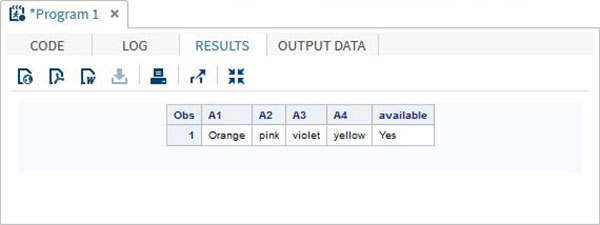
Доступ к значению в массиве также можно получить с помощью оператора IN, который проверяет наличие значения в строке массива. В приведенном ниже примере мы проверяем наличие цвета «Желтый» в данных. Это значение чувствительно к регистру.
DATA array_in_example; INPUT A1 $ A2 $ A3 $ A4 $; ARRAY COLOURS(4) A1-A4; IF 'yellow' IN COLOURS THEN available = 'Yes';ELSE available = 'No'; DATALINES; Orange pink violet yellow ; RUN; PROC PRINT DATA = array_in_example; RUN;
Когда мы выполняем приведенный выше код, он дает следующий результат —
SAS — Числовые форматы
SAS может обрабатывать различные форматы числовых данных. Эти форматы используются в конце имен переменных для применения определенного числового формата к данным. SAS использует два вида числовых форматов. Один для чтения определенных форматов числовых данных, который называется informat, и другой для отображения числовых данных в определенном формате, называемом выходным форматом .
Синтаксис
Синтаксис для числовой информации —
Varname Formatnamew.d
Ниже приведено описание используемых параметров:
-
Varname — это имя переменной.
-
Formatname — это имя имени числового формата, примененного к переменной.
-
w — максимальное количество столбцов данных (включая цифры после десятичной точки и саму десятичную точку), разрешенных для хранения для переменной.
-
d — количество цифр справа от десятичной дроби.
Varname — это имя переменной.
Formatname — это имя имени числового формата, примененного к переменной.
w — максимальное количество столбцов данных (включая цифры после десятичной точки и саму десятичную точку), разрешенных для хранения для переменной.
d — количество цифр справа от десятичной дроби.
Чтение Числовых форматов
Ниже приведен список форматов, используемых для чтения данных в SAS.
Числовые форматы ввода
| Формат | использование |
|---|---|
| п. |
Максимальное количество столбцов «n» без десятичной точки. |
| н.п. |
Максимальное количество столбцов с n-кратными точками «n». |
| COMMAn.p |
Максимальное число столбцов «n» с десятичными знаками «p», которое удаляет любые запятые или знаки доллара |
| COMMAn.p |
Максимальное число столбцов «n» с десятичными знаками «p», которое удаляет любые запятые или знаки доллара |
Максимальное количество столбцов «n» без десятичной точки.
Максимальное количество столбцов с n-кратными точками «n».
Максимальное число столбцов «n» с десятичными знаками «p», которое удаляет любые запятые или знаки доллара
Максимальное число столбцов «n» с десятичными знаками «p», которое удаляет любые запятые или знаки доллара
Отображение числовых форматов
Аналогично применению формата при чтении данных, ниже приведен список форматов, используемых для отображения данных в выходных данных программы SAS.
Числовые форматы вывода
| Формат | использование |
|---|---|
| п. |
Запишите максимальное количество цифр «n» без десятичной точки. |
| н.п. |
Запишите максимальное число столбцов «np» с десятичными точками «p». |
| DOLLARn.p |
Запишите максимальное число столбцов с «n» с p десятичными знаками, начальным знаком доллара и запятой на тысячном месте. |
Запишите максимальное количество цифр «n» без десятичной точки.
Запишите максимальное число столбцов «np» с десятичными точками «p».
Запишите максимальное число столбцов с «n» с p десятичными знаками, начальным знаком доллара и запятой на тысячном месте.
Пожалуйста, обратите внимание —
-
Если количество цифр после десятичной точки меньше спецификатора формата, то в конце будут добавлены нули .
-
Если количество цифр после десятичной точки больше, чем спецификатор формата, то последняя цифра округляется .
Если количество цифр после десятичной точки меньше спецификатора формата, то в конце будут добавлены нули .
Если количество цифр после десятичной точки больше, чем спецификатор формата, то последняя цифра округляется .
Примеры
Ниже приведены примеры, иллюстрирующие приведенные выше сценарии.
DATA MYDATA1; input x 6.; /*maxiiuum width of the data*/ format x 6.3; datalines; 8722 93.2 .1122 15.116 PROC PRINT DATA = MYDATA1; RUN; DATA MYDATA2; input x 6.; /*maximum width of the data*/ format x 5.2; datalines; 8722 93.2 .1122 15.116 PROC PRINT DATA = MYDATA2; RUN; DATA MYDATA3; input x 6.; /*maximum width of the data*/ format x DOLLAR10.2; datalines; 8722 93.2 .1122 15.116 PROC PRINT DATA = MYDATA3; RUN;
Когда мы выполняем приведенный выше код, он дает следующий результат —
# MYDATA1. Obs x 1 8722.0 # Display 6 columns with zero appended after decimal. 2 93.200 # Display 6 columns with zero appended after decimal. 3 0.112 # No integers before decimal, so display 3 available digits after decimal. 4 15.116 # Display 6 columns with 3 available digits after decimal. # MYDATA2 Obs x 1 8722 # Display 5 columns. Only 4 are available. 2 93.20 # Display 5 columns with zero appended after decimal. 3 0.11 # Display 5 columns with 2 places after decimal. 4 15.12 # Display 5 columns with 2 places after decimal. # MYDATA3 Obs x 1 $8,722.00 # Display 10 columns with leading $ sign, comma at thousandth place and zeros appended after decimal. 2 $93.20 # Only 2 integers available before decimal and one available after the decimal. 3 $0.11 # No integers available before decimal and two available after the decimal. 4 $15.12 # Only 2 integers available before decimal and two available after the decimal.
SAS — Операторы
Оператор в SAS — это символ, который используется в математическом, логическом или сравнительном выражении. Эти символы встроены в язык SAS, и многие операторы могут быть объединены в одном выражении для получения окончательного результата.
Ниже приведен список операторов категории SAS.
- Арифметические Операторы
- Логические Операторы
- Операторы сравнения
- Минимальные / максимальные операторы
- Оператор конкатенации
Мы рассмотрим каждый из них по одному. Операторы всегда используются с переменными, которые являются частью данных, которые анализируются программой SAS.
Арифметические Операторы
В приведенной ниже таблице описаны подробности арифметических операторов. Предположим, две переменные данных V1 и V2 со значениями 8 и 4 соответственно.
| оператор | Описание | пример |
|---|---|---|
| + | прибавление | V1 + V2 = 12 |
| — | Вычитание | V1-V2 = 4 |
| * | умножение | V1, V2, * = 32 |
| / | разделение | V1 / V2 = 2 |
| ** | Возведение | V1, V2, ** = 4096 |
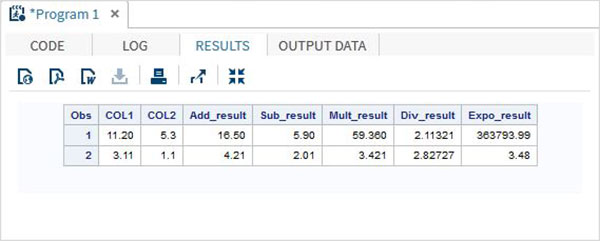
пример
DATA MYDATA1; input @1 COL1 4.2 @7 COL2 3.1; Add_result = COL1+COL2; Sub_result = COL1-COL2; Mult_result = COL1*COL2; Div_result = COL1/COL2; Expo_result = COL1**COL2; datalines; 11.21 5.3 3.11 11 ; PROC PRINT DATA = MYDATA1; RUN;
Запустив приведенный выше код, мы получим следующий вывод.
Логические Операторы
В приведенной ниже таблице описаны детали логических операторов. Эти операторы оценивают значение Истины выражения. Таким образом, результатом логических операторов всегда является 1 или 0. Предположим, что две переменные данных V1 и V2 со значениями 8 и 4 соответственно.
| оператор | Описание | пример |
|---|---|---|
| & | Оператор AND Если оба значения данных имеют значение true, то результат равен 1, иначе он равен 0. | (V1> 2 и V2> 3) дает 0. |
| | | Оператор ИЛИ. Если какое-либо из значений данных оценивается как истинное, то результатом будет 1, иначе 0. | (V1> 9 и V2> 3) равно 1. |
| ~ | НЕ оператор. Результат оператора NOT в форме выражения, значение которого равно FALSE или отсутствует, равен 1, в противном случае он равен 0. | НЕ (V1> 3) равно 1. |
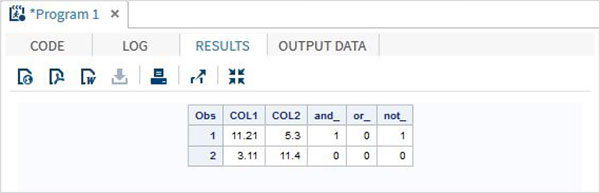
пример
DATA MYDATA1; input @1 COL1 5.2 @7 COL2 4.1; and_=(COL1 > 10 & COL2 > 5 ); or_ = (COL1 > 12 | COL2 > 15 ); not_ = ~( COL2 > 7 ); datalines; 11.21 5.3 3.11 11.4 ; PROC PRINT DATA = MYDATA1; RUN;
Запустив приведенный выше код, мы получим следующий вывод.
Операторы сравнения
В приведенной ниже таблице описаны подробности операторов сравнения. Эти операторы сравнивают значения переменных, и результатом является значение истинности, представленное 1 для ИСТИНЫ и 0 для Ложного. Предположим, две переменные данных V1 и V2 со значениями 8 и 4 соответственно.
| оператор | Описание | пример |
|---|---|---|
| знак равно | РАВНЫЙ Оператор. Если оба значения данных равны, то результат равен 1, иначе он равен 0. | (V1 = 8) дает 1. |
| ^ = | НЕ РАВНЫЙ оператор. Если оба значения данных неравны, то результат равен 1, иначе это 0. | (V1 ^ = V2) дает 1. |
| < | Меньше чем оператор. | (V2 <V2) дает 1. |
| <= | МЕНЬШЕ, ЧЕМ ИЛИ РАВНОЕ Оператору. | (V2 <= 4) дает 1. |
| > | БОЛЬШЕ, ЧЕМ Оператор. | (V2> V1) дает 1. |
| > = | БОЛЬШЕ, ЧЕМ или РАВНО ДЛЯ Оператора. | (V2> = V1) дает 0. |
| В | Оператор IN. Если значение переменной равно любому из значений в данном списке значений, то оно возвращает 1, иначе оно возвращает 0. | V1 в (5,7,9,8) дает 1. |
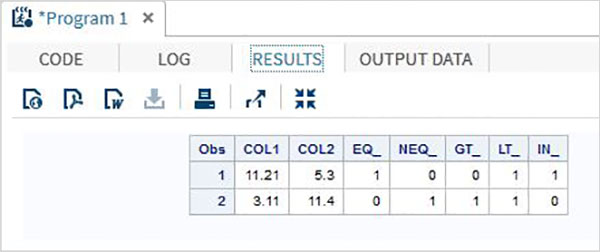
пример
DATA MYDATA1; input @1 COL1 5.2 @7 COL2 4.1; EQ_ = (COL1 = 11.21); NEQ_= (COL1 ^= 11.21); GT_ = (COL2 => 8); LT_ = (COL2 <= 12); IN_ = COL2 in( 6.2,5.3,12 ); datalines; 11.21 5.3 3.11 11.4 ; PROC PRINT DATA = MYDATA1; RUN;
Запустив приведенный выше код, мы получим следующий вывод.
Минимальные / максимальные операторы
В приведенной ниже таблице описаны детали операторов Minimum / Maximum. Эти операторы сравнивают значения переменных в строке, и возвращается минимальное или максимальное значение из списка значений в строках.
| оператор | Описание | пример |
|---|---|---|
| MIN | Оператор МИН. Возвращает минимальное значение из списка значений в строке. | MIN (45,2,11,6,15,41) дает 11,6 |
| МАКСИМУМ | МАКС Оператор. Возвращает максимальное значение из списка значений в строке. | Макс (45,2,11,6,15,41) дает 45,2 |
пример
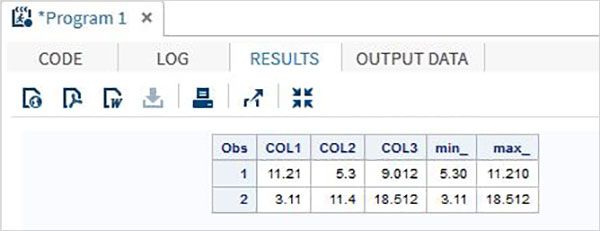
DATA MYDATA1; input @1 COL1 5.2 @7 COL2 4.1 @12 COL3 6.3; min_ = MIN(COL1 , COL2 , COL3); max_ = MAX( COL1, COl2 , COL3); datalines; 11.21 5.3 29.012 3.11 11.4 18.512 ; PROC PRINT DATA = MYDATA1; RUN;
Запустив приведенный выше код, мы получим следующий вывод.
Оператор конкатенации
В приведенной ниже таблице описаны подробности оператора конкатенации. Этот оператор объединяет два или более строковых значения. Возвращается однозначное значение
| оператор | Описание | пример |
|---|---|---|
| || | Оператор сцепления. Возвращает объединение двух или более значений. | ‘Hello’ ||» Мир ‘дает Hello World |
пример
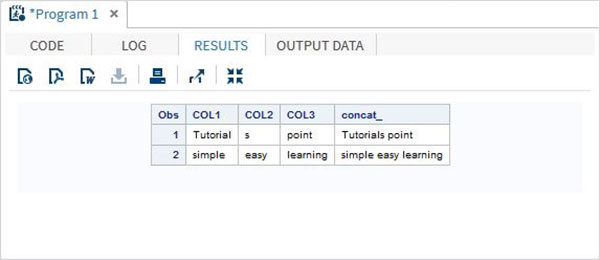
DATA MYDATA1; input COL1 $ COL2 $ COL3 $; concat_ = (COL1 || COL2 || COL3); datalines; Tutorial s point simple easy learning ; PROC PRINT DATA = MYDATA1; RUN;
Запустив приведенный выше код, мы получим следующий вывод.
Приоритет операторов
Приоритет оператора указывает порядок вычисления нескольких операторов, присутствующих в сложном выражении. В приведенной ниже таблице описан порядок приоритета в группе операторов.
| группа | порядок | Символы |
|---|---|---|
| Группа I | Справа налево | ** + — НЕ МИН МАКС |
| Группа II | Слева направо | * / |
| Группа III | Слева направо | + — |
| Группа IV | Слева направо | || |
| Группа V | Слева направо | <<= => => |
SAS — Петли
Вы можете столкнуться с ситуациями, когда блок кода должен выполняться несколько раз. В общем случае операторы выполняются последовательно: первый оператор в функции выполняется первым, затем второй и так далее. Но когда вы хотите, чтобы один и тот же набор операторов выполнялся снова и снова, нам нужна помощь Loops.
В SAS цикл выполняется с помощью оператора DO. Это также называется DO Loop . Ниже приведен общий вид операторов цикла DO в SAS.
Схема потока

Ниже приведены типы циклов DO в SAS.
| Sr.No. | Тип и описание петли |
|---|---|
| 1 | DO индекс.
Цикл продолжается от начального значения до конечного значения индексной переменной. |
| 2 | ДЕЛАТЬ ПОКА.
Цикл продолжается до тех пор, пока условие не станет ложным. |
| 3 | ДЕЛАЙТЕ ДО
Цикл продолжается до тех пор, пока условие UNTIL не станет True. |
Цикл продолжается от начального значения до конечного значения индексной переменной.
Цикл продолжается до тех пор, пока условие не станет ложным.
Цикл продолжается до тех пор, пока условие UNTIL не станет True.
SAS — принятие решений
Структуры принятия решений требуют, чтобы программист указал одно или несколько условий, которые должны быть оценены или протестированы программой, вместе с оператором или инструкциями, которые должны быть выполнены, если условие определено как истинное , и, необязательно, другие операторы, которые должны быть выполнены, если условие определяется как ложный .
Ниже приводится общая форма типичной структуры принятия решений, встречающейся в большинстве языков программирования.
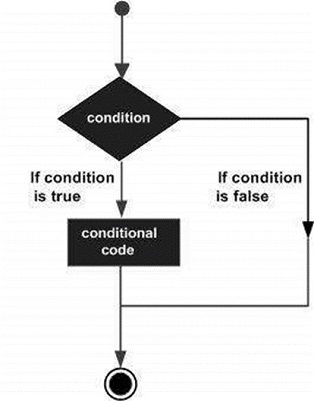
SAS предоставляет следующие типы заявлений о принятии решений. Нажмите на следующие ссылки, чтобы проверить их детали.
| Sr.No. | Тип заявления и описание |
|---|---|
| 1 | Если заявление.
Оператор if состоит из условия. Если условие истинно, то выбираются конкретные данные. |
| 2 | IF-THEN-ELSE Заявление.
Оператор if, за которым следует оператор else, который выполняется, когда логическое условие ложно. |
| 3 | IF-THEN-ELSE-IF Заявление.
Оператор if, за которым следует оператор else, за которым снова следует другая пара операторов IF-THEN. |
| 4 | IF-THEN-DELETE Заявление.
Оператор if состоит из условия, которое при истечении удаляет конкретные данные из наблюдений. |
Оператор if состоит из условия. Если условие истинно, то выбираются конкретные данные.
Оператор if, за которым следует оператор else, который выполняется, когда логическое условие ложно.
Оператор if, за которым следует оператор else, за которым снова следует другая пара операторов IF-THEN.
Оператор if состоит из условия, которое при истечении удаляет конкретные данные из наблюдений.
SAS — Функции
SAS имеет широкий спектр встроенных функций, которые помогают в анализе и обработке данных. Эти функции используются как часть операторов DATA. Они принимают переменные данных в качестве аргументов и возвращают результат, который сохраняется в другой переменной. В зависимости от типа функции количество аргументов, которые она принимает, может варьироваться. Некоторые функции принимают нулевые аргументы, в то время как другие принимают фиксированное число переменных. Ниже приведен список типов функций, которые предоставляет SAS.
Синтаксис
Общий синтаксис использования функции в SAS приведен ниже.
FUNCTIONNAME(argument1, argument2...argumentn)
Здесь аргумент может быть константой, переменной, выражением или другой функцией.
Категории функций
В зависимости от их использования функции в SAS классифицируются следующим образом.
- математическая
- Дата и время
- символ
- сокращение
- Разнообразный
Математические функции
Эти функции используются для применения некоторых математических вычислений к значениям переменных.
Примеры
В приведенной ниже программе SAS показано использование некоторых важных математических функций.
data Math_functions;
v1=21; v2=42; v3=13; v4=10; v5=29; /* Get Maximum value */ max_val = MAX(v1,v2,v3,v4,v5); /* Get Minimum value */ min_val = MIN (v1,v2,v3,v4,v5); /* Get Median value */ med_val = MEDIAN (v1,v2,v3,v4,v5); /* Get a random number */ rand_val = RANUNI(0); /* Get Square root of sum of the values */ SR_val= SQRT(sum(v1,v2,v3,v4,v5)); proc print data = Math_functions noobs; run;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
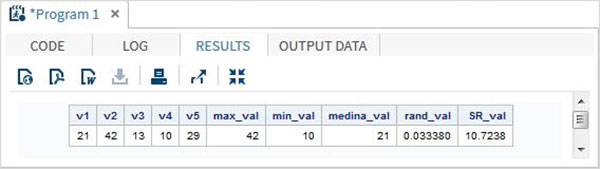
Функции даты и времени
Эти функции используются для обработки значений даты и времени.
Примеры
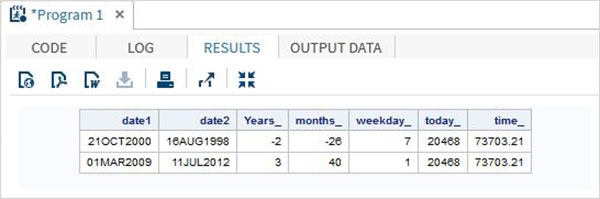
В приведенной ниже программе SAS показано использование функций даты и времени.
data date_functions; INPUT @1 date1 date9. @11 date2 date9.; format date1 date9. date2 date9.; /* Get the interval between the dates in years*/ Years_ = INTCK('YEAR',date1,date2); /* Get the interval between the dates in months*/ months_ = INTCK('MONTH',date1,date2); /* Get the week day from the date*/ weekday_ = WEEKDAY(date1); /* Get Today's date in SAS date format */ today_ = TODAY(); /* Get current time in SAS time format */ time_ = time(); DATALINES; 21OCT2000 16AUG1998 01MAR2009 11JUL2012 ; proc print data = date_functions noobs; run;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
Функции персонажа
Это функции, используемые для обработки символьных или текстовых значений.
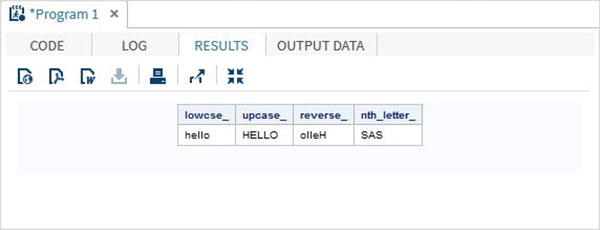
Примеры
В приведенной ниже программе SAS показано использование символьных функций.
data character_functions; /* Convert the string into lower case */ lowcse_ = LOWCASE('HELLO'); /* Convert the string into upper case */ upcase_ = UPCASE('hello'); /* Reverse the string */ reverse_ = REVERSE('Hello'); /* Return the nth word */ nth_letter_ = SCAN('Learn SAS Now',2); run; proc print data = character_functions noobs; run;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
Функции усечения
Эти функции используются для усечения числовых значений.
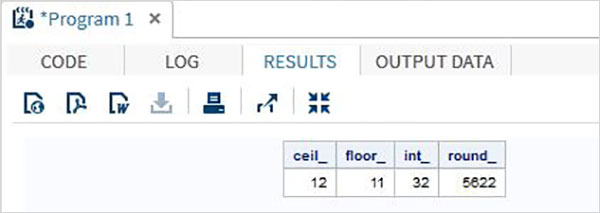
Примеры
В приведенной ниже программе SAS показано использование функций усечения.
data trunc_functions; /* Nearest greatest integer */ ceil_ = CEIL(11.85); /* Nearest greatest integer */ floor_ = FLOOR(11.85); /* Integer portion of a number */ int_ = INT(32.41); /* Round off to nearest value */ round_ = ROUND(5621.78); run; proc print data = trunc_functions noobs; run;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
Разные функции
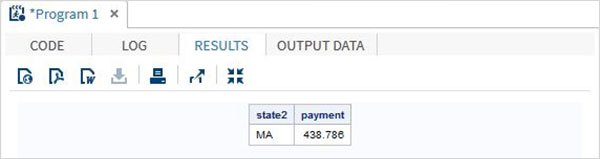
Давайте теперь разберемся с различными функциями SAS на нескольких примерах.
Примеры
В приведенной ниже программе SAS показано использование различных функций.
data misc_functions; /* Nearest greatest integer */ state2=zipstate('01040'); /* Amortization calculation */ payment = mort(50000, . , .10/12,30*12); proc print data = misc_functions noobs; run;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
SAS — Методы ввода
Методы ввода используются для чтения необработанных данных. Необработанные данные могут быть из внешнего источника или из потоковых данных. Оператор ввода создает переменную с именем, которое вы назначаете каждому полю. Таким образом, вы должны создать переменную в операторе ввода. Эта же переменная будет показана в выходных данных набора данных SAS. Ниже приведены различные методы ввода, доступные в SAS.
- Метод ввода списка
- Именованный метод ввода
- Метод ввода столбца
- Форматированный метод ввода
Детали каждого метода ввода описаны ниже.
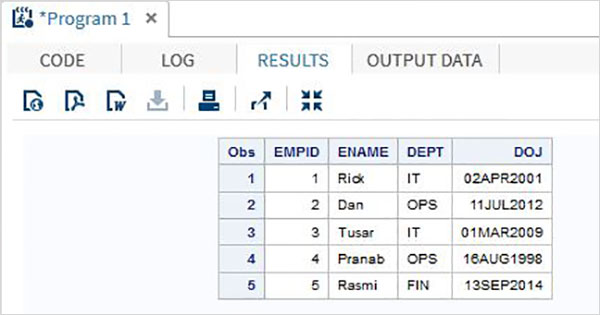
Метод ввода списка
В этом методе переменные перечислены с типами данных. Необработанные данные тщательно анализируются, чтобы порядок объявленных переменных соответствовал данным. Разделитель (обычно пробел) должен быть одинаковым между любой парой соседних столбцов. Любые недостающие данные вызовут проблемы в выводе, поскольку результат будет неправильным.
пример
Следующий код и выходные данные показывают использование метода ввода списка.
DATA TEMP; INPUT EMPID ENAME $ DEPT $ ; DATALINES; 1 Rick IT 2 Dan OPS 3 Tusar IT 4 Pranab OPS 5 Rasmi FIN ; PROC PRINT DATA = TEMP; RUN;
Запустив код bove, мы получим следующий вывод.
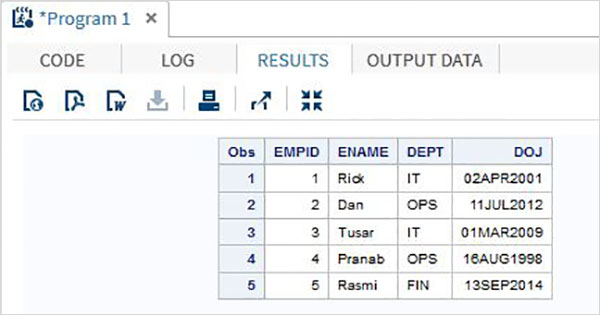
Именованный метод ввода
В этом методе переменные перечислены с типами данных. Необработанные данные модифицируются, чтобы имена переменных объявлялись перед соответствующими данными. Разделитель (обычно пробел) должен быть одинаковым между любой парой соседних столбцов.
пример
Следующий код и выходные данные показывают использование именованного метода ввода.
DATA TEMP; INPUT EMPID= ENAME= $ DEPT= $ ; DATALINES; EMPID = 1 ENAME = Rick DEPT = IT EMPID = 2 ENAME = Dan DEPT = OPS EMPID = 3 ENAME = Tusar DEPT = IT EMPID = 4 ENAME = Pranab DEPT = OPS EMPID = 5 ENAME = Rasmi DEPT = FIN ; PROC PRINT DATA = TEMP; RUN;
Запустив код bove, мы получим следующий вывод.
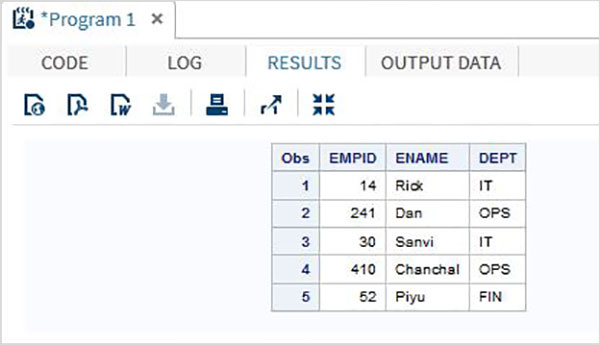
Метод ввода столбца
В этом методе переменные перечисляются с типами данных и шириной столбцов, которые определяют значение одного столбца данных. Например, если имя сотрудника содержит максимум 9 символов, а имя каждого сотрудника начинается с 10-го столбца, то ширина столбца для переменной имени сотрудника будет 10-19.
пример
Следующий код показывает использование метода ввода столбцов.
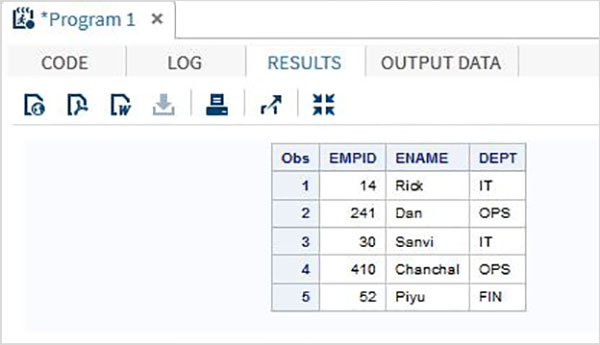
DATA TEMP; INPUT EMPID 1-3 ENAME $ 4-12 DEPT $ 13-16; DATALINES; 14 Rick IT 241Dan OPS 30 Sanvi IT 410Chanchal OPS 52 Piyu FIN ; PROC PRINT DATA = TEMP; RUN;
Когда мы выполняем приведенный выше код, он дает следующий результат —
Форматированный метод ввода
В этом методе переменные считываются из фиксированной начальной точки, пока не встретится пробел. Поскольку каждая переменная имеет фиксированную начальную точку, число столбцов между любой парой переменных становится шириной первой переменной. Символ ‘@n’ используется для указания начальной позиции столбца переменной в качестве n-го столбца.
пример
Следующий код показывает использование форматированного метода ввода
DATA TEMP; INPUT @1 EMPID $ @4 ENAME $ @13 DEPT $ ; DATALINES; 14 Rick IT 241 Dan OPS 30 Sanvi IT 410 Chanchal OPS 52 Piyu FIN ; PROC PRINT DATA = TEMP; RUN;
Когда мы выполняем приведенный выше код, он дает следующий результат —
SAS — Макросы
SAS имеет мощную функцию программирования под названием Macros, которая позволяет нам избегать повторяющихся участков кода и использовать их снова и снова, когда это необходимо. Это также помогает создавать в коде динамические переменные, которые могут принимать разные значения для разных экземпляров прогона одного и того же кода. Макросы также могут быть объявлены для блоков кода, которые будут многократно использоваться аналогично макропеременным. Мы увидим оба из них в следующих примерах.
Макропеременные
Это переменные, которые содержат значение, которое будет снова и снова использоваться программой SAS. Они объявляются в начале программы SAS и вызываются позже в основной части программы. Они могут быть глобальными или локальными по объему.
Глобальная макро-переменная
Их называют глобальными макропеременными, потому что к ним может обращаться любая программа SAS, доступная в среде SAS. Как правило, это системные переменные, к которым обращаются несколько программ. Общий пример — системная дата.
пример
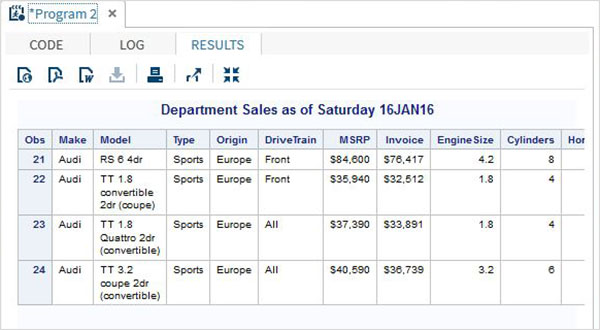
Ниже приведен пример переменной SAS с именем SYSDATE, которая представляет системную дату. Рассмотрим сценарий для печати системной даты в заголовке отчета SAS каждый день, когда отчет генерируется. Заголовок покажет текущую дату и день без кодирования каких-либо значений для них. Мы используем встроенный набор данных SAS под названием CARS, доступный в библиотеке SASHELP.
proc print data = sashelp.cars; where make = 'Audi' and type = 'Sports' ; TITLE "Sales as of &SYSDAY &SYSDATE"; run;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Локальная переменная макроса
Эти переменные могут быть доступны для программ SAS, в которых они объявлены как часть программы. Они, как правило, используются для предоставления разных varaibels одним и тем же операторам SAS, чтобы они могли обрабатывать разные наблюдения набора данных.
Синтаксис
Локальные переменные имеют декальтарный синтаксис.
% LET (Macro Variable Name) = Value;
Здесь поле «Значение» может принимать любое числовое, текстовое значение или значение даты, как того требует программа. Имя макрокоманды — это любая допустимая переменная SAS.
пример
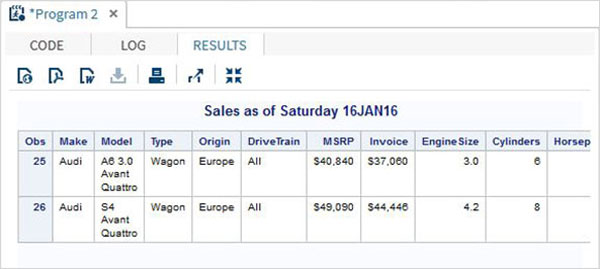
Переменные используются операторами SAS с использованием символа &, добавляемого в начале имени переменной. Ниже программа собирает все наблюдения за маркой «Ауди» и типом «Спорт». В случае, если мы хотим получить результат другого make , нам нужно изменить значение переменной make_name без изменения какой-либо другой части программы. В случае программ переноса эта переменная может быть снова и снова указана в любых операторах SAS.
%LET make_name = 'Audi'; %LET type_name = 'Sports'; proc print data = sashelp.cars; where make = &make_name and type = &type_name ; TITLE "Sales as of &SYSDAY &SYSDATE"; run;
Когда приведенный выше код выполняется, мы получаем тот же вывод, что и предыдущая программа. Но давайте изменим имя типа на «Wagon» и запустим ту же программу. Мы получим следующий результат.
Макро Программы
Макрос — это группа операторов SAS, на которые ссылается имя и которые можно использовать в программе где угодно, используя это имя. Он начинается с оператора% MACRO и заканчивается оператором% MEND.
Синтаксис
Локальные переменные объявлены с синтаксисом ниже.
# Creating a Macro program. %MACRO <macro name>(Param1, Param2,….Paramn); Macro Statements; %MEND; # Calling a Macro program. %MacroName (Value1, Value2,…..Valuen);
пример
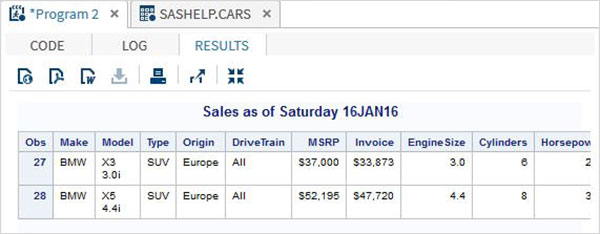
Приведенная ниже программа декальзирует группу STAT-сетей SAT под макросом с именем ‘show_result’; Этот макрос вызывается другими операторами SAS.
%MACRO show_result(make_ , type_); proc print data = sashelp.cars; where make = "&make_" and type = "&type_" ; TITLE "Sales as of &SYSDAY &SYSDATE"; run; %MEND; %show_result(BMW,SUV);
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Обычно используемые макросы
SAS имеет много операторов MACRO, которые встроены в язык программирования SAS. Они используются другими программами SAS без явного объявления их. Общими примерами являются: завершение программы при выполнении какого-либо условия или запись значения переменной времени выполнения в журнал программы. Ниже приведены некоторые примеры.
Макро% PUT
Этот оператор макроса записывает текстовую или макропеременную информацию в журнал SAS. В приведенном ниже примере значение переменной «сегодня» записывается в журнал программы.
data _null_;
CALL SYMPUT ('today',
TRIM(PUT("&sysdate"d,worddate22.)));
run;
%put &today;
Когда приведенный выше код выполняется, мы получаем следующий вывод.

Макро% ВОЗВРАТ
Выполнение этого макроса вызывает нормальное завершение текущего выполняющегося макроса, когда определенное условие оценивается как истинное. В приведенном ниже примере, когда значение переменной «val» становится равным 10, макрос завершается, в противном случае он продолжается.
%macro check_condition(val);
%if &val = 10 %then %return;
data p;
x = 34.2;
run;
%mend check_condition;
%check_condition(11) ;
Когда приведенный выше код выполняется, мы получаем следующий вывод.

Макро% КОНЕЦ
Это макроопределение содержит цикл % DO% WHILE, который заканчивается, как требуется, оператором% END. В приведенном ниже примере макрос с именем test принимает пользовательский ввод и запускает цикл DO, используя это входное значение. Завершение цикла DO достигается с помощью оператора% end, в то время как конец макроса достигается с помощью оператора% mend.
%macro test(finish);
%let i = 1;
%do %while (&i <&finish);
%put the value of i is &i;
%let i=%eval(&i+1);
%end;
%mend test;
%test(5)
Когда приведенный выше код выполняется, мы получаем следующий вывод.

SAS — дата и время
IN SAS даты являются частным случаем числовых значений. Каждому дню присваивается определенное числовое значение, начиная с 1 января 1960 года. Этой дате присваивается значение даты 0, а следующей дате присваивается значение даты 1 и т. Д. Предыдущие дни до этой даты представлены -1, -2 и так далее. При таком подходе SAS может представлять любую дату в будущем и любую дату в прошлом.
Когда SAS читает данные из источника, он преобразует прочитанные данные в определенный формат даты, как указано в формате даты. Переменная для хранения значения даты объявляется с необходимой информацией. Дата вывода отображается с использованием форматов выходных данных.
SAS Date Informat
Исходные данные могут быть прочитаны надлежащим образом с использованием определенных данных даты, как показано ниже. Цифра в конце информата указывает минимальную ширину строки даты, которая должна быть полностью прочитана с использованием информата. Меньшая ширина даст неверный результат. в SAS V9 существует общий формат даты anydtdte15. который может обрабатывать любой ввод даты.
| Дата ввода | Ширина даты | Informat |
|---|---|---|
| 03/11/2014 | 10 | mmddyy10. |
| 03/11/14 | 8 | mmddyy8. |
| 11 декабря 2012 г. | 20 | worddate20. |
| 14mar2011 | 9 | date9. |
| 14-мар-2011 | 11 | date11. |
| 14-мар-2011 | 15 | anydtdte15. |
пример
Код ниже показывает чтение различных форматов даты. Обратите внимание, что все выходные значения являются просто числами, так как мы не применили никакого оператора формата к выходным значениям.
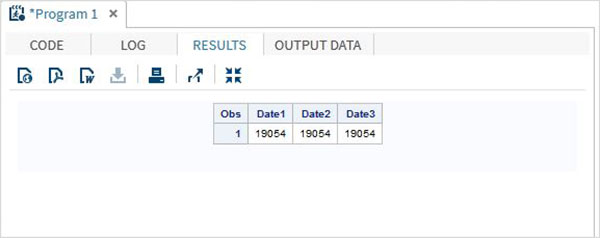
DATA TEMP; INPUT @1 Date1 date11. @12 Date2 anydtdte15. @23 Date3 mmddyy10. ; DATALINES; 02-mar-2012 3/02/2012 3/02/2012 ; PROC PRINT DATA = TEMP; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Формат вывода даты SAS
Даты после прочтения могут быть преобразованы в другой формат в соответствии с требованиями дисплея. Это достигается с помощью оператора формата для типов даты. Они принимают те же форматы, что и информаторы.
пример
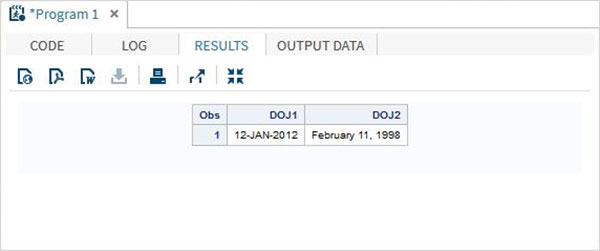
В приведенном ниже примере дата читается в одном формате, но отображается в другом формате.
DATA TEMP; INPUT @1 DOJ1 mmddyy10. @12 DOJ2 mmddyy10.; format DOJ1 date11. DOJ2 worddate20. ; DATALINES; 01/12/2012 02/11/1998 ; PROC PRINT DATA = TEMP; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
SAS — чтение необработанных данных
SAS может читать данные из различных источников, которые включают в себя множество форматов файлов. Форматы файлов, используемые в среде SAS, обсуждаются ниже.
- ASCII (текстовый) набор данных
- Данные с разделителями
- Данные Excel
- Иерархические данные
Чтение ASCII (текстового) набора данных
Это файлы, которые содержат данные в текстовом формате. Данные обычно разделяются пробелом, но также могут быть разные типы разделителей, с которыми может работать SAS. Давайте рассмотрим файл ASCII, содержащий данные о сотрудниках. Мы читаем этот файл, используя инструкцию Infile, доступную в SAS.
пример
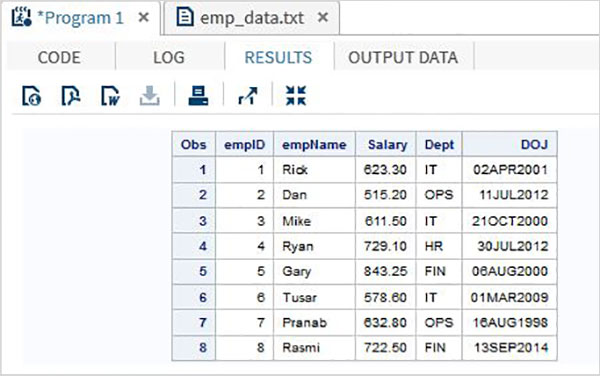
В приведенном ниже примере мы читаем файл данных с именем emp_data.txt из локальной среды.
data TEMP; infile '/folders/myfolders/sasuser.v94/TutorialsPoint/emp_data.txt'; input empID empName $ Salary Dept $ DOJ date9. ; format DOJ date9.; run; PROC PRINT DATA = TEMP; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Чтение данных с разделителями
Это файлы данных, в которых значения столбцов разделены символом-разделителем, таким как запятая, конвейер и т. Д. В этом случае мы используем опцию dlm в операторе infile .
пример
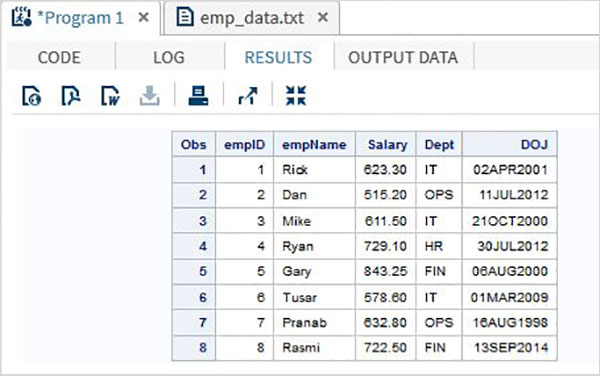
В приведенном ниже примере мы читаем файл данных с именем emp.csv из локальной среды.
data TEMP; infile '/folders/myfolders/sasuser.v94/TutorialsPoint/emp.csv' dlm=","; input empID empName $ Salary Dept $ DOJ date9. ; format DOJ date9.; run; PROC PRINT DATA = TEMP; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Чтение данных Excel
SAS может напрямую читать файл Excel с помощью средства импорта. Как видно из главы «Наборы данных SAS», он может обрабатывать самые разные типы файлов, включая MS Excel. Предполагая, что файл emp.xls доступен локально в среде SAS.
пример
FILENAME REFFILE "/folders/myfolders/TutorialsPoint/emp.xls" TERMSTR = CR; PROC IMPORT DATAFILE = REFFILE DBMS = XLS OUT = WORK.IMPORT; GETNAMES = YES; RUN; PROC PRINT DATA = WORK.IMPORT RUN;
Приведенный выше код считывает данные из файла Excel и выдает тот же вывод, что и выше, для двух типов файлов.
Чтение Иерархических Файлов
В этих файлах данные представлены в иерархическом формате. Для данного наблюдения есть запись заголовка, ниже которой упоминается много подробных записей. Количество записей подробностей может варьироваться от одного наблюдения к другому. Ниже приведена иллюстрация иерархического файла.
В приведенном ниже файле перечислены данные каждого сотрудника в каждом отделе. Первая запись — это запись заголовка с указанием отдела, а следующая запись, несколько записей, начинающихся с DTLS, — запись сведений.
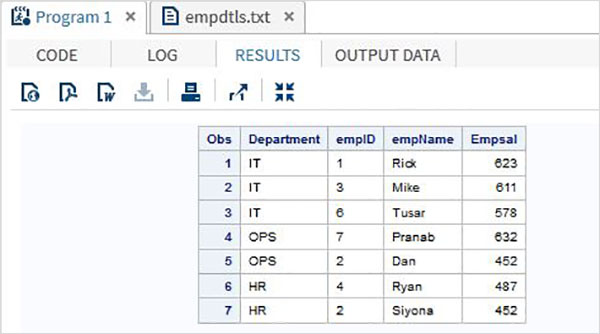
DEPT:IT DTLS:1:Rick:623 DTLS:3:Mike:611 DTLS:6:Tusar:578 DEPT:OPS DTLS:7:Pranab:632 DTLS:2:Dan:452 DEPT:HR DTLS:4:Ryan:487 DTLS:2:Siyona:452
пример
Чтобы прочитать иерархический файл, мы используем приведенный ниже код, в котором мы идентифицируем запись заголовка с помощью предложения IF и используем цикл do для обработки записи сведений.
data employees(drop = Type);
length Type $ 3 Department
empID $ 3 empName $ 10 Empsal 3 ;
retain Department;
infile
'/folders/myfolders/TutorialsPoint/empdtls.txt' dlm = ':';
input Type $ @;
if Type = 'DEP' then
input Department $;
else do;
input empID empName $ Empsal ;
output;
end;
run;
PROC PRINT DATA = employees;
RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
SAS — запись наборов данных
Подобно чтению наборов данных, SAS может записывать наборы данных в разных форматах. Он может записывать данные из файлов SAS в обычный текстовый файл. Эти файлы могут быть прочитаны другими программами. SAS использует PROC EXPORT для записи наборов данных.
ПРОЦ ЭКСПОРТ
Это встроенная процедура SAS, используемая для экспорта наборов данных SAS для записи данных в файлы различных форматов.
Синтаксис
Основной синтаксис для написания процедуры в SAS —
PROC EXPORT DATA = libref.SAS data-set (SAS data-set-options) OUTFILE = "filename" DBMS = identifier LABEL(REPLACE);
Ниже приведено описание используемых параметров:
-
Набор данных SAS — это имя набора данных, который экспортируется. SAS может обмениваться наборами данных из своей среды с другими приложениями, создавая файлы, которые могут быть прочитаны различными операционными системами. Он использует встроенную функцию EXPORT для вывода файлов набора данных в различных форматах. В этой главе мы увидим написание наборов данных SAS с использованием proc export вместе с опциями dlm и dbms .
-
Параметры набора данных SAS используются для указания подмножества экспортируемых столбцов.
-
filename — это имя файла, в который записываются данные.
-
идентификатор используется для упоминания разделителя, который будет записан в файл.
-
Опция LABEL используется для указания имени переменных, записанных в файл.
Набор данных SAS — это имя набора данных, который экспортируется. SAS может обмениваться наборами данных из своей среды с другими приложениями, создавая файлы, которые могут быть прочитаны различными операционными системами. Он использует встроенную функцию EXPORT для вывода файлов набора данных в различных форматах. В этой главе мы увидим написание наборов данных SAS с использованием proc export вместе с опциями dlm и dbms .
Параметры набора данных SAS используются для указания подмножества экспортируемых столбцов.
filename — это имя файла, в который записываются данные.
идентификатор используется для упоминания разделителя, который будет записан в файл.
Опция LABEL используется для указания имени переменных, записанных в файл.
пример
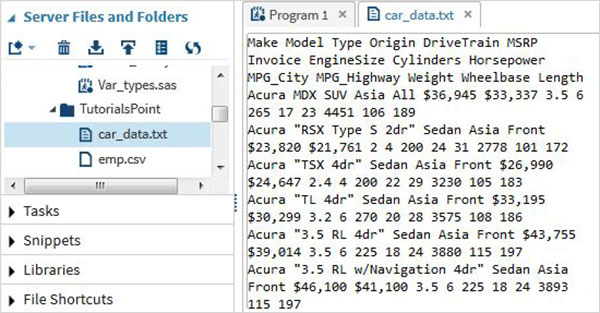
Мы будем использовать набор данных SAS с именами автомобилей, доступный в библиотеке SASHELP. Мы экспортируем его как текстовый файл с разделителями пробелами с кодом, как показано в следующей программе.
proc export data = sashelp.cars outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.txt' dbms = dlm; delimiter = ' '; run;
Выполнив приведенный выше код, мы можем увидеть вывод в виде текстового файла и щелкнуть по нему правой кнопкой мыши, чтобы увидеть его содержимое, как показано ниже.
Написание файла CSV
Чтобы записать файл с разделителями-запятыми, мы можем использовать опцию dlm со значением «csv». Следующий код записывает файл car_data.csv.
proc export data = sashelp.cars outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_data.csv' dbms = csv; run;
Выполнив приведенный выше код, мы получим следующий вывод.

Написание файла с разделителями табуляции
Чтобы написать файл с разделителями табуляции, мы можем использовать опцию dlm со значением «tab». Следующий код записывает файл car_tab.txt.
proc export data = sashelp.cars outfile = '/folders/myfolders/sasuser.v94/TutorialsPoint/car_tab.txt' dbms = csv; run;
Данные также могут быть записаны в виде HTML-файла, который мы увидим в главе «Система доставки вывода».
SAS — объединенные наборы данных
Несколько наборов данных SAS могут быть объединены для получения одного набора данных с помощью оператора SET . Общее количество наблюдений в объединенном наборе данных является суммой количества наблюдений в исходных наборах данных. Порядок наблюдений является последовательным. За всеми наблюдениями из первого набора данных следуют все наблюдения из второго набора данных и т. Д.
В идеале все объединяющие наборы данных имеют одинаковые переменные, но в случае, если у них разное количество переменных, в результате появляются все переменные с пропущенными значениями для меньшего набора данных.
Синтаксис
Основной синтаксис для оператора SET в SAS —
SET data-set 1 data-set 2 data-set 3.....;
Ниже приведено описание используемых параметров:
-
data-set1, data-set2 — это имена наборов данных, записанные одно за другим.
data-set1, data-set2 — это имена наборов данных, записанные одно за другим.
пример
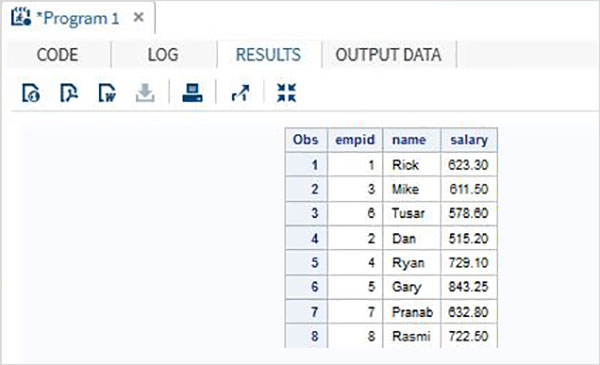
Рассмотрим данные о сотрудниках организации, которые доступны в двух разных наборах данных: один для ИТ-отдела, а другой для не-ИТ-отдела. Чтобы получить полную информацию обо всех сотрудниках, мы объединяем оба набора данных с помощью инструкции SET, показанной ниже.
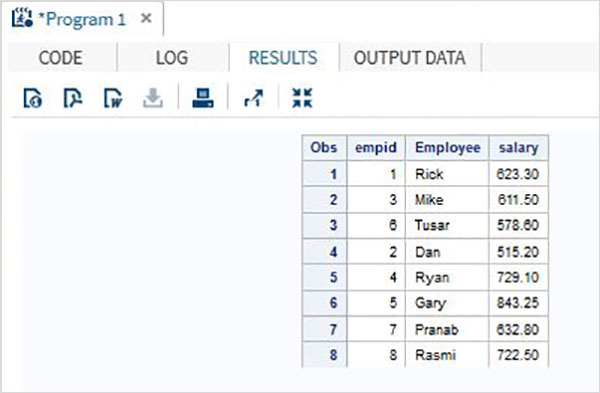
DATA ITDEPT; INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Сценарии
Когда у нас много вариаций в наборах данных для конкатенации, результат переменных может отличаться, но общее количество наблюдений в объединенном наборе данных всегда является суммой наблюдений в каждом наборе данных. Ниже мы рассмотрим множество сценариев этого варианта.
Разное количество переменных
Если один из исходных наборов данных имеет большее количество переменных, чем другой, тогда наборы данных по-прежнему объединяются, но в меньшем наборе данных эти переменные отображаются как отсутствующие.
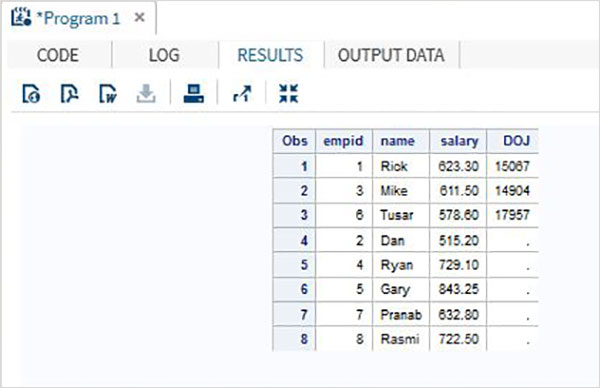
пример
В приведенном ниже примере первый набор данных имеет дополнительную переменную с именем DOJ. В результате значение DOJ для второго набора данных будет отображаться как отсутствующее.
DATA ITDEPT; INPUT empid name $ salary DOJ date9. ; DATALINES; 1 Rick 623.3 02APR2001 3 Mike 611.5 21OCT2000 6 Tusar 578.6 01MAR2009 ; RUN; DATA NON_ITDEPT; INPUT empid name $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT NON_ITDEPT; RUN; PROC PRINT DATA = All_Dept; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Другое имя переменной
В этом сценарии наборы данных имеют одинаковое количество переменных, но имя переменной отличается между ними. В этом случае нормальная конкатенация произведет все переменные в наборе результатов и даст недостающие результаты для двух переменных, которые отличаются. Хотя мы не можем изменить имя переменной в исходных наборах данных, мы можем применить функцию RENAME в объединенном наборе данных, который мы создаем. Это даст тот же результат, что и при обычной конкатенации, но, конечно, с одним новым именем переменной вместо двух разных имен переменных, присутствующих в исходном наборе данных.
пример
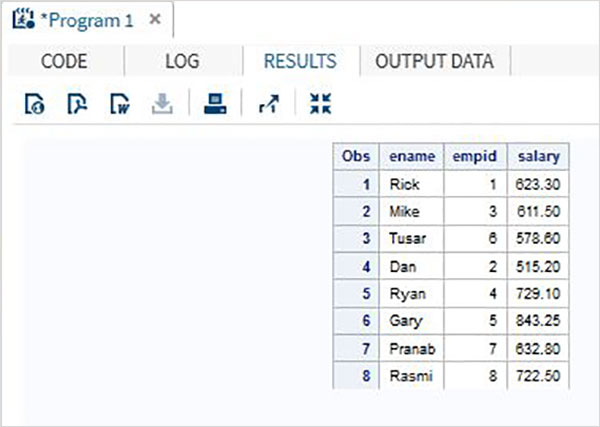
В приведенном ниже примере набора данных ITDEPT имеет имя переменной ename, тогда как набор данных NON_ITDEPT имеет имя переменной empname. Но обе эти переменные представляют один и тот же тип (символ). Мы применяем функцию RENAME в операторе SET, как показано ниже.
DATA ITDEPT; INPUT empid ename $ salary ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid empname $ salary ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; SET ITDEPT(RENAME =(ename = Employee) ) NON_ITDEPT(RENAME =(empname = Employee) ); RUN; PROC PRINT DATA = All_Dept; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
Различные переменные длины
Если длины переменных в двух наборах данных отличаются, то объединенный набор данных будет иметь значения, в которых некоторые данные усекаются для переменной с меньшей длиной. Это происходит, если первый набор данных имеет меньшую длину. Чтобы решить эту проблему, мы применяем большую длину к обоим наборам данных, как показано ниже.
пример
В приведенном ниже примере переменная ename имеет длину 5 в первом наборе данных и 7 во втором. При конкатенации мы применяем оператор LENGTH в конкатенированном наборе данных, чтобы установить длину ename равной 7.
DATA ITDEPT; INPUT empid 1-2 ename $ 3-7 salary 8-14 ; DATALINES; 1 Rick 623.3 3 Mike 611.5 6 Tusar 578.6 ; RUN; DATA NON_ITDEPT; INPUT empid 1-2 ename $ 3-9 salary 10-16 ; DATALINES; 2 Dan 515.2 4 Ryan 729.1 5 Gary 843.25 7 Pranab 632.8 8 Rasmi 722.5 RUN; DATA All_Dept; LENGTH ename $ 7 ; SET ITDEPT NON_ITDEPT ; RUN; PROC PRINT DATA = All_Dept; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
SAS — объединение наборов данных
Несколько наборов данных SAS могут быть объединены на основе определенной общей переменной, чтобы получить один набор данных. Это делается с помощью оператора MERGE и оператора BY . Общее количество наблюдений в объединенном наборе данных часто меньше, чем сумма количества наблюдений в исходных наборах данных. Это связано с тем, что переменные из обоих наборов данных объединяются в одну запись на основе совпадения значения общей переменной.
Ниже приведены две предпосылки для объединения наборов данных:
- входные наборы данных должны иметь хотя бы одну общую переменную для объединения.
- входные наборы данных должны быть отсортированы по общей переменной (переменным), которая будет использоваться для объединения.
Синтаксис
Основной синтаксис для операторов MERGE и BY в SAS —
MERGE Data-Set 1 Data-Set 2 BY Common Variable
Ниже приведено описание используемых параметров:
-
Data-set1, Data-set2 — это имена наборов данных, записанные один за другим.
-
Общая переменная — это переменная, в зависимости от значений которой будут объединены наборы данных.
Data-set1, Data-set2 — это имена наборов данных, записанные один за другим.
Общая переменная — это переменная, в зависимости от значений которой будут объединены наборы данных.
Объединение данных
Давайте разберемся со слиянием данных на примере.
пример
Рассмотрим два набора данных SAS, один из которых содержит идентификатор сотрудника с именем и зарплатой, а другой — идентификатор сотрудника с идентификатором сотрудника и отделом. В этом случае, чтобы получить полную информацию для каждого сотрудника, мы можем объединить эти два набора данных. Окончательный набор данных будет по-прежнему иметь одно наблюдение на сотрудника, но он будет содержать как зарплату, так и переменные отдела.
# Data set 1 ID NAME SALARY 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 # Data set 2 ID DEPT 1 IT 2 OPS 3 IT 4 HR 5 FIN 6 IT 7 OPS 8 FIN # Merged data set ID NAME SALARY DEPT 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN
Вышеуказанный результат достигается с помощью следующего кода, в котором общая переменная (ID) используется в операторе BY. Обратите внимание, что наблюдения в обоих наборах данных уже отсортированы в столбце идентификаторов.
DATA SALARY; INPUT empid name $ salary ; DATALINES; 1 Rick 623.3 2 Dan 515.2 3 Mike 611.5 4 Ryan 729.1 5 Gary 843.25 6 Tusar 578.6 7 Pranab 632.8 8 Rasmi 722.5 ; RUN; DATA DEPT; INPUT empid dEPT $ ; DATALINES; 1 IT 2 OPS 3 IT 4 HR 5 FIN 6 IT 7 OPS 8 FIN ; RUN; DATA All_details; MERGE SALARY DEPT; BY (empid); RUN; PROC PRINT DATA = All_details; RUN;
Отсутствующие значения в соответствующей колонке
Могут быть случаи, когда некоторые значения общей переменной не будут совпадать между наборами данных. В таких случаях наборы данных все еще объединяются, но в результате выдаются пропущенные значения.
пример
Рассмотрим случай, когда идентификатор 3 сотрудника отсутствует в наборе данных о заработной плате, а идентификатор 6 сотрудника отсутствует в наборе данных DEPT. Когда приведенный выше код применяется, мы получаем следующий результат.
ID NAME SALARY DEPT 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 . . IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 . 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN
Слияние только матчей
Чтобы избежать пропущенных значений в результате, мы можем рассмотреть сохранение только наблюдений с совпадающими значениями для общей переменной. Это достигается с помощью оператора IN . Заявление о слиянии программы SAS необходимо изменить.
пример
В приведенном ниже примере значение IN = сохраняет только наблюдения, в которых совпадают значения из обоих наборов данных SALARY и DEPT .
DATA All_details; MERGE SALARY(IN = a) DEPT(IN = b); BY (empid); IF a = 1 and b = 1; RUN; PROC PRINT DATA = All_details; RUN;
После выполнения вышеуказанной программы SAS с измененной частью, полученной выше, мы получаем следующий вывод.
1 Rick 623.3 IT 2 Dan 515.2 OPS 4 Ryan 729.1 HR 5 Gary 843.25 FIN 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN
SAS — Поднабор данных
Подмножество набора данных SAS означает выделение части набора данных путем выбора меньшего числа переменных или меньшего числа наблюдений или обоих. В то время как поднабор переменных выполняется с помощью операторов KEEP и DROP , поднабор наблюдений выполняется с помощью операторов DELETE .
Кроме того, полученные в результате операции поднабора данные хранятся в новом наборе данных, который можно использовать для дальнейшего анализа. Поднабор в основном используется для анализа части набора данных без использования тех переменных или наблюдений, которые могут не иметь отношения к анализу.
Подмножество переменных
В этом методе мы извлекаем только несколько переменных из всего набора данных.
Синтаксис
Основной синтаксис для поднабора переменных в SAS —
KEEP var1 var2 ... ; DROP var1 var2 ... ;
Ниже приведено описание используемых параметров:
-
var1 и var2 — это имена переменных из набора данных, которые необходимо сохранить или удалить.
var1 и var2 — это имена переменных из набора данных, которые необходимо сохранить или удалить.
пример
Рассмотрим приведенный ниже набор данных SAS, содержащий сведения о сотрудниках организации. Если мы заинтересованы только в получении значений Name и Department из набора данных, мы можем использовать приведенный ниже код.
DATA Employee; INPUT empid ename $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; KEEP ename DEPT; RUN; PROC PRINT DATA = OnlyDept; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
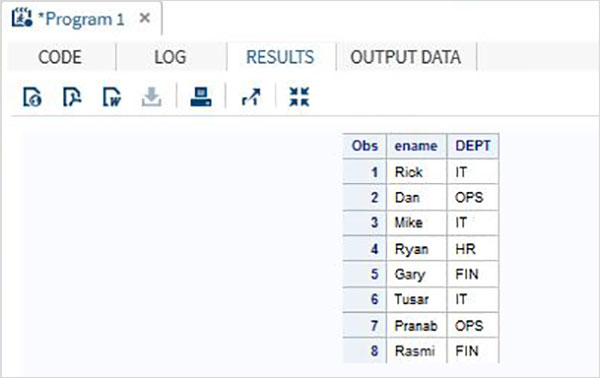
Тот же результат можно получить, отбросив переменные, которые не требуются. Код ниже иллюстрирует это.
DATA Employee; INPUT empid ename $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; DROP empid salary; RUN; PROC PRINT DATA = OnlyDept; RUN;
Подмножество наблюдений
В этом методе мы извлекаем только несколько наблюдений из всего набора данных.
Синтаксис
Мы используем PROC FREQ, который отслеживает наблюдения, выбранные для нового набора данных.
Синтаксис для поднаборов наблюдений —
IF Var Condition THEN DELETE ;
Ниже приведено описание используемых параметров:
-
Var — это имя переменной, в зависимости от значения которой наблюдения будут удаляться с использованием указанного условия.
Var — это имя переменной, в зависимости от значения которой наблюдения будут удаляться с использованием указанного условия.
пример
Рассмотрим приведенный ниже набор данных SAS, содержащий сведения о сотрудниках организации. Если мы заинтересованы только в получении данных для сотрудников с зарплатой более 700, то мы используем приведенный ниже код.
DATA Employee; INPUT empid name $ salary DEPT $ ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; DATA OnlyDept; SET Employee; IF salary < 700 THEN DELETE; RUN; PROC PRINT DATA = OnlyDept; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
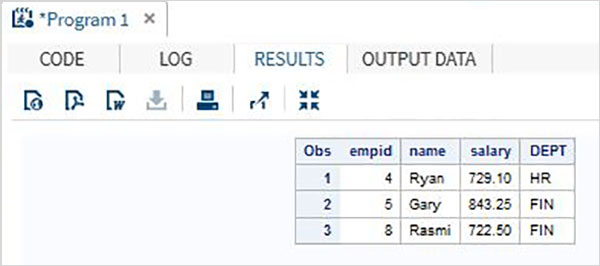
SAS — формат данных
Иногда мы предпочитаем отображать проанализированные данные в формате, который отличается от формата, в котором они уже присутствуют в наборе данных. Например, мы хотим добавить знак доллара и два знака после запятой в переменную, которая имеет информацию о цене. Или мы можем захотеть показать текстовую переменную, все в верхнем регистре. Мы можем использовать FORMAT для применения встроенных форматов SAS, а PROC FORMAT — для применения пользовательских форматов. Также один формат может быть применен к нескольким переменным.
Синтаксис
Основной синтаксис для применения встроенных форматов SAS:
format variable name format name
Ниже приведено описание используемых параметров:
-
имя переменной — это имя переменной, используемой в наборе данных.
-
имя формата — это формат данных, который будет применен к переменной.
имя переменной — это имя переменной, используемой в наборе данных.
имя формата — это формат данных, который будет применен к переменной.
пример
Давайте рассмотрим приведенный ниже набор данных SAS, содержащий сведения о сотрудниках организации. Мы хотим показать все имена в верхнем регистре. Для этого используется форматирование .
DATA Employee; INPUT empid name $ salary DEPT $ ; format name $upcase9. ; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 OPS 3 Mike 611.5 IT 4 Ryan 729.1 HR 5 Gary 843.25 FIN 6 Tusar 578.6 IT 7 Pranab 632.8 OPS 8 Rasmi 722.5 FIN ; RUN; PROC PRINT DATA = Employee; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
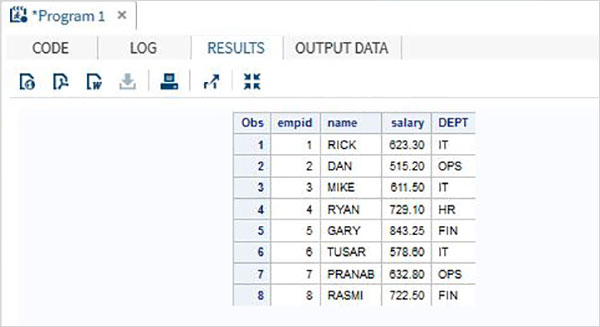
Использование PROC FORMAT
Мы также можем использовать PROC FORMAT для форматирования данных. В приведенном ниже примере мы присваиваем новые значения переменной DEPT, добавляя название отдела.
DATA Employee;
INPUT empid name $ salary DEPT $ ;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 OPS
3 Mike 611.5 IT
4 Ryan 729.1 HR
5 Gary 843.25 FIN
6 Tusar 578.6 IT
7 Pranab 632.8 OPS
8 Rasmi 722.5 FIN
;
proc format;
value $DEP 'IT' = 'Information Technology'
'OPS'= 'Operations' ;
RUN;
PROC PRINT DATA = Employee;
format name $upcase9. DEPT $DEP.;
RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод.
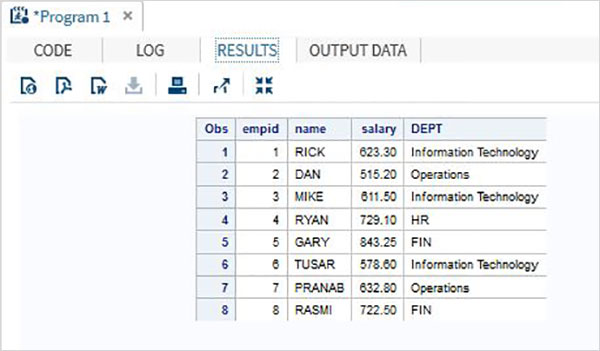
SAS — SQL
SAS предлагает обширную поддержку большинству популярных реляционных баз данных, используя SQL-запросы внутри программ SAS. Большая часть синтаксиса ANSI SQL поддерживается. Процедура PROC SQL используется для обработки операторов SQL. Эта процедура может не только вернуть результат запроса SQL, но и создать таблицы и переменные SAS. Пример всех этих сценариев описан ниже.
Синтаксис
Основной синтаксис для использования PROC SQL в SAS —
PROC SQL; SELECT Columns FROM TABLE WHERE Columns GROUP BY Columns ; QUIT;
Ниже приведено описание используемых параметров:
-
SQL-запрос записывается под оператором PROC SQL, за которым следует оператор QUIT.
SQL-запрос записывается под оператором PROC SQL, за которым следует оператор QUIT.
Ниже мы увидим, как эту процедуру SAS можно использовать для операций CRUD (создание, чтение, обновление и удаление) в SQL.
Операция создания SQL
Используя SQL, мы можем создать новый набор данных из необработанных данных. В приведенном ниже примере сначала мы объявляем набор данных с именем TEMP, содержащий необработанные данные. Затем мы пишем SQL-запрос для создания таблицы из переменных этого набора данных.
DATA TEMP; INPUT ID $ NAME $ SALARY DEPARTMENT $; DATALINES; 1 Rick 623.3 IT 2 Dan 515.2 Operations 3 Michelle 611 IT 4 Ryan 729 HR 5 Gary 843.25 Finance 6 Nina 578 IT 7 Simon 632.8 Operations 8 Guru 722.5 Finance ; RUN; PROC SQL; CREATE TABLE EMPLOYEES AS SELECT * FROM TEMP; QUIT; PROC PRINT data = EMPLOYEES; RUN;
Когда приведенный выше код выполняется, мы получаем следующий результат —
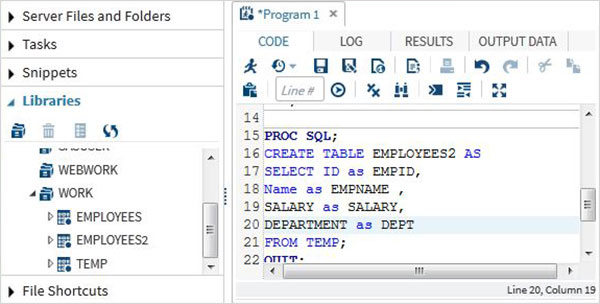
Операция чтения SQL
Операция чтения в SQL включает в себя написание запросов SQL SELECT для чтения данных из таблиц. В приведенной ниже программе запрашивается набор данных SAS с именем CARS, доступный в библиотеке SASHELP. Запрос выбирает некоторые из столбцов набора данных.
PROC SQL; SELECT make,model,type,invoice,horsepower FROM SASHELP.CARS ; QUIT;
Когда приведенный выше код выполняется, мы получаем следующий результат —
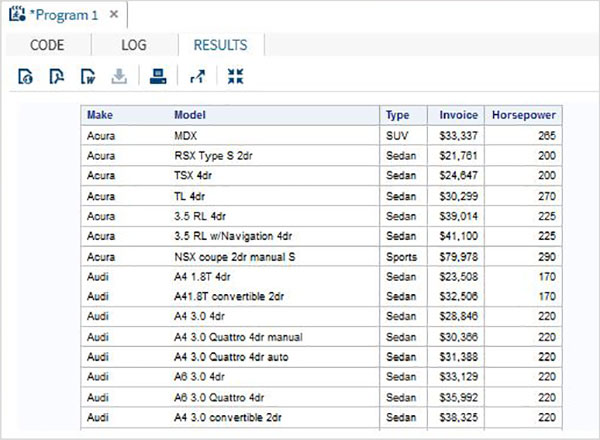
SQL SELECT с предложением WHERE
Приведенная ниже программа запрашивает набор данных CARS с предложением where . В результате мы получаем только те наблюдения, которые обозначены как «Ауди», а тип — как «Спорт».
PROC SQL; SELECT make,model,type,invoice,horsepower FROM SASHELP.CARS Where make = 'Audi' and Type = 'Sports' ; QUIT;
Когда приведенный выше код выполняется, мы получаем следующий результат —
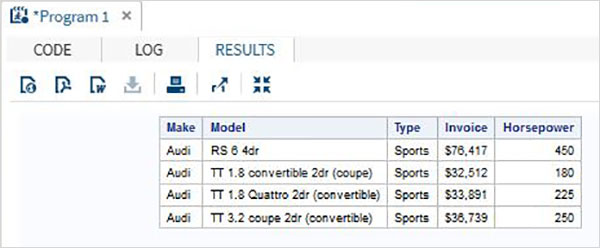
Операция SQL UPDATE
Мы можем обновить таблицу SAS с помощью оператора SQL Update. Ниже мы сначала создаем новую таблицу с именем EMPLOYEES2, а затем обновляем ее с помощью оператора SQL UPDATE.
DATA TEMP;
INPUT ID $ NAME $ SALARY DEPARTMENT $;
DATALINES;
1 Rick 623.3 IT
2 Dan 515.2 Operations
3 Michelle 611 IT
4 Ryan 729 HR
5 Gary 843.25 Finance
6 Nina 578 IT
7 Simon 632.8 Operations
8 Guru 722.5 Finance
;
RUN;
PROC SQL;
CREATE TABLE EMPLOYEES2 AS
SELECT ID as EMPID,
Name as EMPNAME ,
SALARY as SALARY,
DEPARTMENT as DEPT,
SALARY*0.23 as COMMISION
FROM TEMP;
QUIT;
PROC SQL;
UPDATE EMPLOYEES2
SET SALARY = SALARY*1.25;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;
Когда приведенный выше код выполняется, мы получаем следующий результат —

Операция SQL DELETE
Операция удаления в SQL включает удаление определенных значений из таблицы с помощью оператора SQL DELETE. Мы продолжаем использовать данные из приведенного выше примера и удаляем строки из таблицы, в которой зарплата сотрудников превышает 900.
PROC SQL;
DELETE FROM EMPLOYEES2
WHERE SALARY > 900;
QUIT;
PROC PRINT data = EMPLOYEES2;
RUN;
Когда приведенный выше код выполняется, мы получаем следующий результат —

SAS — ODS
Вывод программы SAS можно преобразовать в более удобные для пользователя формы, такие как .html или PDF. Это делается с помощью оператора ODS, доступного в SAS. ODS обозначает систему доставки продукции. Он в основном используется для форматирования выходных данных программы SAS в красивые отчеты, которые хорошо смотреть и понимать. Это также помогает делиться выводом с другими платформами и программными продуктами. Он также может объединять результаты нескольких операторов PROC в одном файле.
Синтаксис
Основной синтаксис для использования оператора ODS в SAS —
ODS outputtype PATH path name FILE = Filename and Path STYLE = StyleName ; PROC some proc ; ODS outputtype CLOSE;
Ниже приведено описание используемых параметров:
-
PATH представляет оператор, используемый в случае вывода HTML. В других типах вывода мы включаем путь в имя файла.
-
Стиль представляет собой один из встроенных стилей, доступных в среде SAS.
PATH представляет оператор, используемый в случае вывода HTML. В других типах вывода мы включаем путь в имя файла.
Стиль представляет собой один из встроенных стилей, доступных в среде SAS.
Создание вывода HTML
Мы создаем вывод HTML, используя оператор ODS HTML. В приведенном ниже примере мы создаем HTML-файл по нашему желаемому пути. Мы применяем стиль, доступный в библиотеке стилей. Мы можем увидеть выходной файл по указанному пути и загрузить его для сохранения в среде, отличной от среды SAS. Обратите внимание, что у нас есть два SQL-оператора proc, и оба их вывода записываются в один файл.
ODS HTML
PATH = '/folders/myfolders/sasuser.v94/TutorialsPoint/'
FILE = 'CARS2.html'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS HTML CLOSE;
Когда приведенный выше код выполняется, мы получаем следующий результат —
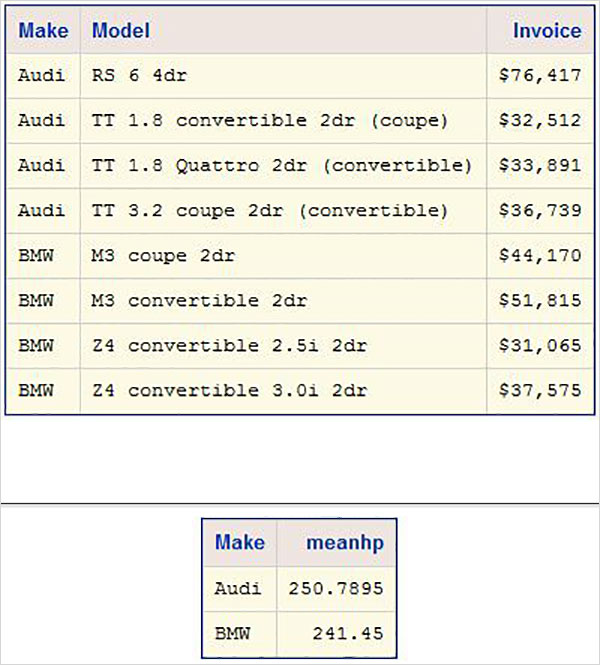
Создание вывода PDF
В приведенном ниже примере мы создаем файл PDF по нашему желаемому пути. Мы применяем стиль, доступный в библиотеке стилей. Мы можем увидеть выходной файл по указанному пути и загрузить его для сохранения в среде, отличной от среды SAS. Обратите внимание, что у нас есть два SQL-оператора proc, и оба их вывода записываются в один файл.
ODS PDF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS2.pdf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS PDF CLOSE;
Когда приведенный выше код выполняется, мы получаем следующий результат —
Создание TRF (Word) вывода
В приведенном ниже примере мы создаем файл RTF по нашему желаемому пути. Мы применяем стиль, доступный в библиотеке стилей. Мы можем увидеть выходной файл по указанному пути и загрузить его для сохранения в среде, отличной от среды SAS. Обратите внимание, что у нас есть два SQL-оператора proc, и оба их вывода записываются в один файл.
ODS RTF
FILE = '/folders/myfolders/sasuser.v94/TutorialsPoint/CARS.rtf'
STYLE = EGDefault;
proc SQL;
select make, model, invoice
from sashelp.cars
where make in ('Audi','BMW')
and type = 'Sports'
;
quit;
proc SQL;
select make,mean(horsepower)as meanhp
from sashelp.cars
where make in ('Audi','BMW')
group by make;
quit;
ODS rtf CLOSE;
Когда приведенный выше код выполняется, мы получаем следующий результат —
SAS — Симуляторы
Моделирование — это вычислительная техника, которая использует повторяющиеся вычисления для множества различных случайных выборок для оценки статистической величины. Используя SAS, мы можем моделировать сложные данные, которые имеют определенные статистические свойства в реальной системе. Мы используем программное обеспечение для построения модели системы и численно генерируем данные, которые можно использовать для лучшего понимания поведения реальной системы. Часть искусства проектирования компьютерной имитационной модели заключается в определении того, какие аспекты реальной системы необходимо включить в модель, чтобы данные, сгенерированные моделью, могли использоваться для принятия эффективных решений. Из-за этой сложности SAS имеет специальный программный компонент для моделирования.
Программный компонент SAS, который используется при создании симуляции SAS, называется SAS Simulation Studio . Его графический интерфейс пользователя предоставляет полный набор инструментов для построения, выполнения и анализа результатов моделей моделирования дискретных событий.
Различные типы статистических распределений, к которым может применяться моделирование SAS, перечислены ниже.
- МОДЕЛЬНЫЕ ДАННЫЕ ОТ НЕПРЕРЫВНОГО РАСПРЕДЕЛЕНИЯ
- МОДЕЛЬНЫЕ ДАННЫЕ ОТ ДИСКРЕТНОГО РАСПРЕДЕЛЕНИЯ
- МОДЕЛИРОВАННЫЕ ДАННЫЕ ИЗ СМЕСИ РАСПРЕДЕЛЕНИЙ
- МОДЕЛЬНЫЕ ДАННЫЕ ОТ КОМПЛЕКСНОГО РАСПРЕДЕЛЕНИЯ
- МОДЕЛЬНЫЕ ДАННЫЕ ОТ МНОГОМЕРНОГО РАСПРЕДЕЛЕНИЯ
- ПРИМЕРИТЕ РАСПРЕДЕЛЕНИЕ ОБРАЗЦОВ
- ОЦЕНИТЬ ОЦЕНКУ РЕГРЕССИИ
SAS — гистограммы
Гистограмма — это графическое отображение данных с использованием столбцов разной высоты. Он группирует различные числа в наборе данных во множество диапазонов. Он также представляет оценку вероятности распределения непрерывной переменной. В SAS PROC UNIVARIATE используется для создания гистограмм с указанными ниже параметрами.
Синтаксис
Основной синтаксис для создания гистограммы в SAS —
PROC UNIVARAITE DATA = DATASET; HISTOGRAM variables; RUN;Ниже приведено описание используемых параметров:
-
DATASET — это имя используемого набора данных.
-
переменные — это значения, используемые для построения гистограммы.
DATASET — это имя используемого набора данных.
переменные — это значения, используемые для построения гистограммы.
Простая гистограмма
Простая гистограмма создается путем указания имени переменной и диапазона, который следует учитывать для группировки значений.
пример
В приведенном ниже примере мы рассматриваем минимальное и максимальное значения переменной лошадиных сил и принимаем диапазон 50. Таким образом, значения образуют группу с шагом 50.
proc univariate data = sashelp.cars; histogram horsepower / midpoints = 176 to 350 by 50; run;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
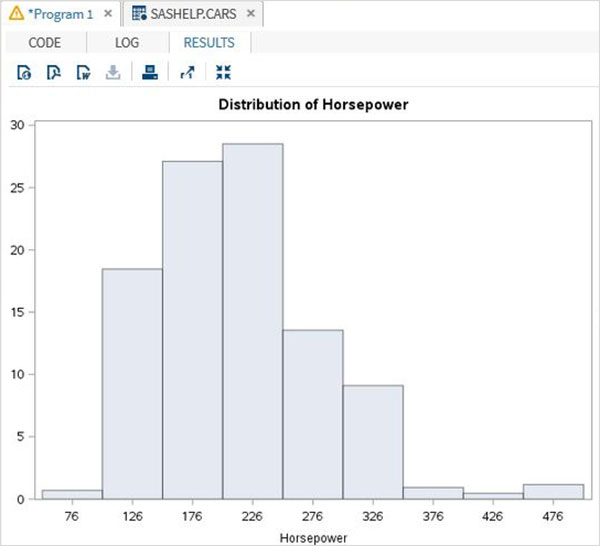
Гистограмма с кривой
Мы можем вписать некоторые кривые распределения в гистограмму, используя дополнительные параметры.
пример
В приведенном ниже примере мы подгоняем кривую распределения со значениями среднего и стандартного отклонения, упомянутыми как EST. Эта опция использует и оценку параметров.
proc univariate data = sashelp.cars noprint; histogram horsepower / normal ( mu = est sigma = est color = blue w = 2.5 ) barlabel = percent midpoints = 70 to 550 by 50; run;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
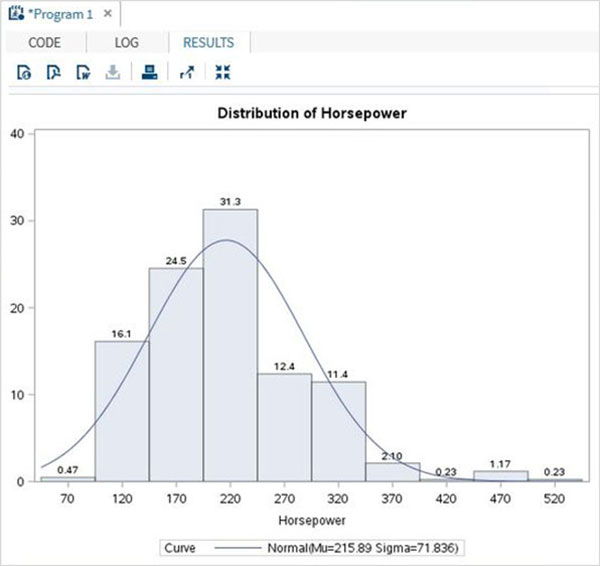
SAS — гистограммы
Гистограмма представляет данные в прямоугольных столбцах, длина столбца которых пропорциональна значению переменной. SAS использует процедуру PROC SGPLOT для создания гистограмм. Мы можем нарисовать как простые, так и сложенные столбцы на гистограмме. В гистограмме каждому из баров могут быть даны разные цвета.
Синтаксис
Основной синтаксис для создания гистограммы в SAS —
PROC SGPLOT DATA = DATASET; VBAR variables; RUN;Ниже приведено описание используемых параметров:
-
DATASET — это имя используемого набора данных.
-
переменные — это значения, используемые для построения гистограммы.
DATASET — это имя используемого набора данных.
переменные — это значения, используемые для построения гистограммы.
Простая гистограмма
Простая гистограмма — это гистограмма, в которой переменная из набора данных представлена в виде столбцов.
пример
Приведенный ниже скрипт создаст гистограмму, представляющую длину автомобилей в виде баров.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc SGPLOT data = work.cars1;
vbar length ;
title 'Lengths of cars';
run;
quit;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
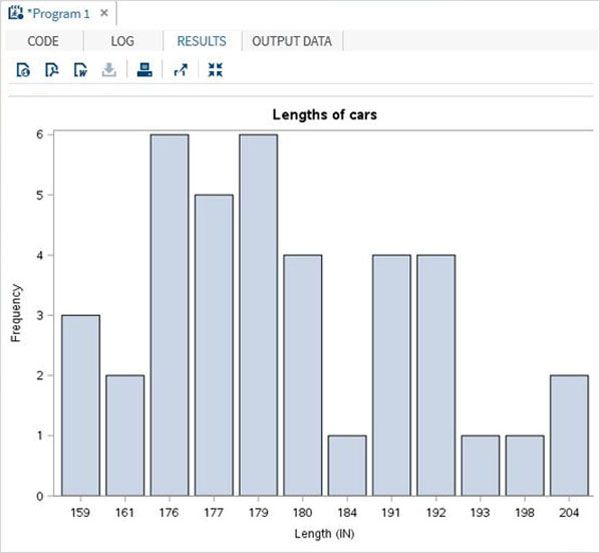
Гистограмма с накоплением
Столбчатая диаграмма с накоплением — это столбчатая диаграмма, в которой переменная из набора данных рассчитывается относительно другой переменной.
пример
Приведенный ниже скрипт создаст гистограмму с накоплением, где длина автомобилей рассчитывается для каждого типа автомобилей. Мы используем параметр группы, чтобы указать вторую переменную.
proc SGPLOT data = work.cars1; vbar length /group = type ; title 'Lengths of Cars by Types'; run; quit;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
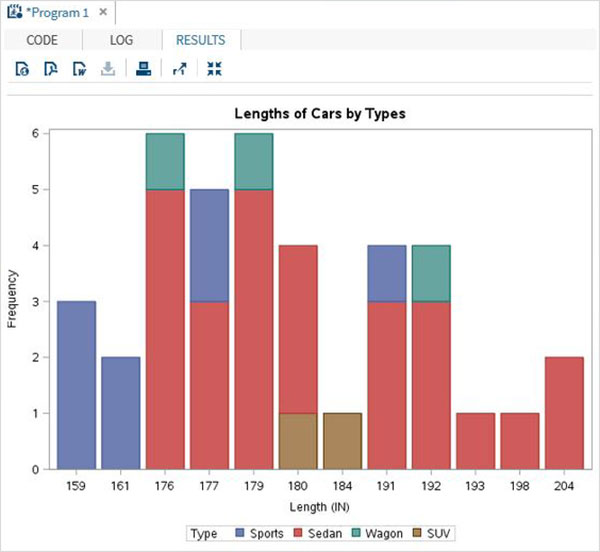
Кластерная гистограмма
Кластерная гистограмма создается, чтобы показать, как значения переменной распространяются по культуре.
пример
Приведенный ниже скрипт создаст кластерную гистограмму, в которой длина автомобилей сгруппирована вокруг типа автомобиля. Итак, мы видим два соседних столбца длиной 191, один для типа автомобиля «Седан», а другой для типа автомобиля «Вагон» ,
proc SGPLOT data = work.cars1; vbar length /group = type GROUPDISPLAY = CLUSTER; title 'Cluster of Cars by Types'; run; quit;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
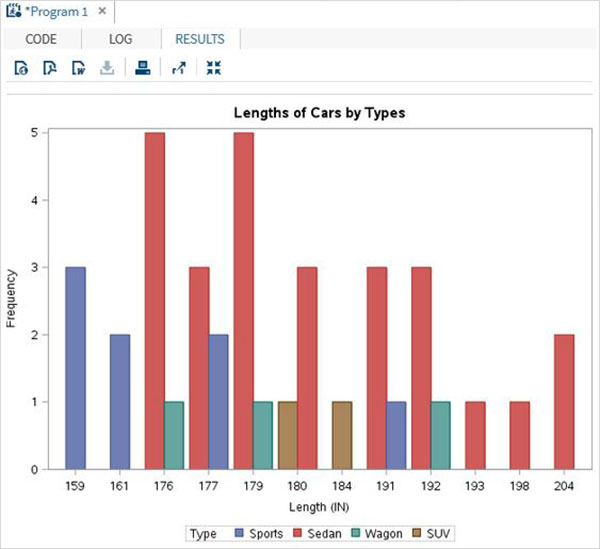
SAS — круговые диаграммы
Круговая диаграмма — это представление значений в виде кусочков круга разных цветов. Срезы помечены, и числа, соответствующие каждому срезу, также представлены на диаграмме.
В SAS круговая диаграмма создается с использованием PROC TEMPLATE, который принимает параметры для управления процентами, метками, цветом, заголовком и т. Д.
Синтаксис
Основной синтаксис для создания круговой диаграммы в SAS —
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = variable /
DATALABELLOCATION = OUTSIDE
CATEGORYDIRECTION = CLOCKWISE
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = ' ';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
Ниже приведено описание используемых параметров:
-
Переменная — это значение, для которого мы создаем круговую диаграмму.
Переменная — это значение, для которого мы создаем круговую диаграмму.
Простая круговая диаграмма
На этой круговой диаграмме мы берем одну переменную из набора данных. Круговая диаграмма создается со значением срезов, представляющих долю числа переменных по отношению к общему значению переменной.
пример
В приведенном ниже примере каждый срез представляет собой долю типа автомобиля от общего количества автомобилей.
PROC SQL; create table CARS1 as SELECT make, model, type, invoice, horsepower, length, weight FROM SASHELP.CARS WHERE make in ('Audi','BMW') ; RUN; PROC TEMPLATE; DEFINE STATGRAPH pie; BEGINGRAPH; LAYOUT REGION; PIECHART CATEGORY = type / DATALABELLOCATION = OUTSIDE CATEGORYDIRECTION = CLOCKWISE START = 180 NAME = 'pie'; DISCRETELEGEND 'pie' / TITLE = 'Car Types'; ENDLAYOUT; ENDGRAPH; END; RUN; PROC SGRENDER DATA = cars1 TEMPLATE = pie; RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
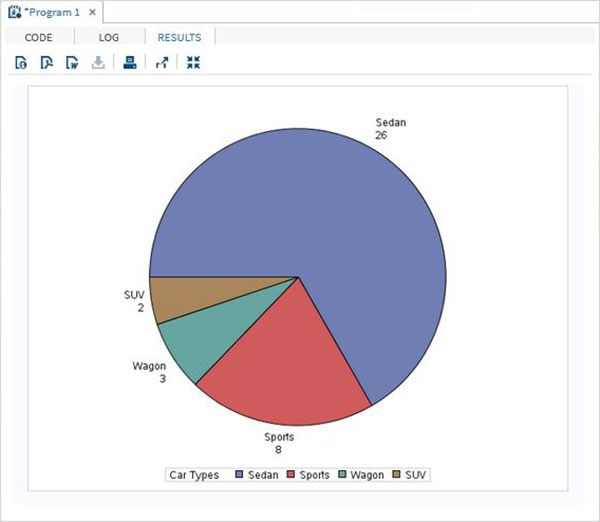
Круговая диаграмма с метками данных
На этой круговой диаграмме мы представляем как дробное значение, так и процентное значение для каждого среза. Мы также меняем расположение метки, чтобы она находилась внутри графика. Стиль внешнего вида диаграммы изменяется с помощью опции DATASKIN. Он использует один из встроенных стилей, доступных в среде SAS.
пример
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type /
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
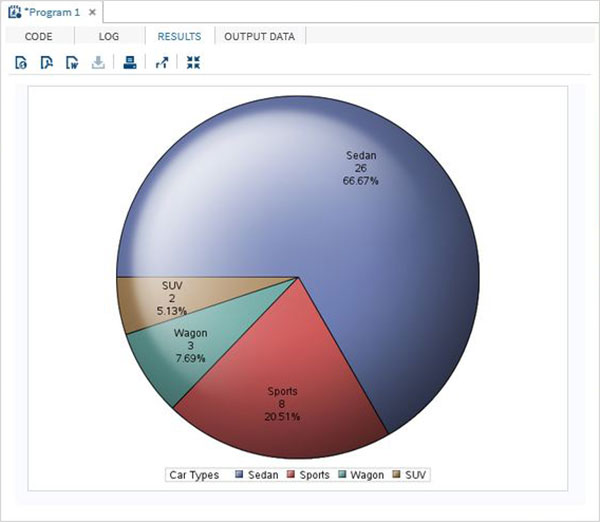
Круговая диаграмма
На этой круговой диаграмме значение переменной, представленной на графике, сгруппировано по отношению к другой переменной из того же набора данных. Каждая группа становится одним кругом, и на диаграмме столько концентрических кругов, сколько есть доступных групп.
пример
В приведенном ниже примере мы группируем диаграмму по переменной с именем «Make». Поскольку доступны два значения («Audi» и «BMW»), мы получаем два концентрических круга, каждый из которых представляет срезы типов автомобилей своей марки.
PROC TEMPLATE;
DEFINE STATGRAPH pie;
BEGINGRAPH;
LAYOUT REGION;
PIECHART CATEGORY = type / Group = make
DATALABELLOCATION = INSIDE
DATALABELCONTENT = ALL
CATEGORYDIRECTION = CLOCKWISE
DATASKIN = SHEEN
START = 180 NAME = 'pie';
DISCRETELEGEND 'pie' /
TITLE = 'Car Types';
ENDLAYOUT;
ENDGRAPH;
END;
RUN;
PROC SGRENDER DATA = cars1
TEMPLATE = pie;
RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
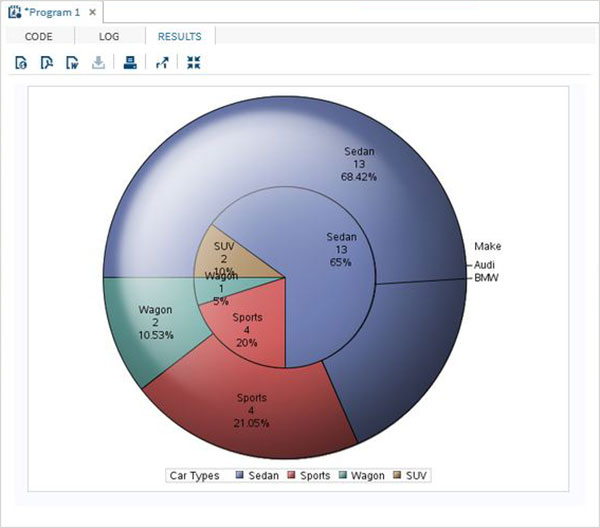
SAS — точечные диаграммы
Диаграмма рассеяния — это тип графика, который использует значения двух переменных, построенных на декартовой плоскости. Обычно используется для выяснения связи между двумя переменными. В SAS мы используем PROC SGSCATTER для создания графиков рассеяния.
Обратите внимание, что мы создаем набор данных с именем CARS1 в первом примере и используем тот же набор данных для всех последующих наборов данных. Этот набор данных остается в рабочей библиотеке до конца сеанса SAS.
Синтаксис
Основной синтаксис для создания точечной диаграммы в SAS —
PROC sgscatter DATA = DATASET; PLOT VARIABLE_1 * VARIABLE_2 / datalabel = VARIABLE group = VARIABLE; RUN;
Ниже приведено описание используемых параметров:
-
DATASET — это имя набора данных.
-
VARIABLE — это переменная, используемая из набора данных.
DATASET — это имя набора данных.
VARIABLE — это переменная, используемая из набора данных.
Простое Scatterplot
В простой диаграмме рассеяния мы выбираем две переменные из набора данных и группируем их по третьей переменной. Мы также можем пометить данные. Результат показывает, как две переменные разбросаны в декартовой плоскости.
пример
PROC SQL; create table CARS1 as SELECT make, model, type, invoice, horsepower, length, weight FROM SASHELP.CARS WHERE make in ('Audi','BMW') ; RUN; TITLE 'Scatterplot - Two Variables'; PROC sgscatter DATA = CARS1; PLOT horsepower*Invoice / datalabel = make group = type grid; title 'Horsepower vs. Invoice for car makers by types'; RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
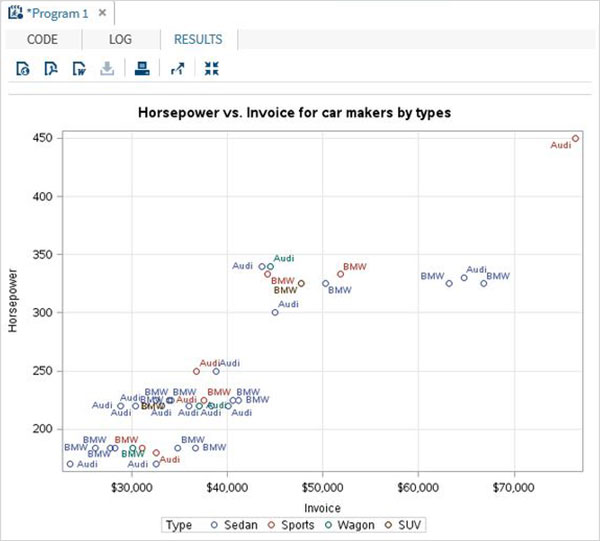
Scatterplot с предсказанием
мы можем использовать параметр оценки, чтобы предсказать степень корреляции между ними, нарисовав эллипс вокруг значений. Мы используем дополнительные параметры в процедуре, чтобы нарисовать эллипс, как показано ниже.
пример
proc sgscatter data = cars1;
compare y = Invoice x = (horsepower length)
/ group = type ellipse =(alpha = 0.05 type = predicted);
title
'Average Invoice vs. horsepower for cars by length';
title2
'-- with 95% prediction ellipse --'
;
format
Invoice dollar6.0;
run;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
Scatter Matrix
Мы также можем получить диаграмму рассеяния, включающую более двух переменных, сгруппировав их в пары. В приведенном ниже примере мы рассмотрим три переменные и нарисуем матрицу графика рассеяния. Получаем 3 пары полученной матрицы.
пример
PROC sgscatter DATA = CARS1; matrix horsepower invoice length / group = type; title 'Horsepower vs. Invoice vs. Length for car makers by types'; RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
SAS — Коробочные участки
Boxplot — графическое представление групп числовых данных через их квартили. Коробчатые участки также могут иметь линии, проходящие вертикально от прямоугольников (усов), указывающих на изменчивость за пределами верхнего и нижнего квартилей. Дно и верх коробки всегда являются первым и третьим квартилями, а полоса внутри коробки — всегда вторым квартилем (медиана). В SAS простой Boxplot создается с помощью PROC SGPLOT, а панельный boxplot создается с помощью PROC SGPANEL .
Обратите внимание, что мы создаем набор данных с именем CARS1 в первом примере и используем тот же набор данных для всех последующих наборов данных. Этот набор данных остается в рабочей библиотеке до конца сеанса SAS.
Синтаксис
Основной синтаксис для создания боксплота в SAS —
PROC SGPLOT DATA = DATASET; VBOX VARIABLE / category = VARIABLE; RUN; PROC SGPANEL DATA = DATASET;; PANELBY VARIABLE; VBOX VARIABLE> / category = VARIABLE; RUN;Ниже приведено описание используемых параметров:
-
DATASET — это имя используемого набора данных.
-
VARIABLE — это значение, используемое для построения Boxplot.
DATASET — это имя используемого набора данных.
VARIABLE — это значение, используемое для построения Boxplot.
Простой боксплот
В простом Boxplot мы выбираем одну переменную из набора данных, а другую — для формирования категории. Значения первой переменной классифицируются по количеству групп по числу различных значений во второй переменной.
пример
В приведенном ниже примере мы выбираем переменную мощность в качестве первой переменной и вводим в качестве переменной категории. Таким образом, мы получаем боксы для распределения значений лошадиных сил для каждого типа автомобиля.
PROC SQL; create table CARS1 as SELECT make, model, type, invoice, horsepower, length, weight FROM SASHELP.CARS WHERE make in ('Audi','BMW') ; RUN; PROC SGPLOT DATA = CARS1; VBOX horsepower / category = type; title 'Horsepower of cars by types'; RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
Boxplot в вертикальных панелях
Мы можем разделить Boxplots переменной на множество вертикальных панелей (столбцов). Каждая панель содержит поля для всех категориальных переменных. Но блокпосты далее группируются с использованием другой третьей переменной, которая делит график на несколько панелей.
пример
В приведенном ниже примере мы обрисовали график с помощью переменной ‘make’. Так как есть два разных значения make, мы получаем две вертикальные панели.
PROC SGPANEL DATA = CARS1; PANELBY MAKE; VBOX horsepower / category = type; title 'Horsepower of cars by types'; RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
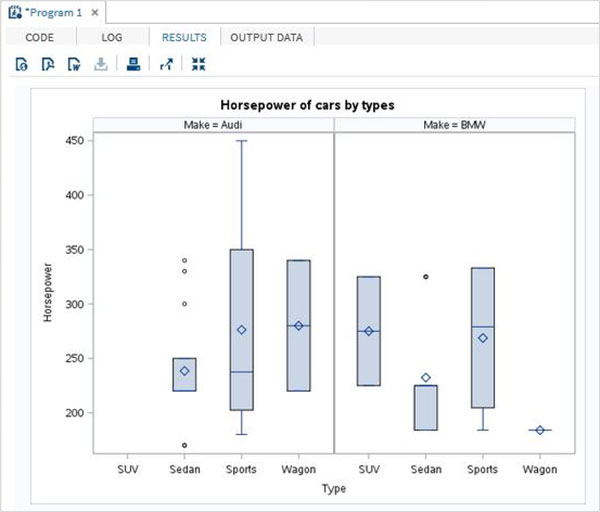
Boxplot в горизонтальных панелях
Мы можем разделить Boxplots переменной на множество горизонтальных панелей (рядов). Каждая панель содержит поля для всех категориальных переменных. Но блокпосты далее группируются с использованием другой третьей переменной, которая делит график на несколько панелей. В приведенном ниже примере мы обрисовали график с помощью переменной ‘make’. Поскольку есть два разных значения make, мы получаем две горизонтальные панели.
PROC SGPANEL DATA = CARS1; PANELBY MAKE / columns = 1 novarname; VBOX horsepower / category = type; title 'Horsepower of cars by types'; RUN;
Когда мы выполняем приведенный выше код, мы получаем следующий вывод:
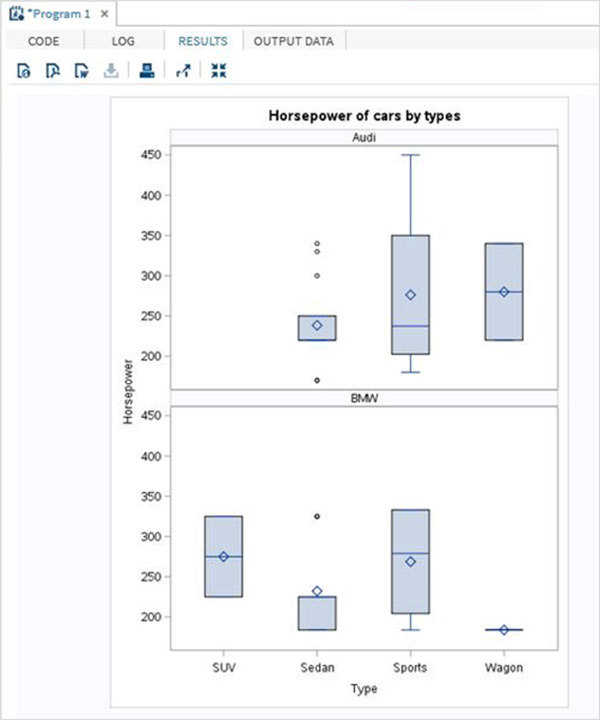
SAS — среднее арифметическое
Среднее арифметическое — это значение, полученное путем суммирования числовых переменных с последующим делением суммы на количество переменных. Это также называется Средний. В SAS среднее арифметическое рассчитывается с использованием PROC MEANS . Используя эту процедуру SAS, мы можем найти среднее значение всех переменных или некоторых переменных набора данных. Мы также можем формировать группы и находить средние значения переменных, характерных для этой группы.
Синтаксис
Основной синтаксис для вычисления среднего арифметического в SAS —
PROC MEANS DATA = DATASET; CLASS Variables ; VAR Variables;
Ниже приведено описание используемых параметров:
-
DATASET — это имя используемого набора данных.
-
Переменные — это имя переменной из набора данных.
DATASET — это имя используемого набора данных.
Переменные — это имя переменной из набора данных.
Среднее из набора данных
Среднее значение каждой числовой переменной в наборе данных рассчитывается с использованием PROC путем предоставления только имени набора данных без каких-либо переменных.
пример
В приведенном ниже примере мы находим среднее значение всех числовых переменных в наборе данных SAS с именем CARS. Мы указываем, что максимальные цифры после десятичного знака равны 2, а также находим сумму этих переменных.
PROC MEANS DATA = sashelp.CARS Mean SUM MAXDEC=2; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
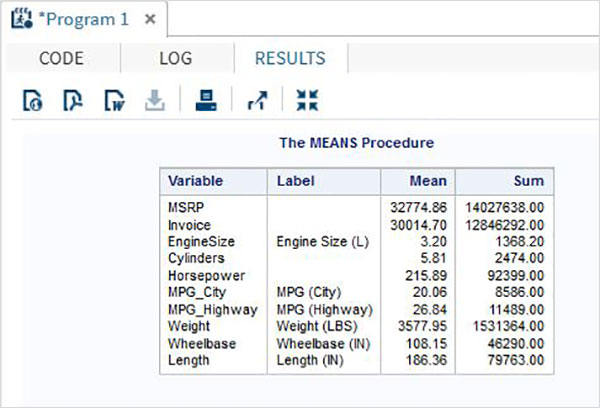
Среднее из выбранных переменных
Мы можем получить среднее значение некоторых переменных, указав их имена в опции var .
пример
Ниже мы вычисляем среднее значение трех переменных.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2 ; var horsepower invoice EngineSize; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
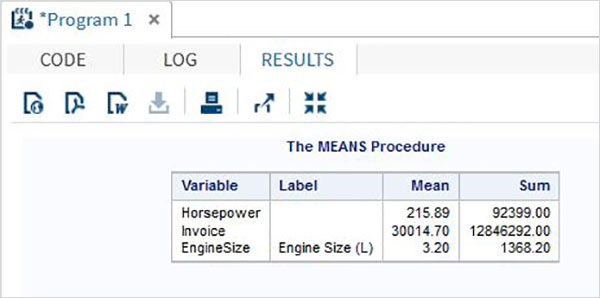
Имеется в виду по классу
Мы можем найти среднее значение числовых переменных, организовав их в группы, используя некоторые другие переменные.
пример
В приведенном ниже примере мы находим среднее значение переменной мощности для каждого типа под каждой маркой автомобиля.
PROC MEANS DATA = sashelp.CARS mean SUM MAXDEC=2; class make type; var horsepower; RUN;
Когда приведенный выше код выполняется, мы получаем следующий вывод:
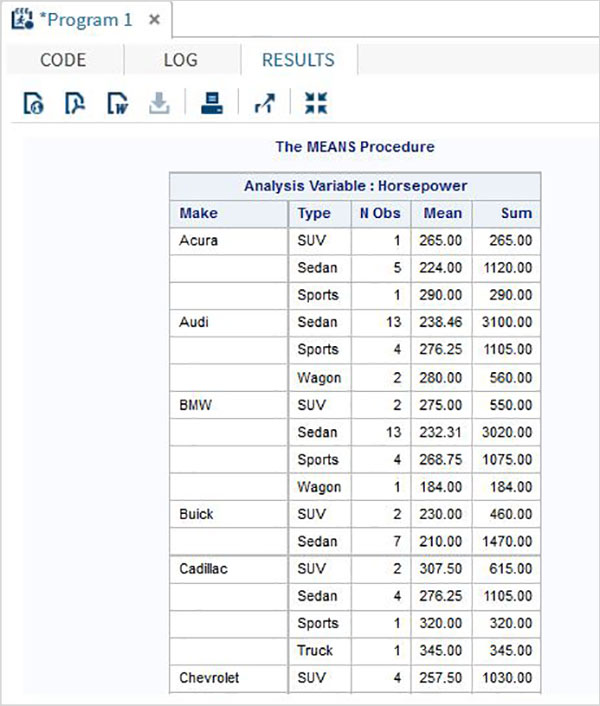
SAS — стандартное отклонение
Стандартное отклонение (SD) является мерой того, насколько разнообразны данные в наборе данных. Математически он измеряет, насколько далеко или близко каждое значение от среднего значения набора данных. Значение стандартного отклонения, близкое к 0, указывает, что точки данных, как правило, очень близки к среднему значению набора данных, а высокое стандартное отклонение указывает, что точки данных распределены по более широкому диапазону значений.
В SAS значения SD измеряются с помощью PROC MEAN, а также PROC SURVEYMEANS.
Использование PROC MEANS
Для измерения SD с помощью средств proc мы выбираем параметр STD на шаге PROC. Он выводит значения SD для каждой числовой переменной, присутствующей в наборе данных.
Синтаксис
Основной синтаксис для расчета стандартного отклонения в SAS —
PROC means DATA = dataset STD;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
Набор данных — это имя набора данных.
пример
В приведенном ниже примере мы создаем набор данных CARS1 из набора данных CARS в библиотеке SASHELP. Мы выбираем вариант STD с шагом PROC означает.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc means data = CARS1 STD;
run;
Когда мы выполняем приведенный выше код, он дает следующий вывод —
Использование PROC SURVEYMEANS
Эта процедура также используется для измерения SD наряду с некоторыми дополнительными функциями, такими как измерение SD для категориальных переменных, а также для получения оценок отклонений.
Синтаксис
Синтаксис использования PROC SURVEYMEANS —
PROC SURVEYMEANS options statistic-keywords ; BY variables ; CLASS variables ; VAR variables ;
Ниже приведено описание используемых параметров:
-
BY — указывает переменные, используемые для создания групп наблюдений.
-
CLASS — указывает переменные, используемые для категориальных переменных.
-
VAR — указывает переменные, для которых будет рассчитываться SD.
BY — указывает переменные, используемые для создания групп наблюдений.
CLASS — указывает переменные, используемые для категориальных переменных.
VAR — указывает переменные, для которых будет рассчитываться SD.
пример
В приведенном ниже примере описано использование опции класса, которая создает статистику для каждого из значений в переменной класса.
proc surveymeans data = CARS1 STD; class type; var type horsepower; ods output statistics = rectangle; run; proc print data = rectangle; run;
Когда мы выполняем приведенный выше код, он дает следующий вывод —
Использование опции BY
Приведенный ниже код дает пример опции BY. В нем результат группируется для каждого значения в опции BY.
пример
proc surveymeans data = CARS1 STD; var horsepower; BY make; ods output statistics = rectangle; run; proc print data = rectangle; run;
Когда мы выполняем приведенный выше код, он дает следующий вывод —
Результат для make = «Audi»
Результат для марки = «BMW»
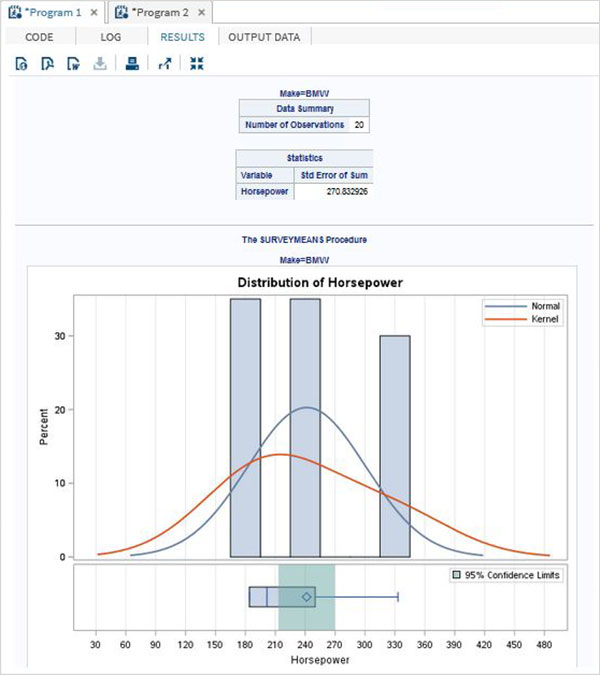
SAS — Распределение частот
Распределение частот — это таблица, показывающая частоту точек данных в наборе данных. Каждая запись в таблице содержит частоту или количество вхождений значений в определенной группе или интервале, и, таким образом, таблица суммирует распределение значений в выборке.
SAS предоставляет процедуру PROC FREQ для расчета частотного распределения точек данных в наборе данных.
Синтаксис
Основной синтаксис для вычисления распределения частот в SAS —
PROC FREQ DATA = Dataset ; TABLES Variable_1 ; BY Variable_2 ;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
Переменные_1 — это имена переменных набора данных, распределение частот которого необходимо рассчитать.
-
Переменные_2 — это переменные, которые классифицировали результат распределения частоты.
Набор данных — это имя набора данных.
Переменные_1 — это имена переменных набора данных, распределение частот которого необходимо рассчитать.
Переменные_2 — это переменные, которые классифицировали результат распределения частоты.
Распределение частоты одной переменной
Мы можем определить распределение частоты одной переменной с помощью PROC FREQ. В этом случае результат покажет частоту каждого значения переменной. Результат также показывает процентное распределение, совокупную частоту и совокупный процент.
пример
В приведенном ниже примере мы находим частотное распределение переменной лошадиной силы для набора данных с именем CARS1, который создается из библиотеки SASHELP.CARS. Мы можем видеть результат, разделенный на две категории результатов. Один для каждой марки автомобиля.
PROC SQL;
create table CARS1 as
SELECT make, model, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1 ;
tables horsepower;
by make;
run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
Многократное частотное распределение
Мы можем найти частотные распределения для нескольких переменных, которые группируют их во все возможные комбинации.
пример
В приведенном ниже примере мы рассчитываем распределение частоты для марки автомобиля, сгруппированного по типу автомобиля, а также распределение частоты для каждого типа автомобиля, сгруппированного по каждой марке.
proc FREQ data = CARS1 ; tables make type; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
Распределение частот с весом
С помощью опции веса мы можем рассчитать распределение частоты, смещенное с весом переменной. Здесь значение переменной берется как количество наблюдений, а не как количество значений.
пример
В приведенном ниже примере мы рассчитываем распределение частот переменных и типа с весом, назначенным для лошадиных сил.
proc FREQ data = CARS1 ; tables make type; weight horsepower; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
SAS — кросс-таблицы
Кросс-табуляция включает в себя создание кросс-таблиц, также называемых условными таблицами, с использованием всех возможных комбинаций двух или более переменных. В SAS он создается с помощью PROC FREQ вместе с опцией TABLES . Например — если нам нужна частота каждой модели для каждой марки в каждой категории автомобилей, то нам нужно использовать опцию TABLES в PROC FREQ.
Синтаксис
Основной синтаксис для применения кросс-табуляции в SAS —
PROC FREQ DATA = dataset; TABLES variable_1*Variable_2;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
Переменная_1 и Переменная_2 — это имена переменных набора данных, распределение частот которых необходимо рассчитать.
Набор данных — это имя набора данных.
Переменная_1 и Переменная_2 — это имена переменных набора данных, распределение частот которых необходимо рассчитать.
пример
Рассмотрим случай определения количества типов автомобилей под каждой маркой автомобилей из набора данных cars1, созданного из SASHELP.CARS, как показано ниже. В этом случае нам нужны отдельные значения частоты, а также сумма значений частоты по маркам и типам. Мы можем наблюдать, что результат показывает значения по строкам и столбцам.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc FREQ data = CARS1;
tables make*type;
run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
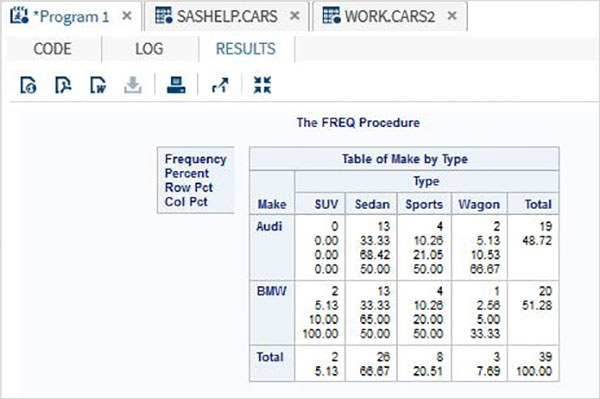
Перекрестная таблица из 3 переменных
Когда у нас есть три переменные, мы можем сгруппировать 2 из них и скрестить каждую из этих двух с третьим допустимым. Таким образом, в результате мы имеем два кросс-таблицы.
пример
В приведенном ниже примере мы находим частоту каждого типа автомобиля и каждой модели автомобиля по отношению к марке автомобиля. Также мы используем опции nocol и norow, чтобы избежать значений суммы и процента.
proc FREQ data = CARS2 ; tables make * (type model) / nocol norow nopercent; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
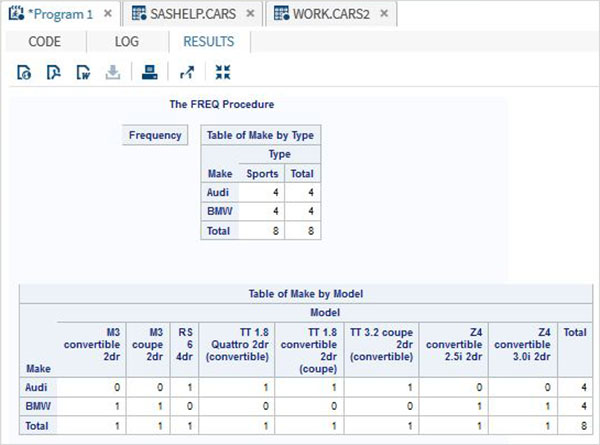
Перекрестная таблица из 4 переменных
С 4 переменными количество парных комбинаций увеличивается до 4. Каждая переменная из группы 1 соединяется с каждой переменной из группы 2.
пример
В приведенном ниже примере мы находим частоту длины автомобиля для каждой марки и каждой модели. Аналогично частота лошадиных сил для каждой марки и каждой модели.
proc FREQ data = CARS2 ; tables (make model) * (length horsepower) / nocol norow nopercent; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
SAS — T Тесты
T-тесты выполняются для вычисления доверительных интервалов для одного или двух независимых образцов путем сравнения их средних и средних различий. Процедура SAS с именем PROC TTEST используется для проведения t-тестов для одной переменной и пары переменных.
Синтаксис
Основной синтаксис применения PROC TTEST в SAS —
PROC TTEST DATA = dataset; VAR variable; CLASS Variable; PAIRED Variable_1 * Variable_2;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
Переменная_1 и Переменная_2 — это имена переменных набора данных, используемого в t-тесте.
Набор данных — это имя набора данных.
Переменная_1 и Переменная_2 — это имена переменных набора данных, используемого в t-тесте.
пример
Ниже мы видим один пример t-теста, в котором находят оценку t-теста для переменной мощности с 95-процентным доверительным интервалом.
PROC SQL;
create table CARS1 as
SELECT make, type, invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc ttest data = cars1 alpha = 0.05 h0 = 0;
var horsepower;
run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
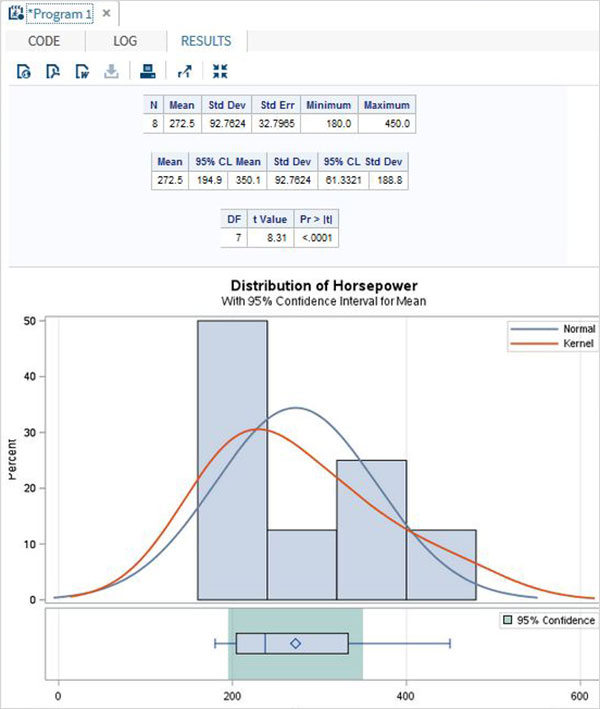
Парный Т-тест
Парный T-тест проводится для проверки того, являются ли две зависимые переменные статистически отличными друг от друга или нет.
пример
Поскольку длина и вес автомобиля будут зависеть друг от друга, мы применяем парный Т-тест, как показано ниже.
proc ttest data = cars1 ; paired weight*length; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
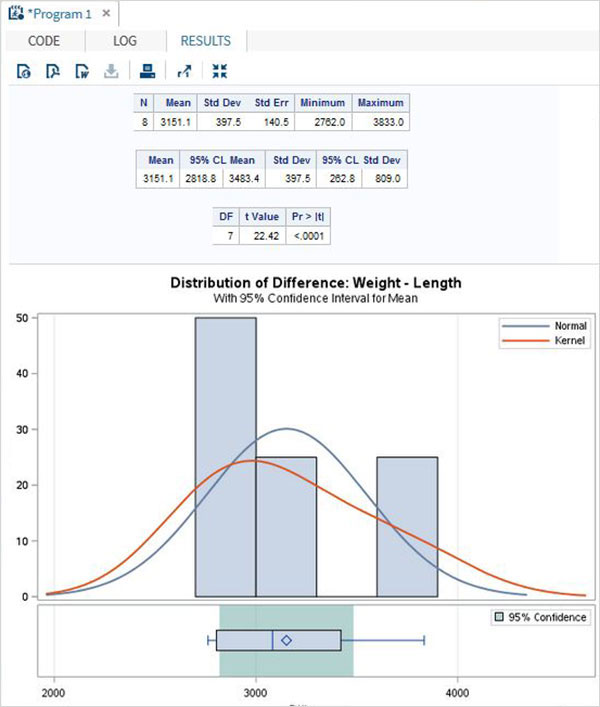
Два образца t-теста
Этот t-тест предназначен для сравнения средних значений одной и той же переменной между двумя группами.
пример
В нашем случае мы сравниваем среднее значение переменной мощности для двух разных марок автомобилей («Ауди» и «БМВ»).
proc ttest data = cars1 sides = 2 alpha = 0.05 h0 = 0; title "Two sample t-test example"; class make; var horsepower; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
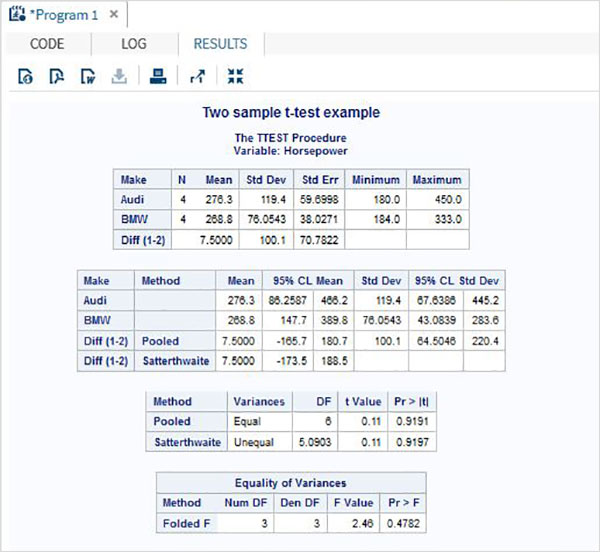
SAS — корреляционный анализ
Корреляционный анализ имеет дело с отношениями между переменными. Коэффициент корреляции является мерой линейной связи между двумя переменными. Значения коэффициента корреляции всегда находятся между -1 и +1. SAS предоставляет процедуру PROC CORR для нахождения коэффициентов корреляции между парой переменных в наборе данных.
Синтаксис
Основной синтаксис для применения PROC CORR в SAS —
PROC CORR DATA = dataset options; VAR variable;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
Опции — это дополнительная опция с такой процедурой, как построение матрицы и т. Д.
-
Переменная — это имя переменной набора данных, используемого для нахождения корреляции.
Набор данных — это имя набора данных.
Опции — это дополнительная опция с такой процедурой, как построение матрицы и т. Д.
Переменная — это имя переменной набора данных, используемого для нахождения корреляции.
пример
Коэффициенты корреляции между парой переменных, доступных в наборе данных, можно получить, используя их имена в выражении VAR. В приведенном ниже примере мы используем набор данных CARS1 и получаем результат, показывающий коэффициенты корреляции между лошадиными силами и весом.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc corr data = cars1 ;
VAR horsepower weight ;
BY make;
run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
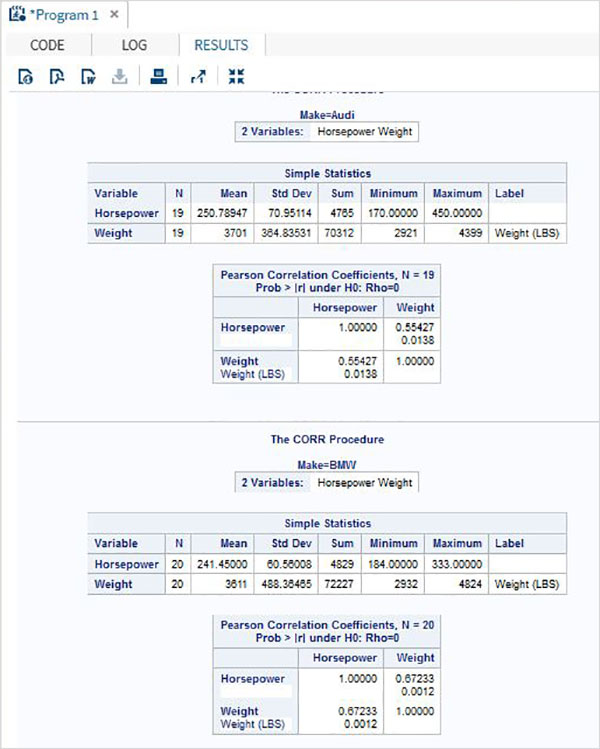
Корреляция между всеми переменными
Коэффициенты корреляции между всеми переменными, доступными в наборе данных, можно получить, просто применив процедуру с именем набора данных.
пример
В приведенном ниже примере мы используем набор данных CARS1 и получаем результат, показывающий коэффициенты корреляции между каждой парой переменных.
proc corr data = cars1 ; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
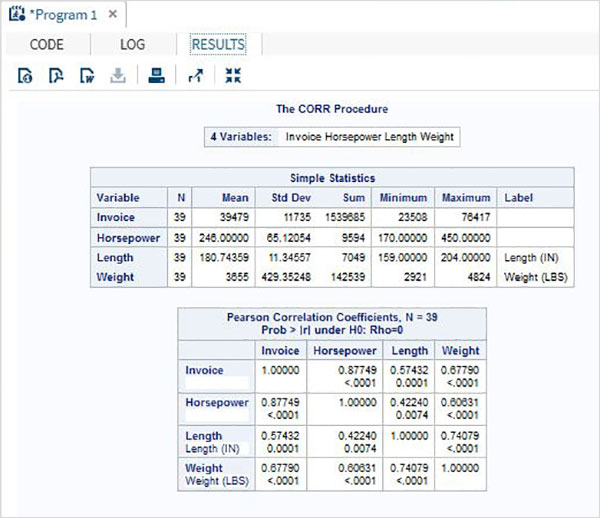
Матрица корреляции
Мы можем получить матрицу рассеяния между переменными, выбрав опцию для построения матрицы в операторе PROC .
пример
В приведенном ниже примере мы получаем матрицу между лошадиными силами и весом.
proc corr data = cars1 plots = matrix ; VAR horsepower weight ; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
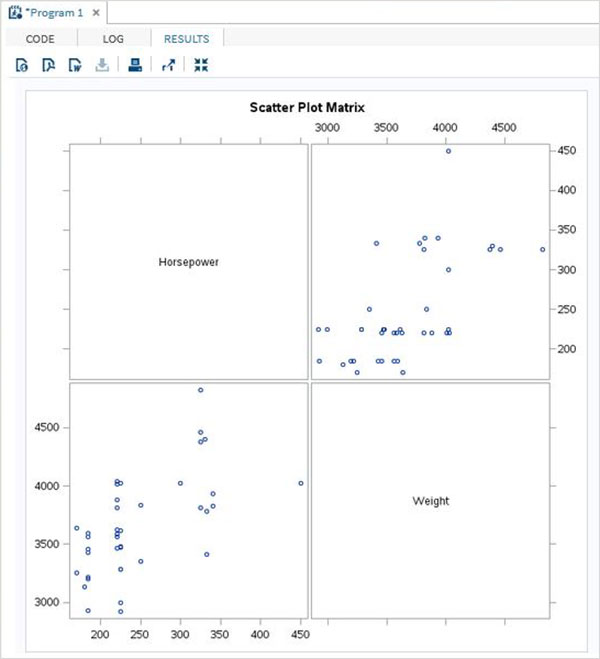
SAS — линейная регрессия
Линейная регрессия используется для определения взаимосвязи между зависимой переменной и одной или несколькими независимыми переменными. Предлагается модель взаимосвязи, и оценки значений параметров используются для разработки оценочного уравнения регрессии.
Затем используются различные тесты, чтобы определить, является ли модель удовлетворительной. Если это так, оцененное уравнение регрессии может использоваться для прогнозирования значения зависимой переменной с учетом значений для независимых переменных. В SAS процедура PROC REG используется для нахождения модели линейной регрессии между двумя переменными.
Синтаксис
Основной синтаксис для применения PROC REG в SAS —
PROC REG DATA = dataset; MODEL variable_1 = variable_2;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
variable_1 и variable_2 являются именами переменных набора данных, используемого при поиске корреляции.
Набор данных — это имя набора данных.
variable_1 и variable_2 являются именами переменных набора данных, используемого при поиске корреляции.
пример
В приведенном ниже примере показан процесс поиска корреляции между двумя переменными лошадиными силами и весом автомобиля с помощью PROC REG. В результате мы видим значения перехвата, которые можно использовать для формирования уравнения регрессии.
PROC SQL;
create table CARS1 as
SELECT invoice, horsepower, length, weight
FROM
SASHELP.CARS
WHERE make in ('Audi','BMW')
;
RUN;
proc reg data = cars1;
model horsepower = weight ;
run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
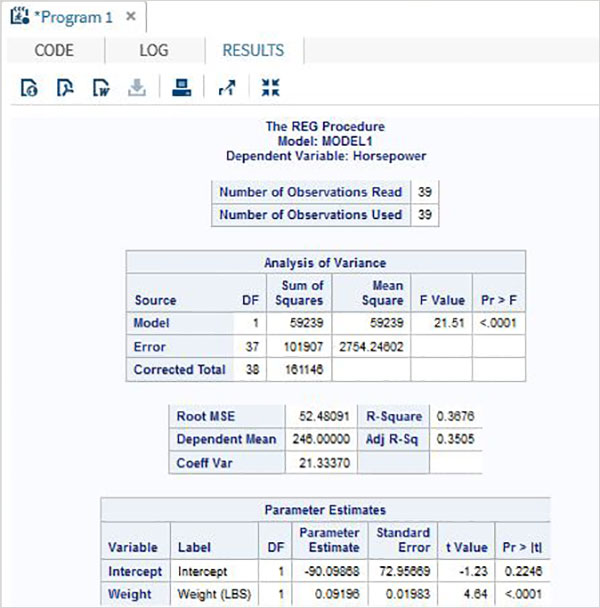
Приведенный выше код также дает графическое представление различных оценок модели, как показано ниже. Будучи продвинутой процедурой SAS, она просто не останавливается на выдаче значений перехвата в качестве вывода.
SAS — Мягкий Альтман Анализ
Анализ Бланда-Альтмана — это процесс проверки степени согласия или несогласия между двумя методами, предназначенными для измерения одних и тех же параметров. Высокая корреляция между методами указывает на то, что при анализе данных была выбрана достаточно хорошая выборка. В SAS мы создаем график Бланда-Альтмана, вычисляя среднее, верхний и нижний пределы значений переменных. Затем мы используем PROC SGPLOT для создания сюжета Бланда-Альтмана.
Синтаксис
Основной синтаксис применения PROC SGPLOT в SAS —
PROC SGPLOT DATA = dataset; SCATTER X = variable Y = Variable; REFLINE value;
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
Оператор SCATTER создает график графика рассеяния значения, представленного в форме X и Y.
-
REFLINE создает горизонтальную или вертикальную контрольную линию.
Набор данных — это имя набора данных.
Оператор SCATTER создает график графика рассеяния значения, представленного в форме X и Y.
REFLINE создает горизонтальную или вертикальную контрольную линию.
пример
В приведенном ниже примере мы берем результат двух экспериментов, сгенерированных двумя методами, названными new и old. Мы рассчитываем различия в значениях переменных, а также среднее значение переменных одного и того же наблюдения. Мы также рассчитываем значения стандартного отклонения, которые будут использоваться в верхней и нижней границе расчета.
Результат показывает график Бланда-Альтмана как график рассеяния.
data mydata;
input new old;
datalines;
31 45
27 12
11 37
36 25
14 8
27 15
3 11
62 42
38 35
20 9
35 54
62 67
48 25
77 64
45 53
32 42
16 19
15 27
22 9
8 38
24 16
59 25
;
data diffs ;
set mydata ;
/* calculate the difference */
diff = new-old ;
/* calculate the average */
mean = (new+old)/2 ;
run ;
proc print data = diffs;
run;
proc sql noprint ;
select mean(diff)-2*std(diff), mean(diff)+2*std(diff)
into :lower, :upper
from diffs ;
quit;
proc sgplot data = diffs ;
scatter x = mean y = diff;
refline 0 &upper &lower / LABEL = ("zero bias line" "95% upper limit" "95%
lower limit");
TITLE 'Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;
Когда приведенный выше код выполняется, мы получаем следующий результат —
Улучшенная модель
В расширенной модели вышеуказанной программы мы получаем подгонку кривой уровня достоверности 95%.
proc sgplot data = diffs ;
reg x = new y = diff/clm clmtransparency = .5;
needle x = new y = diff/baseline = 0;
refline 0 / LABEL = ('No diff line');
TITLE 'Enhanced Bland-Altman Plot';
footnote 'Accurate prediction with 10% homogeneous error';
run ;
quit ;
Когда приведенный выше код выполняется, мы получаем следующий результат —
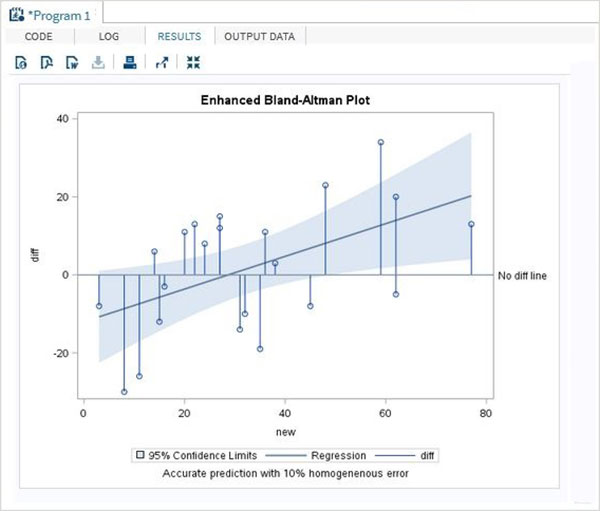
SAS — Площадь Чи
Критерий хи-квадрат используется для изучения связи между двумя категориальными переменными. Его можно использовать для проверки как степени зависимости, так и степени независимости между переменными. SAS использует PROC FREQ вместе с опцией chisq для определения результата теста хи-квадрат.
Синтаксис
Основной синтаксис для применения PROC FREQ для теста хи-квадрат в SAS —
PROC FREQ DATA = dataset; TABLES variables /CHISQ TESTP = (percentage values);
Ниже приведено описание используемых параметров:
-
Набор данных — это имя набора данных.
-
Переменные — это имена переменных набора данных, которые используются в тесте хи-квадрат.
-
Процентные значения в операторе TESTP представляют процентное содержание уровней переменной.
Набор данных — это имя набора данных.
Переменные — это имена переменных набора данных, которые используются в тесте хи-квадрат.
Процентные значения в операторе TESTP представляют процентное содержание уровней переменной.
пример
В приведенном ниже примере мы рассмотрим критерий хи-квадрат для переменной с именем type в наборе данных SASHELP.CARS. Эта переменная имеет шесть уровней, и мы назначаем процент каждому уровню в соответствии с дизайном теста.
proc freq data = sashelp.cars; tables type /chisq testp = (0.20 0.12 0.18 0.10 0.25 0.15); run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
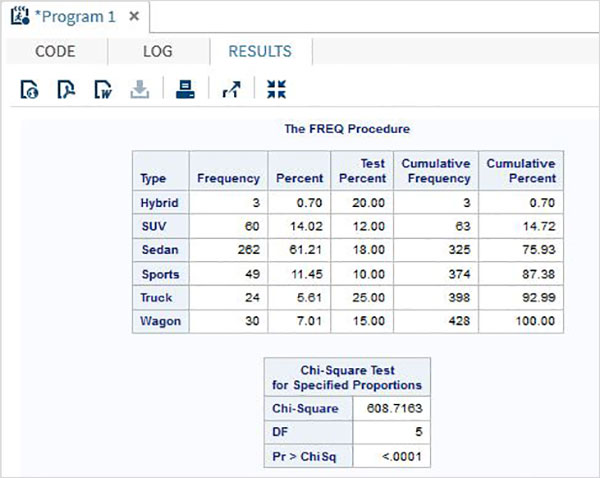
Мы также получаем гистограмму, показывающую отклонение типа переменной, как показано на следующем снимке экрана.
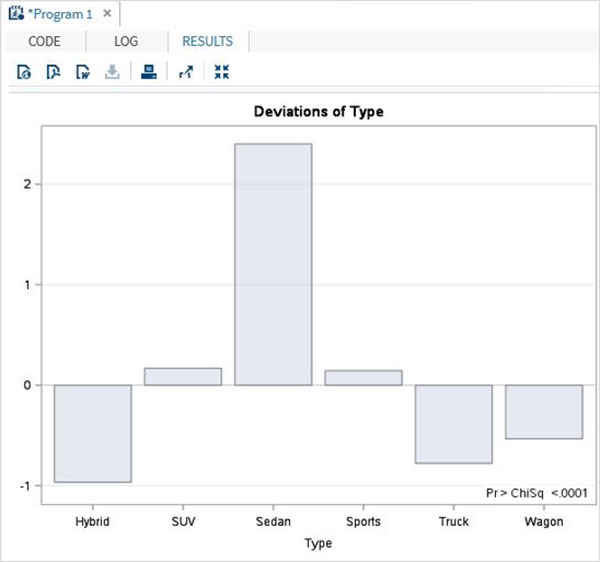
Двухсторонний хи-квадрат
Двусторонний критерий хи-квадрат используется, когда мы применяем тесты к двум переменным набора данных.
пример
В приведенном ниже примере мы применяем критерий хи-квадрат к двум переменным с именем type и origin. Результат показывает табличную форму всех комбинаций этих двух переменных.
proc freq data = sashelp.cars; tables type*origin /chisq ; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
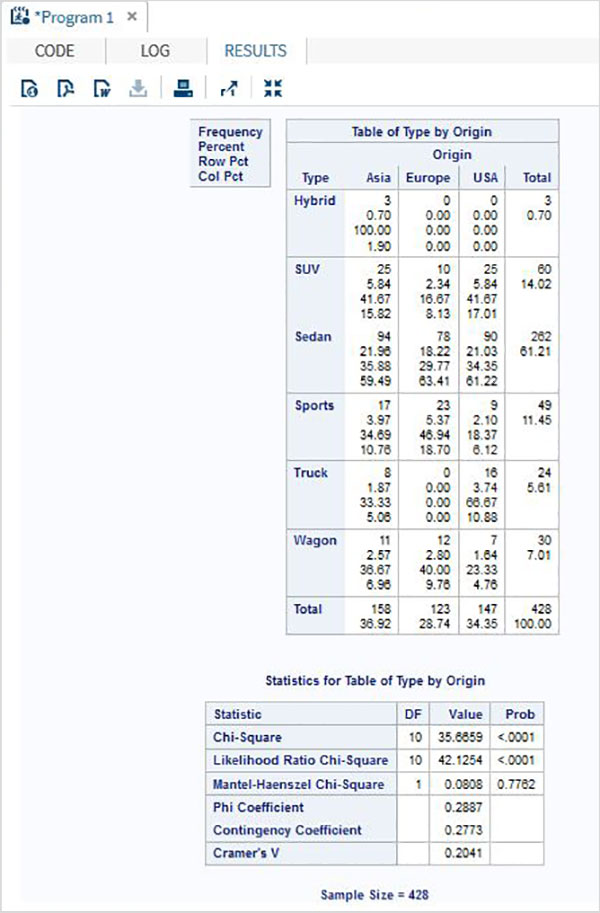
SAS — Точные тесты Fishers
Точный критерий Фишера — это статистический тест, используемый для определения наличия неслучайных ассоциаций между двумя категориальными переменными. В SAS это выполняется с использованием PROC FREQ . Мы используем опцию Таблицы, чтобы использовать две переменные, подвергнутые точному тесту Фишера.
Синтаксис
Основной синтаксис для применения теста Fisher Exact в SAS —
PROC FREQ DATA = dataset ; TABLES Variable_1*Variable_2 / fisher;
Ниже приведено описание используемых параметров:
-
набор данных — это имя набора данных.
-
Переменная_1 * Переменная_2 — это переменные из набора данных.
набор данных — это имя набора данных.
Переменная_1 * Переменная_2 — это переменные из набора данных.
Применение точного теста Фишера
Чтобы применить точный тест Фишера, мы выбираем две категориальные переменные с именами Test1 и Test2 и их результат. Мы используем PROC FREQ, чтобы применить тест, показанный ниже.
пример
data temp; input Test1 Test2 Result @@; datalines; 1 1 3 1 2 1 2 1 1 2 2 3 ; proc freq; tables Test1*Test2 / fisher; run;
Когда приведенный выше код выполняется, мы получаем следующий результат —
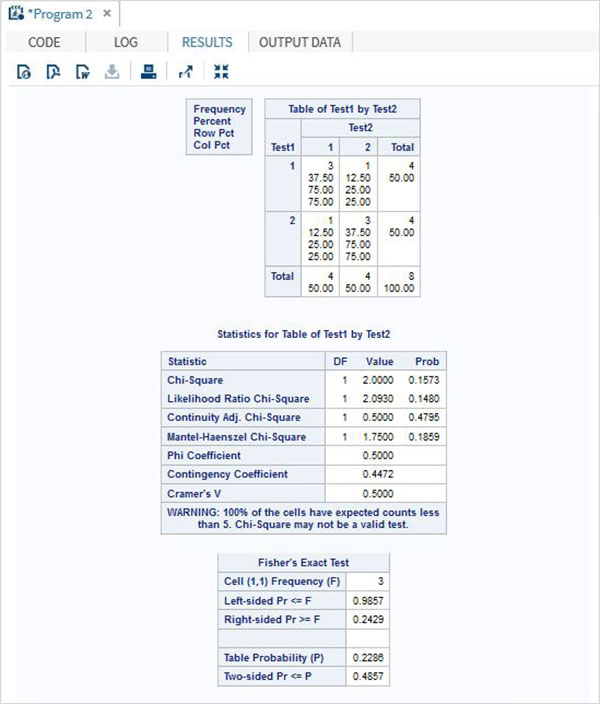
SAS — анализ повторных измерений
Повторный анализ измерений используется, когда все члены случайной выборки измеряются в ряде различных условий. Поскольку образец подвергается воздействию каждого условия по очереди, измерение зависимой переменной повторяется. Использование стандартного ANOVA в этом случае нецелесообразно, так как не удается смоделировать корреляцию между повторными измерениями.
Необходимо четко понимать разницу между дизайном с повторными измерениями и простым многовариантным дизайном. Для обоих членов выборки измеряются несколько раз или в испытаниях, но в схеме с повторными измерениями каждое испытание представляет собой измерение одной и той же характеристики в разных условиях.
В SAS PROC GLM используется для анализа повторных измерений.
Синтаксис
Основной синтаксис для PROC GLM в SAS —
PROC GLM DATA = dataset; CLASS variable; MODEL variables = group / NOUNI; REPEATED TRIAL n;
Ниже приведено описание используемых параметров:
-
набор данных — это имя набора данных.
-
КЛАСС дает переменным переменную, используемую в качестве классификационной переменной.
-
MODEL определяет модель для подгонки, используя определенные переменные из набора данных.
-
REPEATED определяет количество повторных измерений каждой группы для проверки гипотезы.
набор данных — это имя набора данных.
КЛАСС дает переменным переменную, используемую в качестве классификационной переменной.
MODEL определяет модель для подгонки, используя определенные переменные из набора данных.
REPEATED определяет количество повторных измерений каждой группы для проверки гипотезы.
пример
Рассмотрим приведенный ниже пример, в котором у нас есть две группы людей, подвергнутых испытанию на эффект наркотика. Время реакции каждого человека записывается для каждого из четырех протестированных типов лекарств. Здесь проводится 5 испытаний для каждой группы людей, чтобы увидеть силу корреляции между эффектом четырех типов наркотиков.
DATA temp; INPUT person group $ r1 r2 r3 r4; CARDS; 1 A 2 1 6 5 2 A 5 4 11 9 3 A 6 14 12 10 4 A 2 4 5 8 5 A 0 5 10 9 6 B 9 11 16 13 7 B 12 4 13 14 8 B 15 9 13 8 9 B 6 8 12 5 10 B 5 7 11 9 ; RUN; PROC PRINT DATA = temp ; RUN; PROC GLM DATA = temp; CLASS group; MODEL r1-r4 = group / NOUNI ; REPEATED trial 5; RUN;
Когда приведенный выше код выполняется, мы получаем следующий результат —
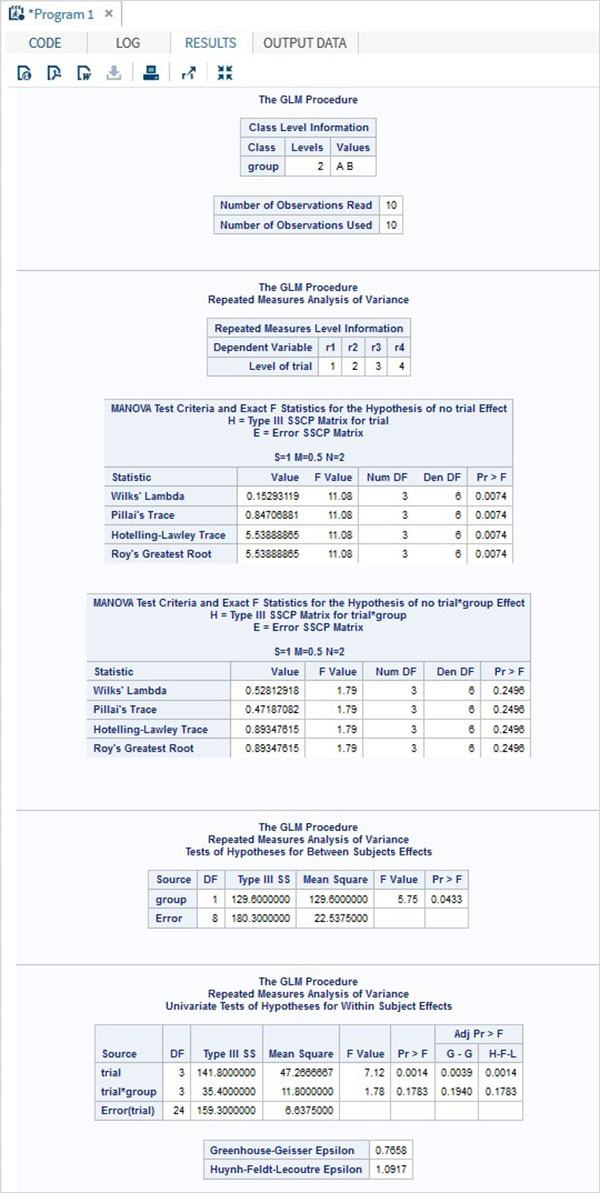
SAS — One Way Anova
ANOVA расшифровывается как дисперсионный анализ. В SAS это делается с помощью PROC ANOVA . Он выполняет анализ данных из широкого спектра экспериментальных проектов. В этом процессе переменная непрерывного отклика, известная как зависимая переменная, измеряется в экспериментальных условиях, определенных классификационными переменными, известными как независимые переменные. Предполагается, что вариация в ответе обусловлена влиянием классификации, а оставшаяся вариация учитывает случайную ошибку.
Синтаксис
Основной синтаксис применения PROC ANOVA в SAS —
PROC ANOVA dataset ; CLASS Variable; MODEL Variable1 = variable2 ; MEANS ;
Ниже приведено описание используемых параметров:
-
набор данных — это имя набора данных.
-
КЛАСС дает переменным переменную, используемую в качестве классификационной переменной.
-
MODEL определяет модель для подгонки, используя определенные переменные из набора данных.
-
Переменная_1 и Переменная_2 — это имена переменных набора данных, используемого в анализе.
-
СРЕДСТВО определяет тип расчета и сравнения средств.
набор данных — это имя набора данных.
КЛАСС дает переменным переменную, используемую в качестве классификационной переменной.
MODEL определяет модель для подгонки, используя определенные переменные из набора данных.
Переменная_1 и Переменная_2 — это имена переменных набора данных, используемого в анализе.
СРЕДСТВО определяет тип расчета и сравнения средств.
Применяя ANOVA
Давайте теперь разберемся с концепцией применения ANOVA в SAS.
пример
Давайте рассмотрим набор данных SASHELP.CARS. Здесь мы изучаем зависимость между переменным типом автомобиля и их лошадиными силами. Поскольку тип автомобиля является переменной с категориальными значениями, мы принимаем ее как переменную класса и используем обе эти переменные в МОДЕЛИ.
PROC ANOVA DATA = SASHELPS.CARS; CLASS type; MODEL horsepower = type; RUN;
Когда приведенный выше код выполняется, мы получаем следующий результат —
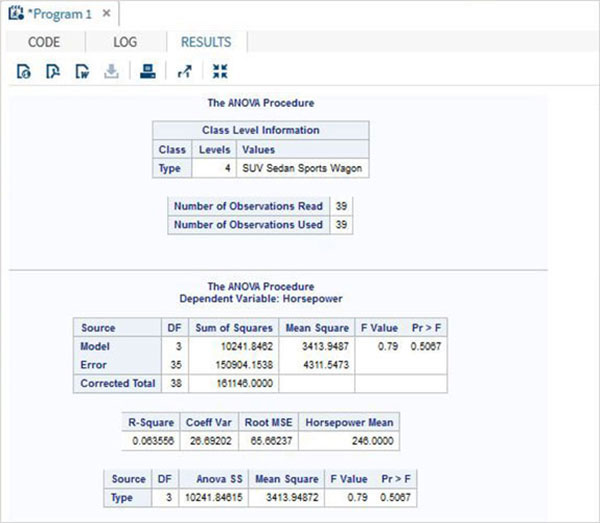
Применение ANOVA со средствами
Давайте теперь поймем концепцию применения ANOVA со средствами в SAS.
пример
Мы также можем расширить модель, применив инструкцию MEANS, в которой мы используем турецкий метод Studentized для сравнения средних значений различных типов автомобилей. Категории типов автомобилей перечислены со средним значением лошадиных сил в каждой категории вместе с некоторыми дополнительными значениями, такими как среднеквадратичная ошибка и т. д.
PROC ANOVA DATA = SASHELPS.CARS; CLASS type; MODEL horsepower = type; MEANS type / tukey lines; RUN;
Когда приведенный выше код выполняется, мы получаем следующий результат —
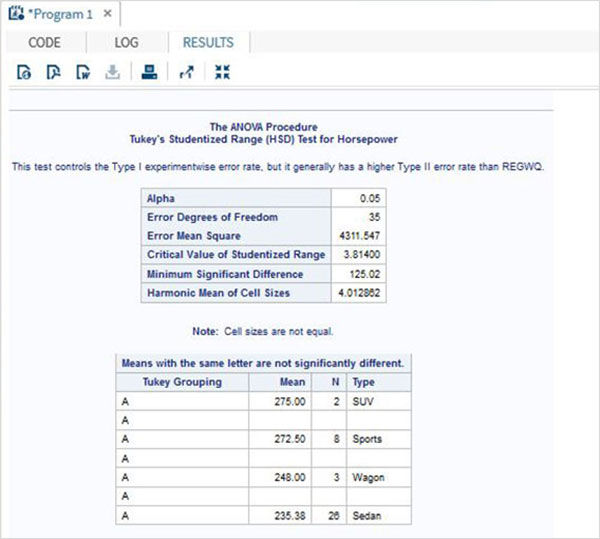
SAS — Проверка гипотез
Проверка гипотез — это использование статистики для определения вероятности того, что данная гипотеза верна. Обычный процесс проверки гипотез состоит из четырех этапов, как показано ниже.
Шаг 1
Сформулируйте нулевую гипотезу H0 (обычно, что наблюдения являются результатом чистой случайности) и альтернативную гипотезу H1 (обычно, что наблюдения показывают реальный эффект в сочетании с компонентом случайного изменения).
Шаг 2
Определите тестовую статистику, которая может быть использована для оценки истинности нулевой гипотезы.
Шаг 3
Вычислите P-значение, которое является вероятностью того, что тестовая статистика, по крайней мере, столь же значимая, как и наблюдаемая, будет получена при условии, что нулевая гипотеза верна. Чем меньше значение P, тем сильнее доказательства против нулевой гипотезы.
Шаг 4
Сравните значение p с приемлемым значением значимости альфа (иногда называемым значением альфа). Если р <= альфа, то наблюдаемый эффект является статистически значимым, нулевая гипотеза исключается, и альтернативная гипотеза верна.
Язык программирования SAS имеет функции для проведения различных типов проверки гипотез, как показано ниже.