Эта статья была создана в партнерстве с MongoDB . Спасибо за поддержку партнеров, которые делают возможным использование SitePoint.
Предположим, что вы создаете платформу для электронной коммерции, и в рамках этого упражнения вам необходимо разработать новую архитектуру данных для управления запасами. Вам необходимо поддерживать быстрые транзакционные рабочие нагрузки, чтобы фактически отслеживать запасы практически в реальном времени.
Бизнес также хотел бы иметь возможность отвечать на такие вопросы, как «на основе исторических данных, когда мы должны пополнять запасы на виджетах и штуковинах?» И «кто те люди, которые покупают виджеты и вообще, где они находятся?» Ваши данные архитектура должна поддерживать смешанные рабочие нагрузки.
С чего бы начать?
Для транзакционного компонента вы, вероятно, поймете, что вам нужна рабочая база данных, то есть та, которая позволяет вам выполнять операции чтения, записи и обновления ваших данных. Это должно иметь смысл, поскольку вам нужно будет не только знать, сколько виджетов у вас есть в вашем инвентаре, но и иметь возможность обновлять это число, когда клиент покупает виджет. И вам также необходимо убедиться, что ваш уровень данных способен обеспечить согласованное представление данных для любых подключенных приложений. В противном случае, ваши недовольные клиенты могут положить вещи в свои корзины, которые на самом деле недоступны.
Для поддержки вашей транзакционной рабочей нагрузки нет недостатка в оперативных базах данных, поскольку базовые технологии насчитывают 40 лет. Для приложений, которые должны обрабатывать различные типы данных и структуры данных, такие как наше приложение для инвентаризации, многие компании выбрали новые нереляционные опции вместо реляционных баз данных, таких как Oracle, MySQL или SQL Server.
Это связано с тем, что нереляционные базы данных, которые не хранят данные в строках и столбцах, как это делают реляционные базы данных, предлагают большую гибкость в их способности принимать и обрабатывать данные различных форматов и форм, экономя значительное количество времени и усилий при разработке приложений. итерационные циклы. Традиционные реляционные базы данных, предназначенные для вертикального масштабирования («увеличить машину»), также испытывают трудности с поддержкой распределенных запросов с низкой задержкой и могут сталкиваться с ограничениями производительности. Это может быть проблематично, если у нас есть географически распределенные клиенты или неожиданные пики в использовании приложений.
В целях обсуждения архитектуры данных для поддержки смешанных рабочих нагрузок давайте сравним реализацию с двумя популярными нереляционными операционными базами данных: DynamoDB, которая является нереляционной службой баз данных, разработанной в AWS; и MongoDB , одна из самых популярных нереляционных баз данных.
Смешанные рабочие нагрузки с DynamoDB
DynamoDB — это полностью управляемая облачная служба базы данных, которая хранит данные в виде набора пар ключ-значение, в котором ключ служит уникальным идентификатором. И ключи, и значения могут быть любыми: от простых объектов до сложных составных объектов. Это значительно упрощает прием и сохранение большого разнообразия данных по сравнению с использованием реляционной базы данных.
Однако для чего-либо кроме простых запросов, таких как аналитика, которую мы хотим поддерживать в нашей архитектуре данных, AWS рекомендует использовать дополнительные продукты, такие как Amazon EMR, Amazon Redshift и другие.
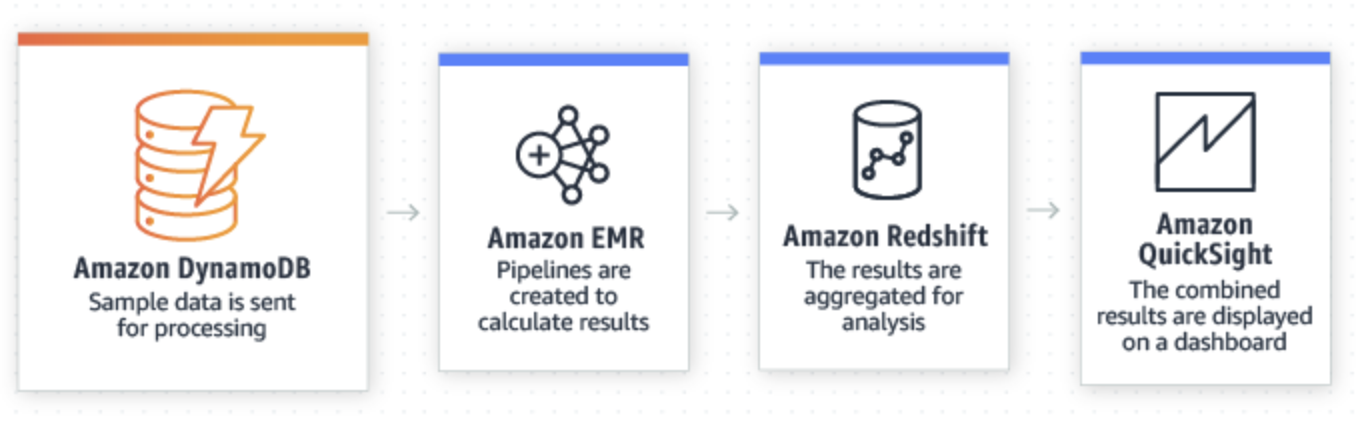
Источник: https://aws.amazon.com/dynamodb/
Это связано с тем, что выразительная мощь языка запросов DynamoDB, или, проще говоря, широта идей, которые могут быть представлены и переданы с использованием языка запросов DynamoDB, несколько ограничена. Это качество довольно распространено среди нереляционных баз данных, иногда называемых базами данных «NoSQL», которые оптимизированы для гибкости и масштабируемости модели данных, часто за счет функциональности базовой базы данных.
Как видно из приведенного выше рекомендуемого шаблона, данные хранятся в DynamoDB, а затем перемещаются в Amazon EMR, который предоставляет управляемую структуру больших данных для обработки. Затем данные передаются в Amazon Redshift, управляемое хранилище данных для агрегирования. Наконец, Amazon Quicksight, инструмент бизнес-аналитики, может использовать агрегированные данные для создания диаграмм и информационных панелей, которые бизнес-пользователи могут использовать.
В этой архитектуре данных немало движущихся частей, не говоря уже о дополнительной сложности обучения работе с несколькими компонентами и их эксплуатации (компенсируя некоторые из них с помощью управляемых служб, а не создавая их все самостоятельно) и затратами. А поскольку данные перемещаются из системы в систему, существует очень хорошая вероятность того, что данные, представленные на диаграммах и панелях мониторинга на одном конце, не соответствуют фактическому состоянию вещей в исходной базе данных.
В этом подходе нет ничего принципиально неправильного, если вы согласны с приведенными выше предостережениями, но давайте рассмотрим другой.
Смешанные рабочие нагрузки с MongoDB
MongoDB похож на DynamoDB в нескольких отношениях:
- Это нереляционная база данных
- Он доступен как полностью управляемая облачная база данных через MongoDB Atlas.
По большей части на этом сходство заканчивается. В отличие от DynamoDB, данные хранятся в JSON-подобных документах. Документы могут содержать столько пар ключ-значение или сложных вложенных структур, сколько требуется приложению. MongoDB также имеет выразительный язык запросов, который отличает его от других нереляционных баз данных. Не только легко получить данные в базу данных, но также легко вернуть данные способами, которые могут служить различным случаям использования. Например, база данных имеет структуру агрегации, которая позволяет выполнять аналитику на месте, не перемещая данные в другую систему.
Это означает, что наша архитектура данных для поддержки смешанных рабочих нагрузок может быть намного проще. Если мы удалим Amazon EMR и Amazon Redshift (или эквивалентные сервисы от вашего облачного провайдера), у нас останется база данных и наш инструмент бизнес-аналитики или инструментальные панели.
Однако у нас есть еще одна вещь, которую стоит рассмотреть: как мы можем гарантировать, что аналитические запросы, которые обычно работают дольше, чем запросы, поддерживающие транзакционную нагрузку, не влияют на производительность всей системы? К счастью, у MongoDB есть ответ и на это. База данных изначально поддерживает репликацию и автоматическое переключение при сбое, чтобы обеспечить высокую доступность, но узлы реплики также могут быть добавлены и использованы для изоляции определенных рабочих нагрузок и запросов.
Atlas, полностью управляемый сервис для MongoDB , позволяет создавать кластер базы данных и добавлять дополнительные узлы реплики для изоляции рабочей нагрузки (так называемые специализированные узлы «аналитики») одним нажатием кнопки или простым вызовом API. Любые длительные аналитические запросы будут попадать в эти аналитические узлы, гарантируя, что производительность транзакционных рабочих нагрузок не будет затронута.
Atlas также предоставляет аналитический инструмент самообслуживания в облаке, называемый MongoDB Charts, который изначально работает с данными MongoDB без перемещения или преобразования данных. Это дает вам более точную информацию об истинном положении вещей, поскольку инструмент BI использует оперативные данные.
Обратите внимание, что, поскольку вы будете выполнять аналитические запросы к реплике, также существует вероятность возможной согласованности. «Задержка» в этом сценарии, вероятно, будет короче, поскольку она связана с задержкой между операцией на «первичной» реплике и применением этой операции к реплике аналитики, а не физическим перемещением данных между несколькими разрозненными системами, как показано в предыдущая архитектура.
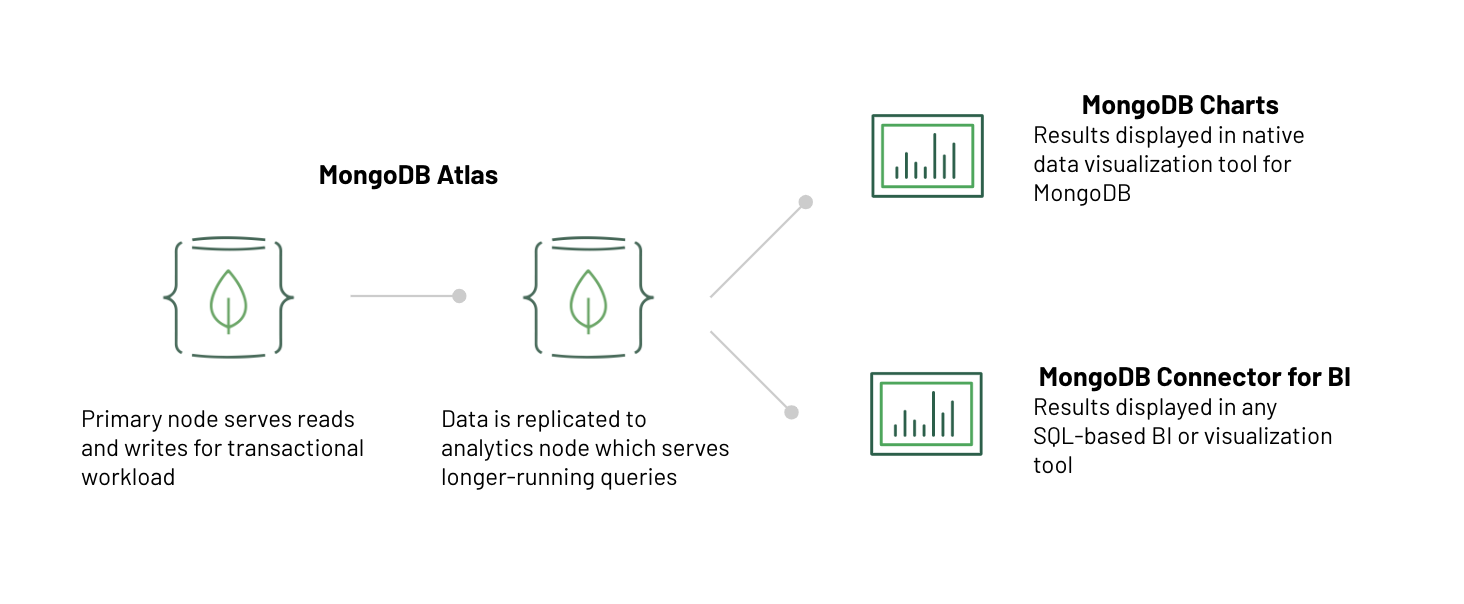
Вот вам и две разные архитектуры данных для поддержки смешанных рабочих нагрузок с использованием нереляционных баз данных. У каждого есть свои компромиссы. Если вам требуется сложная аналитика данных транзакций, может потребоваться дополнительная сложность, задержка и стоимость для преобразования ваших данных и их перемещения через Amazon EMR и Amazon Redshift.
Однако вопросы аналитики, поднятые в начале этой статьи, не требуют такого уровня сложности. Выбрав базу данных, которая позволяет вам выполнять аналитику на месте И способ изолировать эти рабочие нагрузки, чтобы обеспечить минимальное влияние на производительность операций в реальном времени, ваша архитектура может быть намного проще и проще работать.