Недавнее сообщение в блоге Мэтта Магейна о создании новой матрицы книг SitePoint подняло пару интересных вопросов, на которые я постараюсь ответить, так как это сделал я сам.
Когда стол не стол?
Когда его данные не являются действительно табличными; другими словами, когда данные, которые они представляют, не являются действительно двумерными. То, что мы имеем здесь, визуально двумерно, поэтому на первый взгляд может показаться разумным представить его в виде табличных данных; но сами данные на самом деле совсем не двумерные, а линейные.
Двумерный набор данных имеет две оси, каждая из которых представляет свой диапазон или набор значений, поэтому мы должны иметь возможность строить оси относительно данных и создавать значимые перекрестные ссылки. Но, как показано на рисунке ниже, мы не можем:
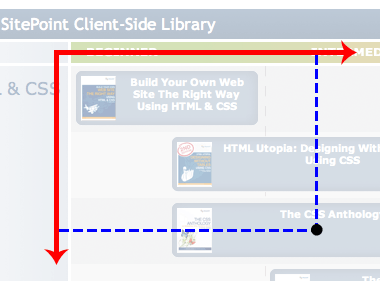
Конечно, мы можем построить эти линии и создать эту контрольную точку, но они ничего не значат, потому что оси x и y представляют одну и ту же шкалу (уровень квалификации).
Прежде чем мы сможем реализовать дизайн, мы должны решить, как данные должны быть размечены, и поэтому так важно сначала определить структуру данных inate, чтобы знать, какую семантику элемента использовать. И когда я рассматриваю семантику, суть, которую я всегда использую, это думать о том, как данные будут восприняты теми, кто использует программу чтения с экрана, в которой нет визуальных подсказок, только семантика.
Располагая эти данные в таблице, мне сразу стало очевидно, что это неправильный способ структурирования:

Насколько последовательна структура — получаем ли мы прогрессию данных, пересекая столбцы? Означает ли упорядочение строк и столбцов что-то такое явное, что на одну точку в таблице можно дать перекрестные ссылки? Или просто данные попадают в столбцы, потому что мы все еще думаем об этом визуально? Я думаю, что это последнее, и что представление данных таким образом было бы неточным и запутанным.
Теперь давайте представим те же данные линейно:

И сразу же это кажется гораздо проще и понятнее, и гораздо легче понять, смотрите ли вы, слушаете ли вы или читаете линейно.
Тогда я пришел к выводу, что данные представляют собой простую линейную структуру и представлены только визуально двумерным способом, потому что это позволяет легко увидеть шаблоны с первого взгляда.
Почему CSS для этого так волосат?
Ну, это не особенно сложно и не сложно, но и не совсем просто. Основная трудность с этим, как и со всеми точными макетами, заключается в том, чтобы создать его так, чтобы он масштабировался с использованием шрифта и размера окна . Это требование означает, что все размеры и положения должны быть относительными, а все поля должны быть гибкими, чтобы макет оставался непротиворечивым и точным независимо от настроек пользователя:

Другая проблема, которая закралась, заключается в том, что цветная шкала сверху представляет только визуальный интерес — эта информация не имеет смысла, когда контент линеаризуется, поэтому ее необходимо создавать таким образом, чтобы она влияла только на визуальный макет и не не как контент.
Пояснительный текст внизу с правой стороны был так же сложен, как и положение. С точки зрения разметки, этот контент идет сразу после каждого названия книги; но визуально это далеко направо. CSS для этого должен был не только создать этот макет, но и сделать это таким образом, чтобы обеспечить большую гибкость — так, чтобы и высота книжного бокса, и высота текста влияли на общую высоту элемента совместно ( т.е. изменение любого из них влияет на них обоих).
Посмотрите на таблицу стилей, если вы хотите поэкспериментировать.
И, конечно же, бесконечные градиенты и закругленные углы, на которых настаивает наш модный дизайнер, делают все намного сложнее … Я думаю, у меня просто стакан в два раза больше, чем нужно, чтобы быть как
парень!