Я не думаю, что говорить о том, что HTML5 изменит ваше представление о веб-разработке, — это гипербола. Я приветствую многие изменения, поскольку они облегчают разработку и расширяют возможности пользователей. Тем не менее, с любым изменением, наверняка, будет немного трепета и противоречий. Одним из дополнений, которое, безусловно, не без противоречий, является спецификация Microdata , но я считаю, что преимущества этой очень простой спецификации изменят ваш взгляд на наценку в ближайшем будущем.
Введение и сфера применения: контекст для машин
Я сосредоточен на спецификации микроданных в этом уроке. Вы должны понимать, что спецификация на данный момент не является надежной и не получила широкого распространения. На самом деле, в ходе моего написания спецификация изменилась. Тем не менее, микроданные были приняты Google как еще один способ предоставления пользователю богатых результатов поиска. В дополнение к незрелой спецификации, есть некоторые противоречия, связанные с микроданными.
Чтобы понять противоречие, вы должны понимать, что микроданные — это подмножество создания документа, имеющего значение для машин, так же, как оно имеет значение для читателя документа. Под смыслом я подразумеваю предоставление метаданных таким образом, чтобы они могли использоваться машиной, читающей документ, и позволяли обрабатывать эти данные. Это противоречиво, так как существуют другие форматы и спецификации, которые также преследуют эту конечную цель. RDFa и микроформаты являются двумя из этих других форматов, с которыми вы, возможно, знакомы, и которые вполне могут быть использованы сегодня.
В идеальном мире не было бы конкурирующих спецификаций, о которых мы должны были бы знать, но, к сожалению, есть куда большие проблемы, о которых нужно беспокоиться. Кроме того, каждый формат имеет свои недостатки, с точки зрения использования. Помимо всего этого, давайте вместо этого остановимся на позитиве и узнаем, что дает нам спецификация, а также то, что мы можем использовать сегодня, чтобы добавить немного больше смысла нашим документам.
Одно замечание, прежде чем мы начнем: независимо от формата, который вы предпочитаете, у вас никогда не должно быть одного набора наценки для того, что видят ваши пользователи, и другого набора для того, что видят машины. Могут быть случаи, когда вам необходимо предоставить конкретные метаданные для машины, но использование должно быть исключением, а не правилом. Цель этих форматов — предоставить контекст, а не обманывать поисковую систему или другое приложение, чтобы они читали больше на странице, чем на самом деле. Вы будете сожалеть об использовании уловок, используя скрытый атрибут или отображение: ни один , поскольку это определенно будет осуждено.
«Микроданные — это подмножество создания документа, имеющего значение для машин, так же, как оно имеет значение для читателя документа. Под смыслом я подразумеваю предоставление метаданных способом, который может использоваться машиной, читающей документ, и разрешить обработку данных
Микроданные в теории: большая картина
Предположим, вы коллекционер комиксов. Я бы поспорил, что человек, который собирает комиксы, не только читает предстоящие вопросы, но и исследует Интернет, чтобы завершить сбор своих комиксов, а также свои знания интересующих их историй. Это исследование может быть так же просто, как тратить время в Google, введя запрос за запросом о вашем интересе. Некоторые страницы будут ударить или пропустить, поскольку они могут упомянуть Супермена, но не обязательно в контексте, который вы ищете. Было бы хорошо, если бы у Google был контекст со страниц, которые они проиндексировали, чтобы предоставить вам правильные результаты поиска. Это обеспечивает более богатый опыт для пользователя и связывает вас с людьми, которые ценят ваш сайт. Это победа / победа.
Давайте сделаем этот шаг дальше результатов поиска. Скажем, вы пишете приложение, которое объединяет единомышленников и желающих веб-сайтов объединить свои знания о комиксах. Очевидно, мы могли бы написать скребок, но у нас на самом деле нет контекста, поскольку, вероятно, ни один из веб-сайтов не использует тот же формат для отображения своих результатов. Возможно, нам придется написать несколько форматов скребка, чтобы получить основную информацию. Вместо этого мы можем определить новую спецификацию формата с помощью микроданных и пяти атрибутов, которые облегчат эту проблему.
Микроданные в теории: новые глобальные атрибуты
Микроданные представляют пять простых глобальных атрибутов (доступных для любого элемента), которые предоставляют компьютерам контекст для ваших данных. Эти пять новых атрибутов: itemid, itemprop, itemref, itemscope и itemtype. Микроданные — это группа пар значений элементов, а атрибуты придают значение нашим элементам. Давайте посмотрим на них подробно.
Атрибут itemscope является логическим атрибутом, который сообщает любой машине, которая читает наш документ, о том, что на этой странице есть микроданные, и именно здесь они начинаются. Вы создаете предмет с использованием itemscope. Любой элемент с itemcope также может иметь атрибут itemtype. Тип элемента — это действительный URL-адрес, который определяет элемент и предоставляет контекст для свойств. Кроме того, у вас может быть itemid, который представляет собой словарь, который использует тип элемента, чтобы мы делали описания в правильном формате определения.
Используя пример из спецификации:
|
1
2
3
|
<dl itemscope
itemtype=»http://vocab.example.net/book»
itemid=»urn:isbn:0-330-34032-8″>
|
У нас есть предмет, идентифицированный нашим предметом. Определение элемента можно найти по адресу http://vocab.example.net/book, а точное значение элемента можно найти, используя словарь itemid. В этом случае мы отождествляем книгу с isbn 0-330-34032-8.
Последние два атрибута для микроданных — itemprop и itemref. Itemprop определяет свойство элемента. Помните, что микроданные — это, в основном, пары значений элементов, то есть здесь значение этого свойства. Итак, itemprop дает контекст нашего элемента. Наконец, у нас есть itemref, который позволяет нам поддерживать поток наших документов для наших пользователей. Помните, что мы даем контекст нашему HTML-документу, а не пытаемся создать новый документ для приложения или поисковой системы. Давайте посмотрим на наш пример еще раз, на этот раз немного отклонился от предоставленного примера от спецификации:
|
01
02
03
04
05
06
07
08
09
10
11
|
<dl itemscope
itemtype=»http://vocab.example.net/book»
itemid=»urn:isbn:0-330-34032-8″
itemref=»author_information»>
<dt>Title
<dd itemprop=»title»>The Reality Dysfunction
<dt>Author
<dt>Publication date
<dd><time itemprop=»pubdate» datetime=»1996-01-26″>26 January 1996</time>
</dl>
<div id=»author_information» itemprop=»author»>Peter F. Hamilton</div>
|
В нашем примере у нас есть свойства со значениями. Мы также следим за потоком документов, ссылаясь на идентификатор автора информации. Тогда машина сможет понять это, анализируя наш элемент и получая этот контекст, и если мы будем думать в формате массива:
Вещь Тип: http://vocab.example.net/book ID: urn: isbn: 0-330-34032-8 название = дисфункция реальности pubdata = 1996-01-26 автор = Питер Ф. Гамильтон
Теперь наш массив данных может быть переведен на машине или изменен на другие форматы, такие как JSON , N-Triples или любой другой внутренний формат, который может понадобиться приложению.
По этой причине мне нравятся микроданные, потому что их легко понять и легко выполнить. Давайте рассмотрим некоторые примеры, которые мы можем использовать сегодня, в частности, как мы можем предоставить некоторый контекст для Google, и как они могут использовать этот контекст. Я буду держать формат как можно ближе к примерам Google, но поменяю продукты, людей, на другие примеры из реального мира.
Микроданные на практике: люди и бизнес
Если вы когда-нибудь просматривали чьи-то результаты в LinkedIn, вы могли видеть что-то вроде этого:

Google будет обрабатывать три формата в настоящее время. Это RDFa, микроформаты, и вы уже догадались, микроданные. Теперь мы можем предоставить контекст из нашего HTML, чтобы улучшить результаты поиска. Хотя LinkedIn использует микроформаты, давайте посмотрим, сможем ли мы получить аналогичный результат, используя микроданные:
|
01
02
03
04
05
06
07
08
09
10
11
|
<div itemscope itemtype=»http://data-vocabulary.org/Person»>
<img src=»avatar.jpg» itemprop=»photo»>
My name is <span itemprop=»name»>John Cox
<a href=»http://net.tutsplus.com» itemprop=»affliation»>Nettuts+</a>.
I live in
<span itemprop=»address» itemscope
itemtype=»http://data-vocabulary.org/Address»>
<span itemprop=»locality»>Louisville
<span itemprop=»region»>KY
</div>
|
В то время как этот маленький фрагмент кода производит что-то похожее на это:

Когда я проверяю, что результаты Google показывают обо мне , я получаю это:
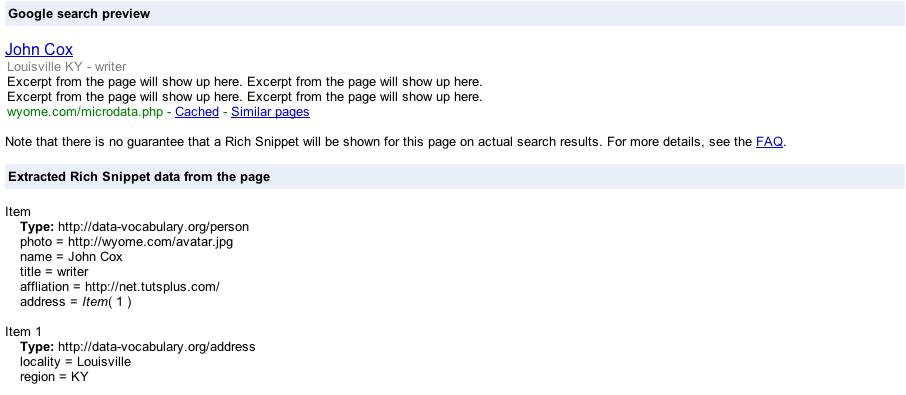
Хотя фрагмент интересный, обратите внимание также на дополнительный контекст, который Google имеет обо мне:

Чем больше контекста я предоставляю, тем больше контекста обо мне будет иметь Google или любое другое приложение, которое читает мою страницу.
Давайте сделаем еще один шаг вперед, посмотрим на бизнес или организацию и посмотрим, не можем ли мы дать немного больше контекста для машины. В этом примере я буду использовать Nettuts +.
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
<address itemscope itemtype=»http://data-vocabulary.org/Organization»>
<span itemprop=»name»>Nettuts+
Postal Address:
<span itemprop=»address» itemscope
itemtype=»http://data-vocabulary.org/Address»>
<span itemprop=»street-address»>PO Box 21177
<span itemprop=»locality»>Melbourne
<span itemprop=»region»>Victoria
<span itemprop=»country-name»>Australia
<span itemprop=»geo» itemscope itemtype=»http://www.data-vocabulary.org/Geo/»>
Latitude: <span itemprop=»latitude»>37.49 S
Longitude: <span itemprop=»longitude»>144.58 E
Phone: <span itemprop=»tel»>+61 (0) 3 9023 0074
<a href=»http://net.tutsplus.com/» itemprop=»url»>Nettuts+ |
</address>
|
К сожалению, у Google пока нет богатого фрагмента для организаций, но давайте посмотрим на данные, которые они видят.

Опять же, мы предоставляем контекст обратно на машину, которую можно использовать различными способами, например, с относительной простотой построения нашей организации на карте.
Микроданные на практике: продукты и обзоры
Другое практическое использование микроданных — это предоставление большего контекста о продуктах, которые мы продаем, будь то продукт или, как люди оценивают продукт. Давайте сначала посмотрим на информацию о продукте.
|
1
2
3
4
5
6
7
8
|
<div itemscope itemtype=»http://data-vocabulary.org/Product»>
Brand: <span itemprop=»brand»>Bridgestone
Category: <span itemprop=»category»>Truck Tires
<h1><span itemprop=»name»>R-195F
<span itemprop=»photo»><img src=»http://www.bfentirenet.com/tires/b_r195f.jpg»/>
On sale for <span itemprop=»price»>$300.09
Find more information from <a href=»http://www.bridgestonetrucktires.com» itemprop=»url»>Bridgestone</a> .
</div>
|
Еще раз, у Google нет богатого фрагмента для продукта, но мы можем видеть контекст, который они видят, когда они анализируют нашу страницу:

У них действительно есть богатый фрагмент для отзывов, и именно к этому мы стремимся. Допустим, мы разрешаем оценки о наших продуктах:
|
1
2
3
4
5
6
7
|
<div itemscope itemtype=»http://data-vocabulary.org/Review»>
<span itemprop=»itemreviewed»>R-195F
By <span itemprop=»reviewer»>John Cox
<time itemprop=»dtreviewed» datetime=»2010-06-10″>June 10, 2010</time>.
<span itemprop=»summary»>This tire runs forever!
Rating: <span itemprop=»rating»>4.5
</div>
|
С помощью этой небольшой дополнительной наценки мы можем дать контекст нашему обзору для машин. Google будет отображать обзор как:
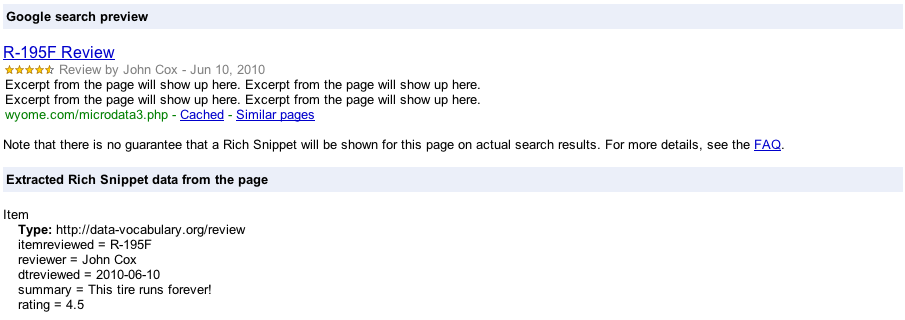
Все дело в предоставлении контекста через пять простых глобальных атрибутов. Теперь мы можем предоставить последовательный метод определения этого контекста, независимо от того, рассматриваем ли мы шины, веб-сайты или игры.
Микроданные на практике: события
Последний пример, о котором можно поговорить, — это возможность дать некоторый контекст предстоящих событий с помощью микроданных. События — это часто встречающийся элемент. Возможно, вы работаете на веб-сайте, на котором запланированы события, которые вы хотите показать. Давайте дадим немного больше контекста для машин и посмотрим, как это можно использовать:
|
01
02
03
04
05
06
07
08
09
10
11
|
<div itemscope itemtype=»http://data-vocabulary.org/Event»>
<a href=»http://www.thedevilmakesthree.com» itemprop=»url» >
<span itemprop=»summary»>The Devil Makes Three
</a>
<img itemprop=»photo» src=»http://www.thedevilmakesthree.com/MediaFiles/right_column/do-wrong-right.jpg» />
<span itemprop=»description»>We are off again down the eastern side of these United States on our way to The Bonnaroo music festival.
<time itemprop=»startDate» datetime=»2010-06-13″>June 13th, 2010</time>
<span itemprop=»location» itemscope itemtype=»http://data-vocabulary.org/Organization»>
<span itemprop=»name»>Bonnaroo
</div>
|
Который будет производить хорошую запись, как это:
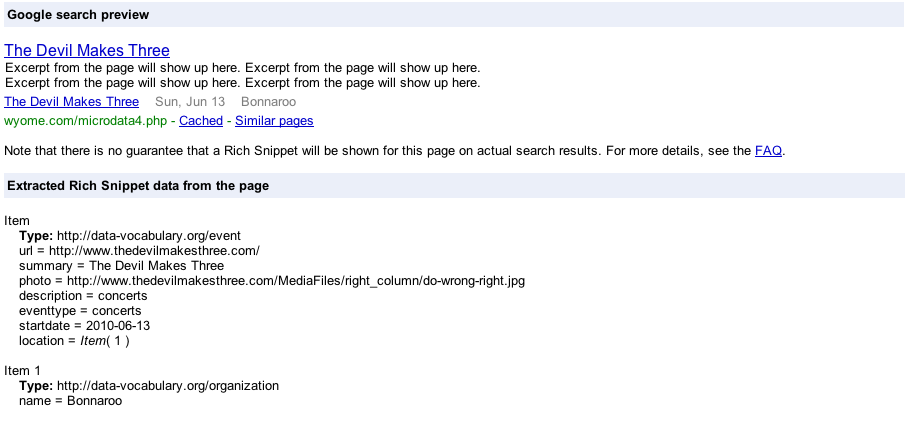
Теперь у нас есть событие в списке результатов поиска, в дополнение к нашему сайту. Опять же, мы даем контекст нашим данным таким образом, который может быть легко распознан другими приложениями.
Вывод
Важно еще раз подчеркнуть, что спецификация микроданных является молодой и претерпевает изменения. Не менее важно понимать, что, хотя я сосредоточился на результатах поиска Google, существует множество других приложений. Для моих целей Google предоставил мне лучший способ показывать микроданные в действии, что было для меня проблемой. Другие альтернативные форматы являются более зрелыми и используются довольно давно. Кроме того, еще одно важное соображение заключается в том, что Google в настоящее время вручную просматривает каждую запись фрагмента расширенного текста :

Микроданные очень просты в использовании и реализации. Несмотря на то, что спецификация не совсем понятна для неспециалистов в определениях атрибутов, я надеюсь, что помог пролить некоторый свет. Чтобы быть экспертом по микроданным, не нужно много, по крайней мере, пока спецификация не изменится (снова). Пожалуйста, поделитесь своими мыслями и опытом с этим молодым форматом HTML5 в комментариях.