В первой главе мы говорили о ресурсах, но в основном фокусировались на URL и на том, как интерпретировать URL. Тем не менее, ресурсы являются центральным элементом HTTP. Теперь, когда мы понимаем HTTP-сообщения, методы и соединения, мы можем вернуться к рассмотрению ресурсов в новом свете. В этой главе мы поговорим об истинной сути работы с ресурсами при разработке веб-приложений и веб-сервисов.
Ресурсы Redux
Хотя веб-ресурс легко представить себе как файл в файловой системе веб-сервера, при таком подходе не учитывается истинная возможность абстракции ресурса. Многие веб-страницы требуют физических ресурсов в файловой системе — файлов JavaScript, изображений и таблиц стилей. Тем не менее, потребители и пользователи Интернета не заботятся об этих фоновых ресурсах. Вместо этого им важны ресурсы, с которыми они могут взаимодействовать, и, что более важно, ресурсы, которые они могут назвать. Ресурсы, такие как:
- Рецепт салата из брокколи
- Результаты поиска по запросу «Chicago pizza»
- История болезни пациента 123
Все эти ресурсы являются типами ресурсов, вокруг которых мы создаем приложения, и общая тема в списке — то, насколько каждый элемент достаточно важен для идентификации и названия. Если мы можем идентифицировать ресурс, мы также можем дать ресурсу URL, чтобы кто-то мог найти ресурс. URL-это удобная вещь, чтобы иметь вокруг. Разумеется, имея URL, вы можете найти ресурс, но вы также можете передать его кому-то еще, встраивая URL в гиперссылку или отправляя его по электронной почте.
Но есть много вещей, которые вы не можете сделать с URL. Скорее, есть много вещей, которые URL не может сделать. Например, URL не может ограничивать клиента или сервер конкретным типом технологии. Все говорят по HTTP. Не имеет значения, является ли ваш клиент C ++, а ваше веб-приложение — на Ruby.
Кроме того, URL-адрес не может заставить сервер хранить ресурс с использованием какой-либо конкретной технологии. Ресурс может быть документом в файловой системе, но веб-платформа также может отвечать на запрос ресурса и создавать ресурс, используя информацию, хранящуюся в файлах, хранящуюся в базах данных, полученную из веб-сервисов, или получать ресурс из текущей время суток
URL не может даже указать представление конкретного ресурса, а ресурс может иметь несколько представлений. Как мы узнали ранее, клиент может запросить конкретное представление, используя заголовки в сообщении HTTP-запроса. Клиент может запросить определенный язык или определенный тип контента. Если вы когда-либо работали с веб-приложением, которое позволяет согласовывать контент, вы видели гибкость ресурсов в действии. JavaScript может запрашивать данные пациента 123 в формате JSON, C # может запрашивать тот же ресурс в формате XML, а браузер может запрашивать данные в формате HTML. Все они работают с одним и тем же ресурсом, но используют три разных представления.
Еще одна вещь, которую URL не может сделать — он не может сказать, что пользователь хочет сделать с ресурсом. URL не говорит, хочу ли я получить ресурс или отредактировать ресурс. Задача сообщения HTTP-запроса — описать это намерение, используя один из стандартных методов HTTP. Как мы говорили во второй части этого сеанса, существует ограниченное количество стандартных методов HTTP, включая GET , POST , PUT и DELETE .
Когда вы начинаете думать о ресурсах и URL-адресах, как в этой главе, вы начинаете рассматривать Интернет как часть вашего приложения и как гибкий архитектурный уровень, на котором вы можете строить. Для более глубокого понимания этого мышления см. Знаменитую диссертацию Роя Филдинга под названием «Архитектурные стили и проектирование сетевых программных архитектур». Эта диссертация представляет собой статью, в которой представлен стиль архитектуры представления состояния (REST) и более подробно рассматриваются идеи и концепции в этом и следующем разделах. Статья размещена по адресу http://www.ics.uci.edu/~fielding/pubs/dis Диссертация/ top.htm .
Видимый протокол-HTTP
До сих пор мы были сосредоточены на том, что URL не может делать , когда мы должны сосредоточиться на том, что может делать URL. Или, скорее, сосредоточиться на том, что могут сделать URL и HTTP, потому что они прекрасно работают вместе. В своей диссертации Филдинг описывает преимущества использования HTTP. Эти преимущества включают в себя масштабируемость, простоту, надежность и слабую связь. HTTP предлагает эти преимущества частично потому, что вы можете рассматривать URL как указатель или единицу косвенного обращения между клиентским и серверным приложением. Опять же, сам URL не диктует конкретное представление ресурса, реализацию технологии или намерение клиента. Вместо этого клиент может выразить желаемое намерение и представление в HTTP-сообщении.
HTTP-сообщение — это простое текстовое сообщение. Прелесть HTTP-сообщения в том, что и запрос, и ответ полностью самоописывают. Запрос включает в себя метод HTTP (что хочет сделать клиент), путь к ресурсу и дополнительные заголовки, предоставляющие информацию о желаемом представлении. Ответ включает в себя код состояния, чтобы указать результат транзакции, но также включает в себя заголовки с инструкциями кеша, тип содержимого ресурса, длину ресурса и, возможно, другие ценные метаданные.
Поскольку вся информация, необходимая для транзакции, содержится в сообщениях, а информация видна и легко анализируется, приложения HTTP могут полагаться на ряд служб, которые предоставляют значение при перемещении сообщения между клиентским приложением и приложением сервера. ,
Добавив значение
Когда сообщение HTTP перемещается из пространства памяти в процессе на одном компьютере в пространство памяти в процессе на другом компьютере, оно может перемещаться через несколько программных и аппаратных средств, которые проверяют и, возможно, модифицируют сообщение. Один хороший пример — это само приложение веб-сервера. Веб-сервер, такой как Apache или IIS, будет одним из первых получателей входящего HTTP-запроса на серверном компьютере, и в качестве веб-сервера он может направить сообщение в соответствующее приложение.
Веб-сервер может использовать информацию в сообщении, такую как URL-адрес или заголовок узла, при принятии решения, куда отправить сообщение. Сервер также может выполнять дополнительные действия с сообщением, такие как запись сообщения в локальный файл. Приложениям на сервере не нужно беспокоиться о регистрации, поскольку сервер настроен на запись всех сообщений.
Аналогично, когда приложение создает ответное сообщение HTTP, сервер может взаимодействовать с сообщением при выходе. Опять же, это может быть простая операция регистрации, но это также может быть прямое изменение самого сообщения. Например, сервер может знать, поддерживает ли клиент сжатие gzip, потому что клиент может объявить этот факт через заголовок Accept-Encoding в HTTP-запросе. Сжатие позволяет серверу взять ресурс объемом 100 КБ и превратить его в ресурс объемом 25 КБ для более быстрой передачи. Вы можете настроить множество веб-серверов на автоматическое использование сжатия для определенных типов контента (обычно текстовых), и это происходит без беспокойства самого приложения о сжатии. Сжатие — это дополнительная ценность, предоставляемая самим программным обеспечением веб-сервера.
Приложениям не нужно беспокоиться о регистрации HTTP-транзакций или сжатии, и все это благодаря самоописательным HTTP-сообщениям, которые позволяют другим частям инфраструктуры обрабатывать и преобразовывать сообщения. Этот тип обработки может происходить, когда сообщение перемещается и по сети.
Доверенные
Прокси-сервер — это компьютер, который находится между клиентом и сервером. Прокси-сервер в основном прозрачен для конечных пользователей. Вы думаете, что отправляете сообщения HTTP-запроса непосредственно на сервер, но на самом деле эти сообщения отправляются на прокси-сервер. Прокси-сервер принимает сообщения HTTP-запроса от клиента и перенаправляет сообщения на нужный сервер. Затем прокси принимает ответ сервера и пересылает ответ обратно клиенту. Перед пересылкой этих сообщений прокси-сервер может проверять сообщения и потенциально предпринимать некоторые дополнительные действия.
Один из клиентов, на которого я работаю, использует прокси-сервер для захвата всего HTTP-трафика, покидающего офис. Они не хотят, чтобы сотрудники и подрядчики проводили все свое время в Твиттере и Фейсбуке, поэтому HTTP-запросы к этим серверам никогда не дойдут до места назначения, и в офисе нет твитов или Фармвилля. Это пример одной популярной роли для прокси-серверов, которая должна функционировать как устройство контроля доступа.
Тем не менее, прокси-сервер может быть гораздо более сложным, чем просто пересылать сообщения на определенные узлы — простой брандмауэр может выполнить эту задачу. Прокси-сервер также может проверять сообщения для удаления конфиденциальных данных, например заголовки Referer которые указывают на внутренние ресурсы в сети компании. Прокси-сервер управления доступом также может регистрировать HTTP-сообщения для создания контрольных журналов по всему трафику. Многие прокси управления доступом требуют аутентификации пользователя — тема, которую мы рассмотрим в следующей статье.
Прокси, который я описываю в предыдущем абзаце, это то, что мы называем прямым прокси . Прямые прокси-серверы обычно ближе к клиенту, чем к серверу, и для работы прямых прокси-серверов обычно требуется некоторая конфигурация в клиентском программном обеспечении или веб-браузере.
Обратный прокси-сервер — это прокси-сервер, который расположен ближе к серверу, чем клиент, и полностью прозрачен для клиента.
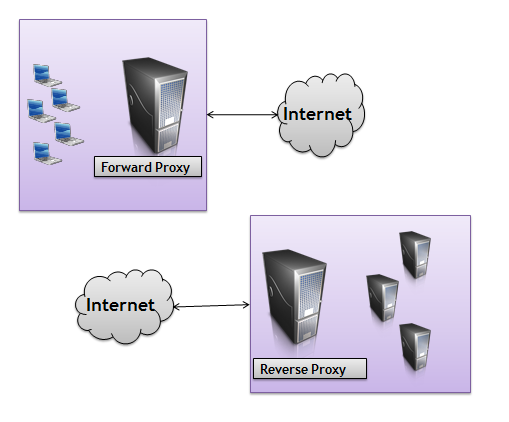
Оба типа прокси могут предоставлять широкий спектр услуг. Если мы вернемся к сценарию сжатия gzip, о котором мы говорили ранее, прокси-сервер сможет сжимать тела ответных сообщений. Компания может использовать обратный прокси-сервер для сжатия, чтобы снять вычислительную нагрузку с веб-серверов, на которых находится приложение. Теперь ни приложение, ни веб-сервер не должны беспокоиться о сжатии. Вместо этого сжатие — это функция, которая наслоена через прокси. В этом прелесть HTTP.
Некоторые другие популярные прокси-сервисы включают следующее.
Прокси- серверы с балансировкой нагрузки могут принять сообщение и переслать его на один из нескольких веб-серверов на основе циклического перебора или узнать, какой сервер в настоящее время обрабатывает наименьшее количество запросов.
Прокси- серверы ускорения SSL могут шифровать и дешифровать HTTP-сообщения, снимая нагрузку шифрования с веб-сервера. Мы поговорим подробнее о SSL в следующей главе.
Прокси могут обеспечить дополнительный уровень безопасности , отфильтровывая потенциально опасные сообщения HTTP. В частности, сообщения, которые выглядят так, как будто они пытаются найти уязвимость межсайтового скриптинга (XSS) или запустить атаку SQL-инъекцией.
Кэширующие прокси могут хранить копии часто используемых ресурсов и отвечать на сообщения, запрашивающие эти ресурсы напрямую. Мы подробнее рассмотрим кеширование в следующем разделе.
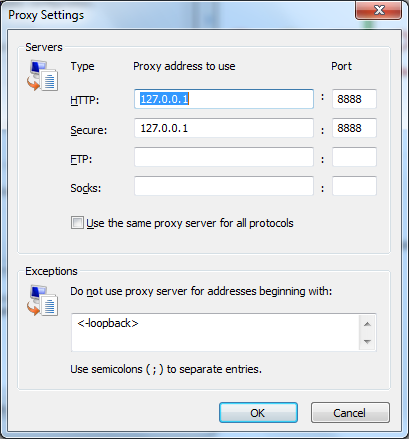
Наконец, стоит отметить, что прокси не обязательно должен быть физическим сервером. Fiddler, инструмент, упомянутый в предыдущей главе, является отладчиком HTTP, который позволяет вам захватывать и проверять сообщения HTTP. Fiddler работает, приказывая Windows перенаправлять весь исходящий HTTP-трафик на порт 8888 по IP-адресу 127.0.0.1. Этот IP-адрес является адресом обратной связи, то есть трафик просто направляется непосредственно на локальную машину, где Fiddler теперь прослушивает порт 8888. Fiddler принимает сообщение HTTP-запроса, регистрирует его, пересылает его в пункт назначения, а также перехватывает ответ перед пересылкой. ответ на локальное приложение. Вы можете просмотреть настройки прокси в Internet Explorer (IE), выбрав Сервис , Свойства обозревателя , перейдя на вкладку Подключения , а затем нажав кнопку Параметры локальной сети . В области « Прокси-сервер» нажмите кнопку « Дополнительно» , чтобы просмотреть сведения о прокси-сервере.
Прокси-серверы являются прекрасным примером того, как HTTP может влиять на архитектуру веб-приложения или веб-сайта. Существует множество сервисов, которые вы можете подключить к сети без влияния на приложение. Единственный сервис, который мы хотим рассмотреть более подробно, — это кэширование.
Кэширование
Кэширование — это оптимизация, сделанная для повышения производительности и масштабируемости. При наличии нескольких запросов на одно и то же представление ресурса сервер может отправлять одни и те же байты по сети снова и снова для каждого запроса. Или прокси-сервер или клиент могут локально кэшировать представление и сократить количество времени и пропускную способность, необходимые для полного поиска. Кэширование может уменьшить задержку, помочь предотвратить узкие места и позволить выжить веб-приложению, когда каждый пользователь сразу появляется, чтобы купить новейший продукт или увидеть последний пресс-релиз. Кэширование также является отличным примером того, как метаданные в заголовках HTTP-сообщений облегчают дополнительные уровни и сервисы.
Первое, что нужно знать, это то, что существует два типа кэшей.
Публичный кеш — это кеш, совместно используемый несколькими пользователями. Публичный кеш обычно находится на прокси-сервере. Общедоступный кеш на прямом прокси-сервере обычно кеширует ресурсы, которые популярны в сообществе пользователей, таких как пользователи конкретной компании или пользователи конкретного интернет-провайдера. Общедоступный кеш на обратном прокси-сервере обычно кеширует ресурсы, которые популярны на определенном веб-сайте, например изображения популярных продуктов с Amazon.com.
Частный кеш выделен для одного пользователя. Веб-браузеры всегда хранят частный кеш ресурсов на вашем диске (это «Временные интернет-файлы» в IE или введите about:cache в адресной строке Google Chrome, чтобы увидеть файлы в личном кеше Chrome). Все, что браузер кэшировал в файловой системе, может появиться практически мгновенно на экране.
Правила о том, что кешировать, когда кешировать и когда делать недействительным элемент кеша (то есть выгружать его из кеша), к сожалению, сложны и запутаны некоторыми унаследованными поведениями и несовместимыми реализациями. Тем не менее, я постараюсь указать на некоторые вещи, которые вы должны знать о кэшировании.
В HTTP 1.1 ответное сообщение с кодом состояния 200 (ОК) для запроса HTTP GET кэшируется по умолчанию (это означает, что прокси и клиентам разрешено кэшировать ответ). Приложение может влиять на это значение по умолчанию, используя правильные заголовки в ответе HTTP. В HTTP 1.1 этот заголовок является заголовком Cache-Control , хотя вы также можете видеть заголовок Expires во многих сообщениях. Заголовок Expires все еще существует и широко поддерживается, несмотря на то, что он устарел в HTTP 1.1. Pragma — это еще один пример заголовка, который используется для управления поведением кэширования, но на самом деле он используется только для обратной совместимости. В этой книге я сосредоточусь на Cache-Control .
HTTP-ответ может иметь значение для Cache-Control : public , private или no-cache . Значение public означает, что публичные прокси-серверы могут кэшировать ответ. Значение private означает, что только браузер может кэшировать ответ. Значение no-cache означает, что никто не должен кэшировать ответ. Существует также значение no-store , означающее, что сообщение может содержать конфиденциальную информацию и не должно сохраняться, а должно быть удалено из памяти как можно скорее.
Как вы используете эту информацию? Для популярных общих ресурсов (например, изображения логотипа домашней страницы) вы можете использовать директиву управления public кэшем и разрешить кэшировать изображение всем, даже прокси-серверам.
Для ответов на конкретного пользователя (например, HTML-код для домашней страницы, включающей имя пользователя) вы должны использовать директиву приватного кэша.
Примечание. В ASP.NET вы можете управлять этими настройками через Response.Cache .
Сервер также может указать значение max-age в Cache-Control . Значение max-age — это количество секунд для кеширования ответа. По истечении этих секунд запрос всегда должен возвращаться на сервер для получения обновленного ответа. Давайте посмотрим на некоторые примеры ответов.
Вот частичный ответ от Flickr.com для одного из CSS-файлов Flickr.
HTTP / 1.1 200 ОК Дата последнего изменения: ср, 25 января 2012 17:55:15 GMT Истекает: сб, 22 января 2022 17:55:15 GMT Cache-Control: max-age = 315360000, общедоступный
Обратите внимание, что Cache-Control позволяет публичным и частным кешам кэшировать файл, и они могут хранить его более 315 миллионов секунд (10 лет). Они также используют заголовок Expires чтобы указать конкретную дату истечения срока действия. Если клиент совместим с HTTP 1.1 и понимает Cache-Control , ему следует использовать значение в max-age вместо Expires . Обратите внимание, что это не означает, что Flickr планирует использовать один и тот же файл CSS в течение 10 лет. Когда Flickr изменит свой дизайн, он, вероятно, просто использует другой URL для своего обновленного файла CSS.
Ответ также включает в себя заголовок Last-Modified чтобы указать, когда представление было в последний раз изменено (что может быть просто временем запроса). Логика кэширования может использовать это значение в качестве валидатора или значение, которое клиент может использовать, чтобы увидеть, является ли кэшированное представление действительным. Например, если агент решит, что ему нужно проверить ресурс, он может выполнить следующий запрос.
ПОЛУЧИТЬ… HTTP / 1.1 If-Modified-Since: ср, 25 января 2012 17:55:15 GMT
Заголовок If-Modified-Since сообщает серверу, что клиенту нужен полный ответ, только если ресурс изменился. Если ресурс не изменился, сервер может ответить сообщением 304 Not Modified .
HTTP / 1.1 304 не изменен Истекает: сб, 22 января 2022 17:16:19 GMT Cache-Control: max-age = 315360000, общедоступный
Сервер сообщает клиенту: продолжайте и используйте байты, которые вы уже кэшировали.
Другой валидатор, который вы обычно видите, это ETag .
HTTP / 1.1 200 ОК Сервер: Apache Дата последнего изменения: пт, 06 января 2012 18:08:20 GMT ETag: "8e5bcd-59f-4b5dfef104d00" Тип контента: текст / xml Варьируется: Accept-Encoding Контент-кодировка: gzip Длина контента: 437
ETag — это непрозрачный идентификатор, то есть он не имеет никакого внутреннего значения. ETag часто создается с использованием алгоритма хеширования ресурса. Если ресурс когда-либо изменится, сервер вычислит новый ETag . Запись в кэше может быть проверена путем сравнения двух ETag . Если ETag одинаковы, ничего не изменилось. Если ETag отличаются, пришло время аннулировать кэш.
Где мы?
В этой главе мы рассмотрели некоторые архитектурные теории, а также практические преимущества архитектуры HTTP. Возможность наложения кэширования и других сервисов между сервером и клиентом была движущей силой успеха HTTP и Интернета. Видимость HTTP-сообщений с самоописанием и косвенность, обеспечиваемая URL-адресами, делает все это возможным. В следующей главе мы поговорим о нескольких темах, которые мы обошли, такие как аутентификация и шифрование.