
Кодирование — только одна из тех вещей, которые должны быть сделаны правильно. Если все сделано неправильно, кажется, что все сломано и ничего не работает. Если все сделано правильно, никто не заметит. Это делает работу с кодированием настолько раздражающей.
Тем не менее, нам повезло, и большинство вещей уже хорошо подготовлены. Нам нужно только убедиться, что наши документы сохранены (и переданы) в правильной кодировке. Правильная кодировка — это та, которую мы указываем. Это может быть что угодно, лишь бы оно содержало все нужные нам символы и пока мы оставались последовательными.
Существует три важных правила кодирования текста для HTML:
- Загрузите контент с правильной кодировкой.
- Передайте контент с той же кодировкой.
- Убедитесь, что клиент читает содержимое с указанной кодировкой.
В этой статье мы подробнее рассмотрим все три правила, особенно второе и третье. В конце мы также рассмотрим кодирование форм, которое не имеет прямого отношения к кодированию текста, но косвенно. Мы увидим, почему есть какая-то связь.
Выбор правильной кодировки
Либо мы знаем, что наш контент должен быть доставлен в какой-то экзотической кодировке, либо нам просто нужно выбрать UTF-8. Есть много причин, почему мы хотели бы использовать UTF-8. Это не лучший формат для хранения символов в памяти, но он просто замечательный как основа для обмена данными и передачи контента. Это в основном легкая задача. Тем не менее, одной из наиболее распространенных ошибок является сохранение файлов без надлежащего кодирования. Поскольку нет текста без кодировки, мы должны тщательно выбирать кодировку.
Пользователи Sublime Text и большинства других текстовых редакторов, вероятно, никогда не сталкивались с проблемой неправильной кодировки, поскольку эти редакторы сохраняются в UTF-8 по умолчанию. Существуют редакторы, в основном для платформы Windows, которые используют другой формат по умолчанию, например, Windows-1252.
Даже в Sublime Text это одна из самых стандартных операций для изменения кодировки файла. В меню File мы выбираем Save with Encoding и выбираем тот, который нам нужен. Это оно!
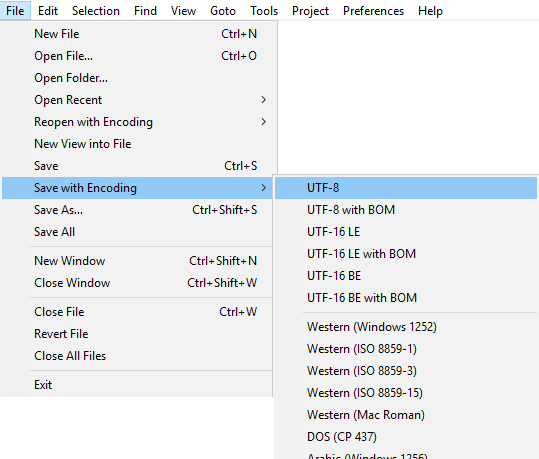
В принципе, каждый более продвинутый редактор должен иметь такие опции. Иногда они содержатся в расширенном меню сохранения. Например, редактор для Microsoft Visual Studio вызывает специальный диалог после нажатия Advanced Save Options … в меню File .
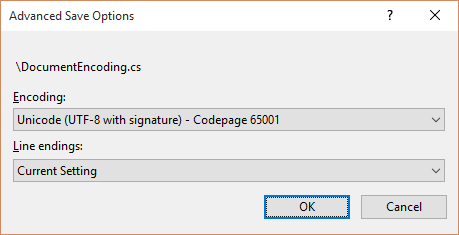
Мы должны обязательно использовать правильную кодировку. Это будет использовать соответствующие байты для нашего контента. UTF-8 имеет главное преимущество: требуется только один байт, если мы не используем специальный символ. Максимум 4 байта на символ расходуется. Это динамично и делает UTF-8 идеальным форматом для хранения и передачи текста. Однако предостережение заключается в том, что UTF-8 — не лучший формат для использования строк из памяти.
Управление передачей
Протокол HTTP передает данные в виде простого текста. Даже если мы решим закодировать передаваемый контент как GZip или если мы используем HTTPS, который шифрует контент, базовый контент по-прежнему остается простым текстом. Мы уже узнали, что не существует такого понятия, как простой текст. Нам всегда нужно ассоциировать контент с некоторой кодировкой, чтобы получить текстовое представление.
HTTP-сообщение разделено на две части. Верхняя часть называется заголовками. Пустой строкой отделена нижняя часть: корпус.
Всегда есть как минимум два HTTP-сообщения: запрос и связанный с ним ответ. Оба типа сообщений имеют эту структуру. Тело ответа — это контент, который мы хотим передать. Тело запроса представляет интерес только для отправки формы, о которой мы позаботимся позже. Если мы хотим предоставить некоторую информацию о кодировке контента, мы должны предоставить некоторую информацию в заголовке.
Следующий заголовок сообщает принимающей стороне, что тело содержит специальный текстовый формат, называемый HTML, с использованием набора символов UTF-8.
plain Content-Type: text/html; charset=utf-8
Существует также заголовок Content-Encoding . Мы можем легко спутать кодировку контента с фактической текстовой кодировкой контента. Первый используется для указания кодирования всего пакета, например GZip, в то время как последний используется в качестве начальной настройки, например, для анализа предоставленного контента.
Если мы заботимся о правильности этого шага, мы должны убедиться, что наш веб-сервер отправляет правильный заголовок. Большинство веб-фреймворков предлагают такую возможность. В PHP мы могли бы написать:
php header('Content-Type:text/html; charset=utf-8');
В Node.js мы можем использовать следующее, где res — это переменная, представляющая запрос:
javascript res.setHeader('Content-Type', 'text/html; charset=utf-8');
Переданный заголовок установит для текстового сканера ввода HTML заданную настройку. В случае предыдущего примера мы используем UTF-8 . Но подождите: начальная настройка! Есть много способов переопределить это. Если фактическим содержимым является не UTF-8, сканер может распознать это и изменить настройку. Такое изменение может быть инициировано обнаружением Byte-Order-Mark (известным как BOM) или путем нахождения специфичных для кодирования шаблонов в контенте. Напротив, первый ищет искусственно сшитые узоры.
Наконец, кодировка может измениться из-за нашего HTML-кода. Это может быть изменено только один раз.
Исправление кодировки
Как только конструктор DOM найдет meta , он будет искать объявление charset . Если он найден, набор символов будет извлечен. Если мы можем извлечь его успешно и если кодировка действительна, мы устанавливаем новую кодировку для сканирования дальнейших символов. В этот момент кодировка будет заморожена, и дальнейшие изменения невозможны.
Есть только одна оговорка. Чтобы проверить, было ли предыдущее сканирование в порядке, нам нужно сравнить уже отсканированные символы с символами, которые были бы отсканированы. Следовательно, нам нужно посмотреть, изменило бы ранее изменение кодировки. Если мы находим разницу, нам нужно перезапустить всю процедуру разбора. В противном случае вся структура DOM может быть неправильной до этого момента.
Как следствие, мы уже выучили два урока:
- Поместите
<meta charset=utf-8>(или другую кодировку) как можно скорее. - Используйте только символы ASCII перед указанием атрибута
charsetв HTML.
Наконец, хороший стартер для шаблона выглядит следующим образом. Как мы узнали из предыдущей статьи, мы можем опустить теги head и body . Фрагмент делает две вещи правильно: он использует правильный тип документа и выбирает набор символов как можно скорее.
« `html <! DOCTYPE html>