Несмотря на обширный кодекс , многие пользователи WordPress не знают, как создавать собственные плагины. В сегодняшнем скриншоте мы начнем с нуля и создадим наш первый используемый плагин. Для этого примера мы напишем простую функцию «форматирования», которая позволяет редактору блога более легко форматировать статьи.

Screencast
Шаг 1: Ваш первый плагин
При создании плагина WordPress первым шагом, очевидно, является обеспечение доступа к установке WordPress. Если у вас нет копии:
- Посетите WordPress.org и загрузите самую последнюю версию на свой жесткий диск.
- Установите WAMP или MAMP, если вы не будете работать на сервере.
- Перетащите загруженную папку WordPress в папку на своих сайтах.
- Создайте новую базу данных с MySQL или из командной строки.
- В Firefox перейдите к новой папке и начните установку.
* Примечание — это не руководство по началу работы с WordPress. Поэтому я не буду подробно останавливаться на инструкциях по установке. Вместо этого я настоятельно рекомендую вам прочитать серию статей Дрю Дугласа «WordPress для дизайнеров» в блоге ThemeForest.
Папка плагинов
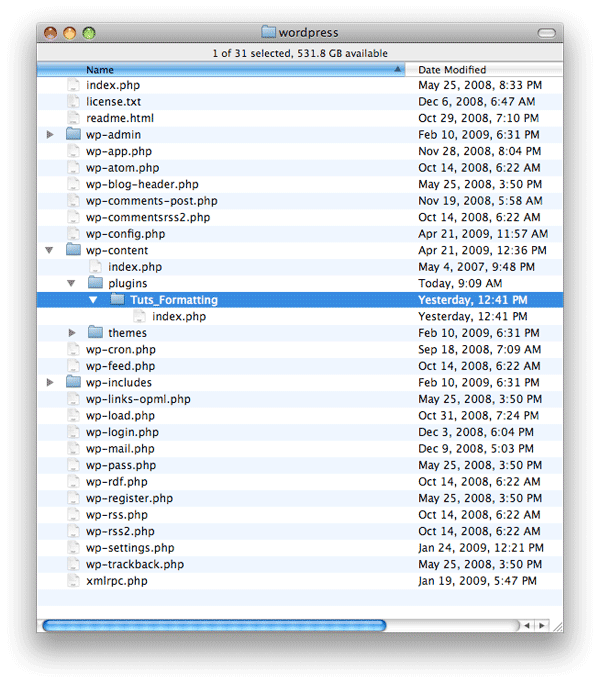
После запуска WordPress перейдите к wp-content -> plugins. Это где все ваши плагины будут храниться. Создать новый плагин — это просто добавить новую папку, индексный файл и добавить несколько комментариев. Давайте сделаем это сейчас.
- В папке плагинов щелкните правой кнопкой мыши и создайте новую папку — назовите ее «Tuts_Formatting».
- В вашем любимом редакторе кода сохраните пустой документ как «index.php» и поместите его в эту папку.
- Вставьте следующие комментарии вверху пустой страницы:
|
01
02
03
04
05
06
07
08
09
10
|
<?php
/*
Plugin Name: Tuts Formatting
Plugin URI: http://net.tutsplus.com
Description: Saves me time.
Version: 1.0
Author: Jeffrey Way
Author URI: http://net.tutsplus.com
*/
|
WordPress распознает эти комментарии и затем создает опцию в вашей панели администратора.

Обратите внимание, что если эти комментарии не включены, WordPress НЕ будет распознавать ваш плагин. Я рекомендую вам создать фрагмент и назначить нажатие клавиш, если вы будете создавать много плагинов в будущем. Я использовал TextExpander и назначил ключ «плагинкомментариев».
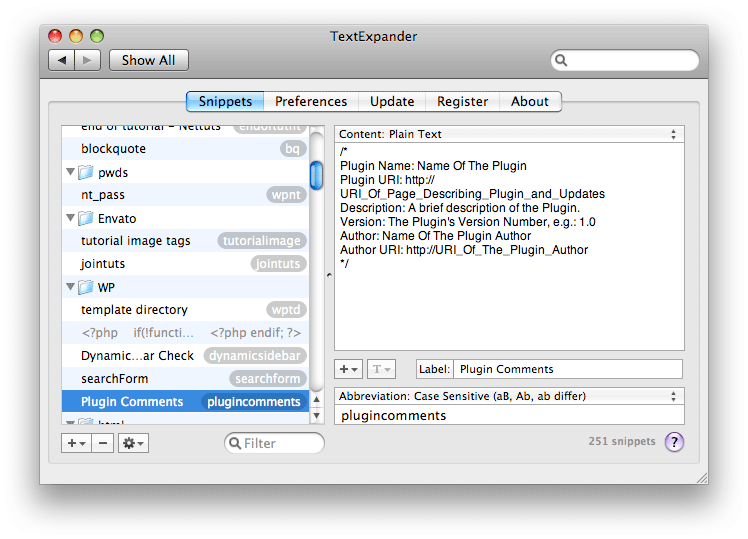
Шаг 2: Изложение нашего плагина
Я уверен, что многие из вас могут себе представить, что Nettuts + требует от наших авторов следовать руководящим принципам при отправке руководств. Например:
- Поместите все заголовки в теги H3.
- Оберните ваши изображения в div с классом учебного изображения. (Это добавляет фон и границы вокруг каждого изображения на Nettuts +.)
Хотя большинство наших авторов делают это правильно, мы часто получаем учебные пособия, которые требуют форматирования изменений. В этих случаях у меня есть два варианта: вернуть учебник отправителю или внести изменения самостоятельно. Более того, я обычно делаю изменения сам.
Разве не было бы удобно, если бы я мог создать плагин WordPress, который будет обрабатывать часть рабочей нагрузки для меня?
Это именно то, что я сделал. Тем не менее, этот конкретный плагин может быть слишком сложным для вашего первого. Вместо этого я создал «уменьшенную» версию, с которой мы будем работать сегодня. Все, что он будет делать, это:
- Добавьте информацию «Подписаться» внизу каждого урока.
- Замените все теги H2 тегами H3. (Согласно нашим правилам)
- Проверьте, не обернул ли автор свои изображения в div. Если нет, наш плагин позаботится об этом.
Шаг 3: Фильтры
Из кодекса WordPress …
«Фильтры — это функции, через которые WordPress передает данные в определенные моменты выполнения непосредственно перед тем, как предпринимать какие-либо действия с данными (например, добавлять их в базу данных или отправлять на экран браузера). Фильтры располагаются между базой данных и браузером ( когда WordPress генерирует страницы) и между браузером и базой данных (когда WordPress добавляет новые записи и комментарии в базу данных), большая часть ввода и вывода в WordPress проходит по крайней мере через один фильтр. WordPress выполняет некоторую фильтрацию по умолчанию, и ваш Плагин может добавить свою собственную фильтрацию. «
Чтобы уточнить, фильтры позволяют нам «привязать» к определенным разделам до отображения страницы. В нашем случае мы хотим зафиксировать основной контент перед его отображением. Таким образом, мы можем изменить форматирование, как описано выше. Для этого мы можем создать фильтр для «the_content». Это довольно просто. Вставьте следующий фрагмент на страницу индекса.
|
1
|
add_filter(‘the_content’, ‘Tut_Formatting’);
|
Этот блок кода по существу означает: «перед отображением содержимого (или тела сообщения в блоге) запустите функцию« Tut_Formatting ». Давайте создадим эту функцию сейчас. Добавьте следующее непосредственно перед вашим кодовым блоком« add_filter ».
|
1
2
|
function Tut_Formatting($content) {
}
|
Когда мы используем «add_filter», мы можем передать содержимое фильтруемого элемента нашей функции — обратите внимание на параметр $ content. В этом случае $ content будет хранить тело определенного блога.
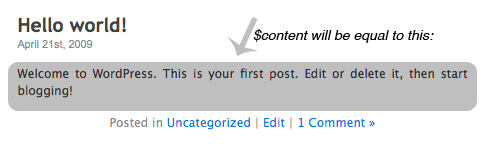
Шаг 4: Функция
Давайте начнем с добавления информации о подписке внизу каждого сообщения. Внутри вашей функции создайте новую переменную с именем $ end_of_tut.
|
1
|
$end_of_tut = <<<EOT <ul class=»webroundup»> <li>Follow us on <a href=»http://www.twitter.com/nettuts»>Twitter</a>, or subscribe to the <a href=»http://feeds.feedburner.com/nettuts» title=»NETTUTS RSS Feed»>NETTUTS RSS Feed</a> for more daily web development tuts and articles.</li></ul> <p> <script type=»text/javascript»><!—digg_url = «post permalink (not digg url)»;
|
То, что вы видите выше, является точным кодом, который мы используем для каждой публикации Nettuts +. Он просто содержит ссылки на наши каналы Twitter и RSS, а затем добавляет ссылку Digg. Digg предоставляет этот фрагмент кода внизу; просто скопируйте и вставьте его.
HereDocs
Смешивая PHP и HTML, heredocs — это простой способ очистить ваш код. Используя синтаксис <<< KEY, мы можем вставить обычный HTML. Мы назначаем закрытие нашего html-блока повторением нашего ключа — в данном случае EOT (для конца текста). Для получения дополнительной информации просмотрите видеоролик «Погружение в PHP: день 8» в блоге ThemeForest .
Если бы это было все, чего мы хотели достичь, нам нужно было бы только вернуть контент плюс этот новый блок html. Это легко сделать:
|
1
|
return $content .
|
Наша функция возвращает тело сообщения блога вместе с информацией о подписке, добавленной в конец. Тем не менее, мы собираемся сделать гораздо больше, поэтому давайте продолжим.
Регулярные выражения
Я решил использовать регулярные выражения для обработки наших изображений. В случае, если вы забыли, нам нужно найти сообщение и проверить, не обернул ли автор все свои изображения в div с классом «tutorial_image». Если у них есть, отлично — нам не нужно ничего делать. Однако, если они этого не сделали, мы будем использовать регулярные выражения в качестве нашей рабочей лошади.
|
1
|
$match = preg_match_all(‘/<div class=[\'»]?tutorial_image[\'»]?>\s*<img src=[\'»]?.+\.(jpg|gif|jpeg|png)[\'»]?(\s.+)?[(\s\/>)|(>)]\s*<\/div>/i’, $content, $matches);
|
Preg_match_all — это функция PHP, которая принимает три параметра:
- Выражение для поиска.
- Что мы ищем?
- Где будут храниться матчи?
Мы начнем с поиска содержимого публикации блога, представленной переменной $ content, и проверки наличия изображений, заключенных в div. Если вы не знакомы с регулярными выражениями, не волнуйтесь — это не так сложно.
|
1
|
/<div class=[\'»]?tutorial_image[\'»]?>\s*<img src=[\'»]?.+\.(jpg|gif|jpeg|png)[\'»]?(\s.+)?[(\s\/>)|(>)]\s*<\/div>/i
|
- Регулярные выражения заключены в разделители. Это может быть что угодно. Я склонен следовать синтаксису Perl и использовать / /. Обратите внимание, как они оборачивают наше выражение.
- Мы начинаем с поиска «<div class =». Теперь с помощью регулярных выражений мы должны компенсировать то, что МОЖЕТ сделать автор. Некоторые могут предпочесть заключать свои атрибуты в одинарные кавычки, в то время как другие могут опустить их полностью (хотя они не должны). Зная это, давайте допустим двойную кавычку, одинарную кавычку или ничего. Мы делаем это следующим образом: [\ ‘»]? Когда символы заключены в квадратные скобки, будет использоваться только один символ. Обратная косая черта — просто экранировать одинарную кавычку. Знак вопроса означает« разрешить ноль или один из предыдущий символ «. Так мы разрешаем автору не использовать кавычки.
- Продолжая — tutorial_image [\ ‘»]? — Мы снова ищем строку» tutorial_image «, за которой следует одинарная или двойная кавычка.
- \ s * означает «искать ноль или более пробелов». Как вы уже догадались, мы представляем пробел с «\ s».
- Теперь нам нужно сопоставить тег изображения. Теперь вы должны понять, на что ссылается первый раздел: <img src = [\ ‘»]?
- . + \. говорит двигателю искать одного или нескольких персонажей, пока не наступит точка. («.» относится к любому символу; «+» относится к одному или нескольким исходящим символам; «\.» буквально относится к точке.
- Теперь нам нужно найти правильное расширение. Мы ищем jpg, gif, jpeg или png, следующие за одинарной, двойной или без кавычек.
- Последний блок просто закрывает наше изображение и теги div.
- «I» в самом конце информирует движок о том, что буквы не должны быть нечувствительными к регистру.
Как вы можете себе представить, регулярные выражения очень сложно объяснить словами. Если этот последний раздел полностью смутил вас, посмотрите скринкаст для более подробного объяснения.
Теперь, когда мы создали наше выражение, нам нужно сообщить движку, что именно мы ищем. Как я уверен, вы уже догадались, нам нужно искать в $ content. Добавьте это в качестве второго параметра. Третий параметр обозначает массив, в котором будут храниться совпадения.
|
1
|
$match = preg_match_all(‘/<div class=[\'»]?tutorial_image[\'»]?>\s*<img src=[\'»]?.+\.(jpg|gif|jpeg|png)[\'»]?(\s.+)?[(\s\/>)|(>)]\s*<\/div>/i’, $content, $matches);
|
Проверка на совпадения
Когда мы запускаем эти регулярные выражения, мы можем ожидать один из двух результатов:
- $ match будет равно 0, потому что автор забыл обернуть свои изображения в div.
- $ match будет равен 1 или более — доказательство того, что автор не забыл обернуть свои изображения, и в этом случае нам ничего не нужно делать.
Нам нужно проверить значение $ match и действовать по-разному в зависимости от его значения.
|
1
2
3
4
5
6
7
8
9
|
if(!$match)
{
$theContent = preg_replace(‘/<img src=[\'»]?.+\.(jpg|gif|jpeg|png)[\'»]?(\s.+)?[(\s\/>)|(>)]/’, ‘<div class=»tutorial_image»>$0</div>’, $content);
}
else
{
$theContent = $content;
}
|
Мы используем! $ Match, чтобы проверить, равна ли переменная нулю. Если это так, нам нужно соответствующим образом обернуть наши изображения. С другой стороны, если оно равно одному или нескольким, это выражение вернет false, в этом случае вместо этого будет выполняться оператор else. Давайте рассмотрим этот первый блок:
Мы создаем новую переменную с именем $ theContent. Далее мы используем другую функцию PHP, которая называется «preg_replace». Эта функция принимает три параметра:
- Регулярное выражение
- Чем заменить любые спички
- Что искать.
|
1
|
preg_replace(‘/<img src=[\'»]?.+\.(jpg|gif|jpeg|png)[\'»]?(\s.+)?[(\s\/>)|(>)]/’, ‘<div class=»tutorial_image»>$0</div>’, $content);
|
Мы вставляем в это же регулярное выражение, за исключением тегов div. Итак, мы по сути находим все изображения в контенте. Второй параметр создает наш тег div и вставляет совпадающее изображение в пределах, обозначенных $ 0, что возвращает всю совпадающую строку. Третий параметр информирует движок о том, какую строку мы ищем.
еще
Теперь, если $ match равен одному или нескольким, вместо этого будет выполняться оператор else. В этом случае переменная $ theContent будет равна $ content или исходному тексту из the_content. Это так просто!
Замена H2s
Следующим шагом будет поиск любых использований тегов <h2> и замена их на <h3>.
|
1
2
|
$theContent = preg_replace(‘/<h2>/’, ‘<h3>’, $theContent);
$theContent = preg_replace(‘/<\/h2>/’, ‘</h3>’, $theContent);
|
Надеюсь, этот синтаксис становится более понятным. Должно быть достаточно очевидно, что делает код.
Шаг 5: Возвращение
Последний шаг — вернуть текст из нашей функции. Тем не менее, мы должны рассмотреть что-то. Мы не хотим, чтобы сообщения в блоге на главной странице содержали информацию о подписке. Это будет загромождать страницу кучей кнопок Digg. Давайте зарезервируем это для отдельных сообщений. Мы можем использовать функцию WordPress под названием is_single (), чтобы определить, находится ли пользователь на одной странице или нет.
|
1
|
return (is_single()) ?
|
Здесь мы используем троичный оператор. Мы можем разбить этот фрагмент на три простых раздела.
- Пользователь на одной странице?
- Если это так, верните $ theContent и добавьте информацию «Subscribe», на которую ссылается переменная $ end_of_tut.
- Если это не так, просто верните только $ theContent.
Это наш плагин!
Вернитесь в админ панель WordPress и нажмите на вкладку «Плагины». ,
Затем активируйте плагин Tuts_Formatting.
Создать новую публикацию
Если наш плагин работает правильно, его магия будет происходить за кулисами. Создайте новую запись в блоге и попробуйте! Создайте пару заголовков h2, добавьте несколько изображений и нажмите «Опубликовать». Если все работает правильно, страница будет изменена соответствующим образом. Используя Firebug или «View Source», мы можем это проверить.
Изображения, завернутые в Div
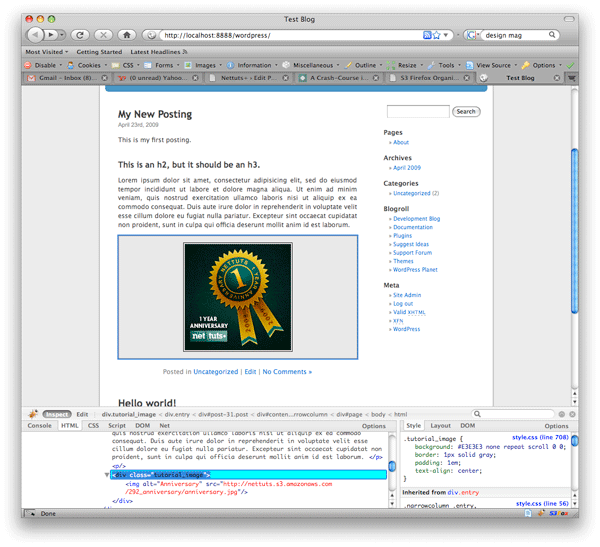
Я применил немного базового CSS для стилизации нашего div «tutorial_image».

Теги H2
Теги H2 теперь успешно изменены на H3s.
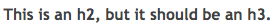
Информация о подписке
При просмотре одного сообщения, информация «Подписаться» должна быть добавлена внизу. Обратите внимание, что если вы работаете на локальном сервере, кнопка Digg не будет отображаться правильно. Не волнуйтесь, это сработает, как только вы перенесете файлы на свой сервер.

Окончательный код плагина
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
<?php
/*
Plugin Name: Tuts Formatting
Plugin URI: http://net.tutsplus.com
Description: Saves me time.
Version: 1.0
Author: Jeffrey Way
Author URI: http://net.tutsplus.com
*/
function Tut_Formatting($content) {
$end_of_tut = <<<EOT
<ul class=»webroundup»>
<li>Follow us on <a href=»http://www.twitter.com/nettuts»>Twitter</a>, or subscribe to the <a href=»http://feeds.feedburner.com/nettuts» title=»NETTUTS RSS Feed»>NETTUTS RSS Feed</a> for more daily web development tuts and articles.</li></ul>
<p>
<script type=»text/javascript»><!—digg_url = «post permalink (not digg url)»;
</script>
<script src=»http://digg.com/tools/diggthis.js» type=»text/javascript»></script></p>
EOT;
$match = preg_match_all(‘/<div class=[\'»]?tutorial_image[\'»]?>\s*<img src=[\'»]?.+\.(jpg|gif|jpeg|png)[\'»]?(\s.+)?[(\s\/>)|(>)]\s*<\/div>/i’, $content, $matches);
if(!$match)
{
$theContent = preg_replace(‘/<img src=[\'»]?.+\.(jpg||gif|jpeg|png)[\'»]?(\s.+)?[(\s\/>)|(>)]/’, ‘<div class=»tutorial_image»>$0</div>’, $content);
}
else
{
$theContent = $content;
}
$theContent = preg_replace(‘/<h2>/’, ‘<h3>’, $theContent);
$theContent = preg_replace(‘/<\/h2>/’, ‘</h3>’, $theContent);
# Or you can combine those two lines above into one if you would rather.
# $theContent = preg_replace(‘/<(\/?)h2>/’, ‘<$1h3>’, $theContent);
return (is_single()) ?
} // end of Tut_Formatting
add_filter(‘the_content’, ‘Tut_Formatting’);
|
Надеюсь, этот сравнительно простой пример поможет вам начать разработку плагинов для WordPress. Я настоятельно рекомендую вам ознакомиться с кодексом, чтобы получить лучшее понимание. Небо это предел при создании плагинов WordPress; есть очень мало, что вы не можете сделать. Какие ваши любимые плагины?
- Подпишитесь на нас в Твиттере или подпишитесь на RSS-канал NETTUTS, чтобы получать ежедневные обзоры и статьи о веб-разработке.