Распространенной и сложной проблемой получения данных является извлечение таблиц из PDF. Ранее я описывал, как извлечь текст из PDF с помощью PDF.js , библиотеки рендеринга PDF, созданной Mozilla Labs.
Процесс рендеринга требует HTML-объекта canvas, а затем рисует на нем каждый объект (символ, линию, прямоугольник и т. Д.). Самый простой способ получить их список — перехватить все вызовы PDF.js, выполняемые функциями рисования на объекте canvas. (см. « Самомодифицирующиеся JavaScript » для аналогичной техники). Метод «set» ниже добавляет закрытие оболочки к каждой функции, которая регистрирует вызов.
function replace(ctx, key) {
var val = ctx[key];
if (typeof(val) == "function") {
ctx[key] = function() {
var args = Array.prototype.slice.call(arguments);
console.log("Called " + key + "(" + args.join(",") + ")");
return val.apply(ctx, args);
}
}
}
for (var k in context) {
replace(context, k);
}
var renderContext = {
canvasContext: context,
viewport: viewport
};
page.render(renderContext);
Это позволяет нам увидеть серию звонков:
Called transform(1,0,0,1,150.42,539.67) Called translate(0,0) Called scale(1,-1) Called scale(0.752625,0.752625) Called measureText(C) Called save() Called scale(0.9701818181818181,1) Called fillText(C,0,0) Called restore() Called restore() Called save() Called transform(1,0,0,1,150.42,539.6
Мы можем легко получить текст, отметив первый аргумент для каждого вызова «fillText»:
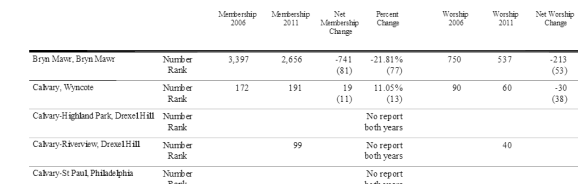
"Congregations Ranked by Growth and Decline in Membership and Worship Attendance, 2006 to 2011Philadelphia Presbytery - Table 16Net Membership ChangeNet Worship ChangePercent ChangePercent ChangeWorship 2006Worship 2011Membership 2006Membership 2011Abington, Abington- 143(74)-13.18%(57)0(15)0.00%(22)NumberRank3003001,085942Anchor, Wrightstown0(23)0.00%(27)-12(25)-21.43%(52)NumberRank56449797Arch Street, Philadelphia-117(71)-68.42%(117)27(5)90.00% (2)NumberRank305717154Aston, Aston3(21)3.53%(22)-5(19)-9.43% (31)NumberRank53488588BeaconNo reportboth yearsNo reportboth yearsNumberRankBensalem, Bensalem-23(39)-13.94%(62)-28(36)-28.57% (64)NumberRank9870165142Berean, Philadelphia106(4)44.92%(4)No reportboth yearsNumberRank00236342Bethany Collegiate, Havertown- 188(76)-42.44%(110)43(3)21.29%(7)NumberRank202245443255Bethel, Philadelphia-13(33)-13.68%(60)-27(35)-35.06% (71)NumberRank77509582Bethesda, Philadelphia9(18)5.56%(18)No reportboth yearsNumberRank1150162171Beverly Hills, Upper Darby-3(26)-3.03% (32)-11(24)-20.00%(48)NumberRank55449996Bridesburg, Philadelphia0(23)0.00%(27)No reportboth yearsNumberRank004444Bristol, BristolNo reportboth yearsNo reportboth yearsNumberRankPage 1 of 10Report prepared by Research Services, Presbyterian Church (U.S.A.)1- 800-728-7228, ext #204006-Oct-12"
Примечательно, что это не отслеживает окончания строк, и не все символы записываются в ожидаемом порядке (первая строка отображается после второй).
Призывы к преобразованию, переводу и масштабированию контролируют место размещения текста. Метод fillText также принимает набор параметров (x, y), который перемещает отдельные буквы между словами. Точная позиция — это комбинация последовательных операций, которые моделируются как стек матричных операций.
К счастью, PDF.js отслеживает вывод этих операций по мере их рендеринга, поэтому нам не нужно пересчитывать его.
Таким образом, мы можем сделать метод, который записывает буквы и их реальные позиции. Этот метод принимает объект внутреннего контекста, тип перехода состояния и аргументы перехода. Этот метод затем вызывается из функции ‘record’, указанной выше.
var chars = [];
var cur = {};
function record(ctx, state, args) {
if (state === 'fillText') {
var c = args[0];
cur.c = c;
cur.x = ctx._transformMatrix[4] + args[1];
cur.y = ctx._transformMatrix[5] + args[2];
chars[chars.length] = cur;
cur = {};
}
}
Эти результаты могут быть отсортированы по позиции (х и у). Метод sort упорядочивает буквы по позициям — если они сдвинуты на небольшую величину вверх или вниз, они считаются одной строкой.
chars.sort(
function(a, b) {
var dx = b.x - a.x;
var dy = b.y - a.y;
if (Math.abs(dy) < 0.5) {
return dx * -1;
} else {
return dy * -1;
}
}
);
Это создает несколько трудностей: это не обнаруживает текст справа налево, и становится ясно, что нам будет трудно узнать, когда вы находитесь за столом, а когда нет.
Для этого мы определяем функцию, которая может преобразовывать массив букв и позиций в вывод в стиле CSV. Это отслеживает от буквы к букве — если он видит «большое» изменение у, он создает новую строку. Если он видит «большое» изменение в x, он рассматривает его как новый столбец.
Реальная проблема — определить «большой», который для моего тестового PDF был около 15 и 20, для dx и dy.
function getText(marks, ex, ey, v) {
var x = marks[0].x;
var y = marks[0].y;
var txt = '';
for (var i = 0; i < marks.length; i++) {
var c = marks[i];
var dx = c.x - x;
var dy = c.y - y;
if (Math.abs(dy) > ey) {
txt += "\"\n\"";
if (marks[i+1]) {
// line feed - start from position of next line
x = marks[i+1].x;
}
}
if (Math.abs(dx) > ex) {
txt += "\",\"";
}
if (v) {
console.log(dx + ", " + dy);
}
txt += c.c;
x = c.x;
y = c.y;
}
return txt;
}
Этот алгоритм не обрабатывает новые строки в строках, и, как ни странно, столбцы выходят не в правильном порядке, но они выглядят непоследовательно. Строки с большими пробелами (например, em-dash) обнаруживаются как имеющие несколько столбцов, но это может быть очищено позже — вот пример выходных данных.
Вы можете увидеть пример ниже, и окончательный источник доступен на github .
Congregations Ranked by Growth and Decline in M","embership and W","orship Attendance, 2006 to 2011" "","Philadelphia Presbytery"," - Table 16" "","Net ","Membership ","Change" "","Net Worship ","Change","Percent ","Change","Percent ","Change","Worship"," 2006","Worship"," 2011","Membership"," 2006","Membership"," 2011" "","Abington, Abington","-143","(74)","-13.18%(57)","0","(15)","0.00%(22)","Number","Rank","300","300","1,085","942" "","Anchor, Wrightstown","0","(23)","0.00%(27)","-12","(25)","-21.43%(52)","Number","Rank","56","44","97","97" "","Arch Street, Philadelphia","-117","(71)","-68.42%","(117)","27(5)","90.00%(2)","Number","Rank","30","57","171","54" "","Aston, Aston","3","(21)","3.53%(22)","-5","(19)","-9.43%(31)","Number","Rank","53","48","85","88" "","Beacon","No report","both years","No report","both years","Number","Rank" "","Bensalem, Bensalem","-23","(39)","-13.94%(62)","-28","(36)","-28.57%(64)","Number","Rank","98","70","165","142" "","Berean, Philadelphia","106(4)","44.92%(4)","No report","both years","Number","Rank","0","0","236","342" "","Bethany Collegiate, Havertown","-188","(76)","-42.44%","(110)","43(3)","21.29%(7)","Number","Rank","202","245","443","255" "","Bethel, Philadelphia","-13","(33)","-13.68%(60)","-27","(35)","-35.06%(71)","Number","Rank","77","50","95","82" "","Bethesda, Philadelphia","9","(18)","5.56%(18)","No report","both years","Number","Rank","115","0","162","171" "","Beverly Hills, Upper Darby","-3","(26)","-3.03%(32)","-11","(24)","-20.00%(48)","Number","Rank","55","44","99","96" "","Bridesburg, Philadelphia","0","(23)","0.00%(27)","No report","both years","Number","Rank","0","0","44","44" "","Bristol, Bristol","No report","both years","No report","both years","Number","Rank" "","Page 1 of 10","Report prepared by Research Services, Presbyterian Church (U.S.A.)","1-800-728-7228, ext #2040","06-Oct-12"