С бумом электронной коммерции в последние годы я стал поклонником приложений для сравнения цен. Каждая покупка, которую я совершаю онлайн (или даже в автономном режиме), является результатом тщательного изучения сайтов, предлагающих этот продукт.
Некоторые из приложений, которые я использую, включают RedLaser, ShopSavvy и BuyHatke, которые проделали большую работу по повышению прозрачности и экономии времени потребителей.
Задумывались ли вы, как эти приложения получают эти важные данные? В большинстве случаев процесс, используемый приложениями, является очисткой веб-страниц .
Веб-скребинг определен

Соскреб в Интернете — это процесс извлечения данных из Интернета. С помощью правильных инструментов можно извлечь все, что вам видно. В этом посте мы сосредоточимся на написании программ, которые автоматизируют этот процесс и помогут вам собрать огромные объемы данных за относительно короткое время. Помимо приведенного мною примера, скребок имеет множество применений, таких как SEO-отслеживание, отслеживание работы, анализ новостей и — мой любимый — анализ настроений в социальных сетях!
Примечание осторожности
Перед тем, как отправиться в путешествие по интернету, убедитесь, что вы знаете о юридических проблемах. Многие веб-сайты специально запрещают соскоб в своих условиях обслуживания. Например, цитируя Medium : «Сканирование Сервисов разрешено, если оно выполнено в соответствии с положениями нашего файла robots.txt, но удаление Сервисов запрещено». Удаление сайтов, которые не допускают удаление, может фактически вывести вас в черный список! Как и любой другой инструмент, очистка веб-страниц может быть использована для таких целей, как копирование содержимого других сайтов. Соскоб также привел ко многим судебным процессам.
Настройка кода
Теперь, когда вы знаете, что мы должны действовать осторожно, давайте приступим к очистке. Соскребание может быть сделано на любом языке программирования, и мы рассмотрели его для Node некоторое время назад В этом посте мы собираемся использовать Python для простоты языка и доступности пакетов, облегчающих процесс.
Что лежит в основе процесса?
Когда вы заходите на сайт в Интернете, вы загружаете HTML-код, который анализируется и отображается вашим веб-браузером. Этот HTML-код содержит всю информацию, которая видна вам. Поэтому необходимую информацию (например, цену) можно получить, проанализировав этот HTML-код. Вы можете использовать регулярные выражения для поиска вашей иглы в стоге сена или использовать библиотеку для анализа HTML и получения необходимых данных.
В Python мы будем использовать модуль Beautiful Soup для анализа этих данных HTML. Вы можете установить модуль с помощью установщика, такого как pip
pip install beautifulsoup4
Кроме того, вы можете построить его из источника. Шаги установки перечислены на странице документации модуля.
После того, как это будет установлено, мы будем широко выполнять следующие шаги:
- отправить запрос на URL
- получить ответ
- проанализировать ответ, чтобы найти необходимые данные.
В демонстрационных целях мы будем использовать мой блог http://dada.theblogbowl.in/
Первые два шага довольно просты и могут быть выполнены следующим образом:
from urllib import urlopen
#Sending the http request
webpage = urlopen('http://my_website.com/').read()
Далее нам нужно предоставить ответ на
from bs4 import BeautifulSoup
#making the soup! yummy ;)
soup = BeautifulSoup(webpage, "html5lib")
Обратите внимание, что мы использовали html5lib Вы можете установить другой парсер для BeautifulSoup, как указано в их документации .
Разбор HTML
Теперь, когда мы предоставили HTML-код BeautifulSoup, давайте проверим несколько команд. Чтобы убедиться в правильности разметки HTML, давайте проверим заголовок страницы (в интерпретаторе Python):
>>> soup.title
<title>Transcendental Tech Talk</title>
>>> soup.title.text
u'Transcendental Tech Talk'
>>>
Далее мы переходим к извлечению определенных элементов со страницы. Допустим, я хочу извлечь список заголовков постов в моем блоге. Для этого мне нужно проанализировать структуру HTML, которую я выполняю с помощью Chrome Inspector (щелкните правой кнопкой мыши на элементе и выберите «Проверка элемента»). Подобные инструменты доступны и в других браузерах.
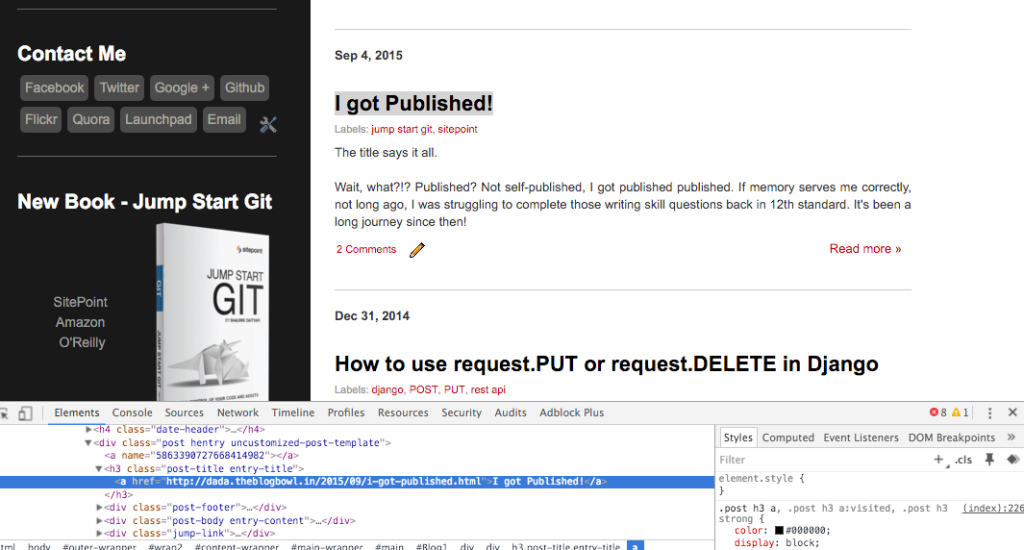
Использование Chrome Inspector для проверки HTML-структуры страницы
Как вы можете заметить, все заголовки размещаются под тегами h3post-titleentry-title Поиск всех элементов h3post-title Мы используем функцию find_allclass_
>>> titles = soup.find_all('h3', class_ = 'post-title') #Getting all titles
>>> titles[0].text
u'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n'
>>>
Тот же результат может быть достигнут при поиске элементов с классом post-title
>>> titles = soup.find_all(class_ = 'post-title') #Getting all items with class post-title
>>> titles[0].text
u'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n'
>>>
Если вы заинтересованы в ссылках для дальнейшего изучения элементов, вы можете запустить следующее:
>>> for title in titles:
... # Each title is in the form of <h3 ...><a href=...>Post Title<a/></h3>
... print title.find("a").get("href")
...
http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html
http://dada.theblogbowl.in/2015/09/i-got-published.html
http://dada.theblogbowl.in/2014/12/how-to-use-requestput-or-requestdelete.html
http://dada.theblogbowl.in/2014/12/zico-isl-and-atk.html
...
>>>
В BeautifulSoup есть много встроенных методов для навигации по HTML, некоторые из них проиллюстрированы ниже:
>>> titles[0].contents
[u'\n', <a href="http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html">Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips</a>, u'\n']
>>>
Обратите внимание, что вы также можете использовать атрибут childrenгенератор :
>>> titles[0].parent
<div class="post hentry uncustomized-post-template">\n<a name="6501973351448547458"></a>\n<h3 class="post-title entry-title">\n<a href="http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html">Kolkata #BergerXP IndiBlogger ...
>>>
Вы также можете использовать регулярные выражения для поиска класса CSS, как объяснено в документации .
Эмулировать логины с помощью Mechanize
То, что мы сделали до сих пор, по сути, это загрузка страницы и анализ ее содержимого. Тем не менее, веб-разработчик может заблокировать запросы через не браузеры, или часть веб-сайта может быть доступна только после входа в систему. Как мы должны идти о процессе тогда?
В первом случае нам нужно эмулировать браузер, когда мы отправляем запрос на страницу. Каждый HTTP-запрос имеет ряд связанных заголовков, которые включают информацию о таких вещах, как браузер посетителя, операционная система и размер экрана. Мы можем манипулировать этим и сделать так, чтобы браузер отправлял запрос.
Во втором случае нам необходимо войти на веб-сайт и поддерживать сеанс с использованием файлов cookie, чтобы получить доступ к закрытым областям. Давайте посмотрим, как это сделать, одновременно эмулируя браузер.
Мы будем использовать модуль cookielib Далее, мы будем использовать mechanize , который можно установить через инсталлятор, например pip
Мы войдем через эту страницу в The Blog Bowl , а затем перейдем на нашу страницу уведомлений . Код поясняется в комментариях:
import mechanize
import cookielib
from urllib import urlopen
from bs4 import BeautifulSoup
# Cookie Jar
cj = cookielib.LWPCookieJar()
browser = mechanize.Browser()
browser.set_cookiejar(cj)
browser.set_handle_robots(False)
browser.set_handle_redirect(True)
# Solving issue #1 by emulating a browser by adding HTTP headers
browser.addheaders = [('User-agent', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1')]
# Open Login Page
browser.open("http://theblogbowl.in/login/")
# Select Login form (1st form of the page)
browser.select_form(nr = 0)
# Alternate syntax - browser.select_form(name = "form_name")
# The first <input> tag of the form is a CSRF token
# Setting the 2nd and 3rd tags to email and password
browser.form.set_value("email@example.com", nr=1)
browser.form.set_value("password", nr=2)
# Logging in
response = browser.submit()
# Opening new page after login
soup = BeautifulSoup(browser.open('http://theblogbowl.in/notifications/').read(), "html5lib")

Структура страницы уведомлений
# Print notifications
print soup.find(class_ = "search_results").text
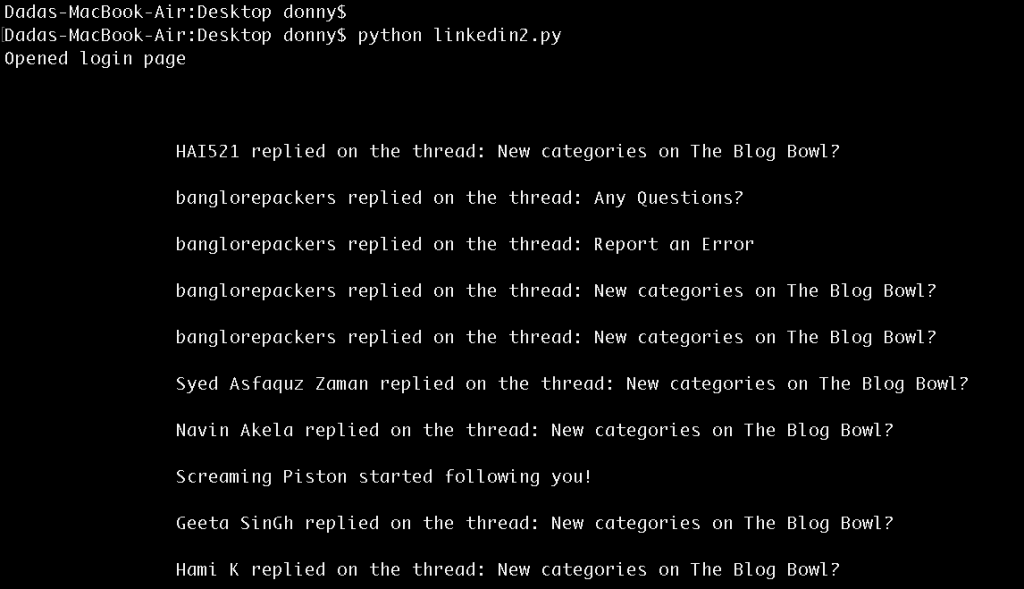
Результаты входа на страницу уведомлений
Заключительные слова
Как многие разработчики скажут вам, что все, что вы можете просматривать в Интернете, можно удалить. Из этого поста вы узнаете, что что-то за логином также может быть легко извлечено. В случаях, когда ваш IP заблокирован, вы можете замаскировать свой IP-адрес (или использовать другой). Чтобы выглядело, как будто человек обращается к данным, вы можете также поддерживать временную задержку между вашими запросами.
В связи с растущей потребностью в данных, веб-очистка (как по хорошим, так и по плохим причинам) будет только расти в будущем. Таким образом, желательно, чтобы вы понимали процесс, чтобы либо эффективно его использовать, либо уберечь себя от него!