В последнее время я много работал над CoffeeScript . Одной из проблем, с которой я столкнулся на раннем этапе, было тестирование: я не хотел вручную конвертировать CoffeeScript в JavaScript, прежде чем я смог его протестировать. Вместо этого я хотел протестировать непосредственно из CoffeeScript. Как я в итоге сделал это? Читай дальше что бы узнать!
Каждые несколько недель мы пересматриваем некоторые из любимых постов нашего читателя на протяжении всей истории сайта. Этот учебник был впервые опубликован в ноябре 2012 года.
Вам необходимо установить Node.js и Node Package Manager .
Прежде чем мы продолжим, я укажу, что вы должны иметь приличное знание CoffeeScript для этого урока; Я не буду объяснять кусочки здесь. Если вы заинтересованы в CoffeeScript, вам следует ознакомиться со статьями CoffeeScript, доступными здесь, на Nettuts + , или с документацией CoffeeScript .
Кроме того, для этого урока вам необходимо установить Node.js и менеджер пакетов узлов (npm). Если у вас их не установлено, не беспокойтесь: зайдите на nodejs.org и скачайте установщик для вашей платформы; тогда, ну, установите его!
Встреча Мокко и Чая
Мы будем строить начало приложения списка задач (клише, я знаю). Это будут классы CoffeeScript. Затем мы напишем несколько тестов с Mocha и Chai, чтобы проверить эту функциональность.
Почему и мокко, и чай? Ну, Mocha — это среда тестирования, но она не включает в себя фактический компонент утверждений. Это может звучать странно: в конце концов, есть не так много для библиотеки тестирования, не так ли? Ну, есть, в случае Мокко. Функции, которые привели меня в библиотеку, двояки: возможность запускать тесты из командной строки (вместо HTML-страницы для их запуска в браузере) и возможность запускать тесты в CoffeeScripts без необходимости конвертировать этот код в JavaScript (как минимум вручную: Mocha делает это за кулисами). Есть и другие функции, о которых я не буду здесь говорить, в том числе:
- Вы можете легко протестировать асинхронный код.
- Вы можете наблюдать за особенно медленными тестами.
- Вы можете выводить результаты в различных форматах.
И так далее. Смотрите больше на домашней странице Мокко . Для установки Mocha просто запустите npm install -g mocha , и все готово.
Что касается Chai: это отличная библиотека утверждений, которая предлагает интерфейсы для выполнения как BDD, так и TDD ; Вы можете использовать его как в браузере, так и в командной строке через узел, как мы будем использовать сегодня. Установите его для Node, через npm install -g chai .
Теперь, когда у нас установлены библиотеки, давайте начнем писать код.
Настройка нашего проекта
Давайте начнем с настройки мини-проекта. Создайте папку проекта. Затем создайте еще две папки в этой src : src и test . Наш код CoffeeScript будет src папку src , и наши тесты будут включены, как вы уже догадались, в папку tests . Mocha ищет test папку по умолчанию, так что, сделав это, мы немного сэкономим при печати.
Мокко ищет
testпапку по умолчанию.
Мы собираемся создать два класса CoffeeScript: Task , который будет элементом todo, и TaskList , который будет списком элементов todo (да, это больше, чем массив). Мы поместим их обоих в файл src/task.coffee . Тогда тесты для этого будут в test/taskTest.coffee . Конечно, мы могли бы разделить их на их собственные файлы, но мы просто не собираемся делать это сегодня.
Мы должны начать с импорта библиотеки Chai и включения синтаксиса BDD. Вот как:
|
1
2
|
chai = require ‘chai’
chai.should()
|
chai.should метод chai.should , мы фактически добавляем свойство chai.should в Object.prototype . Это позволяет нам писать тесты, которые читаются так:
|
1
|
task.name.should.equal «some string»
|
Если вы предпочитаете синтаксис TDD, вы можете сделать это:
|
1
|
expect = chai.expect
|
… Который позволяет вам писать тесты следующим образом:
|
1
|
expect(task.name).to.equal «some string»
|
На самом деле, нам придется использовать оба из них, как вы увидите; однако мы будем максимально использовать синтаксис BDD.
Теперь нам нужно импортировать наши классы Task и TaskList :
|
1
|
{TaskList, List} = require ‘../src/task’
|
Если вы не знакомы с этим синтаксисом, это деструктурированное назначение CoffeeScript на работе, а также некоторые его объектные литералы сахара. По сути, наш вызов require возвращает объект с двумя свойствами, которые являются нашими классами. Эта строка вытягивает их из этого объекта и дает нам две переменные с именами Task и TaskList , каждая из которых указывает на соответствующий класс.
Написание наших первых тестов
Большой! А как насчет теста? Прелесть синтаксиса Mocha в том, что его блоки ( describe и it ) идентичны синтаксису Jasmine (оба очень похожи на RSpec). Вот наш первый тест:
|
1
2
3
4
5
|
describe ‘Task instance’, ->
task1 = task2 = null
it ‘should have a name’, ->
task1 = new Task ‘feed the cat’
task1.name.should.equal ‘feed the cat’
|
Мы начнем с describe вызова: все эти тесты предназначены для экземпляра Test. Установив test1 = test2 = null вне наших индивидуальных тестов, мы можем использовать эти значения для нескольких тестов.
Затем в нашем первом тесте мы просто создаем задачу и проверяем, что ее свойство name имеет правильное значение. Прежде чем писать код для этого, давайте добавим еще два теста:
|
1
2
3
4
5
|
it ‘should be initially incomplete’, ->
task1.status.should.equal ‘incomplete’
it ‘should be able to be completed’, ->
task1.complete().should.be.true
task1.status.should.equal ‘complete’
|
Хорошо, давайте запустим эти тесты, чтобы убедиться, что они не работают. Для этого откроем командную строку и перейдем в папку вашего проекта. Затем выполните эту команду:
|
1
|
mocha —compilers coffee:coffee-script
|
Mocha не проверяет CoffeeScript по умолчанию, поэтому мы должны использовать флаг --compilers чтобы сообщить Mocha, какой компилятор использовать, если он находит файл с расширением coffee . Вы должны получить ошибки, которые выглядят так:
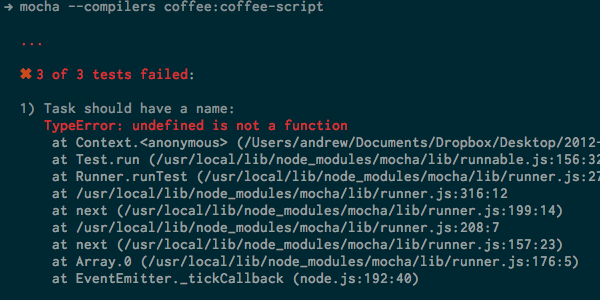
Если вместо того, чтобы увидеть это, вы получаете ошибку Cannot find module '../src/task' , это потому, что ваш файл src/task.coffee еще не существует. Сделайте указанный файл, и вы должны получить указанную ошибку.
Кодирование наших первых функций
Ну, теперь, когда у нас есть провальные тесты, пришло время написать код, правильно? Откройте этот файл src/task.coffee и начнем.
|
1
2
|
class Task
constructor: (@name) ->
|
Только этого достаточно, чтобы пройти наш первый тест. Если вы не знакомы с синтаксисом этого параметра, он просто устанавливает любое значение, переданное new Task @name (или this.name ). Однако давайте добавим еще одну строку в этот конструктор:
|
1
|
@status = ‘incomplete’
|
Это хорошо. Теперь вернитесь к терминалу и повторите наши тесты. Вы найдете это — подождите секунду, ничего не изменилось! Почему наши первые два теста не пройдены?
Простая проблема, на самом деле. Поскольку компилятор CoffeeScript оборачивает код в каждом файле в IIFE (или в вызывающую себя анонимную функцию), нам нужно «экспортировать» все, что мы хотим, чтобы оно было доступно из других файлов. В браузере вы бы сделали что-то вроде window.Whatever = Whatever . Для Node вы можете использовать global или exports . Мы будем использовать exports , поскольку 1) это считается наилучшей практикой и 2) к этому мы готовились при настройке наших тестов (помните наш вызов require ?). Поэтому в конце нашего файла task.coffee добавьте следующее:
|
1
2
|
root = exports ?
root.Task = Task
|
Имея это в виду, вы должны обнаружить, что два из наших трех тестов теперь проходят:
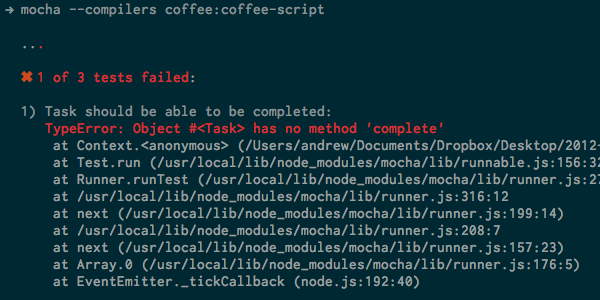
Чтобы пройти последний тест, мы должны добавить complete метод. Попробуй это:
|
1
2
3
|
complete: ->
@status = ‘complete’
true
|
Теперь все тесты проходят:

Сейчас самое время упомянуть, что у Mocha есть несколько разных отчетов: это просто разные способы вывода результатов теста. Вы можете запустить mocha --reporters чтобы увидеть ваши варианты:

По умолчанию Mocha использует точечный репортер. Однако я предпочитаю репортер спецификаций, поэтому я -R spec в конце команды ( -R — флаг настройки репортера).

Добавление функции
Давайте добавим функцию в наш класс Task : мы позволим задачам зависеть от других задач. Если «родительская» задача не выполнена, «дочерняя» задача не может быть выполнена. Мы сделаем эту функцию простой и позволим задачам иметь только одну подзадачу. Мы также не будем проверять рекурсивность, поэтому хотя можно будет установить две задачи как родительские и дочерние по отношению друг к другу, они сделают обе задачи неосуществимыми.
Сначала тесты!
|
01
02
03
04
05
06
07
08
09
10
11
12
|
it ‘should be able to be dependent on another task’, ->
task1 = new Task ‘wash dishes’
task2 = new Task ‘dry dishes’
task2.dependsOn task1
task2.status.should.equal ‘dependent’
task2.parent.should.equal task1
task1.child.should.equal task2
it ‘should refuse completion it is dependent on an uncompleted task’, ->
(-> task2.complete()).should.throw «Dependent task ‘wash dishes’ is not completed.»
|
Экземпляры Task будут иметь метод dependsOn , который dependsOn задачу, которая станет их родителем. Задачи, у которых есть родительская задача, должны иметь статус «зависимые». Кроме того, обе задачи получают либо parent либо child свойство, которое указывает на соответствующий экземпляр задачи.
Во втором тесте мы говорим, что задача с неполным родительским заданием должна вызвать ошибку при вызове complete метода. Обратите внимание на то, как работает синтаксис теста: нам нужно вызывать should из функции, а не результат функции: поэтому мы заключаем функцию в скобки. Таким образом, тестовая библиотека может вызвать саму функцию и проверить ее на наличие ошибок.
Запустите эти тесты, и вы увидите, что оба провалились. Время кодирования!
|
1
2
3
|
dependsOn: (@parent) ->
@parent.child = @
@status = ‘dependent’
|
Опять же, очень просто: мы просто устанавливаем параметр задачи для родительской задачи и присваиваем ему дочернее свойство, которое указывает на this экземпляр задачи. Затем мы устанавливаем статус this задачи как «зависимый».
Если вы запустите это сейчас, вы увидите, что один из наших тестов проходит, а второй нет: это потому, что наш метод complete не проверяет незавершенную родительскую задачу. Давайте изменим это.
|
1
2
3
4
5
|
complete: ->
if @parent?
throw «Dependent task ‘#{@parent.name}’ is not completed.»
@status = ‘complete’
true
|
Вот завершенный метод complete : если есть родительская задача, и она не выполнена, мы выдаем ошибку. В противном случае мы завершим задачу. Теперь все тесты должны пройти.
Создание TaskList
Далее мы TaskList класс TaskList . Опять же, мы начнем с теста:
|
1
2
3
4
5
6
|
describe ‘TaskList’, ->
taskList = null
it ‘should start with no tasks’, ->
taskList = new TaskList
taskList.tasks.length.should.equal 0
taskList.length.should.equal 0
|
На данный момент это старая вещь: мы создаем объект TaskList и проверяем его tasks и свойства length чтобы убедиться, что они оба равны нулю. Как вы можете догадаться, tasks — это массив, содержащий задачи, а length — это просто удобное свойство, которое мы будем обновлять при добавлении или удалении задач; это просто избавляет нас от необходимости писать list.tasks.length .
Чтобы пройти этот тест, мы сделаем этот конструктор:
|
1
2
3
4
|
class TaskList
constructor: () ->
@tasks = []
@length = 0
|
Хорошее начало, и это проходит наш тест.
Мы хотим иметь возможность добавлять задачи в список задач, верно? У нас будет метод add который может принимать либо экземпляр Task , либо строку, которую он преобразует в экземпляр Task .
Наши тесты:
|
1
2
3
4
5
6
7
8
9
|
it ‘should accept new tasks as tasks’, ->
task = new Task ‘buy milk’
taskList.add task
taskList.tasks[0].name.should.equal ‘buy milk’
taskList.length.should.equal 1
it ‘should accept new tasks as string’, ->
taskList.add ‘take out garbage’
taskList.tasks[1].name.should.equal ‘take out garbage’
taskList.length.should.equal 2
|
Сначала мы добавляем фактический объект Task и проверяем массив taskList.tasks чтобы убедиться, что он был добавлен. Затем мы добавляем строку и проверяем, чтобы объект Task с правильным именем был добавлен в массив tasks . В обоих случаях мы также проверяем длину taskList , чтобы убедиться, что это свойство обновляется.
И функция:
|
1
2
3
4
5
6
|
add: (task) ->
if typeof task is ‘string’
@tasks.push new Task task
else
@tasks.push task
@length = @tasks.length
|
Я думаю, довольно понятно. И теперь наши тесты проходят:
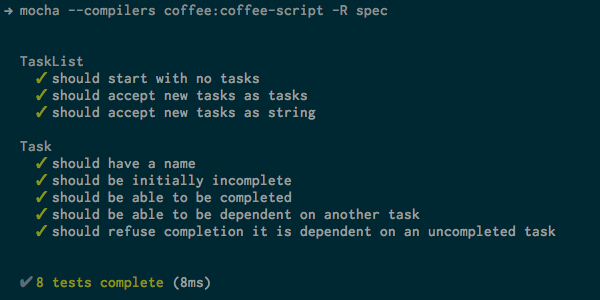
Конечно, мы можем захотеть удалить задачи из нашего списка, верно?
|
1
2
3
4
|
it ‘should remove tasks’, ->
i = taskList.length — 1
taskList.remove taskList.tasks[i]
expect(taskList.tasks[i]).to.not.be.ok
|
Во-первых, мы вызываем метод remove (который еще не написан, конечно), передавая ему последнюю задачу в списке. Конечно, мы могли бы просто жестко закодировать индекс 1 , но я сделал это таким образом, потому что это делает этот тест гибким: если мы изменили наши предыдущие тесты или добавили больше тестов над этим, это может измениться. Конечно, мы должны удалить последнюю, потому что в противном случае задача после нее займет свое место, и в этом индексе будет что-то, когда мы ожидаем, что ничего не будет.
Говоря об ожидании, обратите внимание, что мы используем функцию expect и синтаксис здесь вместо нашего обычного. Это потому, что taskList.tasks[i] будет undefined , который не наследуется от Object.prototype , и поэтому мы не можем его использовать.
О, да, нам все еще нужно написать функцию remove :
|
1
2
3
4
|
remove: (task) ->
i = @tasks.indexOf task
@tasks = @tasks[0…i].concat @tasks[i+1..] if i > -1
@length = @tasks.length
|
Некоторая изощренная работа с массивами в сочетании с диапазонами CoffeeScript и сокращением соединения массивов закрывает эту сделку для нас. Мы просто разделяем все элементы перед тем, как удалить, и все элементы после него; мы concat эти два массива вместе. Конечно, мы обновим @length соответственно. Можете ли вы сказать «сдача экзаменов»?
Давайте сделаем еще одну вещь. Мы хотим напечатать наш (относительно) красивый список текущих задач. Это будет наш самый сложный (или, по крайней мере, наш самый длинный) тест:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
it ‘should print out the list’, ->
taskList = new TaskList
task0 = new Task ‘buy milk’
task1 = new Task ‘go to store’
task2 = new Task ‘another task’
task3 = new Task ‘sub-task’
task4 = new Task ‘sub-sub-task’
taskList.add task0
taskList.add task1
taskList.add task2
taskList.add task3
taskList.add task4
task0.dependsOn task1
task4.dependsOn task3
task3.dependsOn task2
task1.complete()
desiredOutput = «»»Tasks
— buy milk (depends on ‘go to store’)
— go to store (completed)
— another task
— sub-task (depends on ‘another task’)
— sub-sub-task (depends on ‘sub-task’)
«»»
taskList.print().should.equal desiredOutput
|
Что тут происходит? Сначала мы создаем новый объект TaskList чтобы начать с нуля. Затем мы создаем пять задач и добавляем их в taskList . Далее мы установили несколько зависимостей. Наконец мы выполнили одну из наших задач.
Мы используем синтаксис heredoc CoffeeScript для создания многострочной строки. Как видите, у нас все довольно просто. Если у задачи есть родительская задача, она упоминается в скобках после имени задачи. Если задание выполнено, мы тоже это ставим.
Готов написать функцию?
|
1
2
3
4
5
6
7
8
|
print: ->
str = «Tasks\n\n»
for task in @tasks
str += «- #{task.name}»
str += » (depends on ‘#{task.parent.name}’)» if task.parent?
str += ‘ (complete)’ if task.status is ‘complete’
str += «\n»
str
|
Это на самом деле довольно просто: мы просто просматриваем массив @tasks и добавляем их в строку. Если у них есть родитель, мы добавляем это, и если они полны, мы также добавляем это. Обратите внимание, что мы используем форму модификатора оператора if , чтобы ужесточить наш код. Затем мы возвращаем строку.
Теперь все наши тесты должны пройти:
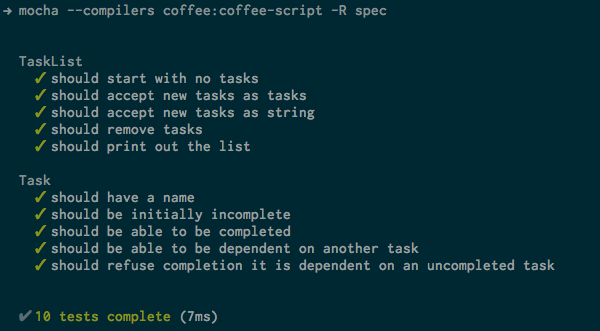
Завершение
Попробуйте добавить несколько функций, чтобы освоить все это.
Это предел нашего маленького проекта сегодня. Вы можете скачать код в верхней части этой страницы; на самом деле, почему бы вам не попробовать добавить несколько функций, чтобы освоить все это? Вот несколько идей:
- Не допускайте, чтобы экземпляры
Taskмогли зависеть друг от друга (рекурсивные зависимости). - Заставьте метод
TaskList::addвыдавать ошибку, если он получает что-то отличное от строки или объектаTask.
В эти дни я нахожу CoffeeScript все более привлекательным, но самым большим его недостатком является то, что он должен быть скомпилирован в JavaScript, прежде чем он будет полезен. Я благодарен за все, что сводит на нет некоторые из этих прерывателей рабочего процесса, и Мокко определенно делает это. Конечно, он не идеален (так как он компилируется в JS перед выполнением кода, номера строк в ошибках не совпадают с номерами ваших строк CoffeeScript), но для меня это шаг в правильном направлении!
Как насчет тебя? Если вы используете CoffeeScript, как вы делали тестирование? Дай мне знать в комментариях.