Первая структура данных, которую мы рассмотрим, это связанный список, и на то есть веские причины. Помимо того, что это почти повсеместная структура, используемая во всем, от операционных систем до видеоигр, она также является строительным блоком, с помощью которого можно создавать множество других структур данных.
обзор
В очень общем смысле цель связанного списка состоит в том, чтобы предоставить согласованный механизм для хранения и доступа к произвольному количеству данных. Как следует из его названия, он делает это путем связывания данных в список.
Прежде чем мы углубимся в то, что это означает, давайте начнем с рассмотрения того, как данные хранятся в массиве.
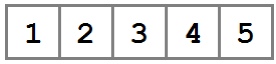
Как показано на рисунке, данные массива хранятся как один непрерывно выделенный фрагмент памяти, который логически сегментирован. Данные, хранящиеся в массиве, помещаются в один из этих сегментов и на них ссылаются через их местоположение или индекс в массиве.
Это хороший способ хранения данных. Большинство языков программирования позволяют легко размещать массивы и работать с их содержимым. Непрерывное хранение данных обеспечивает повышение производительности (а именно локальность данных), итерация по данным проста, и к данным можно обращаться напрямую по индексу (произвольный доступ) в постоянное время.
Однако бывают случаи, когда массив не является идеальным решением.
Рассмотрим программу со следующими требованиями:
- Считайте неизвестное число целых чисел из входного источника (метод
NextValue), пока не встретите число 0xFFFF. - Передайте все целые числа, которые были прочитаны (за один вызов), в метод
ProcessItems.
Поскольку требования указывают, что в метод ProcessItems необходимо передать несколько значений за один вызов, одно очевидное решение будет включать использование массива целых чисел. Например:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
void LoadData()
{
// Assume that 20 is enough to hold the values.
int[] values = new int[20];
for (int i = 0; i < values.Length; i++)
{
if (values[i] == 0xFFFF)
{
break;
}
values[i] = NextValue();
}
ProcessItems(values);
}
void ProcessItems(int[] values)
{
// … Process data.
}
|
У этого решения есть несколько проблем, но наиболее отчетливо видно, когда считывается более 20 значений. Как и сейчас в программе, значения от 21 до n просто игнорируются. Это может быть смягчено путем выделения более 20 значений — возможно, 200 или 2000. Возможно, размер может быть настроен пользователем, или, возможно, если массив заполнится, можно будет выделить больший массив и скопировать в него все существующие данные. В конечном итоге эти решения создают сложность и тратят память.
Нам нужна коллекция, которая позволяет нам добавлять произвольное число целочисленных значений, а затем перечислять эти целые числа в порядке их добавления. Коллекция не должна иметь фиксированный максимальный размер, и индексация произвольного доступа не требуется. Нам нужен связанный список.
Прежде чем мы продолжим и узнаем, как структура данных связанного списка разработана и реализована, давайте предварительно посмотрим, как может выглядеть наше окончательное решение.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
static void LoadItems()
{
LinkedList list = new LinkedList();
while (true)
{
int value = NextValue();
if (value != 0xFFFF)
{
list.Add(value);
}
else
{
break;
}
}
ProcessItems(list);
}
static void ProcessItems(LinkedList list)
{
// … Process data.
}
|
Обратите внимание, что все проблемы с решением для массива больше не существуют. Больше нет проблем с массивом, который недостаточно велик или выделяет больше, чем необходимо.
Вы также должны заметить, что это решение информирует о некоторых конструктивных решениях, которые мы будем принимать позже, а именно о том, что класс LinkedList принимает аргумент универсального типа и реализует интерфейс IEnumerable .
Реализация класса LinkedList
Узел
В основе структуры данных связанного списка лежит класс Node. Узел — это контейнер, который предоставляет возможность хранить данные и подключаться к другим узлам.
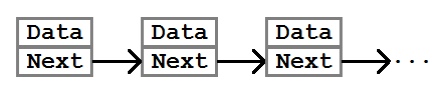
В простейшей форме класс Node, содержащий целые числа, может выглядеть так:
|
1
2
3
4
5
|
public class Node
{
public int Value { get;
public Node Next { get;
}
|
Теперь мы можем создать очень примитивный связанный список. В следующем примере мы выделим три узла (первый, средний и последний) и затем свяжем их вместе в список.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// +——+——+
// |
// +——+——+
Node first = new Node { Value = 3 };
// +——+——+ +——+——+
// |
// +——+——+ +——+——+
Node middle = new Node { Value = 5 };
// +——+——+ +——+——+
// |
// +——+——+ +——+——+
first.Next = middle;
// +——+——+ +——+——+ +——+——+
// |
// +——+——+ +——+——+ +——+——+
Node last = new Node { Value = 7 };
// +——+——+ +——+——+ +——+——+
// |
// +——+——+ +——+——+ +——+——+
middle.Next = last;
|
Теперь у нас есть связанный список, который начинается first с узла и заканчивается last . Свойство Next для последнего узла указывает на ноль, который является индикатором конца списка. Учитывая этот список, мы можем выполнить некоторые основные операции. Например, значение свойства Data каждого узла:
|
1
2
3
4
5
6
7
8
|
private static void PrintList(Node node)
{
while (node != null)
{
Console.WriteLine(node.Value);
node = node.Next;
}
}
|
Метод PrintList работает, перебирая каждый узел в списке, печатая значение текущего узла, а затем переходя к узлу, указанному свойством Next .
Теперь, когда мы понимаем, как может выглядеть узел связанного списка, давайте посмотрим на реальный класс LinkedListNode .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
public class LinkedListNode
{
///
/// Constructs a new node with the specified value.
///
public LinkedListNode(T value)
{
Value = value;
}
///
/// The node value.
///
public T Value { get;
///
/// The next node in the linked list (null if last node).
///
public LinkedListNode Next { get;
}
|
Класс LinkedList
Перед реализацией нашего класса LinkedList нам нужно подумать о том, что мы хотели бы сделать со списком.
Ранее мы видели, что коллекция должна поддерживать строго типизированные данные, поэтому мы знаем, что хотим создать общий интерфейс.
Поскольку мы используем .NET Framework для реализации списка, имеет смысл, что мы хотим, чтобы этот класс мог работать как другие встроенные типы коллекций. Самый простой способ сделать это — реализовать интерфейс ICollection<T> . Обратите внимание, что я выбираю ICollection<T> а не IList<T> . Это связано с тем, что интерфейс IList<T> добавляет возможность доступа к значениям по индексу. Хотя прямая индексация обычно полезна, она не может быть эффективно реализована в связанном списке.
Имея в виду эти требования, мы можем создать заглушку базового класса, а затем в оставшейся части раздела мы можем заполнить эти методы.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
public class LinkedList :
System.Collections.Generic.ICollection
{
public void Add(T item)
{
throw new System.NotImplementedException();
}
public void Clear()
{
throw new System.NotImplementedException();
}
public bool Contains(T item)
{
throw new System.NotImplementedException();
}
public void CopyTo(T[] array, int arrayIndex)
{
throw new System.NotImplementedException();
}
public int Count
{
get;
private set;
}
public bool IsReadOnly
{
get { throw new System.NotImplementedException();
}
public bool Remove(T item)
{
throw new System.NotImplementedException();
}
public System.Collections.Generic.IEnumerator GetEnumerator()
{
throw new System.NotImplementedException();
}
System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
throw new System.NotImplementedException();
}
}
|
добавлять
| Поведение | Добавляет указанное значение в конец связанного списка. |
| Производительность | O (1) |
Добавление элемента в связанный список включает три этапа:
- Выделите новый экземпляр
LinkedListNode. - Найдите последний узел существующего списка.
- Укажите свойство
Nextпоследнего узла на новый узел.
Ключ должен знать, какой узел является последним узлом в списке. Есть два способа узнать это. Первый способ — отслеживать первый узел («головной» узел) и обходить список, пока мы не найдем последний узел. Этот подход не требует, чтобы мы отслеживали последний узел, который сохраняет одну ссылочную стоимость памяти (независимо от размера указателя вашей платформы), но требует, чтобы мы выполняли обход списка каждый раз, когда добавляется узел. Это сделает операцию Add O (n).
Второй подход требует, чтобы мы отслеживали последний узел («хвостовой» узел) в списке, и когда мы добавляем новый узел, мы просто получаем прямой доступ к нашей сохраненной ссылке. Это алгоритм O (1) и, следовательно, предпочтительный подход.
Первое, что нам нужно сделать, это добавить два приватных поля в класс LinkedList : ссылки на первый (головной) и последний (хвостовой) узлы.
|
1
2
|
private LinkedListNode _head;
private LinkedListNode _tail;
|
Далее нам нужно добавить метод, который выполняет три шага.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
|
public void Add(T value)
{
LinkedListNode node = new LinkedListNode(value);
if (_head == null)
{
_head = node;
_tail = node;
}
else
{
_tail.Next = node;
_tail = node;
}
Count++;
}
|
Во-первых, он выделяет новый экземпляр LinkedListNode . Затем он проверяет, является ли список пустым. Если список пуст, новый узел добавляется просто путем назначения _head и _tail на новый узел. Новый узел теперь является первым и последним узлом в списке. Если список не пустой, узел добавляется в конец списка, а ссылка _tail обновляется, чтобы указывать на новый конец списка.
Свойство Count увеличивается при добавлении узла, чтобы обеспечить ICollection<T> . Свойство Count возвращает точное значение.
удалять
| Поведение | Удаляет первый узел в списке, значение которого равно предоставленному значению. Метод возвращает true, если значение было удалено. В противном случае возвращается false. |
| Производительность | На) |
Прежде чем говорить об алгоритме Remove , давайте посмотрим, что он пытается сделать. На следующем рисунке в списке четыре узла. Мы хотим удалить узел со значением три.

Когда удаление будет выполнено, список будет изменен так, чтобы свойство Next на узле со значением два указывало на узел со значением четыре.
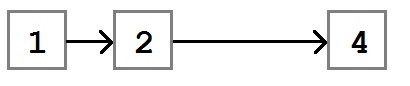
Основной алгоритм удаления узла:
- Найдите узел для удаления.
- Обновите свойство Next узла, предшествующего удаляемому узлу, чтобы указать узел, следующий за удаляемым узлом.
Как всегда, дьявол кроется в деталях. Есть несколько случаев, о которых мы должны подумать при удалении узла:
- Список может быть пустым или значение, которое мы пытаемся удалить, может отсутствовать в списке. В этом случае список остался бы без изменений.
- Удаляемый узел может быть единственным узлом в списке. В этом случае мы просто устанавливаем для
_headи_tailзначениеnull. - Узел для удаления может быть первым узлом. В этом случае нет предыдущего узла, поэтому вместо этого нам нужно обновить поле
_headчтобы оно указывало на новый головной узел. - Узел может быть в середине списка.
- Узел может быть последним узлом в списке. В этом случае мы обновляем поле
_tailдля ссылки на предпоследний узел в списке и устанавливаем для его свойстваNextзначениеnull.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
public bool Remove(T item)
{
LinkedListNode previous = null;
LinkedListNode current = _head;
// 1: Empty list: Do nothing.
// 2: Single node: Previous is null.
// 3: Many nodes:
// a: Node to remove is the first node.
// b: Node to remove is the middle or last.
while (current != null)
{
if (current.Value.Equals(item))
{
// It’s a node in the middle or end.
if (previous != null)
{
// Case 3b.
// Before: Head -> 3 -> 5 -> null
// After: Head -> 3 ——> null
previous.Next = current.Next;
// It was the end, so update _tail.
if (current.Next == null)
{
_tail = previous;
}
}
else
{
// Case 2 or 3a.
// Before: Head -> 3 -> 5
// After: Head ——> 5
// Head -> 3 -> null
// Head ——> null
_head = _head.Next;
// Is the list now empty?
if (_head == null)
{
_tail = null;
}
}
Count—;
return true;
}
previous = current;
current = current.Next;
}
return false;
}
|
Свойство Count уменьшается при удалении узла, чтобы обеспечить ICollection<T> . Свойство Count возвращает точное значение.
Содержит
| Поведение | Возвращает логическое значение, указывающее, существует ли указанное значение в связанном списке. |
| Производительность | На) |
Метод Contains довольно прост. Он просматривает каждый узел в списке, от первого до последнего, и возвращает true, как только будет найден узел, соответствующий параметру. Если достигнут конец списка, а узел не найден, метод возвращает значение false .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
public bool Contains(T item)
{
LinkedListNode current = _head;
while (current != null)
{
if (current.Value.Equals(item))
{
return true;
}
current = current.Next;
}
return false;
}
|
GetEnumerator
| Поведение | Возвращает экземпляр IEnumerator, который позволяет перечислять значения связанного списка от первого до последнего. |
| Производительность | Возвращение экземпляра перечислителя является операцией O (1). Перечисление каждого элемента является операцией O (n). |
GetEnumerator реализуется путем перечисления списка от первого до последнего узла и использует ключевое слово yield C # для возврата значения текущего узла вызывающей стороне.
Обратите внимание, что LinkedList реализует поведение итерации в версии IEnumerable<T> метода GetEnumerator и относится к этому поведению в версии IEnumerable.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
IEnumerator IEnumerable.GetEnumerator()
{
LinkedListNode current = _head;
while (current != null)
{
yield return current.Value;
current = current.Next;
}
}
IEnumerator IEnumerable.GetEnumerator()
{
return ((IEnumerable)this).GetEnumerator();
}
|
ясно
| Поведение | Удаляет все элементы из списка. |
| Производительность | O (1) |
Метод Clear просто устанавливает _head и _tail в null, чтобы очистить список. Поскольку .NET является языком сборки мусора, узлы не нужно явно удалять. Ответственность за то, чтобы узлы содержали ссылки на IDisposable , надлежащим образом удаляются вызывающей стороной, а не связанным списком.
|
1
2
3
4
5
6
|
public void Clear()
{
_head = null;
_tail = null;
Count = 0;
}
|
Скопировать в
| Поведение | Копирует содержимое связанного списка от начала до конца в предоставленный массив, начиная с указанного индекса массива. |
| Производительность | На) |
Метод CopyTo просто перебирает элементы списка и использует простое назначение для копирования элементов в массив. Вызывающая сторона должна убедиться, что целевой массив содержит соответствующее свободное пространство для размещения всех элементов в списке.
|
1
2
3
4
5
6
7
8
9
|
public void CopyTo(T[] array, int arrayIndex)
{
LinkedListNode current = _head;
while (current != null)
{
array[arrayIndex++] = current.Value;
current = current.Next;
}
}
|
подсчитывать
| Поведение | Возвращает целое число, указывающее количество элементов, находящихся в данный момент в списке. Когда список пуст, возвращаемое значение равно 0. |
| Производительность | O (1) |
Count — это просто автоматически реализованное свойство с открытым и закрытым установщиком. Реальное поведение происходит в методах Add , Remove и Clear .
|
1
2
3
4
5
|
public int Count
{
get;
private set;
}
|
IsReadOnly
| Поведение | Возвращает false, если список не только для чтения. |
| Производительность | O (1) |
|
1
2
3
4
|
public bool IsReadOnly
{
get { return false;
}
|
Двусвязный список
Класс LinkedList, который мы только что создали, известен как отдельный связанный список. Это означает, что существует только одна однонаправленная связь между узлом и следующим узлом в списке. Существует общий вариант связанного списка, который позволяет вызывающей стороне получить доступ к списку с обоих концов. Этот вариант известен как двусвязный список.
Чтобы создать двусвязный список, нам нужно сначала изменить наш класс LinkedListNode, чтобы иметь новое свойство с именем Previous. Предыдущая будет действовать как Следующая, только она будет указывать на предыдущий узел в списке.

В следующих разделах будут описаны только изменения между односвязным списком и новым двусвязным списком.
Класс узла
Единственное изменение, которое будет сделано в классе LinkedListNode — это добавление нового свойства с именем Previous которое указывает на предыдущий LinkedListNode в связанном списке или возвращает null если это первый узел в списке.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public class LinkedListNode
{
///
/// Constructs a new node with the specified value.
///
///
public LinkedListNode(T value)
{
Value = value;
}
///
/// The node value.
///
public T Value { get;
///
/// The next node in the linked list (null if last node).
///
public LinkedListNode Next { get;
///
/// The previous node in the linked list (null if first node).
///
public LinkedListNode Previous { get;
}
|
добавлять
В то время как односвязный список только добавляет узлы в конец списка, двусвязный список позволит добавлять узлы в начало и конец списка, используя AddFirst и AddLast , соответственно. ICollection<T> . Метод Add будет откладываться на метод AddLast чтобы сохранить совместимость с классом List связанным с одним AddLast
AddFirst
| Поведение | Добавляет указанное значение в начало списка. |
| Производительность | O (1) |
При добавлении узла в начало списка действия очень похожи на добавление в односвязный список.
- Установите свойство
Nextнового узла на старый головной узел. - Установите для свойства
Previousстарого узла head новый узел. - Обновите поле
_tail(при необходимости) и_tail.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public void AddFirst(T value)
{
LinkedListNode node = new LinkedListNode(value);
// Save off the head node so we don’t lose it.
LinkedListNode temp = _head;
// Point head to the new node.
_head = node;
// Insert the rest of the list behind head.
_head.Next = temp;
if (Count == 0)
{
// If the list was empty then head and tail should
// both point to the new node.
_tail = _head;
}
else
{
// Before: head ——-> 5 <-> 7 -> null
// After: head -> 3 <-> 5 <-> 7 -> null
temp.Previous = _head;
}
Count++;
}
|
AddLast
| Поведение | Добавляет указанное значение в конец списка. |
| Производительность | O (1) |
Добавить узел в конец списка даже проще, чем добавить его в начало.
Новый узел просто добавляется в конец списка, обновляя состояние _tail и _head соответствующим образом, и _head увеличивается.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
|
public void AddLast(T value)
{
LinkedListNode node = new LinkedListNode(value);
if (Count == 0)
{
_head = node;
}
else
{
_tail.Next = node;
// Before: Head -> 3 <-> 5 -> null
// After: Head -> 3 <-> 5 <-> 7 -> null
// 7.Previous = 5
node.Previous = _tail;
}
_tail = node;
Count++;
}
|
И, как упоминалось ранее, ICollection<T> .Add теперь просто вызывает AddLast .
|
1
2
3
4
|
public void Add(T value)
{
AddLast(value);
}
|
удалять
Как и Add , метод Remove будет расширен для поддержки удаления узлов из начала или конца списка. Метод ICollection<T> .Remove будет продолжать удалять элементы с самого начала, единственное изменение заключается в обновлении соответствующего свойства Previous .
RemoveFirst
| Поведение | Удаляет первое значение из списка. Если список пуст, никаких действий не предпринимается. Возвращает true, если значение было удалено. В противном случае возвращается false. |
| Производительность | O (1) |
RemoveFirst обновляет список, устанавливая свойство RemoveFirst связанного списка для второго узла в списке и изменяя его свойство Previous на null . Это удаляет все ссылки на предыдущий головной узел, удаляя его из списка. Если список содержал только один фрагмент или был пуст, список будет пустым (свойства head и tail будут null ).
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public void RemoveFirst()
{
if (Count != 0)
{
// Before: Head -> 3 <-> 5
// After: Head ——-> 5
// Head -> 3 -> null
// Head ——> null
_head = _head.Next;
Count—;
if (Count == 0)
{
_tail = null;
}
else
{
// 5.Previous was 3;
_head.Previous = null;
}
}
}
|
RemoveLast
| Поведение | Удаляет последний узел из списка. Если список пуст, никакие действия не выполняются. Возвращает true, если значение было удалено. В противном случае возвращается false. |
| Производительность | O (1) |
RemoveLast работает, устанавливая свойство tail списка, чтобы быть узлом, предшествующим текущему хвостовому узлу. Это удаляет последний узел из списка. Если список был пуст или имел только один узел, когда метод возвращает свойства head и tail , они оба будут null .
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
public void RemoveLast()
{
if (Count != 0)
{
if (Count == 1)
{
_head = null;
_tail = null;
}
else
{
// Before: Head —> 3 —> 5 —> 7
// Tail = 7
// After: Head —> 3 —> 5 —> null
// Tail = 5
// Null out 5’s Next property.
_tail.Previous.Next = null;
_tail = _tail.Previous;
}
Count—;
}
}
|
удалять
| Поведение | Удаляет первый узел в списке, значение которого равно предоставленному значению. Метод возвращает true, если значение было удалено. В противном случае возвращается false. |
| Производительность | На) |
ICollection<T> . Метод Remove практически идентичен односвязной версии, за исключением того, что свойство Previous теперь обновляется во время операции удаления. Чтобы избежать повторения кода, метод вызывает RemoveFirst когда определяется, что удаляемый узел является первым узлом в списке.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
public bool Remove(T item)
{
LinkedListNode previous = null;
LinkedListNode current = _head;
// 1: Empty list: Do nothing.
// 2: Single node: Previous is null.
// 3: Many nodes:
// a: Node to remove is the first node.
// b: Node to remove is the middle or last.
while (current != null)
{
// Head -> 3 -> 5 -> 7 -> null
// Head -> 3 ——> 7 -> null
if (current.Value.Equals(item))
{
// It’s a node in the middle or end.
if (previous != null)
{
// Case 3b.
previous.Next = current.Next;
// It was the end, so update _tail.
if (current.Next == null)
{
_tail = previous;
}
else
{
// Before: Head -> 3 <-> 5 <-> 7 -> null
// After: Head -> 3 <——-> 7 -> null
// previous = 3
// current = 5
// current.Next = 7
// So… 7.Previous = 3
current.Next.Previous = previous;
}
Count—;
}
else
{
// Case 2 or 3a.
RemoveFirst();
}
return true;
}
previous = current;
current = current.Next;
}
return false;
}
|
Но почему?
Мы можем добавить узлы в начало и конец списка — и что? Почему мы заботимся? На данный момент двусвязный класс List не более мощный, чем односвязный список. Но только с одной незначительной модификацией мы можем открыть все возможные варианты поведения. Выставив свойства head и tail качестве общедоступных свойств, доступных только для чтения, потребитель связанного списка сможет реализовать все виды нового поведения.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
public LinkedListNode Head
{
get
{
return _head;
}
}
public LinkedListNode Tail
{
get
{
return _tail;
}
}
|
С этим простым изменением мы можем перечислить список вручную, что позволяет нам выполнять обратное (хвостовое) перечисление и поиск.
Например, в следующем примере кода показано, как использовать свойства Tail и Previous списка, чтобы перечислить список в обратном порядке и выполнить некоторую обработку на каждом узле.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
public void ProcessListBackwards()
{
LinkedList list = new LinkedList();
PopulateList(list);
LinkedListNode current = list.Tail;
while (current != null)
{
ProcessNode(current);
current = current.Previous;
}
}
|
Кроме того, двусвязный класс List позволяет нам легко создавать класс Deque , который сам по себе является строительным блоком для других классов. Мы обсудим этот класс позже в другом разделе.
Следующий
Это завершает вторую часть о связанных списках. Далее мы перейдем к списку массивов.