Как вы думаете, сколько раз Ruby выделял память для строки «Lorem ipsum…» во время выполнения этого фрагмента кода?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str
… или как насчет запуска этого фрагмента?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = String.new(str)
…и этот?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup str2.upcase!
Или этот?
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..-1]
Ответы не то, что вы ожидаете! Оба интерпретатора Ruby MRI 1.9 и 1.8 используют оптимизацию, называемую «копировать при записи», чтобы избежать ненужного копирования больших строковых значений. Как и две недели назад, когда я обсуждал, как Ruby 1.9 работает быстрее со строками, содержащими 23 байта или меньше , сегодня я собираюсь глубоко погрузиться во внутренности Ruby, чтобы посмотреть, как работает оптимизация копирования при записи. Читайте дальше, чтобы узнать больше … и узнать, сколько строк было выделено фрагментами кода выше!
Ссылка на один объект String с двумя переменными
Две недели назад я использовал этот пример, чтобы показать, как Ruby разделяет строковые значения:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str
Вот диаграмма, показывающая, как это строковое значение совместно используется str и str2 :
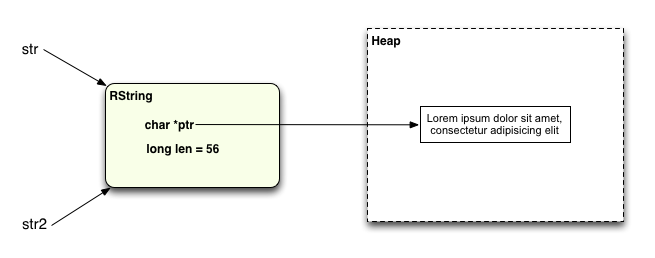
Как отметил Эван Феникс в комментарии к моему последнему сообщению, я был на самом деле не прав, используя это как пример общей строки. Здесь на самом деле вообще нет разделения: вместо этого у нас есть две переменные Ruby, указывающие или ссылающиеся на одно и то же значение RString.
Чтобы точно узнать, что содержится в любой структуре RString, и доказать, что это действительно происходит внутри интерпретатора Ruby, я написал простое расширение C, которое будет отображать шестнадцатеричный адрес данного значения RString вместе с шестнадцатеричным значением ptr , который является членом RString, который указывает на фактические строковые данные. Смотрите мой последний постдля более подробной информации о том, как работает RString. Я включил исходный код C для этого расширения ниже в «Приложение», если вас интересуют подробности.
Чтобы использовать мое расширение C, мне просто нужно потребовать его, создать экземпляр класса Debug и использовать его, вызвав display_string следующим образом:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Запустив этот код, я получаю следующий вывод:
$ ruby test.rb str: DEBUG: RString = 0x7fd64a84f620 DEBUG: ptr = 0x7fd64a416fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fd64a84f620 DEBUG: ptr = 0x7fd64a416fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56
Не удивительно: вы можете видеть единственную структуру RString по шестнадцатеричному адресу 0x7fd64a84f620, на которую указывают как str, так и str2 . И ptr , расположение фактических строковых данных для каждой переменной, также одинаково: 0x7fd64a416fe0. Очевидно, str и str2 оба ссылаются на один и тот же строковый объект Ruby.
Совместное использование одного строкового значения между двумя объектами String
Тем не менее, Ruby действительно разделяет строковые значения. В моем последнем посте я должен был использовать следующий код в качестве примера:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup
Теперь вызов метода Object.dup создаст вторую структуру RString, которая использует те же строковые данные, поскольку создается второй объект String. Я мог бы также использовать String.new следующим образом:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = String.new(str)
Вот что мы имеем сейчас:
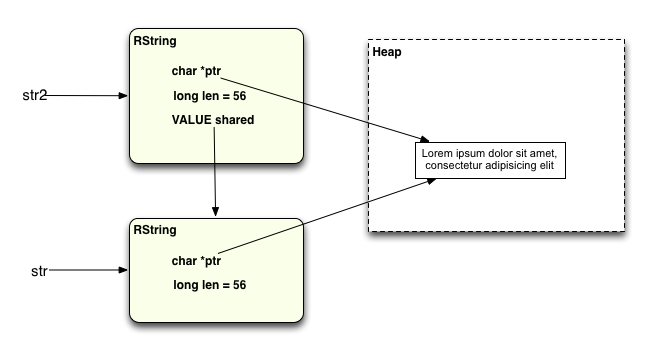
Это «Общая строка»: две структуры RString, которые используют одни и те же строковые данные. Вы можете видеть, что есть единственная копия фактических строковых данных, и что обе структуры RString имеют одинаковое значение для ptr и len . Кроме того, общее значение в str2 является указателем на структуру RString, с которой оно делится. Один и тот же шаблон может использоваться для 3, 4 или более структур RString, которые имеют одинаковое строковое значение.
Очевидные преимущества здесь:
- Вы экономите память, так как есть только одна копия строковых данных, а не две, и:
- Вы экономите время выполнения, так как нет необходимости вызывать malloc второй раз, чтобы выделить больше памяти из кучи.
Чтобы доказать, что это происходит с RString после вызова Object.dup , я снова вызову свой код display_string следующим образом:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Запуск этого:
$ ruby test.rb str: DEBUG: RString = 0x7fdd2904f4a8 DEBUG: ptr = 0x7fdd28d16fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fdd2904f430 DEBUG: ptr = 0x7fdd28d16fe0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56
Здесь вы можете видеть две различные структуры RString, как на картинке выше, с этими двумя адресами: 0x7fdd2904f4a8 и 0x7fdd2904f430. Но важная деталь, на которую следует обратить внимание, это то, что значение ptr , шестнадцатеричный адрес фактических строковых данных (0x7fdd28d16fe0), одинаково в обоих случаях!
Помните, концепция разделяемой строки — это чисто внутренняя оптимизация. Как разработчику Ruby вам не нужно знать, что на самом деле в памяти есть только одна копия строковых данных, и что оба объекта совместно используют ее. Просто думайте о них как о двух отдельных строковых значениях — в большинстве случаев вам не нужно думать об этом.
Примечание: эта оптимизация фактически не происходит, если строковое значение составляет 23 байта или меньше, с использованием встроенных строк, поскольку в этом случае строковые данные фактически сохраняются прямо внутри каждой структуры RString. Но при совместном использовании коротких строк мы бы не сэкономили много времени и памяти, а благодаря сохранению строковых данных внутри структуры RString Ruby может сэкономить еще больше времени и памяти. Оптимизация общей строки помогает вам больше всего, например, при работе с очень большими строковыми значениями, которые содержат тысячи или даже миллионы байтов. В этом сценарии приятно знать, что Ruby не будет копировать все эти строковые данные всякий раз, когда вы копируете строковое значение из одного объекта Ruby String в другой.
Копирование при записи
Очевидно, что здесь есть еще кое-что. Как два отдельных объекта String могут иметь одинаковое значение, если я могу изменить одно или оба их значения? Например, предположим, у меня есть две отдельные строки:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup
Что произойдет, если я сейчас изменю значение одного из двух объектов String, например, так:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup str2.upcase!
Теперь два значения разные:
puts str => "Lorem ipsum dolor sit amet, consectetur adipisicing elit" puts str2 => "LOREM IPSUM DOLOR SIT AMET, CONSECTETUR ADIPISICING ELIT"
Очевидно, что эти две строки больше не имеют одинаковое значение. Что произошло? Ну во-первых, в тот момент, когда вы звоните upcase! интерпретатор Ruby создает новую копию данных кучи строк для str2 следующим образом:
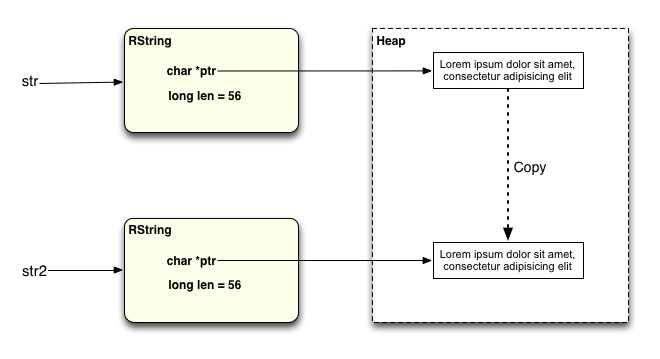
И тогда это выполняет upcase! операция над этой новой копией:
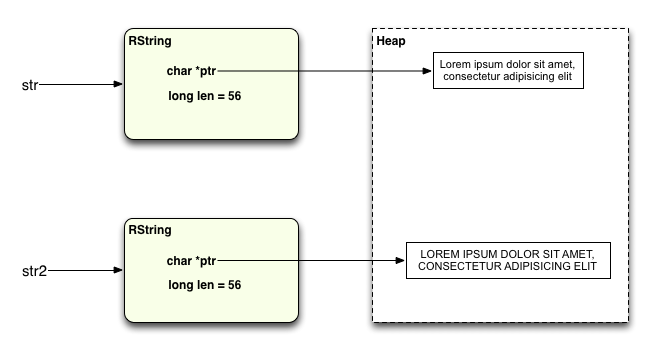
Как объяснил Саймон Рассел в комментарии к моему последнему сообщению, этот алгоритм называется «копировать при записи», что означает, что два строковых объекта фактически имеют одинаковое строковое значение до самого последнего момента, когда это возможно, тогда как два значения все те же. Затем, перед тем как одно из них изменится, Ruby создаст отдельную копию строки и применяет операцию записи ( upcase! В этом примере) к новой копии.
Давайте снова посмотрим на два значения RString, используя мой код display_string:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str.dup str2.upcase! puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Запустив это я получаю:
$ ruby test.rb str: DEBUG: RString = 0x7fa46b04ef90 DEBUG: ptr = 0x7fa46ac8b1d0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fa46b04ef68 DEBUG: ptr = 0x7fa46ac2e560 -> "LOREM IPSUM DOLOR SIT AMET, CONSECTETUR ADIPISICING ELIT" DEBUG: len = 56
Вы можете видеть, что две структуры RString теперь имеют разные значения для члена ptr — они больше не являются общими строками. Все это происходит прозрачно с разработчиком Ruby.
Как копирование при записи работает со String.slice
Следуя совету Роберта Сандерса, приведенному в другом комментарии к моему последнему сообщению, я решил взглянуть на то, как операция копирования при записи работает с другим методом Ruby String: slice . Я обнаружил, что большую часть времени для операции среза создается вторая копия строки. Например:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..25]
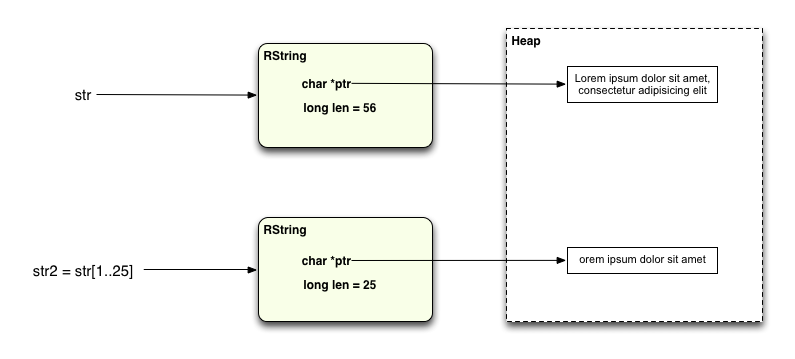
Однако часто подстрока представляет собой один символ или всего несколько символов из целевой строки:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..4]
В этом случае длина новой строки составляет менее 24 символов, поэтому нет необходимости снова вызывать malloc, чтобы выделить больше памяти. Короткая подстрока просто сохраняется в новом объекте RString:
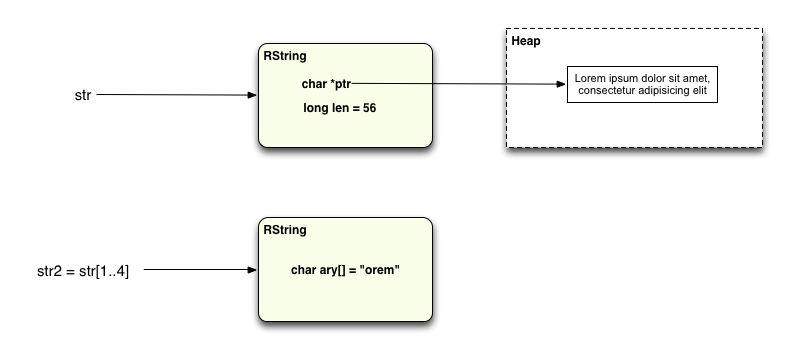
Однако одна интересная оптимизация, которую я обнаружил в реализации строки MRI Ruby, заключалась в том, что если вам случится взять подстроку, включающую все оставшиеся символы до конца исходной строки, например, так:
str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..-1]
… Тогда Ruby продолжит использовать те же строковые данные! Что он делает, так это устанавливает значение ptr для str2, чтобы оно указывало на те же строковые данные, но продвигалось вперед в памяти на надлежащее количество байтов, чтобы вернуть нужную подстроку:
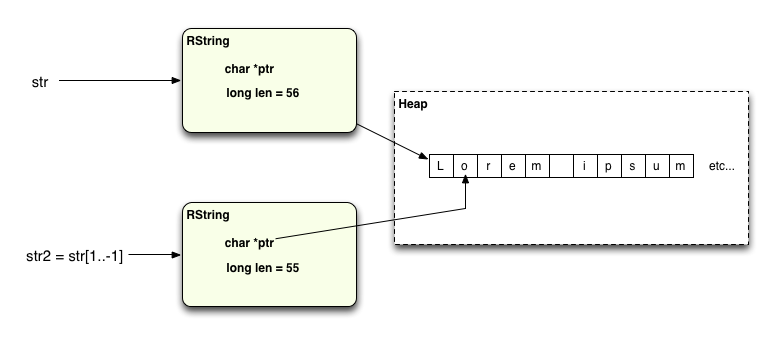
Давайте проверим это, используя тот же код отладки:
require_relative 'display_string' debug = Debug.new str = "Lorem ipsum dolor sit amet, consectetur adipisicing elit" str2 = str[1..-1] puts "str:" debug.display_string str puts puts "str2:" debug.display_string str2
Теперь я вижу, что значение ptr для str2 установлено в ptr + 1 от str !
$ ruby test.rb str: DEBUG: RString = 0x7fb71b04efa0 DEBUG: ptr = 0x7fb71ad007a0 -> "Lorem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 56 str2: DEBUG: RString = 0x7fb71b04ef78 DEBUG: ptr = 0x7fb71ad007a1 -> "orem ipsum dolor sit amet, consectetur adipisicing elit" DEBUG: len = 55
Для разработчиков Ruby, использующих str.slice или str [a..b], это означает следующее:
- Создание подстроки длиной не более 23 символов
- Создать подстроку, идущую до конца целевой строки, также быстро ( синтаксис str [x ..- 1] ), и
- Создание любой другой длинной подстроки, 24 или более байтов, происходит медленнее.
Вывод
Как разработчик Ruby, вы должны спокойно копировать длинные строковые значения из одного объекта String в другой, даже если строковые значения довольно велики. Команда разработчиков MRI Ruby проделала огромную работу, чтобы гарантировать, что интерпретатор не будет без необходимости выделять память и копировать содержимое больших строк. Программы на Ruby часто интенсивно работают со строками, и эта важная оптимизация может оказать существенное влияние как на скорость, так и на потребление памяти.
Однако помните, что изменение строкового значения заставит Ruby создавать новую копию строковых данных во время фактического изменения. В большинстве случаев это неизбежно … если вам нужно изменить строку, вам нужно ее изменить. Однако понимание того, как Ruby реализует копирование при записи, может помочь вам быть умнее при написании кода ruby, который должен обрабатывать большие строки и, возможно, изменять их.
Приложение: расширение C display_string
Вот код расширения C, который я использовал выше, на случай, если кому-то будет интересно:
#include "ruby.h"
static VALUE display_string(VALUE self, VALUE str) {
char *ptr;
printf("DEBUG: RString = 0x%lx\n", str);
ptr = RSTRING_PTR(str);
printf("DEBUG: ptr = 0x%lx -> \"%s\"\n", (VALUE)ptr, ptr);
printf("DEBUG: len = %ld\n", RSTRING_LEN(str));
return Qnil;
}
void Init_display_string() {
VALUE klass;
klass = rb_define_class("Debug", rb_cObject);
rb_define_method(klass, "display_string", display_string, 1);
Этот код на C создает новый класс Ruby с именем Debug, который содержит единственный метод с именем display_string . Метод принимает один строковый аргумент и затем отображает адрес структуры RString, а также адрес фактических строковых данных, а также их длину с помощью операторов printf .
Чтобы создать и использовать этот код расширения, сначала вставьте код C сверху в файл с именем «display_string.c», а затем создайте файл с именем «extconf.rb» в том же каталоге, содержащем эти две строки:
require 'mkmf'
create_makefile("display_string")
Затем создайте C Makefile, используя эту команду:
$ ruby extconf.rb
И, наконец, скомпилируйте код C следующим образом:
$ make
Теперь вы можете использовать фрагменты Ruby сверху, если ваш код Ruby находится в том же каталоге.
Источник: http://patshaughnessy.net/2012/1/18/seeing-double-how-ruby-shares-string-values