
Одним из наиболее важных понятий HTML5 является унифицированная модель парсинга. В более ранних версиях спецификации HTML у разработчика была большая свобода. По сути, можно выбрать способ обработки определенных сценариев. В результате расхождение было одной из наиболее важных причин для разных интерпретаций многих веб-сайтов в разных браузерах. В HTML5 обработка ошибок была определена очень подробно, не оставляя места для интерпретаций.
В этой первой статье серии «HTML5 Mastery» мы рассмотрим алгоритмы обработки ошибок, указанные в стандарте. Мы увидим, что некоторые из этих потенциальных ошибок являются фактически допустимым поведением, что делает их пригодными для использования на популярных веб-сайтах. В основной части этой статьи будут обсуждаться правила области видимости, которые охватывают большую часть опытного поведения при запуске определенных алгоритмов. Мы начнем с практического примера, который показывает подразумеваемые закрывающие теги.
Примеры из реального мира
Двумя наиболее часто используемыми возможностями стандартизированного анализатора HTML5 являются автоматическое построение корректной структуры документа и вставка подразумеваемых конечных тегов. Начнем с последнего. Действительно хорошим примером, иллюстрирующим эту функцию, является создание простого списка. Следующий фрагмент кода показывает несортированный список из трех элементов.
|
1
2
3
4
5
|
<ul>
<li>First item
<li>Second item
<li>Third item
</ul>
|
Даже если мы опускаем закрывающий тег ( </li> ), страница отображает правильные данные. Правильный рендеринг возможен только в том случае, если дерево DOM было правильно построено из данного источника. Дерево DOM — это представление узлов DOM в иерархии дерева. Узел DOM может быть элементом, комментарием, текстом или какой-либо другой конструкцией, которая представлена в других частях этой серии.
Иерархия дерева DOM начинается с так называемого корня и показывает дочерние узлы корня. Корень — это первый узел дерева. У него нет родительского элемента. Некоторые узлы, такие как элементы, могут иметь дочерние узлы самостоятельно. Дерево дает нам информацию о фактически построенном DOM, тогда как источник просто предлагает конструкцию.
Синтаксический анализатор HTML5 обеспечивает вставку пропущенных конечных тегов перед добавлением новых элементов списка. Это соответствует нашей интуиции. Естественно, мы считаем, что в данном списке должно быть три пункта. До HTML5 мы могли фактически получить один элемент, который содержал текст, и другой элемент, который снова содержал текст и элемент с текстом.
В браузере мы видим следующий рендеринг (левая сторона). Мы также можем проверить дерево DOM, чтобы проверить, правильно ли обработал синтаксический анализатор сценарий (справа).

Несмотря на то, что Opera (здесь, в версии 31) использовалась для создания снимков экрана выше, это поведение не зависит от браузера, как было указано в стандарте HTML5.
Глядя на исходный код некоторых очень популярных сайтов, мы, возможно, увидим некоторые странности. Например, страница ошибок, отображаемая Google, содержит следующую разметку.
|
1
2
3
4
5
6
7
8
9
|
<!DOCTYPE html>
<html lang=en>
<meta charset=utf-8>
<meta name=viewport content=»initial-scale=1, minimum-scale=1, width=device-width»>
<title>Error 404 (Not Found)!!1</title>
<style>/* … */</style>
<a href=//www.google.com/><span id=logo aria-label=Google>
<p><b>404.</b> <ins>That’s an error.</ins>
<p>The requested URL <code>/error</code> was not found on this server.
|
Даже без указания элемента <head> или <body> элементы создаются. Также в абзацах есть закрывающие теги. Очевидно, параграфы обрабатываются аналогично пунктам списка. Они не встречаются как вложенные — по крайней мере, если они созданы из исходного кода анализатором HTML5.
Поэтому браузер генерирует дерево справа, которое будет отображать макет слева.
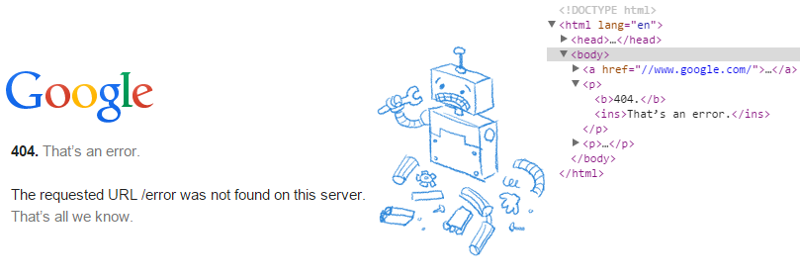
Одна из наиболее важных строк в предыдущем коде — это объявление правильного типа документа HTML5. В противном случае мы можем оказаться в режиме причуд, который по сути эквивалентен неопределенному поведению с точки зрения кросс-браузерной разработки.
Подразумеваемые конечные теги
Поведение, которое мы видели в предыдущем разделе, основано на генерации подразумеваемых конечных тегов. Механизм генерации подразумеваемых конечных тегов работает путем закрытия текущего узла, в то время как текущий узел является одним из следующих элементов:
-
<dd>или<dt>или<li> -
<option>или<optgroup> -
<rp>или<rt> -
<p>
Мы понимаем, что это действительно имеет смысл для всех этих тегов. Вложенный абзац не является четко определенным. Аналогично вложенные списки или параметры. Они имеют смысл только внутри другого контейнера.
Элемент с подразумеваемым конечным тегом не совпадает с самозакрывающимся элементом. В стандарте HTML есть элементы, такие как <source> , <img> или <input> , которые являются самозакрывающимися. Даже если они являются элементами, они не должны иметь детей. Парсер закрывает их немедленно. В то время как XML обозначает эти элементы с косой чертой, HTML рекомендует опускать косую черту.
Области применения HTML
Существует много сценариев, в которых применяется обзор. В принципе, когда синтаксический анализатор HTML5 обнаруживает определенные элементы во время построения дерева, он проверяет, находится ли элемент в определенной области видимости. Если это так, дальнейшие действия могут последовать. В противном случае текущий элемент обычно игнорируется.
Процесс определения того, находится ли элемент в заданной области видимости, начинается с просмотра текущего элемента. Если элемент является хостом области действия, мы находимся в его области действия. Если элемент находится в специальном подмножестве элементов, указанных в области, мы не попадаем в область. В противном случае мы продолжаем поиск по родительскому элементу текущего элемента.
Подмножество элементов можно разделить на пять групп. Каждая область выбирает одну из этих групп, чтобы указать элементы исключения. Эти пять групп названы:
- Общая
- Пункт списка
- кнопка
- Стол
- Выбрать
Элемент списка и группы кнопок также содержат все элементы общей группы. Группа таблиц содержит только <html> и сам элемент таблицы. Группа выбора включает все элементы, кроме <optgroup> и <option> .
Обзорные примеры
Группу select можно использовать для иллюстрации того, что мы получим, используя эти правила определения области видимости. Если мы, например, закрываем элемент select, то проверяется, есть ли у нас элемент <select> в группе выбора. Если это не так, закрывающий тег игнорируется. В противном случае мы закрываем все элементы, пока не закроем узел выбора.
Давайте посмотрим на некоторый код. Какое дерево будет сгенерировано?
|
1
|
<select><optgroup><option>First</select>
|
На самом деле это было слишком просто. Наша интуиция говорит нам, что </select> закрывает опцию и группу опций. Это верно. На самом деле мы ограничены использованием только элементов option и option group в элементе select. Это контролируется парсером. Так как насчет сейчас?
|
1
|
<p><optgroup><option>First</select>
|
Ну, здесь есть два основных различия. Во-первых, мы не вводим элемент select. Поэтому <optgroup> и <option> не будут ограничены синтаксическим анализатором. Они также могут принимать произвольные элементы. Во-вторых, закрытие элемента select будет игнорироваться. Происхождение этого поведения лежит в применяемом правиле ограничения.
Давайте теперь рассмотрим некоторое поведение, которое может повлиять на ваш дизайн разметки. Как будет выглядеть построенное дерево DOM для следующего фрагмента?
|
1
|
<p>I am from <address>Germany</address>.</p>
|
Нет ничего проще, не так ли? Ну, не так быстро. Разметка может показаться законной на первый взгляд. В конце концов, это просто семантическое объявление адреса внутри, верно? К сожалению нет. Элемент <address> также считается блоком, как абзац. Этот блок не имеет ничего общего с CSS, поэтому мы не можем изменить поведение, используя другое объявление display .
Мы уже видим, что построенный DOM имеет значение (справа). Рендеринг просто следует (левая сторона).

Такое поведение относится к довольно многим элементам. Спецификация гласит:
Начальный тег, имя тега которого является одним из: «адрес», «статья», «в сторону», «блок-цитата», «центр», «подробности», «dir», «div», «dl», «fieldset», «Figcaption», «figure», «footer», «header», «hgroup», «menu», «nav», «ol», «p», «section», «summary», «ul» […]
Все эти элементы проверят, есть ли у нас элемент абзаца в группе кнопок. Если это так, то абзац будет закрыт.
Есть много других мест, где элементы контекста / предка действительно имеют значение. Все это делает фрагменты HTML крайне нелокальными. Однако сейчас мы рассмотрим еще одну тему обработки ошибок.
Переформатирование и таблицы
Давайте начнем с простого вопроса. Как выглядит дерево DOM для следующего кода?
|
1
|
<p>1<b>2<i>3</b>4</i>5</p>
|
Конечно, не очень сложно вычислить получившееся дерево до 3 , но тогда начинаются проблемы. Там нет действительно хороший аргумент для того, что должно произойти дальше. По этой причине некоторые поставщики браузеров решили ввести алгоритм, который описывает, как работает переформатирование.
Во-первых, закрывающий жирный тег подразумевает конец всех включенных тегов. В нашем примере это влияет на курсив. Но поскольку мы не закрывали тег курсива, мы должны обработать его специально. После того, как все внутренние теги были закрыты, нам нужно открыть новые для неявно закрытых тегов форматирования. Тег форматирования — это обычный тег, соответствующий элементу, который имеет (исторические) последствия для форматирования содержимого текста.
Следующая картинка показывает результат. Дерево слева является конструкцией до 3, а дерево справа иллюстрирует полную картинку после фрагмента кода.
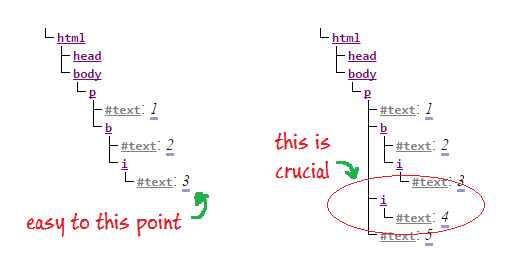
Во времена CSS реконструкция элементов форматирования может считаться устаревшей, но она далеко не устарела. Он не запускается напрямую, когда элементы закрыты, а когда вставляется новый текст.
Еще одна интересная тема — связь форматирования с элементами таблицы. Обработка ошибок в таблицах довольно странная. Кажется, никто не понимает это правильно интуитивно. Исторически это было разработано многими продавцами с различными философиями.
Давайте снова рассмотрим пример. Как дерево DOM будет искать следующий фрагмент?
|
1
|
<table><b><tr><td>aaa</td></tr>bbb</table>ccc
|
В <table> допускаются только элементы раздела <table> . Как было показано ранее с основными элементами HTML (такими как <head> или <body> ), синтаксический анализатор обычно заботится об этом. Например, если строка добавляется непосредственно в таблицу, секция <tbody> вставляется автоматически, чтобы позаботиться о строке.
Поэтому естественным является добавление элемента форматирования жирным шрифтом к элементу <body> . Но, поскольку мы указали форматирование текста, выделенное жирным шрифтом, нам все равно нужно иметь его для любого текста (вне таблицы) Поэтому первым шагом является создание таблицы (после вставленного элемента <b> ) с некоторым (обычным) текстом.
После закрытия строки мы встречаем еще немного текста. Этот текст находится внутри таблицы, но он не был помещен в ячейку. Поэтому он должен быть добавлен перед таблицей, как жирный элемент. Здесь полужирное форматирование все еще активно, то есть текст не будет добавляться автономно, а должен быть заключен в <b> .
Наконец, у нас есть текст за пределами таблицы. Мы можем правильно предположить, что этот текст должен идти после таблицы в дереве DOM, но ключевой вопрос: должен ли он быть отформатирован? Единственный правильный ответ — нет, не должен. Почему? Причина в том, что мы никогда не закрывали жирный тег. Поскольку жирный тэг был перенесен со стола на тело, мы все еще не закрывали его.
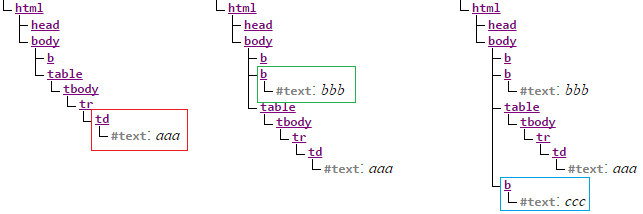
Разметка в первом примере не может считаться читаемой, интуитивно понятной или желаемой. Поведение, которое мы видели, является моделью исправления ошибок на работе, ничего, что не должно быть желательным Я выбрал этот пример, чтобы проиллюстрировать проблему (и показанное решение парсера) вложения несовместимых тегов. В большинстве случаев такие проблемы возникают из-за ошибок копирования / вставки или контроля версий.
Вывод
Знание внутренних особенностей парсера HTML5 очень важно. Это знание приводит к правильным правилам минимизации, которые могут сэкономить много байтов и некоторое время анализа. Также у нас теперь есть базовое понимание обработки индуцированных ошибок анализатором HTML.
Правила области видимости всегда очевидны в процессе анализа HTML5. Мы имеем дело с чрезвычайно сложным процессом, который не принимает элементы равными или неизвестными. Вместо этого у нас есть огромный набор специального поведения, которое сильно зависит от текущей области видимости, которая определяется рассматриваемым элементом.
Мы также видели, что угадывание правильного дерева не всегда так интуитивно, как должно быть. В общем, мы должны стараться избегать таких проблемных областей.