Эта статья была рецензирована Райаном Ченки . Спасибо всем рецензентам SitePoint за то, что сделали контент SitePoint как можно лучше!
Запрос данных с сервера на стороне клиента не является новой концепцией. Это позволяет приложению загружать данные без обновления страницы. Это чаще всего используется в одностраничных приложениях, которые вместо получения отрендеренной страницы с сервера запрашивают только данные, необходимые для ее отрисовки на стороне клиента.
За последние несколько лет наиболее распространенным подходом в Интернете стал архитектурный стиль REST . Однако этот подход имеет некоторые ограничения для приложений с высокими требованиями к данным. В системе RESTful нам нужно сделать несколько HTTP-запросов, чтобы получить все нужные нам данные, что существенно влияет на производительность . Что если бы был способ запросить несколько ресурсов в одном HTTP-запросе?
Представляем GraphQL, язык запросов, который объединяет взаимодействие между клиентом и сервером. Это позволяет клиентской стороне точно описывать необходимые данные в одном запросе.
В этой статье мы создадим сервер Node.js / Express с маршрутом GraphQL, который будет обрабатывать все наши запросы и мутации. Затем мы проверим этот маршрут, отправив несколько запросов POST и проанализируем результат с помощью Postman .
Вы можете найти полный исходный код этого приложения здесь . Я также сделал коллекцию почтальонов, которую вы можете скачать здесь .
Настройка конечной точки GraphQL на сервере Express
Первое, что нужно сделать, это создать наш сервер Node.js, используя платформу Express. Мы также будем использовать MongoDB вместе с Mongoose для обеспечения сохранности данных и babel для использования ES6 . Поскольку код передается в ES5 во время выполнения, процесс сборки не требуется. Это делается в index.js :
// index.js require('babel/register'); require('./app'); В app.js мы запустим наш сервер, подключимся к базе данных Mongo и создадим маршрут GraphQL.
// app.js import express from 'express'; import graphqlHTTP from 'express-graphql'; import mongoose from 'mongoose'; import schema from './graphql'; var app = express(); // GraphqQL server route app.use('/graphql', graphqlHTTP(req => ({ schema, pretty: true }))); // Connect mongo database mongoose.connect('mongodb://localhost/graphql'); // start server var server = app.listen(8080, () => { console.log('Listening at port', server.address().port); });
Самая относительная часть кода выше, в контексте этой статьи, — это то, где мы определяем наш маршрут GraphQL. Мы используем express-graphql , промежуточное программное обеспечение Express, разработанное командой GraphQL в Facebook. Это обработает HTTP-запрос через GraphQL и вернет ответ JSON. Чтобы это работало, нам нужно пройти через опции нашей схемы GraphQL, которая обсуждается в следующем разделе. Мы также устанавливаем параметр pretty верно. Это делает ответы JSON довольно печатными, что облегчает их чтение.
Схема GraphQL
Чтобы GraphQL понимал наши запросы, нам нужно определить схему. А схема GraphQL — это не что иное, как группа запросов и мутаций. Вы можете рассматривать запросы как ресурсы для извлечения из базы данных, а мутации — как любое обновление вашей базы данных. В качестве примера мы создадим модель BlogPost и Comment Mongoose, а затем создадим для нее несколько запросов и мутаций.
Мангуст Модели
Начнем с создания моделей мангустов. Здесь не будем вдаваться в подробности, поскольку мангуста не является предметом этой статьи. Вы можете найти две модели в файлах models / blog-post.js и models / comment.js .
Типы GraphQL
Как и в Mongoose, в GraphQL нам нужно определить структуру данных. Разница в том, что мы определяем для каждого запроса и мутации, какой тип данных может вводиться и что отправляется в ответе. Если эти типы не совпадают, выдается ошибка. Хотя это может показаться излишним, поскольку мы уже определили модель схемы в mongoose, у нее есть большие преимущества, такие как:
- Вы контролируете то, что разрешено, что повышает безопасность вашей системы
- Вы контролируете то, что разрешено. Это означает, что вы можете определить конкретные поля, которые никогда не будут доступны для извлечения. Например: пароли или другие конфиденциальные данные
- Он фильтрует недопустимые запросы, поэтому дальнейшая обработка не выполняется, что может повысить производительность сервера.
Вы можете найти исходный код для типов GraphQL в graphql / types / . Вот пример одного:
// graphql/types/blog-post.js import { GraphQLObjectType, GraphQLNonNull, GraphQLString, GraphQLID } from 'graphql'; export default new GraphQLObjectType({ name: 'BlogPost', fields: { _id: { type: new GraphQLNonNull(GraphQLID) }, title: { type: GraphQLString }, description: { type: GraphQLString } } });
Здесь мы определяем тип вывода GraphQL для поста в блоге, который мы будем использовать в дальнейшем при создании запросов и мутаций. Обратите внимание, насколько похожа структура на BlogPost модель BlogPost . Это может показаться дублированием работы, но это отдельные проблемы. Модель mongoose определяет структуру данных для базы данных, тип GraphQL определяет правило того, что принято в запросе или мутации на вашем сервере.
Создание схемы GraphQL
Создав модели Mongoose и типы GraphQL, мы можем теперь создать нашу схему GraphQL.
// graphql/index.js import { GraphQLObjectType, GraphQLSchema } from 'graphql'; import mutations from './mutations'; import queries from './queries'; export default new GraphQLSchema({ query: new GraphQLObjectType({ name: 'Query', fields: queries }), mutation: new GraphQLObjectType({ name: 'Mutation', fields: mutations }) });
Здесь мы экспортируем GraphQLSchema, где мы определяем два свойства: запрос и мутация. GraphQLObjectType является одним из многих типов GraphQL . С этим, в частности, вы можете указать:
- имя — которое должно быть уникальным и идентифицировать объект;
- fields — свойство, которое принимает объект, чем в этом случае будут наши запросы и мутации.
Мы импортируем queries и mutations из другого места, это только для структурных целей. Исходный код структурирован таким образом, что позволяет нашему проекту хорошо масштабироваться, если мы хотим добавить больше моделей, запросов, мутаций и т. Д.
Переменные queries и mutations которые мы передаем поля, являются простыми объектами JavaScript. Ключами являются имена мутаций или запросов. Значения — это простые объекты JavaScript с конфигурацией, которая сообщает GraphQL, что с ними делать. Давайте возьмем следующий запрос GraphQL в качестве примера:
query { blogPosts { _id, title } comments { text } }
Чтобы GrahpQL понимал, что делать с этим запросом, нам нужно определить запрос blogPosts и comments . Таким образом, наша переменная queries будет выглядеть примерно так:
{ blogPosts: {...}, comments: {...} }
То же самое касается mutations . Это объясняет, что существует прямая связь между ключами, которые мы имеем в наших запросах или мутациях, и именами, которые мы помещаем в запросы. Давайте теперь посмотрим, как определяется каждый из этих запросов и мутаций.
Запросы
Начиная с запросов, давайте возьмем пример с использованием моделей, которые мы создали до сих пор. Хорошим примером может быть получение поста в блоге и всех его комментариев.
В REST-решении вам придется сделать два HTTP-запроса для этого. Один, чтобы получить сообщение в блоге, а другой, чтобы получить комментарии, которые будут выглядеть примерно так:
GET /api/blog-post/[some-blog-post-id] GET /api/comments?postId='[some-blog-post-id]'
В GraphQL мы можем сделать это только в одном HTTP-запросе с помощью следующего запроса:
query ($postId: ID!) { blogPost (id: $postId) { title, description } comments (postId: $postId) { text } }
Мы можем получить все данные, которые нам нужны, одним запросом, который сам по себе повышает производительность. Мы также можем запросить точные свойства, которые мы собираемся использовать. В приведенном выше примере ответ будет содержать только title и description сообщения в блоге, а комментарии — только text .
Извлечение только необходимых полей из каждого ресурса может оказать огромное влияние на время загрузки веб-страницы или приложения. Давайте рассмотрим, например, комментарии, которые также имеют свойства postId и postId . Каждый из них является маленьким, 12 байтов каждый, чтобы быть точным (не считая с ключом объекта). Это имеет небольшое влияние, когда это один или несколько комментариев. Когда мы говорим о 200 комментариях, это более 4800 байтов, которые мы даже не будем использовать. И это может существенно повлиять на время загрузки приложения. Это особенно важно для устройств с ограниченными ресурсами, таких как мобильные, которые обычно имеют более медленное сетевое соединение.
Чтобы это работало, нам нужно сообщить GraphQL, как получать данные для каждого конкретного запроса. Давайте посмотрим пример определения запроса:
// graphql/queries/blog-post/single.js import { GraphQLList, GraphQLID, GraphQLNonNull } from 'graphql'; import {Types} from 'mongoose'; import blogPostType from '../../types/blog-post'; import getProjection from '../../get-projection'; import BlogPostModel from '../../../models/blog-post'; export default { type: blogPostType, args: { id: { name: 'id', type: new GraphQLNonNull(GraphQLID) } }, resolve (root, params, options) { const projection = getProjection(options.fieldASTs[0]); return BlogPostModel .findById(params.id) .select(projection) .exec(); } };
Здесь мы создаем запрос, который извлекает отдельный пост в блоге на основе параметра id. Обратите внимание, что мы указываем type , который мы ранее создали, который проверяет вывод запроса. Мы также устанавливаем объект args с необходимыми аргументами для этого запроса. И, наконец, функция resolve где мы запрашиваем базу данных и возвращаем данные.
Для дальнейшей оптимизации процесса извлечения данных и использования функции проецирования на mongoDB мы обрабатываем AST, который GraphQL предоставляет нам для создания проекции, совместимой с mongoose. Так что, если мы сделаем следующий запрос:
query ($postId: ID!) { blogPost (id: $postId) { title, description } }
Поскольку нам просто нужно извлечь title и description из базы данных, функция getProjection сгенерирует корректную проекцию getProjection :
{ title: 1, description: 1 }
Вы можете увидеть другие запросы в graphql/queries/* в исходном коде. Мы не будем проходить через каждый из них, так как все они похожи на пример выше.
Мутации
Мутации — это операции, которые будут вносить какие-то изменения в базу данных. Как и запросы, мы можем группировать различные мутации в одном HTTP-запросе. Обычно действие является изолированным, например «добавить комментарий» или «создать запись в блоге». Несмотря на растущую сложность приложений и сбора данных, предназначенных для аналитики, тестирования пользовательского опыта или сложных операций, действие пользователя на веб-сайте или в приложении может вызвать значительное количество мутаций в различных ресурсах вашей базы данных. Следуя нашему примеру, новый комментарий к нашему сообщению в блоге может означать новый комментарий и обновление счетчика комментариев к сообщению в блоге. В решении REST у вас будет что-то вроде следующего:
POST /api/blog-post/increment-comment POST /api/comment/new
С GraphQL вы можете сделать это только в одном HTTP-запросе, например:
mutation ($postId: ID!, $comment: String!) { blogPostCommentInc (id: $postId) addComment (postId: $postId, comment: $comment) { _id } }
Обратите внимание, что синтаксис для запросов и мутаций точно такой же, только изменяя query на mutation . Мы можем запрашивать данные из мутации так же, как и из запроса. Не указав фрагмент, как у нас в запросе для blogPostCommentInc , мы просто запрашиваем истинное или ложное возвращаемое значение, которого часто достаточно для подтверждения операции. Или мы можем запросить некоторые данные, как у нас, для мутации addComment , которая может быть полезна для получения данных, сгенерированных только на сервере.
Давайте тогда определим наши мутации на нашем сервере. Мутации создаются именно как запрос:
// graphql/mutations/blog-post/add.js import { GraphQLNonNull, GraphQLBoolean } from 'graphql'; import blogPostInputType from '../../types/blog-post-input'; import BlogPostModel from '../../../models/blog-post'; export default { type: GraphQLBoolean, args: { data: { name: 'data', type: new GraphQLNonNull(blogPostInputType) } }, async resolve (root, params, options) { const blogPostModel = new BlogPostModel(params.data); const newBlogPost = await blogPostModel.save(); if (!newBlogPost) { throw new Error('Error adding new blog post'); } return true; } };
Эта мутация добавит новое сообщение в блог и вернет true случае успеха. Обратите внимание, как в type мы указываем, что будет возвращено. В args аргументы получены от мутации. И функция resolve() точно так же, как в определении запроса.
Тестирование конечной точки GraphQL
Теперь, когда мы создали наш сервер Express с маршрутом GraphQL и некоторыми запросами и мутациями, давайте проверим его, отправив ему несколько запросов.
Существует много способов отправки запросов GET или POST в определенное место, например:
- Браузер — введя URL-адрес в браузере, вы отправляете запрос GET. Это имеет ограничение на невозможность отправки запросов POST
- cURL — для фанатов командной строки. Это позволяет отправлять запросы любого типа на сервер. Хотя это не лучший интерфейс, вы не можете сохранять запросы и вам нужно писать все в командной строке, что не идеально с моей точки зрения
- GraphiQL — отличное решение для GraphQL. Это встроенная в браузер среда разработки, которую вы можете использовать для создания запросов к вашему серверу. Он имеет несколько замечательных функций, таких как: подсветка синтаксиса и ввод текста
Есть больше решений, чем описано выше. Первые два являются самыми известными и используемыми. GraphiQL — это решение команды GraphQL, упрощающее процесс с помощью GraphQL, поскольку запросы могут быть более сложными для написания.
Из этих трех я бы порекомендовал GraphiQL, хотя я предпочитаю и рекомендую прежде всего Почтальон . Этот инструмент, безусловно, прогресс в тестировании API. Он предоставляет интуитивно понятный интерфейс, где вы можете создавать и сохранять коллекции запросов любого типа. Вы даже можете создавать тесты для своего API и запускать их одним нажатием кнопки. Он также имеет функцию совместной работы и позволяет обмениваться коллекциями запросов. Итак, я создал один, который вы можете скачать здесь , а затем импортировать в Почтальон. Если у вас не установлен Postman, я определенно рекомендую вам сделать это.
Давайте начнем с запуска сервера. У вас должен быть установлен узел 4 или выше; Если нет, я рекомендую использовать nvm для его установки. Затем мы можем запустить следующее в командной строке:
$ git clone https://github.com/sitepoint-editors/graphql-nodejs.git $ cd graphql-nodejs $ npm install $ npm start
Теперь сервер готов к приему запросов, поэтому давайте создадим их на Postman. Наш маршрут GraphQL установлен на /graphql поэтому первое, что нужно сделать, — это указать местоположение, куда мы хотим направить наш запрос: http://localhost:8080/graphql . Затем нам нужно указать, является ли это запросом GET или POST. Хотя вы можете использовать любой из них, я предпочитаю POST, так как он не влияет на URL, делая его чище. Нам также нужно настроить заголовок, который идет с запросом, в нашем случае нам просто нужно добавить Content-Type равный application/json . Вот как это выглядит в Postman:
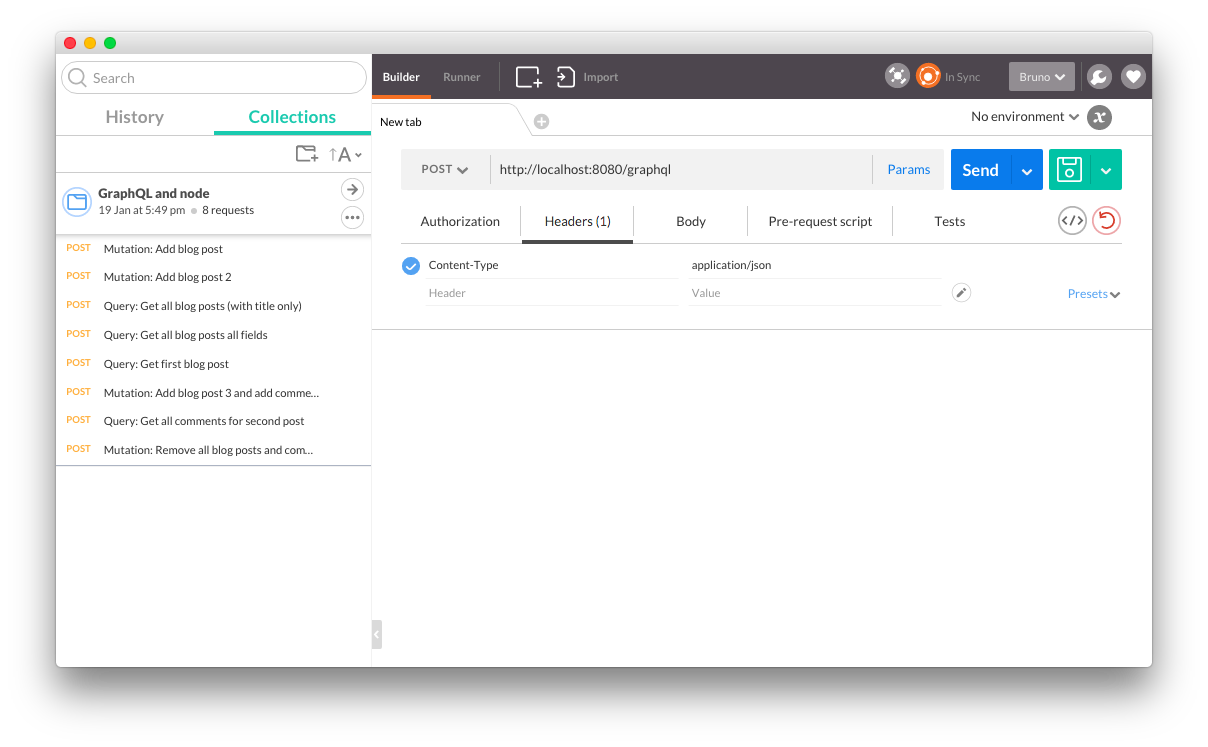
Теперь мы можем создать тело, которое будет иметь наш запрос GraphQL и переменные, необходимые в формате JSON, как показано ниже:

Предполагая, что вы импортировали предоставленную мною коллекцию, у вас уже должны быть некоторые запросы и запросы на мутации, которые вы можете протестировать. Поскольку я использовал жестко запрограммированные идентификаторы Mongo, выполняйте запросы по порядку, и все они должны быть успешными. Проанализируйте, что я положил в тело каждого, и вы увидите, что это всего лишь приложение того, что обсуждалось в этой статье. Кроме того, если вы выполняете первый запрос более одного раза, так как это будет повторяющийся идентификатор, вы увидите, как возвращаются ошибки:

Вывод
В этой статье мы представили потенциал GraphQL и его отличие от архитектурного стиля REST. Этот новый язык запросов будет оказывать большое влияние на Интернет. Особенно для более сложных приложений обработки данных, которые теперь могут точно описывать нужные данные и запрашивать их одним HTTP-запросом.
Я хотел бы услышать от вас: что вы думаете о GraphQL и каков ваш опыт работы с ним?