В прошлой статье мы рассмотрели HTTP-сообщения и увидели примеры текстовых команд и кодов, которые передаются от клиента к серверу и обратно в HTTP-транзакции. Но как информация в этих сообщениях перемещается по сети? Когда открываются сетевые подключения? Когда соединения закрыты? Вот некоторые из вопросов, на которые ответит эта статья, когда мы смотрим на HTTP с точки зрения низкого уровня. Но сначала нам нужно понять некоторые абстракции ниже HTTP.
Вихрь тур по сети
Чтобы понять HTTP-соединения, нам нужно немного узнать о том, что происходит в слоях под HTTP. Сетевое общение, как и многие приложения, состоит из слоев. Каждый уровень коммуникационного стека отвечает за определенное и ограниченное количество обязанностей.
Например, HTTP — это то, что мы называем протоколом прикладного уровня, поскольку он позволяет двум приложениям взаимодействовать по сети. Довольно часто одно из приложений представляет собой веб-браузер, а другое — веб-сервер, такой как IIS или Apache. Мы видели, как HTTP-сообщения позволяют браузеру запрашивать ресурсы с сервера. Но спецификации HTTP ничего не говорят о том, как сообщения на самом деле пересекают сеть и достигают сервера — это работа протоколов нижнего уровня. Сообщение от веб-браузера должно проходить через ряд слоев, а когда оно поступает на веб-сервер, оно проходит через ряд слоев, чтобы достичь процесса веб-службы.
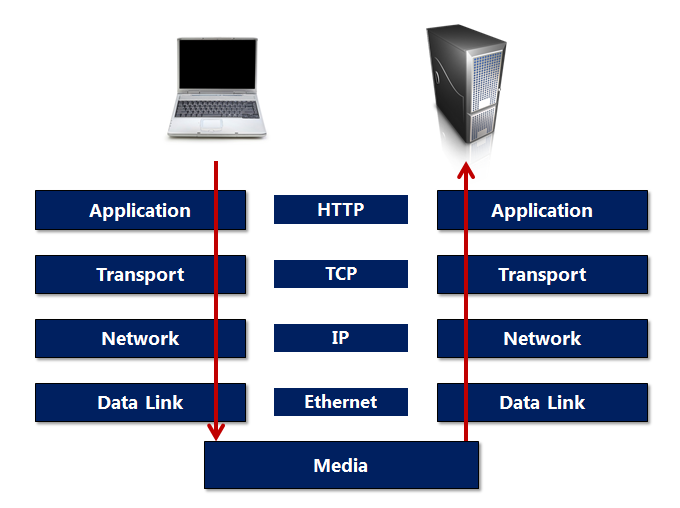
Уровень под HTTP является протоколом транспортного уровня . Почти весь HTTP-трафик проходит по TCP (сокращенно от Transmission Control Protocol), хотя для HTTP это не требуется. Когда пользователь вводит URL в браузер, браузер сначала извлекает имя хоста из URL (и номер порта, если таковой имеется) и открывает сокет TCP , указав адрес сервера (получаемый из имени хоста) и порт (который по умолчанию 80).
Как только приложение имеет открытый сокет, оно может начать запись данных в сокет. Единственное, о чем должен беспокоиться браузер, — это записать правильно отформатированное сообщение HTTP-запроса в сокет. Уровень TCP принимает данные и обеспечивает доставку сообщения на сервер без потери или дублирования. TCP автоматически отправит любую информацию, которая может быть потеряна при передаче, и именно поэтому TCP известен как надежный протокол . В дополнение к обнаружению ошибок, TCP также обеспечивает управление потоком. Алгоритмы управления потоком в TCP гарантируют, что отправитель не отправляет данные слишком быстро, чтобы получатель мог обработать данные. Управление потоком важно в этом мире разнообразных сетей и устройств.
Короче говоря, TCP предоставляет службы, жизненно важные для успешной доставки HTTP-сообщений, но делает это прозрачным образом, так что большинству приложений не нужно беспокоиться о TCP. Как показывает предыдущий рисунок, TCP — это только первый уровень ниже HTTP. После TCP на транспортном уровне идет IP в качестве протокола сетевого уровня.
IP это сокращение от интернет-протокола . В то время как TCP отвечает за обнаружение ошибок, управление потоком и общую надежность, IP отвечает за сбор информации и ее перемещение через различные коммутаторы, маршрутизаторы, шлюзы, ретрансляторы и другие устройства, которые перемещают информацию из одной сети в другую и по всему миру. IP старается доставить данные в пункт назначения (но не гарантирует доставку — это работа TCP). IP требует, чтобы у компьютеров был адрес (известный IP-адрес, пример 208.192.32.40). IP также отвечает за разбиение данных на пакеты (часто называемые датаграммами), а иногда за фрагментацию и повторную сборку этих пакетов, чтобы они были оптимизированы для определенного сегмента сети.
Все, о чем мы говорили до сих пор, происходит внутри компьютера, но в конечном итоге эти IP-пакеты должны проходить по куску провода, оптоволоконному кабелю, беспроводной сети или спутниковой связи. Это ответственность канального уровня . Распространенным выбором технологии на данный момент является Ethernet . На этом уровне пакеты данных становятся кадрами, а низкоуровневые протоколы, такие как Ethernet, ориентированы на 1, 0 и электрические сигналы.
В конечном счете сигнал достигает сервера и поступает через сетевую карту, где процесс полностью изменен. Канальный уровень доставляет пакеты на уровень IP, который передает данные в TCP, который может собрать данные в исходное HTTP-сообщение, отправленное клиентом, и отправить его в процесс веб-сервера. Это прекрасно спроектированная работа, которая стала возможной благодаря стандартам.
Быстрый HTTP-запрос с сокетами и C #
Если вам интересно, как выглядит приложение, которое будет отправлять HTTP-запросы, то следующий код C # — простой пример того, как может выглядеть этот код. Этот код не обрабатывает ошибки и пытается записать любой ответ сервера в окно консоли (поэтому вам потребуется запросить текстовый ресурс), но он работает для простых запросов. Копия следующего примера кода доступна по адресу https://bitbucket.org/syncfusion/http-succinctly . Имя образца — sockets-sample.
используя Систему; используя System.Net; использование System.Net.Sockets; использование System.Text; открытый класс GetSocket { public static void Main (строка [] args) { var host = "www.wikipedia.org"; var resource = "/"; Console.WriteLine («Соединение с {0}», хост); if (args.GetLength (0)> = 2) { host = args [0]; ресурс = аргументы [1]; } var result = GetResource (host, resource); ЕЫпе (результат); } приватная статическая строка GetResource (строковый хост, строковый ресурс) { var hostEntry = Dns.GetHostEntry (host); var socket = CreateSocket (hostEntry); SendRequest (сокет, хост, ресурс); return GetResponse (сокет); } частный статический сокет CreateSocket (IPHostEntry hostEntry) { const int httpPort = 80; foreach (переменный адрес в hostEntry.AddressList) { var endPoint = новый IPEndPoint (адрес, httpPort); var socket = new Socket ( endPoint.AddressFamily, SocketType.Stream, ProtocolType.Tcp); Socket.connect (конечная точка); if (socket.Connected) { возвратная розетка; } } вернуть ноль; } приватная статическая пустота SendRequest (сокет, строковый хост, строковый ресурс) { var requestMessage = String.Format ( "ПОЛУЧИТЬ {0} HTTP / 1.1 \ r \ n" + "Хост: {1} \ r \ n" + "\ Г \ п", ресурс, хост ); var requestBytes = Encoding.ASCII.GetBytes (requestMessage); socket.Send (requestBytes); } приватная статическая строка GetResponse (Socket socket) { int bytes = 0; byte [] buffer = new byte [256]; var result = new StringBuilder (); делать { bytes = socket.Receive (buffer); result.Append (Encoding.ASCII.GetString (buffer, 0, bytes)); } while (байт> 0); вернуть результат. ToString (); } }
Обратите внимание, что программе необходимо найти адрес сервера (используя Dns.GetHostEntry ) и сформулировать правильное HTTP-сообщение с оператором GET и заголовком Host . Реальная сетевая часть довольно проста, потому что реализация сокетов и TCP выполняют большую часть работы. TCP понимает, например, как управлять несколькими подключениями к одному серверу (все они будут получать разные номера портов локально). Из-за этого два невыполненных запроса к одному серверу не будут перепутаны и не получат данные, предназначенные для другого.
Сеть и Wireshark
Если вам нужна некоторая информация о TCP и IP, вы можете установить бесплатную программу, такую как Wireshark (доступна для OSX и Windows с wireshark.org ). Wireshark — это сетевой анализатор, который может отображать каждый бит информации, проходящей через ваши сетевые интерфейсы. Используя Wireshark, вы можете наблюдать TCP-рукопожатия, которые являются TCP-сообщениями, необходимыми для установления соединения между клиентом и сервером до того, как фактические HTTP-сообщения начинают передаваться. Вы также можете видеть заголовки TCP и IP (по 20 байт) в каждом сообщении. На следующем рисунке показаны два последних шага рукопожатия, за которыми следуют GET и перенаправление 304 .
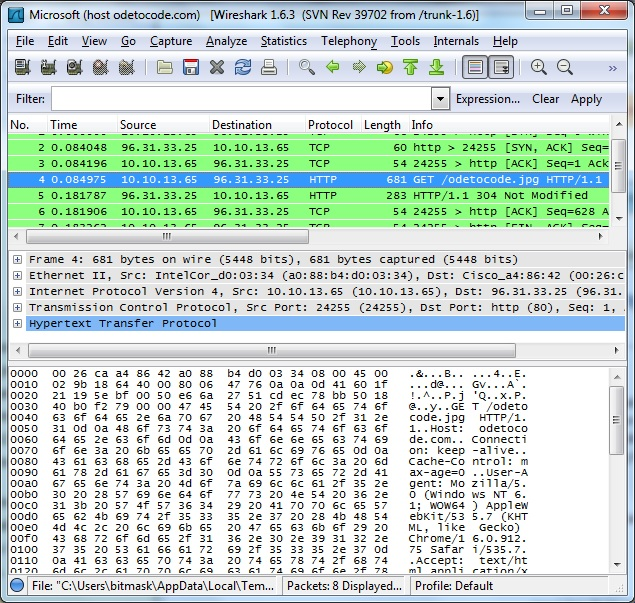
С Wireshark вы можете видеть, когда HTTP-соединения установлены и закрыты. Важным моментом, который необходимо устранить, является не то, как рукопожатия и TCP работают на самом низком уровне, а то, что HTTP почти полностью полагается на TCP, чтобы справиться со всей тяжелой работой, а TCP требует некоторых накладных расходов, таких как рукопожатия. Таким образом, характеристики производительности HTTP также зависят от характеристик производительности TCP, и это тема для следующего раздела.
HTTP, TCP и эволюция Интернета
В очень давние времена Интернета большинство ресурсов были текстовыми. Вы можете запросить документ с веб-сервера, отключиться и прочитать в течение пяти минут, а затем запросить другой документ. Мир был прост.
Для современных веб-страниц большинству веб-страниц требуется более одного ресурса для полной визуализации. Каждая страница в веб-приложении содержит одно или несколько изображений, один или несколько файлов JavaScript и один или несколько файлов CSS. Нередко первоначальный запрос домашней страницы вызывает 30 или 50 дополнительных запросов для извлечения всех других ресурсов, связанных со страницей.
В старые времена браузеру также было просто устанавливать соединение с сервером, отправлять запрос, получать ответ и закрывать соединение. Если современные веб-браузеры открывают соединения по одному и ожидают полной загрузки каждого ресурса, прежде чем начать следующую загрузку, сеть будет работать очень медленно. Интернет полон латентности. Сигналы должны преодолевать большие расстояния и прокладывать себе путь через различные части оборудования. Существует также некоторые издержки при установлении TCP-соединения. Как мы видели на скриншоте Wireshark, необходимо выполнить трехэтапное рукопожатие, прежде чем можно будет начать транзакцию HTTP.
Переход от простых документов к сложным страницам потребовал некоторой изобретательности в практическом использовании HTTP.
Параллельные соединения
Большинство пользовательских агентов (или веб-браузеры) не будут посылать запросы последовательно один за другим. Вместо этого они открывают несколько параллельных подключений к серверу. Например, при загрузке HTML-кода для страницы браузер может увидеть два <img> на странице, поэтому браузер откроет два параллельных соединения для одновременной загрузки двух изображений. Количество параллельных подключений зависит от пользовательского агента и конфигурации агента.
Долгое время мы рассматривали два в качестве максимального числа параллельных подключений, которое может создать браузер. Мы считали два максимума, потому что самый популярный браузер за многие годы — Internet Explorer (IE) 6 — допускал только два одновременных подключения к одному хосту. IE только подчинялся правилам, изложенным в спецификации HTTP 1.1, которая гласит:
Однопользовательский клиент НЕ ДОЛЖЕН поддерживать более двух соединений с любым сервером или прокси.
Чтобы увеличить количество параллельных загрузок, многие сайты используют некоторые приемы. Например, ограничение двух соединений для каждого хоста означает, что браузер, такой как IE 6, с радостью установит два параллельных соединения с www.odetocode.com и два параллельных соединения с images.odetocode.com. Размещая изображения на другом сервере, веб-сайты могут увеличить количество параллельных загрузок и ускорить загрузку своих страниц (даже если записи DNS были настроены так, чтобы все четыре запроса были направлены на один и тот же сервер, поскольку ограничение на два соединения для каждого хоста имя, а не IP-адрес ).
Сегодня все по-другому. Большинство пользовательских агентов будут использовать другой набор эвристик при решении, сколько параллельных соединений устанавливать. Например, Internet Explorer 8 теперь будет открывать до шести одновременных подключений.
Реальный вопрос, который нужно задать: сколько соединений слишком много? Параллельные соединения будут подчиняться закону убывающей отдачи. Слишком большое количество соединений может насытить сеть и заполнить ее, особенно когда речь идет о мобильных устройствах или ненадежных сетях. Таким образом, слишком большое количество соединений может снизить производительность. Кроме того, сервер может принимать только конечное число подключений, поэтому, если 100 000 браузеров одновременно создают 100 подключений к одному веб-серверу, могут произойти плохие вещи. Тем не менее, использование более одного соединения на одного агента лучше, чем последовательная загрузка всего.
К счастью, параллельные соединения — не единственная оптимизация производительности.
Постоянные соединения
В первые дни Интернета пользовательский агент открывал и закрывал соединение для каждого отдельного запроса, отправляемого на сервер. Эта реализация соответствовала идее HTTP быть протоколом без сохранения состояния. По мере роста количества запросов на страницу увеличивались издержки, создаваемые рукопожатиями TCP, и структуры данных в памяти, необходимые для установки каждого сокета TCP. Чтобы уменьшить эти издержки и повысить производительность, спецификация HTTP 1.1 предполагает, что клиенты и серверы должны реализовывать постоянные соединения и делать постоянные соединения типом соединения по умолчанию.
Постоянное соединение остается открытым после завершения одной транзакции запрос-ответ. Такое поведение оставляет пользовательский агент с уже открытым сокетом, который он может использовать для продолжения отправки запросов на сервер без дополнительных затрат на открытие нового сокета. Постоянные соединения также избегают стратегии медленного запуска, которая является частью контроля перегрузки TCP, благодаря чему постоянные соединения со временем улучшаются. Короче говоря, постоянные соединения уменьшают использование памяти, уменьшают нагрузку на процессор, уменьшают перегрузку сети, уменьшают задержку и в целом улучшают время отклика страницы. Но, как и все в жизни, есть и обратная сторона.
Как упоминалось ранее, сервер может поддерживать только конечное количество входящих соединений. Точное число зависит от объема доступной памяти, конфигурации серверного программного обеспечения, производительности приложения и многих других переменных. Трудно дать точное число, но, вообще говоря, если вы говорите о поддержке тысяч одновременных соединений, вам придется начать тестирование, чтобы посмотреть, будет ли сервер поддерживать нагрузку. На самом деле, многие серверы настроены на ограничение количества одновременных подключений намного ниже точки, в которой сервер будет падать. Конфигурация — это мера безопасности, помогающая предотвратить атаки типа «отказ в обслуживании». Для кого-то относительно легко создать программу, которая откроет тысячи постоянных соединений с сервером и не даст серверу реагировать на реальных клиентов. Постоянные соединения — это оптимизация производительности, но также и уязвимость.
Размышляя об уязвимости, мы также задаемся вопросом, как долго поддерживать постоянное соединение открытым. В мире бесконечной масштабируемости соединения могут оставаться открытыми до тех пор, пока работает программа агента пользователя. Но поскольку сервер поддерживает конечное число соединений, большинство серверов настроены на закрытие постоянного соединения, если оно простаивает в течение некоторого периода времени (например, пять секунд в Apache). Пользовательские агенты также могут закрывать соединения после периода простоя. Единственный видимость закрытых соединений — через сетевой анализатор, такой как Wireshark.
В дополнение к агрессивному закрытию постоянных подключений, большинство программного обеспечения веб-сервера можно настроить на отключение постоянных подключений. Это часто встречается на общих серверах. Общие серверы жертвуют производительностью, чтобы разрешить как можно больше соединений. Поскольку постоянные подключения являются стилем подключения по умолчанию в HTTP 1.1, сервер, который не разрешает постоянные подключения, должен включать заголовок Connection в каждый HTTP-ответ. Следующий код является примером.
HTTP / 1.1 200 ОК Content-Type: text / html; кодировка = UTF-8 Сервер: Microsoft-IIS / 7.0 X-AspNet-версия: 2.0.50727 X-Powered-By: ASP.NET Подключение: закрыть Длина контента: 17149
Заголовок Connection: close является сигналом для пользовательского агента, что соединение не будет постоянным и должно быть закрыто как можно скорее. Агент не может сделать второй запрос на том же соединении.
Конвейерные соединения
Параллельные и постоянные соединения широко используются и поддерживаются клиентами и серверами. Спецификация HTTP также допускает конвейерные соединения , которые не так широко поддерживаются ни серверами, ни клиентами. В конвейерном соединении пользовательский агент может отправить несколько HTTP-запросов на соединение перед ожиданием первого ответа. Конвейерная конвейерная обработка обеспечивает более эффективную упаковку запросов в пакеты и может снизить задержку, но она не так широко поддерживается, как параллельные и постоянные соединения.
Где мы?
В этой главе мы рассмотрели HTTP-соединения и поговорили о некоторых способах оптимизации производительности, которые стали возможными благодаря спецификациям HTTP. Теперь, когда мы углубились в HTTP-сообщения и даже изучили соединения и поддержку TCP в рамках протокола, мы сделаем шаг назад и посмотрим на Интернет в более широкой перспективе.