Веб-приложения можно разделить на два основных компонента: внешний интерфейс, который отображает и собирает информацию, и внутренний компонент для хранения информации. В этой статье я покажу, что такое реляционная база данных и как правильно спроектировать базу данных для хранения информации вашего приложения.
База данных хранит данные организованным образом, чтобы их можно было искать и получать позже. Он должен содержать одну или несколько таблиц. Таблица очень похожа на электронную таблицу, так как состоит из строк и столбцов. Все строки имеют одинаковые столбцы, и каждый столбец содержит сами данные. Если это помогает, думайте о своих таблицах так же, как о таблицах в Excel.

рисунок 1
Данные могут быть вставлены, извлечены, обновлены и удалены из таблицы. Созданное слово обычно используется вместо вставленного , поэтому в совокупности эти четыре функции ласково сокращены как CRUD.
Реляционная база данных — это тип базы данных, которая организует данные в таблицы и связывает их на основе определенных отношений. Эти отношения позволяют вам извлекать и объединять данные из одной или нескольких таблиц с помощью одного запроса.
Но это была просто пара слов. Чтобы по-настоящему понять реляционную базу данных, вам нужно создать ее самостоятельно. Давайте начнем с получения реальных данных, с которыми мы можем работать.
Шаг 1: Получить некоторые данные
В духе статей-клонов Nettuts + Twitter ( PHP , Ruby on Rails , Django ) давайте немного данных из Twitter. Я искал в Твиттере «#databases» и взял следующий пример из десяти твитов:
Таблица 1
| ФИО | имя пользователя | текст | создан в | following_username |
|---|---|---|---|---|
| «Борис Хаджур» | «_DreamLead» | «Что вы думаете о #emailing #campaigns #traffic в #USA? Это хороший рынок в настоящее время? У вас есть #databases?» | «Вт, 12 февраля 2013 г. 08:43:09 +0000» | «Scootmedia», «MetiersInternet» |
| «Гуннар Сваландер» | «GunnarSvalander» | «Билл Гейтс говорит о базах данных, бесплатном программном обеспечении на Reddit http://t.co/ShX4hZlA #billgates #databases» | «Вт, 12 февраля 2013 г. 07:31:06 +0000» | «клоут», «зиллоу» |
| «GE Software» | «GEsoftware» | «RT @KirkDBorne: Чтения в # Базы данных: превосходный список чтения, много категорий: http://t.co/S6RBUNxq через @rxin Fascinating.» | «Вт, 12 февраля 2013 г. 07:30:24 +0000» | «DayJobDoc», «быско» |
| «Адриан Берч» | «Adrianburch» | «RT @tisakovich: @NimbusData на сегодняшней конференции @Barclays Big Data в Сан-Франциско, где говорится о виртуализации, # базах данных и # флэш-памяти». | «Вторник, 12 февраля 2013 г., 06:58:22 +0000» | «СиндиКроуфорд», «Арджантим» |
| «Энди Райдер» | «AndyRyder5» | «http://t.co/D3KOJIvF статья о Madden 2013 с использованием ИИ для создания суперкубка #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:29:41 +0000» | «MichaelDell», «Yahoo» |
| «Энди Райдер» | «AndyRyder5» | «http://t.co/rBhBXjma статья о настройках конфиденциальности и facebook #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:24:17 +0000» | «MichaelDell», «Yahoo» |
| «Бретт Энглберт» | «Brett_Englebert» | «# BUS311 NCFPD Университета Миннесоты создает # базы данных для предотвращения» мошенничества с продуктами питания «. Http://t.co/0LsAbKqJ» | «Вт, 12 февраля 2013 г. 01:49:19 +0000» | «RealSkipBayless», «Stephenasmith» |
| Бретт Энглберт | «Brett_Englebert» | «# Компании BUS311 могут защищать свои производственные # базы данных, но как насчет их файлов резервных копий? Http://t.co/okJjV3Bm» | «Вт, 12 февраля 2013 г. 01:31:52 +0000» | «RealSkipBayless», «Stephenasmith» |
| «Nimbus Data Systems» | «NimbusData» | «@NimbusData CEO @tisakovich @BarclaysOnline Конференция Big Data в Сан-Франциско сегодня, на которой обсуждаются # виртуализация, # базы данных и # флэш-память» | «Пн, 11 фев 2013 23:15:05 +0000» | «dellock6», «rohitkilam» |
| «SSWUG.ORG» | «SSWUGorg» | «Не забудьте подписаться на нашу БЕСПЛАТНУЮ выставку в эту пятницу: #Database, #BI и #Sharepoint: Что нужно знать! Http://t.co/Ijrqrz29» | «Пн, 11 фев 2013 22:15:37 +0000» | «drsql», «steam_games» |
Вот что означает название каждого столбца:
MySQL используется практически в каждой интернет-компании, о которой вы слышали.
- полное имя: полное имя пользователя
- имя пользователя : ручка Twitter
- текст : сам твит
- create_at : отметка времени твита
- follow_username : список людей, за которыми следует этот пользователь, разделенных запятыми. Для краткости я ограничил длину списка двумя
Это все реальные данные; Вы можете искать в Twitter и на самом деле найти эти твиты.
Это хорошо. Данные все в одном месте; так что это легко найти, верно? Не совсем. Есть несколько проблем с этой таблицей. Во-первых, в столбцах есть повторяющиеся данные. Столбцы «username» и «follow_username» являются повторяющимися, потому что оба содержат один и тот же тип данных — дескрипторы Twitter. В столбце «follow_username» есть другая форма повторения. Поля должны содержать только одно значение, но каждое из полей «follow_username» содержит два.
Во-вторых, в строках есть повторяющиеся данные.
@ AndyRyder5 и @Brett_Englebert каждый твитнул дважды, поэтому остальная часть их информации была продублирована.
Дубликаты проблематичны, потому что это делает операции CRUD более сложными. Например, для извлечения данных потребуется больше времени, потому что время будет потрачено впустую, проходя через одинаковые строки. Кроме того, обновление данных будет проблемой; если пользователь меняет свой дескриптор Twitter, нам нужно будет найти каждый дубликат и обновить его.
Повторяющиеся данные являются проблемой. Мы можем решить эту проблему, разбив таблицу 1 на отдельные таблицы. Давайте начнем с разрешения проблемы повторения по столбцам.
Шаг 2: Удалить повторяющиеся данные через столбцы
Как отмечено выше, столбцы «username» и «follow_username» в таблице 1 являются повторяющимися. Это повторение произошло, потому что я пытался выразить следующие отношения между пользователями. Давайте улучшим дизайн Таблицы 1 , разделив его на две таблицы: одну только для следующих отношений и одну для остальной информации.
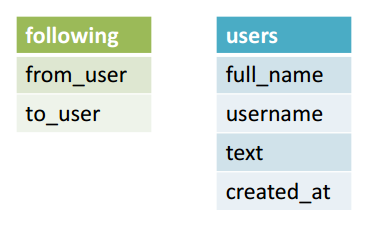
Рис. 2
Поскольку @Brett_Englebert следует за @RealSkipBayless, в следующей таблице эти отношения будут выражаться путем сохранения @Brett_Englebert в качестве «from_user» и @RealSkipBayless в качестве «to_user». Давайте разберем таблицу 1 на эти две таблицы:
Таблица 2: Следующая таблица
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | Klout |
| GunnarSvalander | Zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | Кроуфорд |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3: Таблица пользователей
| ФИО | имя пользователя | текст | создан в |
|---|---|---|---|
| «Борис Хаджур» | «_DreamLead» | «Что вы думаете о #emailing #campaigns #traffic в #USA? Это хороший рынок в настоящее время? У вас есть #databases?» | «Вт, 12 февраля 2013 г. 08:43:09 +0000» |
| «Гуннар Сваландер» | «GunnarSvalander» | «Билл Гейтс говорит о базах данных, бесплатном программном обеспечении на Reddit http://t.co/ShX4hZlA #billgates #databases» | «Вт, 12 февраля 2013 г. 07:31:06 +0000» |
| «GE Software» | «GEsoftware» | «RT @KirkDBorne: Чтения в # Базы данных: превосходный список чтения, много категорий: http://t.co/S6RBUNxq через @rxin Fascinating.» | «Вт, 12 февраля 2013 г. 07:30:24 +0000» |
| «Адриан Берч» | «Adrianburch» | «RT @tisakovich: @NimbusData на сегодняшней конференции @Barclays Big Data в Сан-Франциско, где говорится о виртуализации, # базах данных и # флэш-памяти». | «Вторник, 12 февраля 2013 г., 06:58:22 +0000» |
| «Энди Райдер» | «AndyRyder5» | «http://t.co/D3KOJIvF статья о Madden 2013 с использованием ИИ для создания суперкубка #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:29:41 +0000» |
| «Энди Райдер» | «AndyRyder5» | «http://t.co/rBhBXjma статья о настройках конфиденциальности и facebook #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:24:17 +0000» |
| «Бретт Энглберт» | «Brett_Englebert» | «# BUS311 NCFPD Университета Миннесоты создает # базы данных для предотвращения» мошенничества с продуктами питания «. Http://t.co/0LsAbKqJ» | «Вт, 12 февраля 2013 г. 01:49:19 +0000» |
| Бретт Энглберт | «Brett_Englebert» | «# Компании BUS311 могут защищать свои производственные # базы данных, но как насчет их файлов резервных копий? Http://t.co/okJjV3Bm» | «Вт, 12 февраля 2013 г. 01:31:52 +0000» |
| «Nimbus Data Systems» | «NimbusData» | «@NimbusData CEO @tisakovich @BarclaysOnline Конференция Big Data в Сан-Франциско сегодня, на которой обсуждаются # виртуализация, # базы данных и # флэш-память» | «Пн, 11 фев 2013 23:15:05 +0000» |
| «SSWUG.ORG» | «SSWUGorg» | «Не забудьте подписаться на нашу БЕСПЛАТНУЮ выставку в эту пятницу: #Database, #BI и #Sharepoint: Что нужно знать! Http://t.co/Ijrqrz29» | «Пн, 11 фев 2013 22:15:37 +0000» |
Это выглядит лучше. Теперь в таблице пользователей ( таблица 3 ) есть только один столбец с ручками Twitter. В следующей таблице ( таблица 2 ) для каждого поля в столбце «to_user» указан только один дескриптор Twitter.
Эдгар Ф. Кодд, ученый-компьютерщик, заложивший теоретическую основу реляционных баз данных, назвал этот шаг удаления повторяющихся данных по столбцам первой нормальной формой (1NF).
Шаг 3: Удалить повторяющиеся данные между строками
Теперь, когда мы исправили повторы в столбцах, нам нужно исправить повторы в строках. Поскольку пользователи @ AndyRyder5 и @Brett_Englebert каждый твитят дважды, их информация дублируется в таблице пользователей ( таблица 3 ). Это указывает на то, что нам нужно вытащить твиты и поместить их в свой собственный стол.

Рис. 3
Как и прежде, «текст» хранит сам твит. Поскольку в столбце «create_at» хранится временная метка твита, имеет смысл также включить ее в эту таблицу. Я также включил ссылку на столбец «имя пользователя», чтобы мы знали, кто опубликовал твит. Вот результат размещения твитов в собственной таблице:
Таблица 4: Таблица твитов
| текст | создан в | имя пользователя |
|---|---|---|
| «Что вы думаете о #emailing #campaigns #traffic в #USA? Это хороший рынок в настоящее время? У вас есть #databases?» | «Вт, 12 февраля 2013 г. 08:43:09 +0000» | «_DreamLead» |
| «Билл Гейтс говорит о базах данных, бесплатном программном обеспечении на Reddit http://t.co/ShX4hZlA #billgates #databases» | «Вт, 12 февраля 2013 г. 07:31:06 +0000» | «GunnarSvalander» |
| «RT @KirkDBorne: Чтения в # Базы данных: превосходный список чтения, много категорий: http://t.co/S6RBUNxq через @rxin Fascinating.» | «Вт, 12 февраля 2013 г. 07:30:24 +0000» | «GEsoftware» |
| «RT @tisakovich: @NimbusData на сегодняшней конференции @Barclays Big Data в Сан-Франциско, где говорится о виртуализации, # базах данных и # флэш-памяти». | «Вторник, 12 февраля 2013 г., 06:58:22 +0000» | «Adrianburch» |
| «http://t.co/D3KOJIvF статья о Madden 2013 с использованием ИИ для создания суперкубка #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:29:41 +0000» | «AndyRyder5» |
| «http://t.co/rBhBXjma статья о настройках конфиденциальности и facebook #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:24:17 +0000» | «AndyRyder5» |
| «# BUS311 NCFPD Университета Миннесоты создает # базы данных для предотвращения» мошенничества с продуктами питания «. Http://t.co/0LsAbKqJ» | «Вт, 12 февраля 2013 г. 01:49:19 +0000» | «Brett_Englebert» |
| «# Компании BUS311 могут защищать свои производственные # базы данных, но как насчет их файлов резервных копий? Http://t.co/okJjV3Bm» | «Вт, 12 февраля 2013 г. 01:31:52 +0000» | «Brett_Englebert» |
| «@NimbusData CEO @tisakovich @BarclaysOnline Конференция Big Data в Сан-Франциско сегодня, на которой обсуждаются # виртуализация, # базы данных и # флэш-память» | «Пн, 11 фев 2013 23:15:05 +0000» | «NimbusData» |
| «Не забудьте подписаться на нашу БЕСПЛАТНУЮ выставку в эту пятницу: #Database, #BI и #Sharepoint: Что нужно знать! Http://t.co/Ijrqrz29» | «Пн, 11 фев 2013 22:15:37 +0000» | «SSWUGorg» |
Таблица 5: Таблица пользователей
| ФИО | имя пользователя |
|---|---|
| «Борис Хаджур» | «_DreamLead» |
| «Гуннар Сваландер» | «GunnarSvalander» |
| «GE Software» | «GEsoftware» |
| «Адриан Берч» | «Adrianburch» |
| «Энди Райдер» | «AndyRyder5» |
| «Бретт Энглберт» | «Brett_Englebert» |
| «Nimbus Data Systems» | «NimbusData» |
| «SSWUG.ORG» | «SSWUGorg» |
После разделения таблица пользователей ( таблица 5 ) имеет уникальные строки для пользователей и их маркеров Twitter.
Эдгар Ф. Кодд назвал этот шаг удаления повторяющихся данных по строкам второй нормальной формой (1NF).
Шаг 4: Связывание таблиц с ключами
Данные могут быть вставлены, извлечены, обновлены и удалены из таблицы.
До настоящего времени Таблица 1 была разделена на три новые таблицы: следующие ( Таблица 2 ), твиты ( Таблица 4 ) и пользователи ( Таблица 5 ). Но как это полезно? Повторяющиеся данные были удалены, но теперь данные распределены по трем независимым таблицам. Чтобы получить данные, нам нужно нарисовать значимые ссылки между таблицами. Таким образом, мы можем выражать запросы типа «что пользователь написал в Твиттере и за кем он следит».
Способ рисования связей между таблицами состоит в том, чтобы сначала дать каждой строке в таблице уникальный идентификатор, называемый первичным ключом, а затем ссылаться на этот первичный ключ в другой таблице, с которой вы хотите связать.
На самом деле мы уже сделали это для пользователей ( Таблица 5 ) и твитов ( Таблица 4 ). У пользователей первичным ключом является столбец «имя пользователя», потому что ни у одного пользователя не будет одинакового дескриптора Twitter. В твитах мы ссылаемся на этот ключ в столбце «имя пользователя», чтобы мы знали, кто что твитнул. Поскольку это ссылка, столбец «username» в твитах называется внешним ключом. Таким образом, ключ «username» связывает пользователей и таблицы твитов вместе.
Является ли столбец «имя пользователя» лучшей идеей для первичного ключа для таблицы пользователей ?
С одной стороны, это естественный ключ — имеет смысл искать с помощью ручки Twitter, а не присваивать каждому пользователю какой-либо числовой идентификатор и выполнять поиск по нему. С другой стороны, что если пользователь захочет изменить свой дескриптор Twitter? Это может привести к ошибкам, если первичный ключ и все внешние ссылки ссылаются неправильно, ошибок, которых можно избежать, если использовать постоянный числовой идентификатор. В конечном итоге выбор зависит от вашей системы. Если вы хотите, чтобы ваши пользователи могли менять свое имя пользователя, лучше добавить для пользователя числовой столбец «id» с автоинкрементом и использовать его в качестве первичного ключа. В противном случае «имя пользователя» должно подойти. Я буду продолжать использовать «имя пользователя» в качестве первичного ключа для пользователей
Давайте перейдем к твитам ( Таблица 4 ). Первичный ключ должен однозначно идентифицировать каждую строку, так какой же здесь должен быть первичный ключ? Поле «create_at» не будет работать, потому что, если два пользователя пишут твиты в одно и то же время, их твиты будут иметь одинаковую метку времени. «Текст» имеет ту же проблему в том, что если два пользователя пишут в Твиттере «Hello world», мы не можем различить строки. Столбец «имя пользователя» — это внешний ключ, который определяет связь с пользователями, поэтому давайте не будем связываться с этим. Поскольку другие столбцы не являются хорошими кандидатами, здесь имеет смысл добавить числовой автоматически увеличивающийся столбец «id» и использовать его в качестве первичного ключа.
Таблица 6: Таблица твитов со столбцом «id»
| Я бы | текст | создан в | имя пользователя |
|---|---|---|---|
| 1 | «Что вы думаете о #emailing #campaigns #traffic в #USA? Это хороший рынок в настоящее время? У вас есть #databases?» | «Вт, 12 февраля 2013 г. 08:43:09 +0000» | «_DreamLead» |
| 2 | «Билл Гейтс говорит о базах данных, бесплатном программном обеспечении на Reddit http://t.co/ShX4hZlA #billgates #databases» | «Вт, 12 февраля 2013 г. 07:31:06 +0000» | «GunnarSvalander» |
| 3 | «RT @KirkDBorne: Чтения в # Базы данных: превосходный список чтения, много категорий: http://t.co/S6RBUNxq через @rxin Fascinating.» | «Вт, 12 февраля 2013 г. 07:30:24 +0000» | «GEsoftware» |
| 4 | «RT @tisakovich: @NimbusData на сегодняшней конференции @Barclays Big Data в Сан-Франциско, где говорится о виртуализации, # базах данных и # флэш-памяти». | «Вторник, 12 февраля 2013 г., 06:58:22 +0000» | «Adrianburch» |
| 5 | «http://t.co/D3KOJIvF статья о Madden 2013 с использованием ИИ для создания суперкубка #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:29:41 +0000» | «AndyRyder5» |
| 6 | «http://t.co/rBhBXjma статья о настройках конфиденциальности и facebook #databases # bus311» | «Вторник, 12 февраля 2013 г., 05:24:17 +0000» | «AndyRyder5» |
| 7 | «# BUS311 NCFPD Университета Миннесоты создает # базы данных для предотвращения» мошенничества с продуктами питания «. Http://t.co/0LsAbKqJ» | «Вт, 12 февраля 2013 г. 01:49:19 +0000» | «Brett_Englebert» |
| 8 | «# Компании BUS311 могут защищать свои производственные # базы данных, но как насчет их файлов резервных копий? Http://t.co/okJjV3Bm» | «Вт, 12 февраля 2013 г. 01:31:52 +0000» | «Brett_Englebert» |
| 9 | «@NimbusData CEO @tisakovich @BarclaysOnline Конференция Big Data в Сан-Франциско сегодня, на которой обсуждаются # виртуализация, # базы данных и # флэш-память» | «Пн, 11 фев 2013 23:15:05 +0000» | «NimbusData» |
| 10 | «Не забудьте подписаться на нашу БЕСПЛАТНУЮ выставку в эту пятницу: #Database, #BI и #Sharepoint: Что нужно знать! Http://t.co/Ijrqrz29» | «Пн, 11 фев 2013 22:15:37 +0000» | «SSWUGorg» |
Наконец, давайте добавим первичный ключ в следующую таблицу. В этой таблице ни столбец «from_user», ни столбец «to_user» однозначно не идентифицируют каждую строку. Однако «from_user» и «to_user» вместе делают, так как они представляют одну связь. Первичный ключ может быть определен для нескольких столбцов, поэтому мы будем использовать оба этих столбца в качестве первичного ключа для следующей таблицы.
Что касается внешнего ключа, «from_user» и «to_user» являются внешними ключами, поскольку они могут использоваться для определения связи с таблицей пользователей . Если мы запросим дескриптор Twitter в столбце from_user, мы получим всех пользователей, за которыми он следует. Соответственно, если мы запросим дескриптор Twitter в столбце «to_user», мы получим всех пользователей, следующих за ним.
Мы многое уже достигли. Мы удалили повторы по столбцам и строкам, разделив данные на три разные таблицы, а затем выбрали значимые первичные ключи, чтобы связать таблицы вместе. Весь этот процесс называется нормализацией, и его вывод — это данные, которые четко организованы в соответствии с реляционной моделью. Следствием этой организации является то, что строки появятся в базе данных только после продвижения вперед, что, в свою очередь, облегчает операции CRUD.
На рис. 4 представлена схема окончательной схемы базы данных. Три таблицы связаны между собой, и первичные ключи выделены.
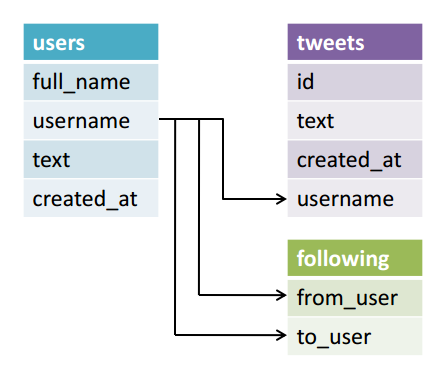
Рис. 4
Системы управления реляционными базами данных
Есть небольшие различия в SQL между каждым поставщиком СУБД, называемые диалектами SQL.
Теперь, когда мы знаем, как спроектировать реляционную базу данных, как мы на самом деле ее реализуем? Системы управления реляционными базами данных (RDBMS) — это программное обеспечение, позволяющее создавать и использовать реляционные базы данных. Есть несколько коммерческих и открытых поставщиков на выбор. С коммерческой точки зрения Oracle Database , IBM DB2 и Microsoft SQL Server — это три хорошо известных решения. Со стороны свободного и открытого исходного кода MySQL , SQLite и PostgreSQL являются тремя широко используемыми решениями.
MySQL используется практически в каждой интернет-компании, о которой вы слышали. В контексте этой статьи, Twitter использует MySQL для хранения твитов своих пользователей.
SQLite распространен во встроенных системах. iOS и Android позволяют разработчикам использовать SQLite для управления частной базой данных своего приложения. Google Chrome использует SQLite для хранения истории посещений, файлов cookie и миниатюр на странице «Самые посещаемые».
PostgreSQL также является широко используемой СУБД. Его расширение PostGIS дополняет PostgreSQL геопространственными функциями, которые делают его полезным для картографических приложений. Известный пользователь PostgreSQL — OpenStreetMap .
Язык структурированных запросов (SQL)
После того как вы загрузили и настроили СУБД в своей системе, следующим шагом будет создание базы данных и таблиц внутри нее для вставки ваших реляционных данных и управления ими. Это можно сделать с помощью языка структурированных запросов (SQL), который является стандартным языком для работы с СУБД.
Вот краткий обзор общих операторов SQL, относящихся к приведенным выше данным Twitter. Я рекомендую вам ознакомиться с « Кулинарной книгой SQL», чтобы получить более полный список запросов SQL, управляемых приложением.
- Создайте базу данных с именем «разработка»
1CREATE DATABASE development;
- Создайте таблицу с именем «пользователи»
1234CREATE TABLE users (full_name VARCHAR(100),username VARCHAR(100));
СУБД требуют, чтобы каждому столбцу таблицы был присвоен тип данных. Здесь я назначил столбцам «полное_имя» и «имя пользователя» тип данных
VARCHARкоторый представляет собой строку, которая может варьироваться по ширине. Я произвольно установил максимальную длину 100. Полный список типов данных можно найти здесь . - Вставить запись (операция Создать в CRUD)
12INSERT INTO users (full_name, username)VALUES («Boris Hadjur», «_DreamLead»);
- Получить все твиты, принадлежащие @_DreamLead (операция Получить в CRUD)
1SELECT text, created_at FROM tweets WHERE username=»_DreamLead»;
- Обновить имя пользователя (операция обновления в CRUD)
123UPDATE usersSET full_name=»Boris H»WHERE username=»_DreamLead»;
- Удалить пользователя (операция удаления в CRUD)
|
1
2
|
DELETE FROM users
WHERE username=»_DreamLead»;
|
SQL очень похож на обычные английские предложения. Есть небольшие различия в SQL между каждым поставщиком СУБД, называемые диалектами SQL, но различия не настолько существенны, что вы не можете легко перенести свои знания SQL от одного к другому.
Вывод
В этой статье мы узнали, как создать реляционную базу данных. Мы взяли сбор данных и организовали их в связанные таблицы. Мы также кратко рассмотрели решения RDBMS и SQL. Итак, начните с загрузки СУБД и нормализации некоторых ваших данных в реляционной базе данных сегодня.
Предварительный просмотр Источник изображения: FindIcons.com/Barry Mieny