Динамические веб-страницы великолепны; Вы можете адаптировать полученную страницу для своего пользователя, показать активность другого пользователя, предложить различные продукты своим клиентам на основе их истории навигации и так далее. Но чем динамичнее сайт, тем больше запросов к базе данных вам, вероятно, потребуется выполнить. К сожалению, эти запросы к базе данных занимают большую часть вашего времени выполнения.
В этом уроке я продемонстрирую способ повышения производительности без выполнения дополнительных ненужных запросов. Мы разработаем систему кэширования запросов для нашего уровня данных с небольшими затратами на программирование и развертывание.
1. Уровень доступа к данным
Прозрачное добавление слоя кэширования в приложение часто затруднено из-за внутреннего дизайна. С объектно-ориентированными языками (такими как PHP 5) это намного проще, но все еще может быть сложным из-за плохого дизайна.
В этом уроке мы устанавливаем отправную точку в приложении, которое выполняет весь доступ к базе данных через централизованный класс, из которого все модели данных наследуют основные методы доступа к базе данных. Скелет для этого начального класса выглядит следующим образом:
|
01
02
03
04
05
06
07
08
09
10
|
class model_Model {
protected static $DB = null;
function __construct () {}
protected function doStatement ($query) {}
protected function quoteString ($value) {}
}
|
Давайте реализуем это шаг за шагом. Во-первых, конструктор, который будет использовать библиотеку PDO для взаимодействия с базой данных:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
function __construct () {
// connect to the DB if needed
if ( is_null(self::$DB) ) {
$dsn = app_AppConfig::getDSN();
$db_user = app_AppConfig::getDBUser();
$db_pass = app_AppConfig::getDBPassword();
self::$DB = new PDO($dsn, $db_user, $db_pass);
self::$DB->setAttribute( PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION );
}
}
|
Мы подключаемся к базе данных, используя библиотеку PDO. Для учетных данных базы данных я использую статический класс с именем app_AppConfig, который централизует информацию о конфигурации приложения.
Для хранения соединения с базой данных мы используем статический атрибут ($ DB). Мы используем статический атрибут, чтобы разделить одно и то же соединение со всеми экземплярами «model_Model», и поэтому код соединения защищен с помощью if (мы не хотим подключаться более одного раза).
В последней строке конструктора мы устанавливаем модель ошибки исключения для PDO. В этой модели для каждой ошибки, которую обнаруживает PDO, он возвращает исключение (класс PDOException) вместо возврата значений ошибки. Это дело вкуса, но остальная часть кода может содержаться в чистоте благодаря исключительной модели, которая хороша для этого урока.
Выполнение запросов может быть очень сложным, но в этом классе мы выбрали простой подход с одним методом doStatement ():
|
1
2
3
4
5
6
7
8
|
protected function doStatement ($query) {
$st = self::$DB->query($query);
if ( $st->columnCount()>0 ) {
return $st->fetchAll(PDO::FETCH_ASSOC);
} else {
return array();
}
}
|
Этот метод выполняет запрос и возвращает ассоциативный массив со всем набором результатов (если есть). Обратите внимание, что мы используем статическое соединение (self :: $ DB). Также обратите внимание, что этот метод защищен. Это потому, что мы не хотим, чтобы пользователь выполнял произвольные запросы. Вместо этого мы будем предоставлять конкретные модели для пользователя. Мы увидим это позже, но перед тем, как реализовать последний метод:
|
1
2
3
|
protected function quoteString ($value) {
return self::$DB->quote($value,PDO::PARAM_STR);
}
|
Класс «model_Model» — это очень простой, но удобный класс для наложения данных. Хотя это просто (его можно улучшить с помощью расширенных функций, таких как подготовленные операторы, если хотите), оно делает основные вещи для нас.
Чтобы завершить настройку нашего приложения, давайте напишем статический класс app_Config:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
class app_AppConfig {
static public function getDSN () {
return «mysql:host=localhost;dbname=test»;
}
static public function getDbUser () {
return «test»;
}
static public function getDbPassword () {
return «MyTest»;
}
}
|
Как указывалось ранее, мы предоставим конкретные модели для доступа к базе данных. В качестве небольшого примера мы будем использовать эту простую схему: таблицу документов и инвертированный индекс для поиска, содержит ли документ данное слово или нет:
|
1
|
CREATE TABLE documents ( id integer primary key, owner varchar(40) not null, server_location varchar(250) not null );
|
Из базового класса доступа к данным (model_Model) мы получаем столько классов, сколько необходимо для проектирования данных нашего приложения. В этом примере мы можем получить эти два понятных класса:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
class model_Index extends model_Model {
public function getWord ($word) {
return $this->doStatement(«SELECT doc_id FROM words WHERE word=» . $this->quoteString($word));
}
}
class model_Documents extends model_Model {
public function get ($id) {
return $this->doStatement( «SELECT * FROM documents WHERE id=» . intval($id) );
}
}
|
Те производные модели, где мы добавляем публичную информацию. Использовать их чрезвычайно просто:
|
1
2
3
|
$index = new model_Index();
$words = $index->getWord(«coche»);
var_dump($words);
|
Результат для этого примера может выглядеть примерно так (очевидно, это зависит от ваших реальных данных):
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
array(119) {
[0]=>
array(1) {
[«doc_id»]=>
string(4) «4630»
}
[1]=>
array(1) {
[«doc_id»]=>
string(4) «4635»
}
[2]=>
array(1) {
[«doc_id»]=>
string(4) «4873»
}
[3]=>
array(1) {
[«doc_id»]=>
string(4) «4922»
}
[4]=>
array(1) {
[«doc_id»]=>
string(4) «5373»
}
…
|
То, что мы написали, показано на следующей диаграмме классов UML:
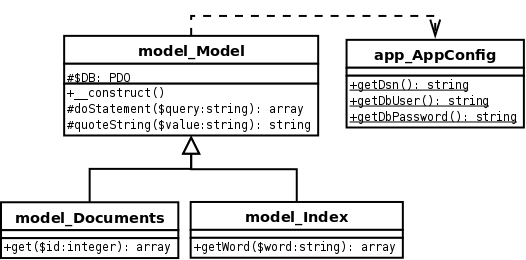
2. Планирование нашей схемы кэширования
Когда на вашем сервере баз данных начинают происходить сбои, наступает время сделать перерыв и подумать об оптимизации уровня данных. После оптимизации ваших запросов, добавления правильных индексов и т. Д. Второй шаг — попытаться избежать ненужных запросов: зачем делать один и тот же запрос к базе данных при каждом запросе пользователя, если эти данные почти не изменяются?
Благодаря хорошо спланированной и хорошо отлаженной организации классов мы можем добавить дополнительный уровень в наше приложение практически без затрат на программирование. В этом случае мы собираемся расширить класс «model_Model», чтобы добавить прозрачное кэширование на наш уровень базы данных.
Основы кэширования
Поскольку мы знаем, что нам нужна система кеширования, давайте сосредоточимся на этой конкретной проблеме и, как только разберемся, мы интегрируем ее в нашу модель данных. Пока мы не будем думать с точки зрения запросов SQL. Легко немного абстрагироваться и построить достаточно общую схему.
Самая простая схема кэширования состоит из пар [ключ, данные], где ключ идентифицирует фактические данные, которые мы хотим сохранить. Эта схема не нова, на самом деле она аналогична ассоциативным массивам PHP, и мы используем ее постоянно.
Поэтому нам понадобится способ сохранить пару, прочитать ее и удалить. Этого достаточно, чтобы построить наш интерфейс для помощников кеша:
|
1
2
3
4
5
6
7
8
|
interface cache_CacheHelper {
function get ($key);
function put ($key,$data);
function delete ($key);
}
|
Интерфейс довольно прост: метод get получает значение с учетом его идентифицирующего ключа, метод put устанавливает (или обновляет) значение для данного ключа, а метод delete удаляет его.
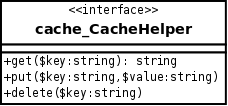
Учитывая этот интерфейс, пришло время реализовать наш первый настоящий модуль кеширования. Но перед этим мы выберем способ хранения данных.
Базовая система хранения
Решение о создании общего интерфейса (например, cache_CacheHelper) для помощников кэширования позволит нам реализовать их практически поверх любого хранилища. Но сверху на какой системе хранения? Их можно использовать много: общая память, файлы, серверы memcached или даже базы данных SQLite.
Часто недооцениваемые файлы DBM идеально подходят для нашей системы кэширования, и мы собираемся использовать их в этом руководстве.
Файлы DBM наивно работают на парах (ключ, данные) и делают это очень быстро благодаря своей внутренней организации B-дерева. Они также выполняют контроль доступа для нас: нам не нужно беспокоиться о блокировке кэша перед записью (как мы должны делать в других системах хранения); DBM делает это для нас.
Файлы DBM не управляются дорогими серверами, они выполняют свою работу в облегченной библиотеке на стороне клиента, имеющей локальный доступ к реальному файлу, в котором хранятся данные. Фактически они представляют собой семейство форматов файлов, и все они имеют одинаковый базовый API для доступа (ключ, данные). Некоторые из них допускают повторные ключи, другие являются постоянными и не разрешают запись после первого закрытия файла (cdb) и т. Д. Подробнее об этом можно прочитать на http://www.php.net/manual/en. /dba.requirements.php
Почти каждая система UNIX устанавливает один или несколько типов этих библиотек (возможно, Berkeley DB или GNU dbm). В этом примере мы будем использовать формат «db4» (формат Sleepycat DB4: http://www.sleepycat.com ). Я обнаружил, что эта библиотека часто предустановлена, но вы можете использовать любую нужную вам библиотеку (конечно, кроме cdb: мы хотим записать в файл). Фактически вы можете перенести это решение в класс app_AppConfig и адаптировать его для каждого проекта, который вы делаете.
В PHP у нас есть две альтернативы для работы с файлами DBM: расширение «dba» ( http://php.net/manual/en/book.dba.php ) или модуль «PEAR :: DBA» ( http: / /pear.php.net/package/DBA ). Мы будем использовать расширение «dba», которое, вероятно, вы уже установили в своей системе.
Подождите, мы имеем дело с SQL и результирующими наборами!
Файлы DBM работают со строками для ключа и значений, но наша проблема заключается в хранении наборов результатов SQL (которые могут сильно различаться по структуре). Как нам удалось превратить их из одного мира в другой?
Что касается ключей, это очень просто, потому что фактическая строка запроса SQL очень хорошо идентифицирует набор данных. Мы можем использовать дайджест MD5 строки запроса, чтобы укоротить ключ. Для значений это сложнее, но здесь вашими союзниками являются PHP-функции serialize () / unserialize (), которые можно использовать для преобразования массивов в строковые и наоборот.
Мы увидим, как все это работает в следующем разделе.
3. Статическое кеширование
В нашем первом примере мы рассмотрим самый простой способ выполнения кэширования: кэширование для статических значений. Мы напишем класс с именем «cache_DBM», реализующий интерфейс «cache_CacheHelper», вот так:
|
1
|
class cache_DBM implements cache_CacheHelper { protected $dbm = null;
|
Этот класс очень прост: отображение между нашим интерфейсом и функциями dba. В конструкторе данный файл открывается,
и возвращенный обработчик сохраняется в объекте, чтобы использовать его в других методах.
Простой пример использования:
|
1
2
3
4
5
6
7
8
9
|
$cache = new cache_DBM( «/tmp/my_first_cache.dbm» );
$cache->put(«key1», «my first value»);
echo $cache->get(«key1»);
$cache->delete(«key1»);
$data = $cache->get(«key1»);
if ( is_null($data) ) {
echo «\nCorrectly deleted!»;
}
|
Ниже вы найдете то, что мы здесь сделали, в виде диаграммы классов UML:
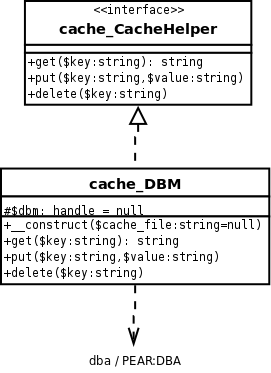
Теперь давайте добавим систему кэширования в нашу модель данных. Мы могли бы изменить класс «model_Model», чтобы добавить кеширование в каждый из его производных классов. Но если бы мы сделали это, мы бы потеряли гибкость в назначении характеристики кэширования только конкретным моделям, и я думаю, что это важная часть нашей работы.
Поэтому мы создадим еще один класс с именем «model_StaticCache», который расширит «model_Model» и добавит функциональность кэширования. Давайте начнем со скелета:
|
1
2
3
4
5
6
7
8
9
|
class model_StaticCache extends model_Model {
protected static $cache = array();
protected $model_name = null;
function __construct () { }
protected function doStatement ($query) { }
}
|
В конструкторе мы сначала вызываем родительский конструктор для подключения к базе данных. Затем мы статически создаем и храним объект «cache_DBM» (если он не был создан ранее). Мы храним один экземпляр для каждого производного имени класса, потому что мы используем один файл DBM для каждого из них. Для этого мы используем статический массив «$ cache».
|
1
2
3
4
5
6
7
8
9
|
function __construct () {
parent::__construct();
$this->model_name = get_class($this);
if ( ! isset( self::$cache[$this->model_name] ) ) {
$cache_dir = app_AppConfig::getCacheDir();
self::$cache[$this->model_name] = new cache_DBM( $cache_dir . $this->model_name);
}
}
|
Чтобы определить, в какой каталог нам нужно записать файлы кэша, мы снова использовали класс конфигурации приложения: «app_AppConfig».
А теперь: метод doStatement (). Логика для этого метода такова: преобразовать инструкцию SQL в допустимый ключ, найти ключ в кэше, если он найден, вернуть значение. Если не найден, запустите его в базе данных, сохраните результат и верните его:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
protected function doStatement ($query) {
$key = md5($query);
$data = self::$cache[$this->model_name]->get($key);
if ( ! is_null($data) ) {
return unserialize($data);
}
$data = parent::doStatement($query);
self::$cache[$this->model_name]->put($key,serialize($data));
return $data;
}
|
Есть еще две вещи, которые стоит отметить. Во-первых, мы используем MD5 запроса в качестве ключа. На самом деле, в этом нет необходимости, потому что базовая библиотека DBM принимает ключи произвольного размера, но в любом случае представляется, что лучше укоротить ключ. Если вы используете подготовленные операторы, не забудьте объединить фактические значения в строку запроса, чтобы создать ключ!
После того как «model_StaticCache» создан, изменение конкретной модели для ее использования становится тривиальным, вам нужно всего лишь изменить его предложение «extends» в объявлении класса:
|
1
2
|
class model_Documents extends model_StaticCache {
}
|
И это все, волшебство сделано! «Model_Document» будет выполнять только один запрос для каждого документа для извлечения. Но мы можем сделать это лучше.
4. Срок действия кэширования
В нашем первом подходе, после того как запрос сохранен в кеше, он остается действительным всегда, пока не произойдут две вещи: мы явно удалим его ключ или отсоединим файл DBM.
Однако этот подход действителен только для нескольких моделей данных нашего приложения: статических данных (таких как пункты меню и подобные вещи). Нормальные данные в нашем приложении, вероятно, будут более динамичными.
Подумайте о таблице, содержащей товары, которые мы продаем на нашей веб-странице. Это вряд ли изменится каждую минуту, но есть вероятность, что эти данные будут меняться (путем добавления новых продуктов, изменения продажных цен и т. Д.). Нам нужен способ реализации кэширования, но у нас есть способ реагировать на изменения данных.
Один из подходов к этой проблеме — установить срок действия данных, хранящихся в кеше. Когда мы храним новые данные в кеше, мы устанавливаем окно времени, в которое эти данные будут действительны. По истечении этого времени данные будут снова считаны из базы данных и сохранены в кеше в течение другого периода времени.
Как и раньше, мы можем создать еще один производный класс из «model_Model» с этой функциональностью. На этот раз мы назовем его «model_ExpiringCache». Скелет похож на «model_StaticCache»:
|
01
02
03
04
05
06
07
08
09
10
|
class model_ExpiringCache extends model_Model {
protected static $cache = array();
protected $model_name = null;
protected $expiration = 0;
function __construct () { }
protected function doStatement ($query) { }
}
|
В этом классе мы ввели новый атрибут: $ expiration. Этот будет хранить настроенное временное окно для действительных данных. Мы устанавливаем это значение в конструкторе, остальная часть конструктора такая же, как в «model_StaticCache»:
|
01
02
03
04
05
06
07
08
09
10
11
|
function __construct () {
parent::__construct();
$this->model_name = get_class($this);
if ( ! isset( self::$cache[$this->model_name] ) ) {
$cache_dir = app_AppConfig::getCacheDir();
self::$cache[$this->model_name] = new cache_DBM( $cache_dir . $this->model_name);
}
$this->expiration = 3600;
}
|
Основная часть работы приходит в doStatement. Файлы DBM не имеют внутреннего способа контроля истечения срока действия данных, поэтому мы должны реализовать свой собственный. Мы сделаем это, сохраняя массивы, как этот:
|
1
2
3
4
|
array(
«time» => 1250443188,
«data» => (the actual data)
)
|
Этот тип массива мы сериализуем и храним в кеше. Ключ «время» — это время изменения данных в кеше, а «данные» — это фактические данные, которые мы хотим сохранить. Во время чтения, если мы обнаружим, что ключ существует, мы сравниваем время создания с текущим временем и возвращаем данные, если они не истекли.
|
01
02
03
04
05
06
07
08
09
10
11
|
protected function doStatement ($query) {
$key = md5($query);
$now = time();
$data = self::$cache[$this->model_name]->get($key);
if ( !is_null($data) ) {
$data = unserialize($data);
if ( $data[‘time’] + $this->expiration > $now ) {
return $data[‘data’];
}
}
|
Если ключ не существует или срок его действия истек, мы продолжаем выполнение запроса и сохраняем новый набор результатов в кеше, прежде чем его вернуть.
|
1
2
3
4
5
6
7
|
$data = parent::doStatement($query);
self::$cache[$this->model_name]->put( $key,
serialize( array(«data»=>$data,»time»=>$now) ) );
return $data;
}
|
Просто!
Теперь давайте преобразуем «model_Index» в модель с устаревшим кешем. Как это бывает, с «model_Documents» нам нужно только изменить объявление класса и изменить предложение «extends»:
|
1
2
|
class model_Documents extends model_ExpiringCache {
}
|
О времени истечения … некоторые соображения должны быть сделаны. Мы используем постоянное время истечения (1 час = 3600 секунд), для простоты и потому, что мы не хотим изменять остальную часть нашего кода. Но мы можем легко изменить его множеством способов, чтобы позволить нам использовать разные сроки годности, по одному для каждой модели. После мы увидим как.
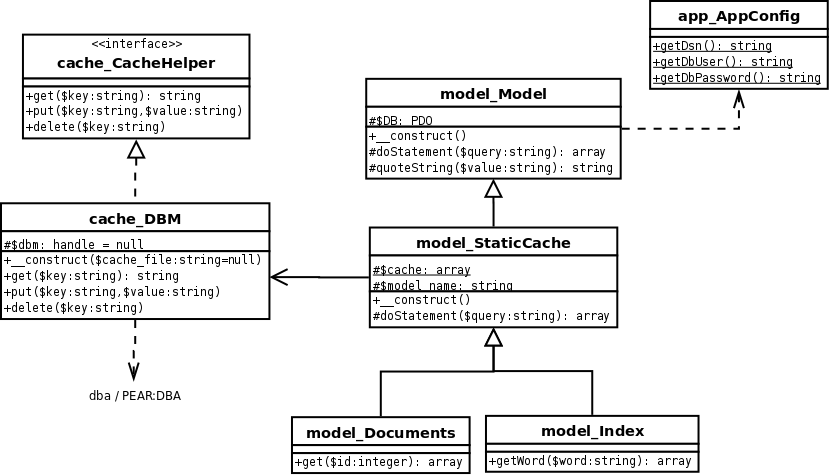
Диаграмма классов для всей нашей работы выглядит следующим образом:
5. Различный срок действия
Я уверен, что в каждом проекте у вас будет разное время истечения для почти каждой модели: от пары минут до часов или даже дней.
Если бы у каждой модели было разное время истечения, это было бы идеально … но, подождите! Мы можем сделать это легко!
Наиболее прямой подход — добавить аргумент в конструктор, поэтому новый конструктор для «model_ExpiringCache» будет таким:
|
1
2
3
4
5
6
|
function __construct ( $expiration=3600 ) {
parent::__construct();
$this->expiration = $expiration;
…
}
|
Затем, если нам нужна модель с 1-дневным сроком годности (1 день = 24 часа = 1440 минут = 86 400 секунд), мы можем сделать это следующим образом:
|
1
2
3
4
5
6
7
|
class model_Index extends model_ExpiringCache {
function __construct() {
parent::__construct(86400);
}
…
}
|
И это все. Однако недостатком является то, что мы должны изменить все модели данных.
Другой способ сделать это — делегировать задачу «app_AppConfig»:
|
01
02
03
04
05
06
07
08
09
10
11
12
|
class app_AppConfig {
…
public static function getExpirationTime ($model_name) {
switch ( $model_name ) {
case «model_Index»:
return 86400;
…
default:
return 3600;
}
}
}
|
А затем добавьте вызов к этому новому методу в конструкторе «model_ExpiringCache», например так:
|
1
2
3
4
5
6
7
8
9
|
function __construct () {
parent::__construct();
$this->model_name = get_class($this);
$this->expiration = app_AppConfig::getExpirationTime($this->model_name);
…
}
|
Этот последний метод позволяет нам делать причудливые вещи, например, использовать различные значения срока годности для производственных или сред разработки более централизованным способом. В любом случае, вы можете выбрать свой.
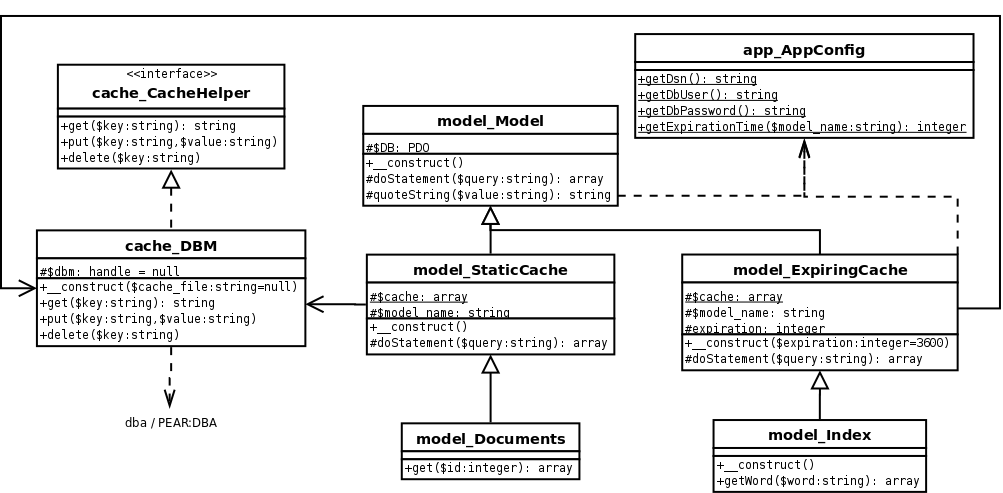
В UML общий проект выглядит так:
6. Некоторые предостережения
Есть несколько запросов, которые нельзя кэшировать. Наиболее очевидными являются изменения запросов, таких как INSERT, DELETE или UPDATE. Эти запросы должны поступить на сервер базы данных.
Но даже с запросами SELECT существуют некоторые обстоятельства, при которых система кэширования может создавать проблемы. Посмотрите на такой запрос:
|
1
|
SELECT * FROM banners WHERE zone=’home’ ORDER BY rand() LIMIT 10
|
Этот запрос случайным образом выбирает 10 баннеров для «домашней» зоны нашего сайта. Это предназначено для создания движения в баннерах, показанных в нашем доме, но если мы кешируем этот запрос, пользователь вообще не увидит никакого движения, пока не истечет срок хранения кэшированных данных.
Функция rand () не является детерминированной (как и сейчас () или другими); поэтому он будет возвращать разные значения при каждом выполнении. Если мы кешируем его, мы замораживаем только один из этих результатов за весь период кеширования, и, следовательно, нарушаем функциональность.
Но с помощью простого перефакторинга мы можем получить преимущества кэширования и показать псевдослучайность:
|
01
02
03
04
05
06
07
08
09
10
11
|
class model_Banners extends model_ExpiringCache {
public function getRandom ($zone) {
$random_number = rand(1,50);
$banners = $this->doStatement( «SELECT * FROM banners WHERE zone=» .
$this->quoteString($zone) .
» AND $random_number = $random_number ORDER BY rand() LIMIT 10″ );
return $banners;
}
…
}
|
Здесь мы кешируем пятьдесят различных конфигураций случайных баннеров и выбираем их случайным образом. 50 SELECT будут выглядеть так:
|
1
2
3
4
|
SELECT * FROM banners WHERE zone=’home’ AND 1=1 ORDER BY rand() LIMIT 10
SELECT * FROM banners WHERE zone=’home’ AND 2=2 ORDER BY rand() LIMIT 10
…
SELECT * FROM banners WHERE zone=’home’ AND 50=50 ORDER BY rand() LIMIT 10
|
Мы добавили постоянное условие для выбора, который не требует затрат для сервера базы данных, но отображает 50 различных ключей для системы кэширования. Пользователь должен будет загрузить страницу пятьдесят раз, чтобы увидеть все конфигурации баннера; Таким образом, динамический эффект достигается. Стоимость составляет пятьдесят запросов к базе данных для извлечения кеша.
7. Контрольный показатель
Какие преимущества мы можем ожидать от нашей новой системы кэширования?
Во-первых, нужно сказать, что в сырой производительности иногда наша новая реализация будет работать медленнее, чем запросы к базе данных, особенно с очень простыми, хорошо оптимизированными запросами. Но для тех запросов с объединениями наш кэш DBM будет работать быстрее.
Тем не менее, проблема, которую мы решили, это не грубая производительность. У вас никогда не будет запасного сервера базы данных для ваших тестов в производстве. Вероятно, у вас будет сервер с высокой нагрузкой. В этой ситуации даже самый быстрый запрос может выполняться медленно, но с нашей схемой кэширования мы даже не используем сервер, и, фактически, мы уменьшаем его рабочую нагрузку. Таким образом, реальное увеличение производительности будет заключаться в том, что число обращений в секунду будет больше
На веб-сайте, который я сейчас разрабатываю, я сделал простой тест, чтобы понять преимущества кэширования. Сервер скромный: на нем установлена Ubuntu 8.10, работающая поверх AMD Athlon 64 X2 5600+, с 2 ГБ оперативной памяти и старым жестким диском PATA. Система работает с Apahce и MySQL 5.0, которая поставляется с дистрибутивом Ubuntu без каких-либо настроек.
Тест состоял в том, чтобы запустить эталонную программу Apache (ab) с 1, 5 и 10 одновременными клиентами, загружающими страницу 1000 раз с моего веб-сайта разработки. Фактическая страница представляла собой информацию о продукте, которая имеет не менее 20 запросов: содержимое меню, сведения о продукте, рекомендуемые продукты, баннеры и т. Д.
Результаты без кеша составили 4,35 p / s для 1 клиента, 8,25 для 5 клиентов и 8,29 для 10 клиентов. С кэшированием (с истекшим сроком действия) результаты составили 25,55 п / с с 1 клиентом, 49,01 для 5 клиентов и 48,74 для 10 клиентов.
Последние мысли
Я показал вам простой способ вставить кеширование в вашу модель данных. Конечно, существует множество альтернатив, но этот — всего лишь один из возможных вариантов.
Мы использовали локальные файлы DBM для хранения данных, но есть еще более быстрые альтернативы, которые вы могли бы рассмотреть. Некоторые идеи на будущее: использование функций APC apc_store () в качестве базовой системы хранения, разделяемая память для действительно важных данных, использование memcached и т. Д.
Надеюсь, вам понравился этот урок так же, как я его написал. Удачного кеширования!