Для каждого веб-разработчика важно знать взаимодействие с базой данных. Во второй части этой серии мы продолжим изучение языка SQL и применим полученные знания к базе данных MySQL. Мы узнаем об индексах, типах данных и более сложных структурах запросов.
Что вам нужно
Пожалуйста, обратитесь к разделу «Что вам нужно» в первой статье здесь: SQL для начинающих (часть 1) .
Если вы хотите следовать примерам в этой статье на своем собственном сервере разработки, сделайте следующее:
- Откройте MySQL Console и войдите в систему.
- Если вы этого еще не сделали, создайте базу данных с именем «my_first_db» с помощью запроса CREATE.
- Переключитесь на базу данных с помощью оператора USE.
Индексы базы данных
Индексы (или ключи) в основном используются для повышения скорости операций извлечения данных (например, SELECT) для таблиц.
Они являются такой важной частью хорошего дизайна базы данных, что их трудно классифицировать как «оптимизация». В большинстве случаев они включены в первоначальный дизайн, но их также можно добавить позже с помощью запроса ALTER TABLE.
Наиболее распространенные причины индексации столбцов базы данных:
- Почти каждая таблица должна иметь индекс PRIMARY KEY, обычно в виде столбца «id».
- Если ожидается, что столбец будет содержать уникальные значения, он должен иметь индекс UNIQUE.
- Если вы собираетесь часто выполнять поиск по столбцу (в предложении WHERE), он должен иметь обычный индекс INDEX.
- Если столбец используется для связи с другой таблицей, он должен быть FOREIGN KEY, если это возможно, или просто иметь обычный индекс в противном случае.
ПЕРВИЧНЫЙ КЛЮЧ
Почти каждая таблица должна иметь ПЕРВИЧНЫЙ КЛЮЧ, в большинстве случаев как INT с опцией AUTO_INCREMET.
Если вы помните из первой статьи , мы создали поле ‘user_id’ в таблице пользователей, и это был ПЕРВИЧНЫЙ КЛЮЧ. Таким образом, в веб-приложении мы можем ссылаться на всех пользователей по их идентификационным номерам.
Значения, хранящиеся в столбце PRIMARY KEY, должны быть уникальными. Кроме того, не может быть больше, чем один ПЕРВИЧНЫЙ КЛЮЧ на каждой таблице.
Давайте рассмотрим пример запроса, создающего таблицу для списка штатов США:
|
1
2
3
4
|
CREATE TABLE states (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20)
);
|
Это также можно записать так:
|
1
2
3
4
5
|
CREATE TABLE states (
id INT AUTO_INCREMENT,
name VARCHAR(20),
PRIMARY KEY (id)
);
|
УНИКАЛЬНАЯ
Поскольку мы ожидаем, что имя состояния будет уникальным, нам следует немного изменить предыдущий пример запроса:
|
1
2
3
4
5
6
|
CREATE TABLE states (
id INT AUTO_INCREMENT,
name VARCHAR(20),
PRIMARY KEY (id),
UNIQUE (name)
);
|
По умолчанию индекс будет назван после имени столбца. Если вы хотите, вы можете назначить ему другое имя:
|
1
2
3
4
5
6
|
CREATE TABLE states (
id INT AUTO_INCREMENT,
name VARCHAR(20),
PRIMARY KEY (id),
UNIQUE state_name (name)
);
|
Теперь индекс называется «имя_состояния» вместо «имя».
ПОКАЗАТЕЛЬ
Допустим, мы хотим добавить столбец для представления года, к которому присоединился каждый штат.
|
1
2
3
4
5
6
7
8
|
CREATE TABLE states (
id INT AUTO_INCREMENT,
name VARCHAR(20),
join_year INT,
PRIMARY KEY (id),
UNIQUE (name),
INDEX (join_year)
);
|
Я просто добавил столбец join_year и проиндексировал его. Этот тип индекса не имеет ограничения уникальности.
Вы также можете назвать его KEY вместо INDEX.
|
1
2
3
4
5
6
7
8
|
CREATE TABLE states (
id INT AUTO_INCREMENT,
name VARCHAR(20),
join_year INT,
PRIMARY KEY (id),
UNIQUE (name),
KEY (join_year)
);
|
Подробнее о производительности
Добавление индекса снижает производительность запросов INSERT и UPDATE. Поскольку каждый раз, когда новые данные добавляются в таблицу, данные индекса также обновляются автоматически, что требует дополнительной работы. Повышение производительности запросов SELECT обычно перевешивает это. Но, тем не менее, не просто добавляйте индексы в каждый столбец таблицы, не думая о запросах, которые вы будете выполнять.
Образец таблицы
Прежде чем мы продолжим с дополнительными запросами, я хотел бы создать пример таблицы с некоторыми данными.
Это будет список штатов США с датами их присоединения (дата, когда штат ратифицировал Конституцию США или был принят в Союз) и их нынешним населением. Вы можете скопировать и вставить следующую строку в консоль MySQL:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
CREATE TABLE states (
id INT AUTO_INCREMENT,
name VARCHAR(20),
join_year INT,
population INT,
PRIMARY KEY (id),
UNIQUE (name),
KEY (join_year)
);
INSERT INTO states VALUES
(1, ‘Alabama’, 1819, 4661900),
(2, ‘Alaska’, 1959, 686293),
(3, ‘Arizona’, 1912, 6500180),
(4, ‘Arkansas’, 1836, 2855390),
(5, ‘California’, 1850, 36756666),
(6, ‘Colorado’, 1876, 4939456),
(7, ‘Connecticut’, 1788, 3501252),
(8, ‘Delaware’, 1787, 873092),
(9, ‘Florida’, 1845, 18328340),
(10, ‘Georgia’, 1788, 9685744),
(11, ‘Hawaii’, 1959, 1288198),
(12, ‘Idaho’, 1890, 1523816),
(13, ‘Illinois’, 1818, 12901563),
(14, ‘Indiana’, 1816, 6376792),
(15, ‘Iowa’, 1846, 3002555),
(16, ‘Kansas’, 1861, 2802134),
(17, ‘Kentucky’, 1792, 4269245),
(18, ‘Louisiana’, 1812, 4410796),
(19, ‘Maine’, 1820, 1316456),
(20, ‘Maryland’, 1788, 5633597),
(21, ‘Massachusetts’, 1788, 6497967),
(22, ‘Michigan’, 1837, 10003422),
(23, ‘Minnesota’, 1858, 5220393),
(24, ‘Mississippi’, 1817, 2938618),
(25, ‘Missouri’, 1821, 5911605),
(26, ‘Montana’, 1889, 967440),
(27, ‘Nebraska’, 1867, 1783432),
(28, ‘Nevada’, 1864, 2600167),
(29, ‘New Hampshire’, 1788, 1315809),
(30, ‘New Jersey’, 1787, 8682661),
(31, ‘New Mexico’, 1912, 1984356),
(32, ‘New York’, 1788, 19490297),
(33, ‘North Carolina’, 1789, 9222414),
(34, ‘North Dakota’, 1889, 641481),
(35, ‘Ohio’, 1803, 11485910),
(36, ‘Oklahoma’, 1907, 3642361),
(37, ‘Oregon’, 1859, 3790060),
(38, ‘Pennsylvania’, 1787, 12448279),
(39, ‘Rhode Island’, 1790, 1050788),
(40, ‘South Carolina’, 1788, 4479800),
(41, ‘South Dakota’, 1889, 804194),
(42, ‘Tennessee’, 1796, 6214888),
(43, ‘Texas’, 1845, 24326974),
(44, ‘Utah’, 1896, 2736424),
(45, ‘Vermont’, 1791, 621270),
(46, ‘Virginia’, 1788, 7769089),
(47, ‘Washington’, 1889, 6549224),
(48, ‘West Virginia’, 1863, 1814468),
(49, ‘Wisconsin’, 1848, 5627967),
(50, ‘Wyoming’, 1890, 532668);
|
GROUP BY: группировка данных
Предложение GROUP BY группирует результирующие строки данных в группы. Вот пример:
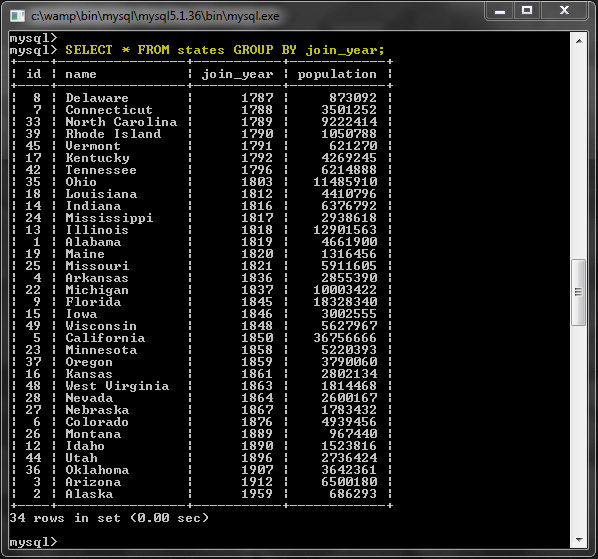
Так что же случилось? У нас в таблице 50 строк, но по этому запросу было возвращено 34 результата. Это связано с тем, что результаты были сгруппированы по столбцу «join_year». Другими словами, мы видим только одну строку для каждого отдельного значения join_year. Поскольку в некоторых штатах одинаковый join_year, мы получили менее 50 результатов.
Например, в 1787 году была только одна строка, но в этой группе 3 штата:
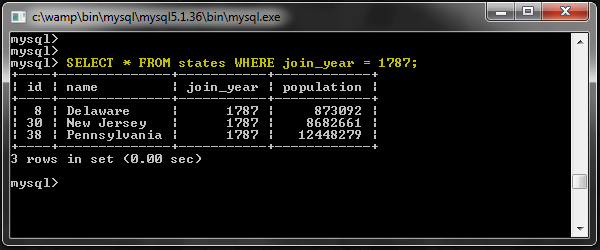
Таким образом, здесь есть три состояния, но только имя Делавера появилось после запроса GROUP BY ранее. На самом деле, это мог быть любой из трех штатов, и мы не можем полагаться на этот фрагмент данных. Тогда какой смысл использовать предложение GROUP BY?
Это было бы бесполезно без использования агрегатной функции, такой как COUNT (). Давайте посмотрим, что делают некоторые из этих функций и как они могут получить нам некоторые полезные данные.
COUNT (*): подсчет строк
Это, пожалуй, наиболее часто используемая функция наряду с запросами GROUP BY. Возвращает количество строк в каждой группе.
Например, мы можем использовать его, чтобы увидеть количество состояний для каждого join_year:
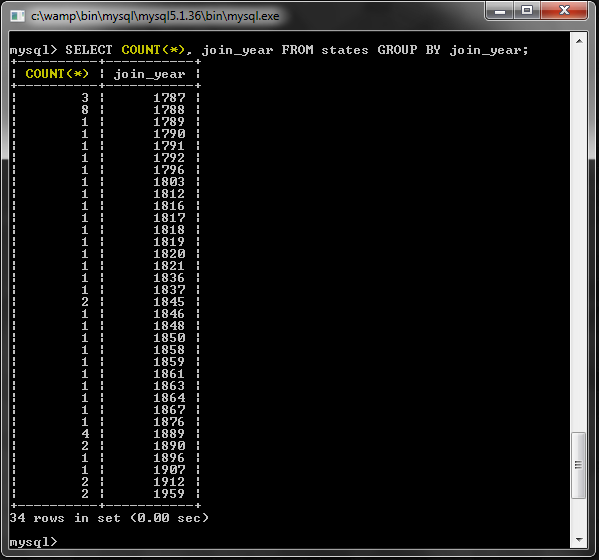
Группировка всего
Если вы используете агрегатную функцию GROUP BY и не указываете предложение GROUP BY, все результаты будут помещены в одну группу.
Количество всех строк в таблице:
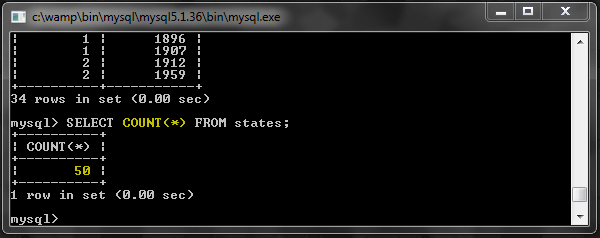
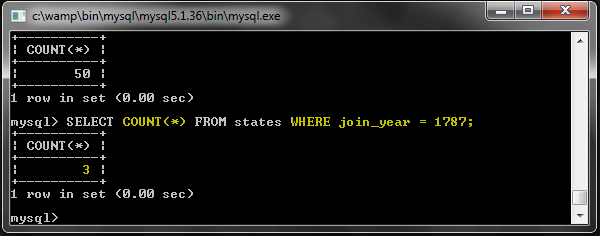
Количество строк, удовлетворяющих предложению WHERE:
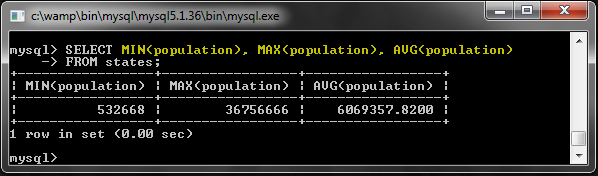
MIN (), MAX () и AVG ()
Эти функции возвращают минимальное, максимальное и среднее значения:
GROUP_CONCAT ()
Эта функция объединяет все значения внутри группы в одну строку с указанным разделителем.
В первом примере запроса GROUP BY мы могли видеть только одно имя штата в год. Вы можете использовать эту функцию, чтобы увидеть все имена в каждой группе:
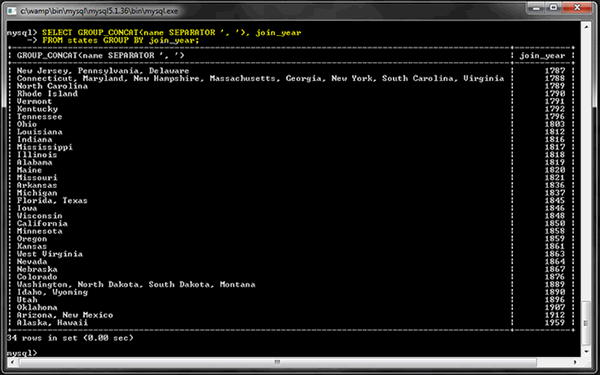
Если изображение с измененным размером трудно прочитать, это запрос:
|
1
2
|
SELECT GROUP_CONCAT(name SEPARATOR ‘, ‘), join_year
FROM states GROUP BY join_year;
|
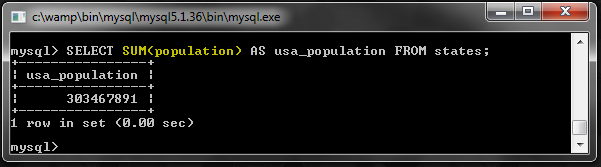
СУММА ()
Вы можете использовать это, чтобы сложить числовые значения.
IF () и CASE: поток управления
Подобно другим языкам программирования, SQL имеет некоторую поддержку потока управления.
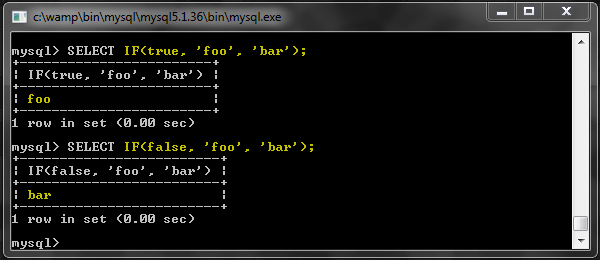
ЕСЛИ()
Эта функция принимает три аргумента. Первый аргумент является условием, второй аргумент используется, если условие истинно, а третий аргумент используется, если условие ложно.
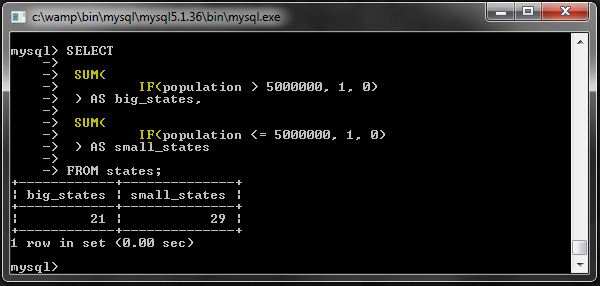
Вот более практичный пример, где мы используем его с функцией SUM ():
|
01
02
03
04
05
06
07
08
09
10
11
|
SELECT
SUM(
IF(population > 5000000, 1, 0)
) AS big_states,
SUM(
IF(population <= 5000000, 1, 0)
) AS small_states
FROM states;
|
Первый вызов SUM () подсчитывает количество больших штатов (население более 5 миллионов), а второй — количество малых штатов. Вызов IF () внутри этих вызовов SUM () возвращает 1 или 0 в зависимости от условия.
Вот результат:
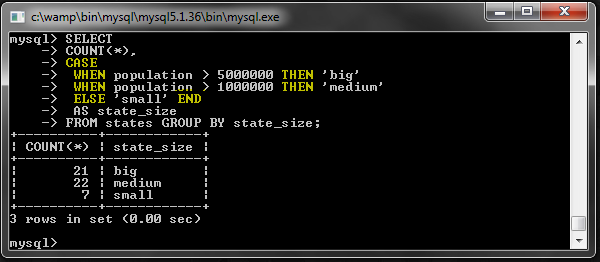
КЕЙС
Это работает аналогично операторам switch-case, с которыми вы, возможно, знакомы по программированию.
Допустим, мы хотим классифицировать каждое государство в одну из трех возможных категорий.
|
1
2
3
4
5
6
7
8
|
SELECT
COUNT(*),
CASE
WHEN population > 5000000 THEN ‘big’
WHEN population > 1000000 THEN ‘medium’
ELSE ‘small’ END
AS state_size
FROM states GROUP BY state_size;
|
Как видите, мы можем на самом деле GROUP BY значение, возвращаемое из оператора CASE. Вот что происходит:
HAVING: условия на скрытых полях
Предложение HAVING позволяет нам применять условия к «скрытым» полям, таким как возвращаемые результаты агрегатных функций. Поэтому он обычно используется вместе с GROUP BY.
Например, давайте посмотрим на запрос, который мы использовали для подсчета количества состояний по году соединения:
|
1
|
SELECT COUNT(*), join_year FROM states GROUP BY join_year;
|
Результат составил 34 строки.
Однако предположим, что нас интересуют только строки, число которых превышает 1. Мы не можем использовать для этого предложение WHERE:
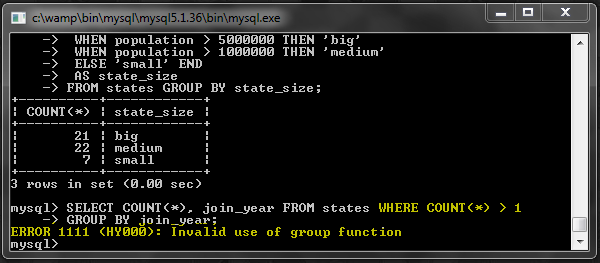
Вот где ИСПОЛЬЗОВАНИЕ становится полезным:
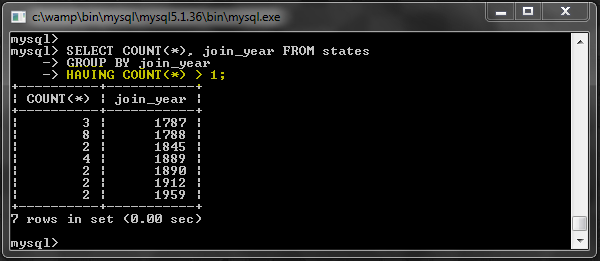
Помните, что эта функция может быть доступна не во всех системах баз данных.
подзапросов
Можно получить результаты одного запроса и использовать его для другого запроса.
В этом примере мы получим штат с наибольшим населением:
|
1
2
3
|
SELECT * FROM states WHERE population = (
SELECT MAX(population) FROM states
);
|
Внутренний запрос вернет наибольшую популяцию из всех штатов. И внешний запрос будет искать таблицу снова, используя это значение.
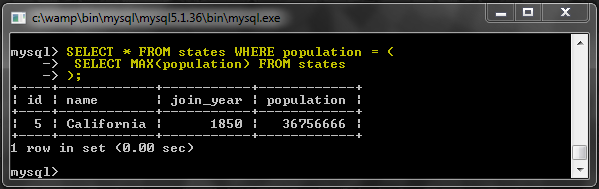
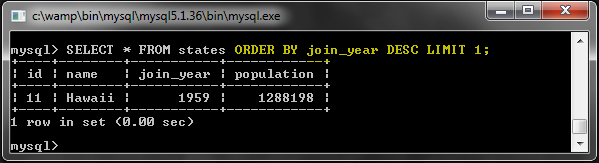
Вы можете подумать, что это плохой пример, и я в чем-то согласен. Тот же запрос может быть написан более эффективно, как это:
|
1
|
SELECT * FROM states ORDER BY population DESC LIMIT 1;
|
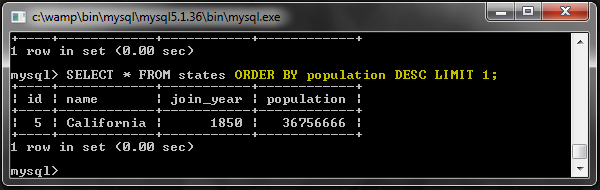
Результаты в этом случае одинаковы, однако между этими двумя типами запросов есть важное различие. Может быть, другой пример продемонстрирует это лучше.
В этом примере мы получим последние состояния, которые присоединились к Союзу:
|
1
2
3
|
SELECT * FROM states WHERE join_year = (
SELECT MAX(join_year) FROM states
);
|
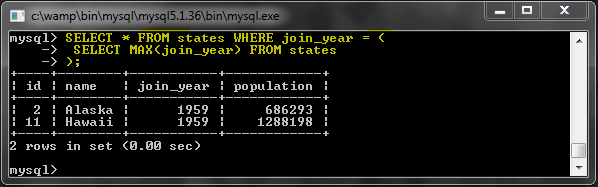
На этот раз в результатах две строки. Если бы мы использовали здесь тип запроса ORDER BY … LIMIT 1, мы бы не получили тот же результат.
В()
Иногда вы можете использовать несколько результатов, возвращаемых внутренним запросом.
Следующий запрос находит годы, когда несколько государств присоединились к Союзу, и возвращает список этих государств:
|
1
2
3
4
5
|
SELECT * FROM states WHERE join_year IN (
SELECT join_year FROM states
GROUP BY join_year
HAVING COUNT(*) > 1
) ORDER BY join_year;
|
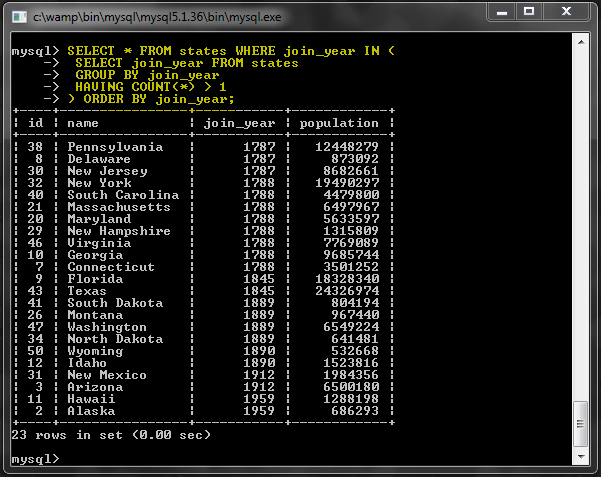
Подробнее о подзапросах
Подзапросы могут стать довольно сложными, поэтому я не буду углубляться в них в этой статье. Если вы хотите узнать о них больше, ознакомьтесь с руководством по MySQL .
Также стоит отметить, что подзапросы могут иногда иметь плохую производительность, поэтому их следует использовать с осторожностью.
СОЮЗ: Объединение данных
С помощью запроса UNION мы можем объединить результаты нескольких запросов SELECT.
Этот пример объединяет состояния, которые начинаются с буквы «N», и состояния с большим населением:
|
1
2
3
|
(SELECT * FROM states WHERE name LIKE ‘n%’)
UNION
(SELECT * FROM states WHERE population > 10000000);
|
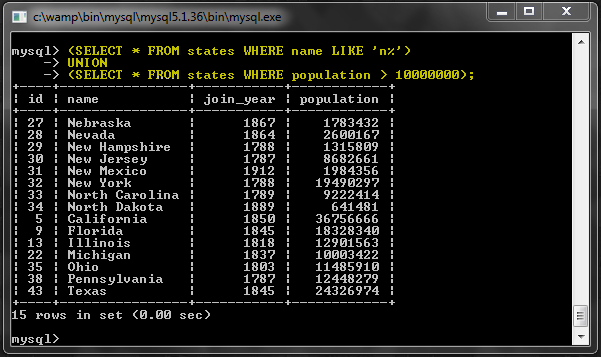
Обратите внимание, что Нью-Йорк большой и его имя начинается с буквы «N». Но он появляется только один раз, потому что повторяющиеся строки удаляются из результатов автоматически.
Еще одна приятная вещь в UNION заключается в том, что вы можете комбинировать запросы в разных таблицах.
Предположим, у нас есть таблицы для сотрудников, менеджеров и клиентов. И у каждой таблицы есть поле электронной почты. Если мы хотим получить все электронные письма одним запросом, мы можем запустить это:
|
1
2
3
4
5
|
(SELECT email FROM employees)
UNION
(SELECT email FROM managers)
UNION
(SELECT email FROM customers WHERE subscribed = 1);
|
Он будет получать все электронные письма всех сотрудников и менеджеров, но только электронные письма клиентов, которые подписались на получение электронных писем.
Вставить продолжение
Мы уже говорили о запросе INSERT в прошлой статье. Теперь, когда мы изучили индексы базы данных сегодня, мы можем поговорить о более сложных функциях запроса INSERT.
ВСТАВИТЬ … НА ДУБЛИКАТЬ КЛЮЧЕВОЕ ОБНОВЛЕНИЕ
Это почти как условное утверждение. Сначала запрос пытается выполнить заданную INSERT, и если он не выполняется из-за повторяющегося значения для PRIMARY KEY или UNIQUE KEY, он выполняет UPDATE.
Давайте сначала создадим тестовую таблицу.
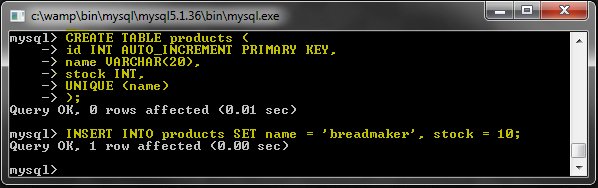
Это стол для хранения продуктов. Столбец «сток» — это количество товаров, имеющихся у нас на складе.
Теперь попытайтесь вставить повторяющееся значение и посмотрите, что произойдет.
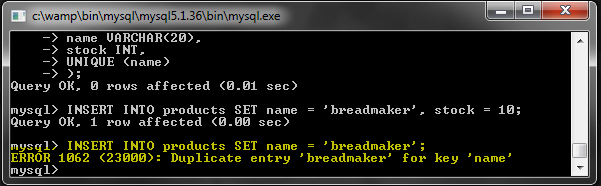
Мы получили ошибку, как и ожидалось.
Допустим, мы получили новую хлебопечку и хотим обновить базу данных, и мы не знаем, есть ли уже запись для нее. Мы могли бы проверить существующие записи и затем сделать еще один запрос на основе этого. Или мы можем сделать все это одним простым запросом:
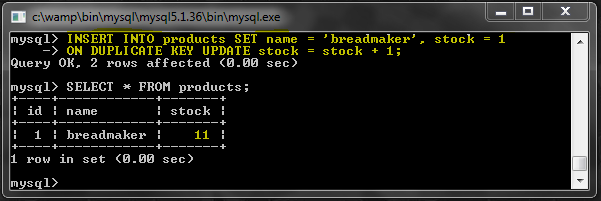
ЗАМЕНА НА
Это работает точно так же, как INSERT с одним важным исключением. Если найдена повторяющаяся строка, она сначала удаляет ее, а затем выполняет INSERT, поэтому мы не получаем сообщений об ошибках.
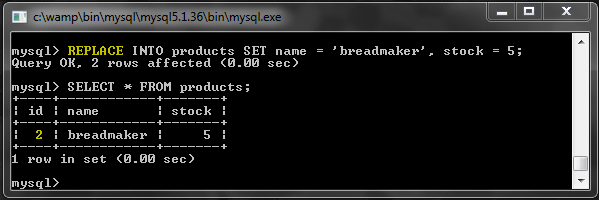
Обратите внимание, что поскольку это на самом деле совершенно новая строка, идентификатор был увеличен.
ВСТАВИТЬ ИГНОР
Это способ подавления повторяющихся ошибок, обычно для предотвращения взлома приложения. Иногда вы можете попытаться вставить новую строку и просто позволить ей потерпеть неудачу без каких-либо жалоб в случае обнаружения дубликата.
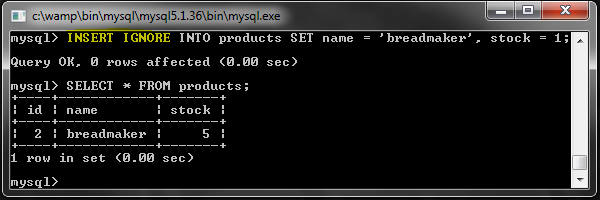
Ошибки не возвращены и строки не обновлены.
Типы данных
Каждый столбец таблицы должен иметь тип данных. До сих пор мы использовали типы INT, VARCHAR и DATE, но мы не говорили о них подробно. Также есть несколько других типов данных, которые мы должны изучить.
Сначала давайте начнем с числовых типов данных. Мне нравится разбивать их на две отдельные группы: целые и нецелые.
Целочисленные типы данных
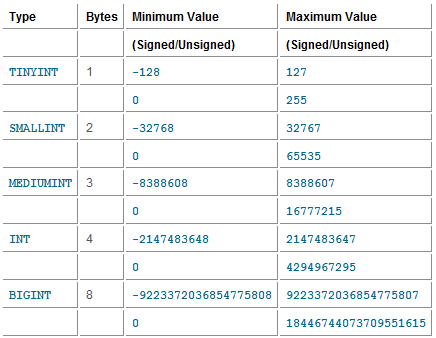
Целочисленный столбец может содержать только натуральные числа (без десятичных знаков). По умолчанию они могут быть отрицательными или положительными числами. Но если установлена опция UNSIGNED, она может содержать только положительные числа.
MySQL поддерживает 5 типов целых чисел различных размеров и диапазонов:
Нецелые числовые типы данных
Эти типы данных могут содержать десятичные числа: FLOAT, DOUBLE и DECIMAL.
FLOAT — 4 байта, DOUBLE — 8 байтов, и они работают аналогично. Однако DOUBLE имеет лучшую точность.
DECIMAL (M, N) имеет различный размер в зависимости от уровня точности, который можно настраивать. M — максимальное количество цифр, а N — количество цифр справа от десятичной точки.
Например, DECIMAL (13,4) имеет максимум 9 целых и 4 дробных цифры.
Типы данных String
Как следует из названия, мы можем хранить строки в этих столбцах типов данных.
CHAR (N) может содержать до N символов и имеет фиксированный размер. Например, CHAR (50) всегда будет занимать 50 символов пробела на строку, независимо от размера строки в ней. Абсолютный максимум 255 символов
VARCHAR (N) работает так же, но размер хранилища не фиксирован. N используется только для максимального размера. Если хранится строка короче N символов, это займет намного меньше места на жестком диске. Абсолютный максимальный размер составляет 65535 символов.
Вариации типа данных TEXT больше подходят для длинных строк. Текст имеет ограничение 65535 символов, MEDIUMTEXT 16,7 миллиона символов и LONGTEXT 4,3 миллиарда символов. MySQL обычно хранит их в отдельных местах на сервере, поэтому основное хранилище для таблицы остается относительно небольшим и быстрым.
Типы дат
DATE сохраняет даты и отображает их в формате «ГГГГ-ММ-ДД», но не содержит информацию о времени. Диапазон значений от 1001-01-01 до 9999-12-31.
DATETIME содержит дату и время и отображается в этом формате «ГГГГ-ММ-ДД ЧЧ: ММ: СС». Диапазон значений: от 1000-01-01 00:00:00 до 9999-12-31 23:59:59. Требуется 8 байт пространства.
TIMESTAMP работает как DATETIME с несколькими исключениями. Он занимает всего 4 байта, а диапазон от ‘1970-01-01 00:00:01’ UTC до ‘2038-01-19 03:14:07’ UTC. Так, например, это может быть не хорошо для хранения дат рождения.
TIME хранит только время, а YEAR — только год.
Другой
Есть несколько других типов данных, поддерживаемых MySQL. Вы можете увидеть их список здесь . Вы также должны проверить размеры хранилищ каждого типа данных здесь .
Вывод
Спасибо, что прочитали статью. SQL является важным языком и инструментом в арсенале веб-разработчиков.
Пожалуйста, оставляйте свои комментарии и вопросы, и хорошего дня!
- Подпишитесь на нас в Твиттере или подпишитесь на ленту Nettuts + RSS для получения лучших учебных материалов по веб-разработке. готов
Готовы поднять свои навыки на новый уровень и начать зарабатывать на своих скриптах и компонентах? Проверьте наш родной рынок, CodeCanyon .
